
Introducción a Llama 3.1 Instruct 405B
Llama 3.1 de Meta Instruct 405B representa un avance significativo en el ámbito de los modelos de lenguaje grandes (LLM). Como su nombre indica, este gigante cuenta con la impresionante cifra de 405 mil millones de parámetros, lo que lo convierte en uno de los modelos de IA disponibles públicamente más grandes hasta la fecha. Esta escala masiva se traduce en capacidades mejoradas en una amplia gama de tareas, desde la comprensión y generación del lenguaje natural hasta el razonamiento complejo y la resolución de problemas.
Una de las características destacadas de Llama 3.1 405B es su ventana de contexto ampliada de 128.000 tokens. Este aumento sustancial con respecto a las versiones anteriores permite que el modelo procese y genere textos mucho más largos, lo que abre nuevas posibilidades para aplicaciones como la creación de contenido de formato largo, el análisis profundo de documentos y las interacciones conversacionales extendidas.
El modelo destaca en áreas como:
- Resumen y precisión de textos
- Razonamiento y análisis matizados
- Capacidades multilingües (compatible con 8 idiomas)
- Generación y comprensión de código
- Potencial de ajuste fino específico para cada tarea
Con su naturaleza de código abierto, Llama 3.1 405B está preparado para democratizar el acceso a la tecnología de IA de vanguardia, permitiendo a investigadores, desarrolladores y empresas aprovechar su poder para una amplia gama de aplicaciones.
Comparación de proveedores de API de Llama 3.1
Varios proveedores de la nube ofrecen acceso a los modelos de Llama 3.1 a través de sus API. Comparemos algunas de las opciones más destacadas:
| Proveedor | Precios (por millón de tokens) | Velocidad de salida | Latencia | Características clave |
|---|---|---|---|---|
| Together.ai | 7,50 $ (tarifa combinada) | 70 tokens/segundo | Moderada | Impresionante velocidad de salida |
| Fireworks | 3,00 $ (tarifa combinada) | Buena | 0,57 segundos (muy baja) | Precios más competitivos |
| Microsoft Azure | Varía según el nivel de uso | Moderada | 0,00 segundos (casi instantánea) | Latencia más baja |
| Replicate | 9,50 $ (tokens de salida) | 29 tokens/segundo | Más alta que algunos competidores | Modelo de precios sencillo |
| Anakin AI | 9,90 $/mes (modelo Freemium) | No especificado | No especificado | Constructor de aplicaciones de IA sin código |
- Together.ai: Ofrece una impresionante velocidad de salida de 70 tokens/segundo, lo que lo hace ideal para aplicaciones que requieren respuestas rápidas. Su precio es competitivo, 7,50 $ por millón de tokens, lo que supone un equilibrio entre rendimiento y coste.
- Fireworks: Destaca por tener los precios más competitivos, 3,00 $ por millón de tokens, y una latencia muy baja (0,57 segundos). Esto lo convierte en una excelente opción para proyectos sensibles a los costes que también requieren tiempos de respuesta rápidos.
- Microsoft Azure: Cuenta con la latencia más baja (casi instantánea) entre los proveedores, lo cual es crucial para las aplicaciones en tiempo real. Sin embargo, su estructura de precios varía según los niveles de uso, lo que podría dificultar la estimación de los costes.
- Replicate: Ofrece un modelo de precios sencillo de 9,50 $ por millón de tokens de salida. Si bien su velocidad de salida (29 tokens/segundo) es inferior a la de Together.ai, sigue ofreciendo un rendimiento decente para muchos casos de uso.
- Anakin AI: El enfoque de Anakin AI difiere significativamente del de los otros proveedores, centrándose en la accesibilidad y la personalización en lugar de en las métricas de rendimiento bruto. Es compatible con múltiples modelos de IA, incluidos GPT-3.5, GPT-4 y Claude 2 y 3, lo que ofrece flexibilidad en diversas tareas de IA. Comienza con un modelo freemium con planes a partir de 9,90 $/mes.
Cómo realizar llamadas API a los modelos de Llama 3.1 utilizando Apidog
Para aprovechar la potencia de Llama 3.1, tendrás que realizar llamadas API a tu proveedor elegido. Si bien el proceso exacto puede variar ligeramente entre los proveedores, los principios generales siguen siendo los mismos.
Aquí tienes una guía paso a paso sobre cómo realizar llamadas API utilizando Apidog:
- Abrir Apidog: Inicia Apidog y crea una nueva solicitud.
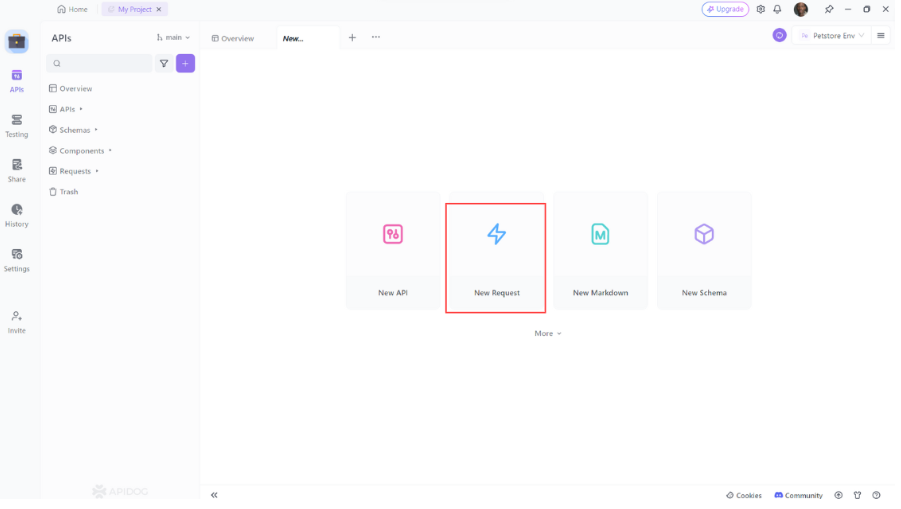
2. Selecciona el método HTTP: Elige "GET" como método de solicitud o "Post"
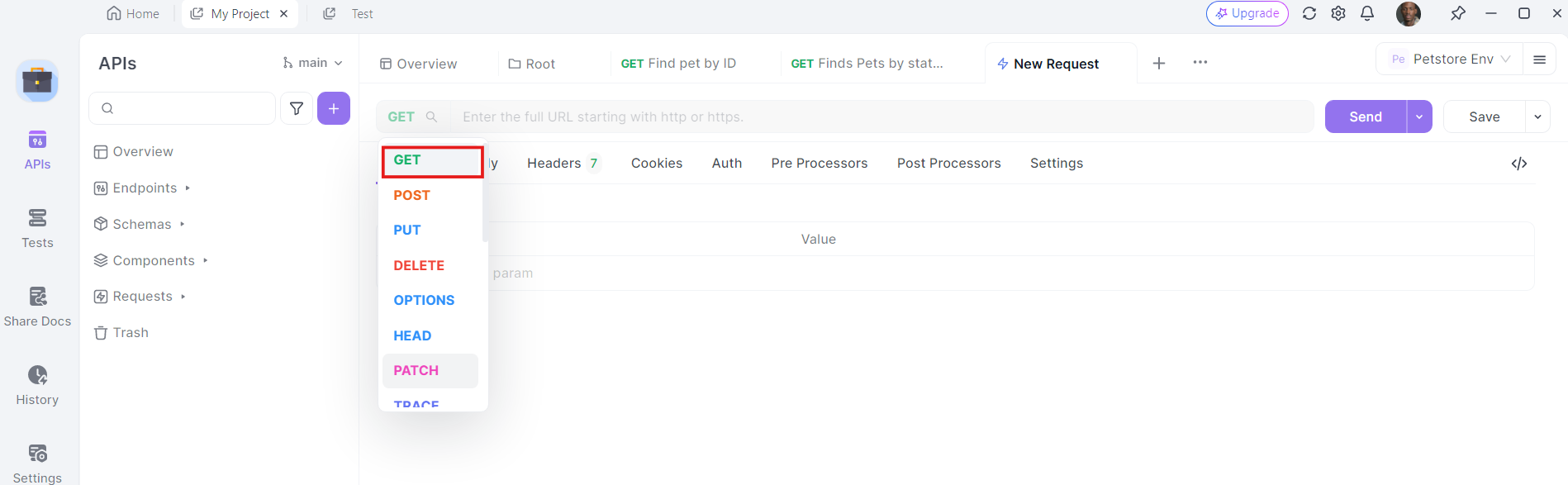
3. Introduce la URL: En el campo URL, introduce el punto final al que quieres enviar la solicitud GET.
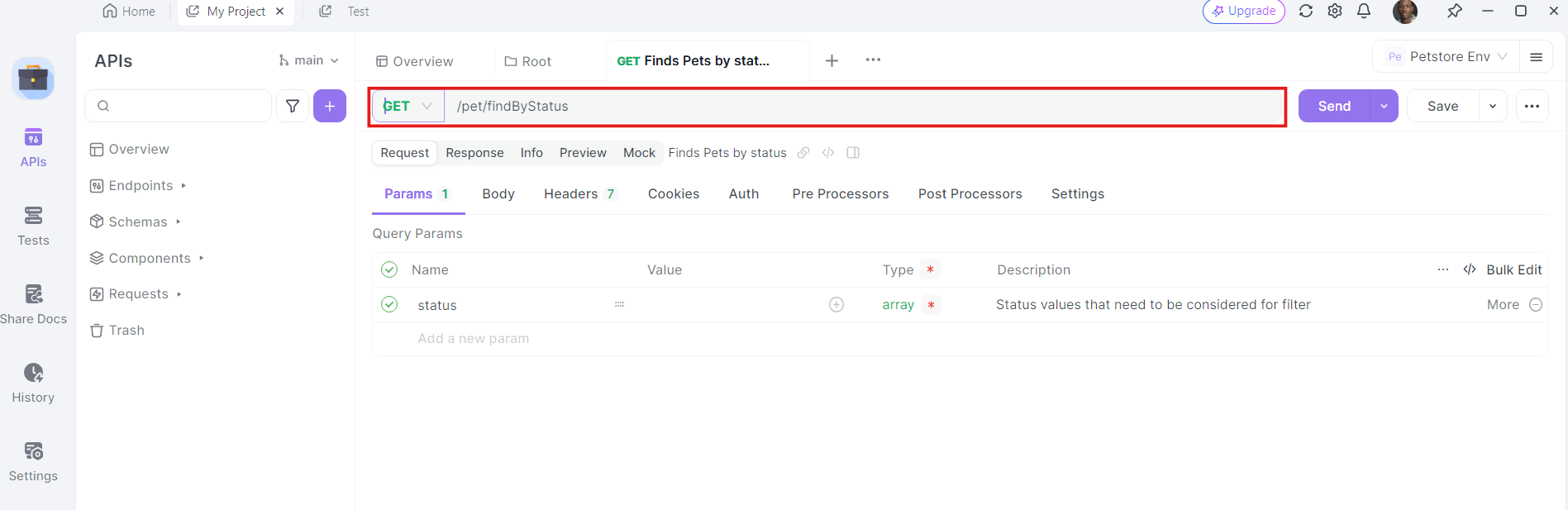
4. Añade encabezados: Ahora, es el momento de añadir los encabezados necesarios. Haz clic en la pestaña "Headers" (Encabezados) en Apidog. Aquí, puedes especificar cualquier encabezado requerido por la API. Los encabezados comunes para las solicitudes GET pueden incluir Authorization, Accept y User-Agent.
Por ejemplo:
- Authorization:
Bearer YOUR_ACCESS_TOKEN - Accept:
application/json
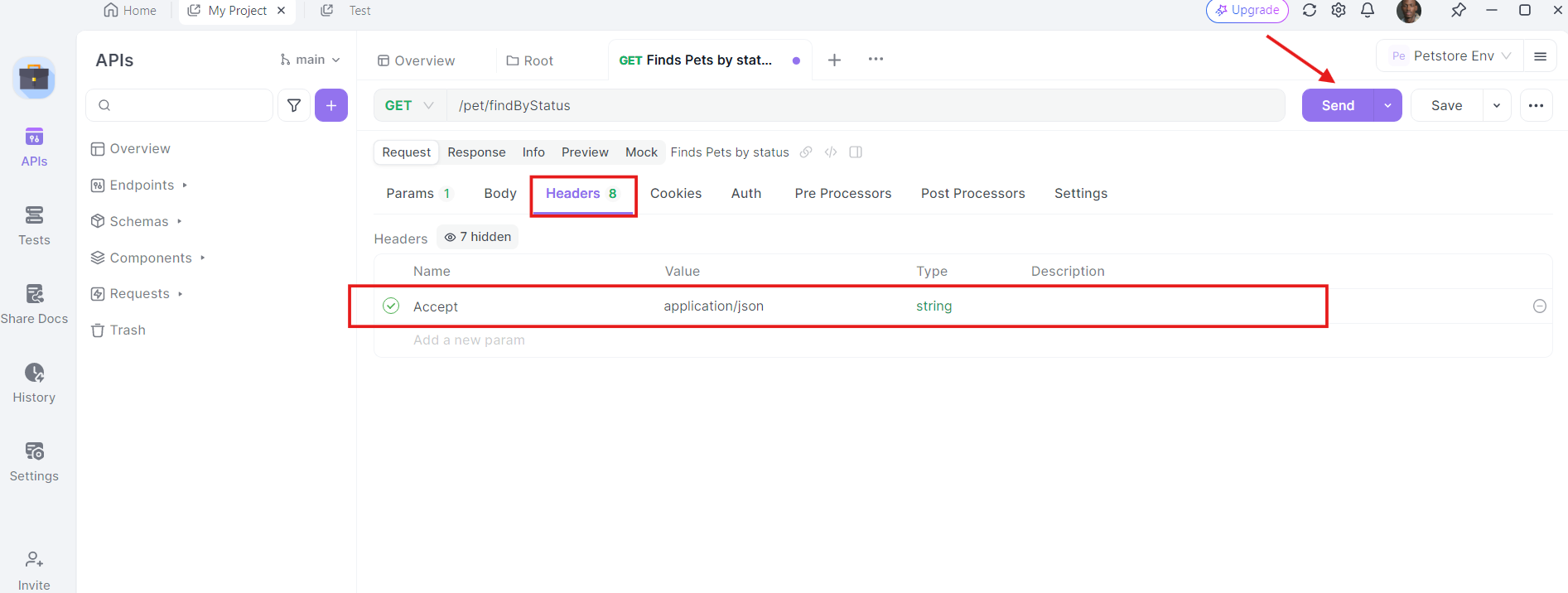
5. Envía la solicitud e inspecciona la respuesta: Con la URL, los parámetros de consulta y los encabezados en su lugar, ahora puedes enviar la solicitud API. Haz clic en el botón "Send" (Enviar) y Apidog ejecutará la solicitud. Verás la respuesta mostrada en la sección de respuesta.
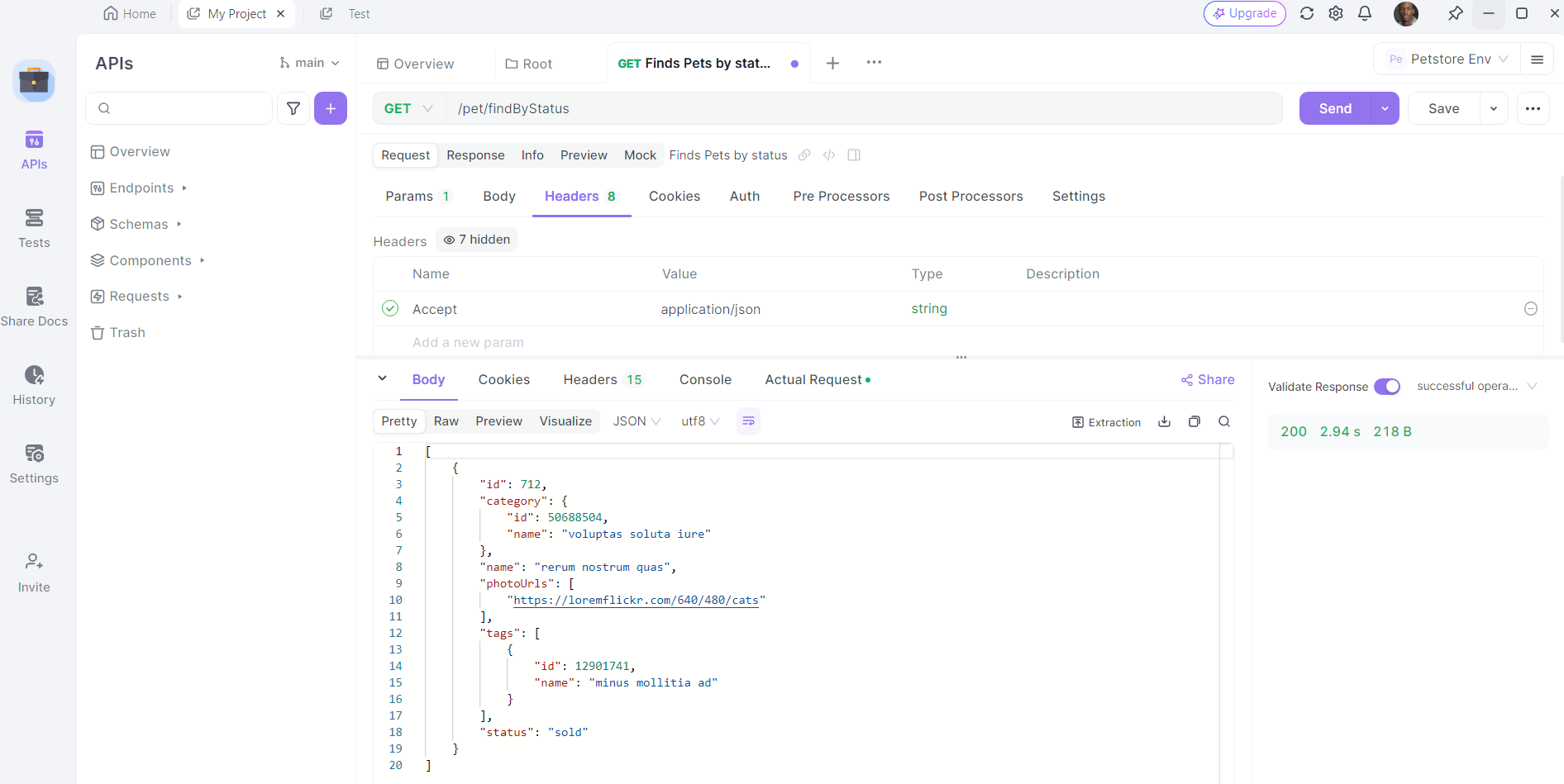
Una vez que se envía la solicitud, Apidog mostrará la respuesta del servidor. Puedes ver el código de estado, los encabezados y el cuerpo de la respuesta. Esto es invaluable para depurar y verificar que tus llamadas API estén funcionando como se espera.
Prácticas recomendadas para utilizar la API de Llama 3.1
Cuando trabajes con la API de Llama 3.1, ten en cuenta estas prácticas recomendadas:
- Implementar la transmisión: Para respuestas más largas, es posible que desees implementar la transmisión para recibir el texto generado en fragmentos en tiempo real. Esto puede mejorar la experiencia del usuario para las aplicaciones que requieren retroalimentación inmediata.
- Respetar los límites de velocidad: Ten en cuenta y respeta los límites de velocidad establecidos por tu proveedor de API para evitar interrupciones del servicio.
- Implementar el almacenamiento en caché: Para las indicaciones o consultas de uso frecuente, implementa un sistema de almacenamiento en caché para reducir las llamadas API y mejorar los tiempos de respuesta.
- Supervisar el uso: Realiza un seguimiento de tu uso de la API para administrar los costes y asegurarte de que estás dentro de tu cuota asignada.
- Seguridad: Nunca expongas tu clave API en el código del lado del cliente. Siempre realiza llamadas API desde un entorno de servidor seguro.
- Filtrado de contenido: Implementa el filtrado de contenido tanto en las indicaciones de entrada como en las salidas generadas para garantizar un uso adecuado del modelo.
- Ajuste fino: Considera la posibilidad de ajustar el modelo con datos específicos del dominio si estás trabajando en aplicaciones especializadas.
- Control de versiones: Realiza un seguimiento de la versión específica del modelo Llama 3.1 que estás utilizando, ya que las actualizaciones pueden afectar el comportamiento y las salidas del modelo.
Casos de uso en el mundo real
Veamos algunos casos de uso en el mundo real en los que la integración de Llama 3.1 con una API puede cambiar las reglas del juego:
1. Análisis de sentimientos
Si estás ejecutando un proyecto de análisis de sentimientos, Llama 3.1 puede ayudarte a clasificar el texto como positivo, negativo o neutro. Al integrarlo con una API, puedes automatizar el análisis de grandes volúmenes de datos, como reseñas de clientes o publicaciones en redes sociales.
2. Chatbots
¿Estás construyendo un chatbot? Las capacidades de procesamiento del lenguaje natural de Llama 3.1 pueden mejorar la comprensión y las respuestas de tu chatbot. Al utilizar una API, puedes integrarlo sin problemas con tu marco de chatbot y proporcionar interacciones en tiempo real.
3. Reconocimiento de imágenes
Para los proyectos de visión artificial, Llama 3.1 puede realizar tareas de reconocimiento de imágenes. Al aprovechar una API, puedes cargar imágenes, obtener clasificaciones en tiempo real e integrar los resultados en tu aplicación.
Solución de problemas comunes
A veces las cosas no salen según lo planeado. Estos son algunos problemas comunes que puedes encontrar y cómo solucionarlos:
1. Errores de autenticación
Si recibes errores de autenticación, comprueba tu clave API y asegúrate de que esté configurada correctamente en Apidog.
2. Problemas de red
Los problemas de red pueden provocar el fallo de las llamadas API. Asegúrate de que tu conexión a Internet sea estable e inténtalo de nuevo. Si el problema persiste, consulta la página de estado del proveedor de la API para ver si hay alguna interrupción.
3. Limitación de velocidad
Los proveedores de API suelen aplicar límites de velocidad para evitar el abuso. Si superas el límite, tendrás que esperar antes de realizar más solicitudes. Considera la posibilidad de implementar una lógica de reintento con retroceso exponencial para gestionar la limitación de velocidad con elegancia.
Ingeniería de prompts con Llama 3.1 405B
Para obtener los mejores resultados de Llama 3.1 405B, tendrás que experimentar con diferentes prompts y parámetros. Ten en cuenta factores como:
- Ingeniería de prompts: Elabora prompts claros y específicos para guiar la salida del modelo.
- Temperatura: Ajusta este parámetro para controlar la aleatoriedad de la salida.
- Tokens máximos: Establece un límite adecuado para la longitud del texto generado.
Conclusión
Llama 3.1 405B representa un avance significativo en el campo de los modelos de lenguaje grandes, que ofrece capacidades sin precedentes en un paquete de código abierto. Al aprovechar la potencia de este modelo a través de las API proporcionadas por varios proveedores de la nube, los desarrolladores y las empresas pueden desbloquear nuevas posibilidades en las aplicaciones impulsadas por la IA.
El futuro de la IA es abierto, y con herramientas como Llama 3.1 a nuestra disposición, las posibilidades están limitadas solo por nuestra imaginación e ingenio. A medida que explores y experimentes con este potente modelo, no solo estás utilizando una herramienta, sino que estás participando en la revolución en curso de la inteligencia artificial, ayudando a dar forma al futuro de cómo interactuamos y aprovechamos la inteligencia de las máquinas.


