
Ejecutar Gemma 3 localmente con Ollama te da control total sobre tu entorno de IA sin depender de servicios en la nube. Esta guía te explica cómo configurar Ollama, descargar Gemma 3 y ponerlo en marcha en tu máquina.
Empecemos.
¿Por qué ejecutar Gemma 3 localmente con Ollama?
“¿Por qué molestarse en ejecutar Gemma 3 localmente?” Bueno, hay algunas razones convincentes. Por un lado, la implementación local te da control total sobre tus datos y privacidad, sin necesidad de enviar información confidencial a la nube. Además, es rentable, ya que evitas las tarifas de uso de la API en curso. Además, la eficiencia de Gemma 3 significa que incluso el modelo 27B puede ejecutarse en una sola GPU, lo que lo hace accesible para desarrolladores con hardware modesto.
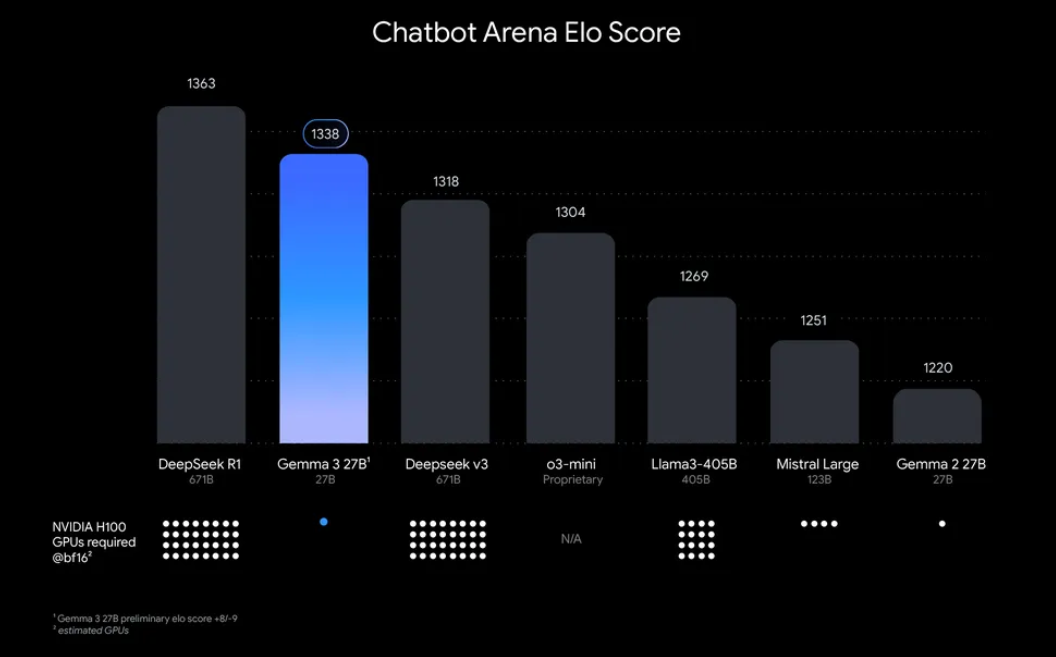
Ollama, una plataforma ligera para ejecutar modelos de lenguaje grandes (LLM) localmente, simplifica este proceso. Empaqueta todo lo que necesitas (pesos del modelo, configuraciones y dependencias) en un formato fácil de usar. Esta combinación de Gemma 3 y Ollama es perfecta para experimentar, construir aplicaciones o probar flujos de trabajo de IA en tu máquina. ¡Así que, arremanguémonos y empecemos!
Qué necesitarás para ejecutar Gemma 3 con Ollama
Antes de que nos lancemos a la configuración, asegúrate de tener los siguientes requisitos previos:
- Una máquina compatible: Necesitarás un ordenador con una GPU (preferiblemente NVIDIA para un rendimiento óptimo) o una CPU potente. El modelo 27B requiere recursos significativos, pero las versiones más pequeñas como 1B o 4B pueden ejecutarse en hardware menos potente.
- Ollama instalado: Descarga e instala Ollama, disponible para MacOS, Windows y Linux. Puedes obtenerlo de ollama.com.
- Habilidades básicas de línea de comandos: Interactuarás con Ollama a través del terminal o el símbolo del sistema.
- Conexión a Internet: Inicialmente, necesitarás descargar los modelos de Gemma 3, pero una vez descargados, puedes ejecutarlos sin conexión.
- Opcional: Apidog para pruebas de API: Si planeas integrar Gemma 3 con una API o probar sus respuestas programáticamente, la interfaz intuitiva de Apidog puede ahorrarte tiempo y esfuerzo.
Ahora que estás equipado, vamos a sumergirnos en el proceso de instalación y configuración.
Guía paso a paso: Instalación de Ollama y descarga de Gemma 3
1. Instala Ollama en tu máquina
Ollama facilita la implementación local de LLM, y la instalación es sencilla. Aquí te mostramos cómo:
- Para MacOS/Windows: Visita ollama.com y descarga el instalador para tu sistema operativo. Sigue las instrucciones en pantalla para completar la instalación.
- Para Linux (p. ej., Ubuntu): Abre tu terminal y ejecuta el siguiente comando:
curl -fsSL https://ollama.com/install.sh | sh
Este script detecta automáticamente tu hardware (incluidas las GPU) e instala Ollama.
Una vez instalado, verifica la instalación ejecutando:
ollama --version

Deberías ver el número de versión actual, confirmando que Ollama está listo para funcionar.
2. Extrae los modelos de Gemma 3 usando Ollama
La biblioteca de modelos de Ollama incluye Gemma 3, gracias a su integración con plataformas como Hugging Face y las ofertas de IA de Google. Para descargar Gemma 3, usa el comando ollama pull.
ollama pull gemma3

Para modelos más pequeños, puedes usar:
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
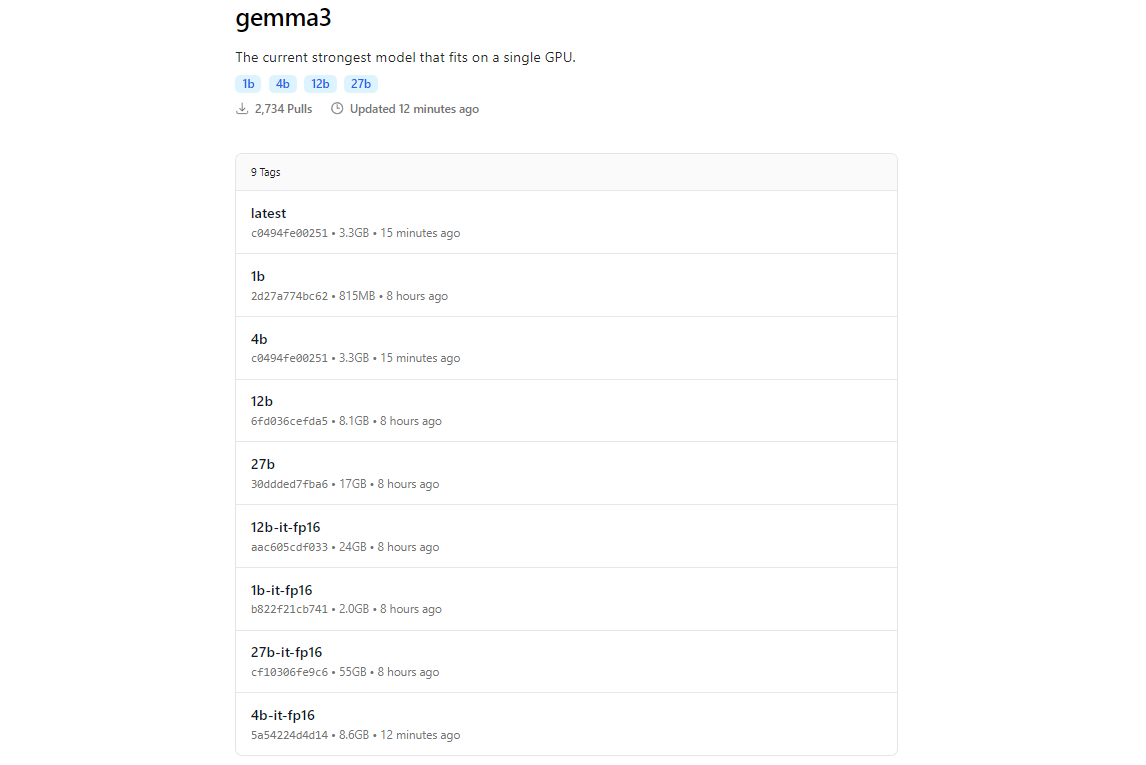
El tamaño de la descarga varía según el modelo; espera que el modelo 27B tenga varios gigabytes, así que asegúrate de tener suficiente almacenamiento. Los modelos de Gemma 3 están optimizados para la eficiencia, pero aún requieren un hardware decente para las variantes más grandes.
3. Verifica la instalación
Una vez descargado, comprueba que el modelo está disponible listando todos los modelos:
ollama list

Deberías ver gemma3 (o el tamaño que hayas elegido) en la lista. Si está ahí, ¡estás listo para ejecutar Gemma 3 localmente!
Ejecución de Gemma 3 con Ollama: Modo interactivo e integración de API
Modo interactivo: Chateando con Gemma 3
El modo interactivo de Ollama te permite chatear con Gemma 3 directamente desde el terminal. Para empezar, ejecuta:
ollama run gemma3
Verás un indicador donde puedes escribir consultas. Por ejemplo, prueba:
¿Cuáles son las características clave de Gemma 3?
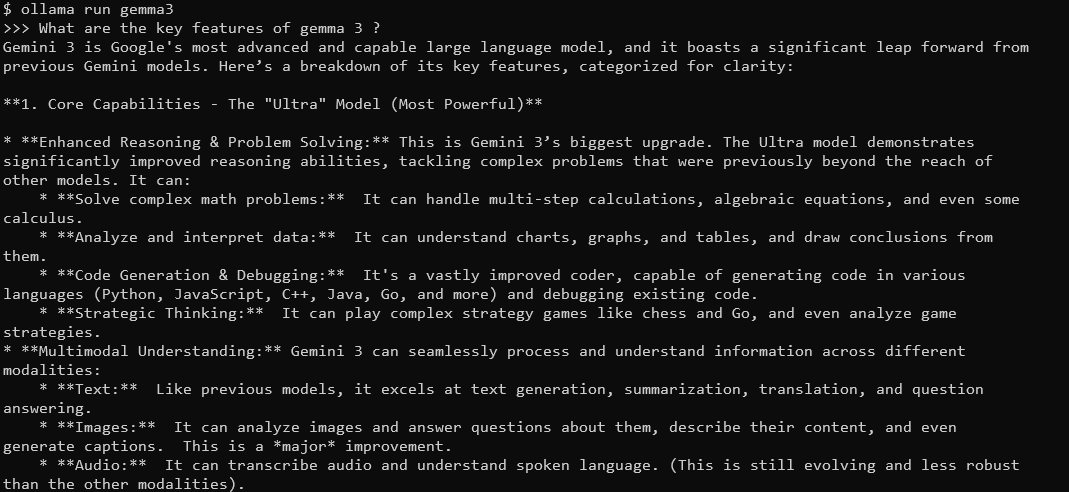
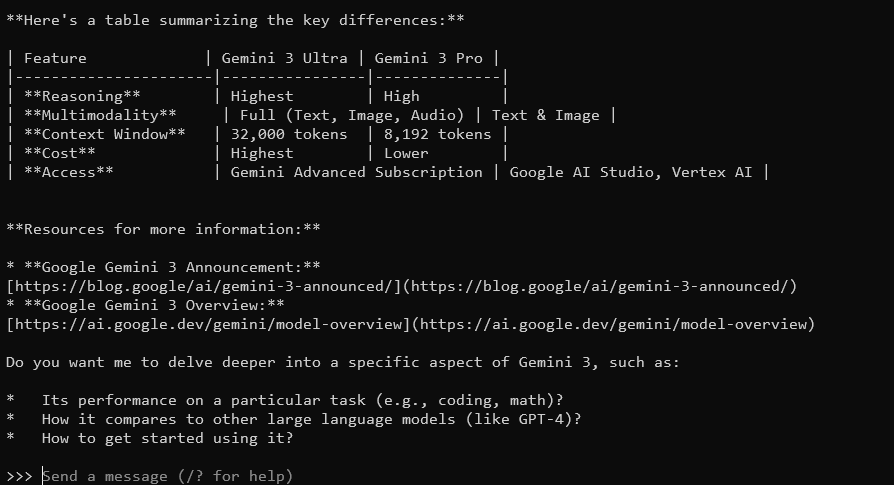
Gemma 3, con su ventana de contexto de 128K y capacidades multimodales, responderá con respuestas detalladas y conscientes del contexto. Admite más de 140 idiomas y puede procesar texto, imágenes e incluso entradas de vídeo (para ciertos tamaños).
Para salir, escribe Ctrl+D o /bye.
Integración de Gemma 3 con la API de Ollama
Si quieres construir aplicaciones o automatizar interacciones, Ollama proporciona una API que puedes usar. Aquí es donde Apidog brilla: su interfaz fácil de usar te ayuda a probar y gestionar las solicitudes de API de manera eficiente. Aquí te mostramos cómo empezar:
Inicia el servidor de Ollama: Ejecuta el siguiente comando para iniciar el servidor API de Ollama:
ollama serve
Esto inicia el servidor en localhost:11434 de forma predeterminada.
Realiza solicitudes API: Puedes interactuar con Gemma 3 a través de solicitudes HTTP. Por ejemplo, usa curl para enviar un mensaje:
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "¿Cuál es la capital de Francia?"}'
La respuesta incluirá la salida de Gemma 3, formateada como JSON.
Usa Apidog para pruebas: Descarga Apidog gratis y crea una solicitud API para probar las respuestas de Gemma 3. La interfaz visual de Apidog te permite introducir el punto final (http://localhost:11434/api/generate), establecer la carga útil JSON y analizar las respuestas sin escribir código complejo. Esto es especialmente útil para depurar y optimizar tu integración.
Guía paso a paso para usar las pruebas SSE en Apidog
Repasemos el proceso de uso de la función optimizada de pruebas SSE en Apidog, completa con las nuevas mejoras de Auto-Merge. Sigue estos pasos para configurar y maximizar tu experiencia de depuración en tiempo real.
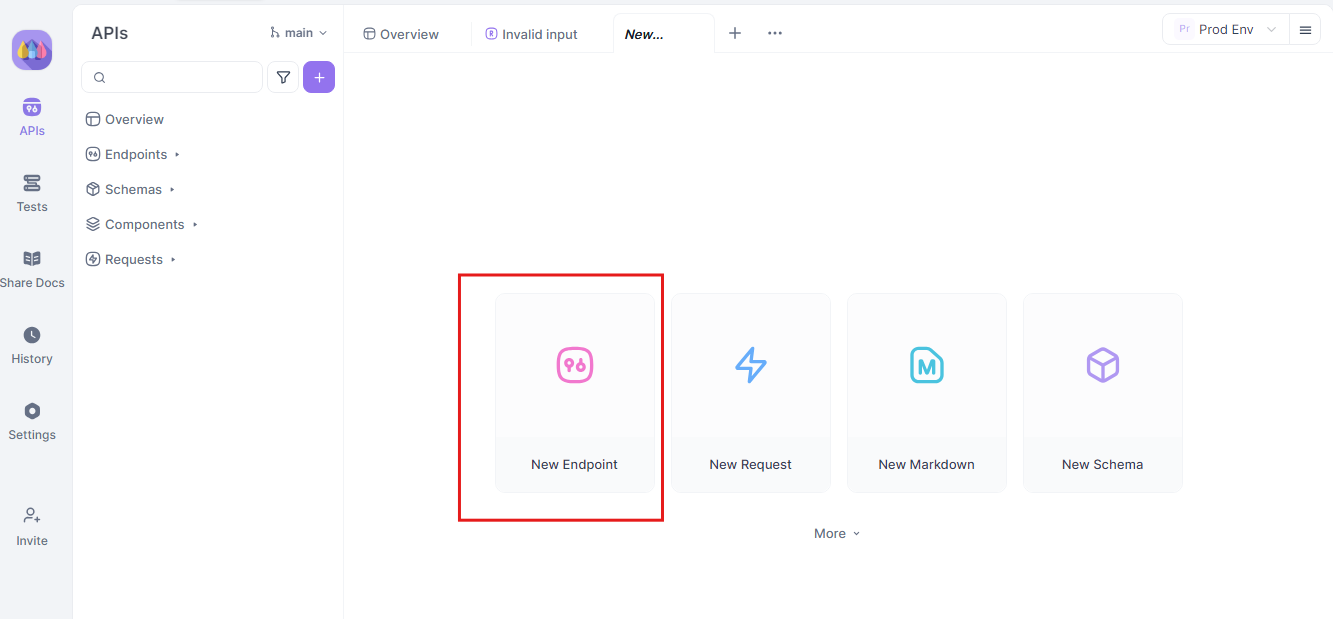
Paso 1: Crea una nueva solicitud API
Comienza lanzando un nuevo proyecto HTTP en Apidog. Añade un nuevo punto final e introduce la URL para el punto final de tu API o modelo de IA. Este es tu punto de partida para probar y depurar tus flujos de datos en tiempo real.
Paso 2: Envía la solicitud
Una vez que tu punto final esté configurado, envía la solicitud API. Observa cuidadosamente los encabezados de respuesta. Si el encabezado incluye Content-Type: text/event-stream, Apidog reconocerá e interpretará automáticamente la respuesta como un flujo SSE. Esta detección es crucial para el proceso de fusión automática posterior.

Paso 3: Supervisa la línea de tiempo en tiempo real
Después de que se establezca la conexión SSE, Apidog abrirá una vista de línea de tiempo dedicada donde todos los eventos SSE entrantes se muestran en tiempo real. Esta línea de tiempo se actualiza continuamente a medida que llegan nuevos datos, lo que te permite supervisar el flujo de datos con precisión milimétrica. La línea de tiempo no es solo un volcado de datos sin procesar, es una visualización cuidadosamente estructurada que te ayuda a ver exactamente cuándo y cómo se transmiten los datos.
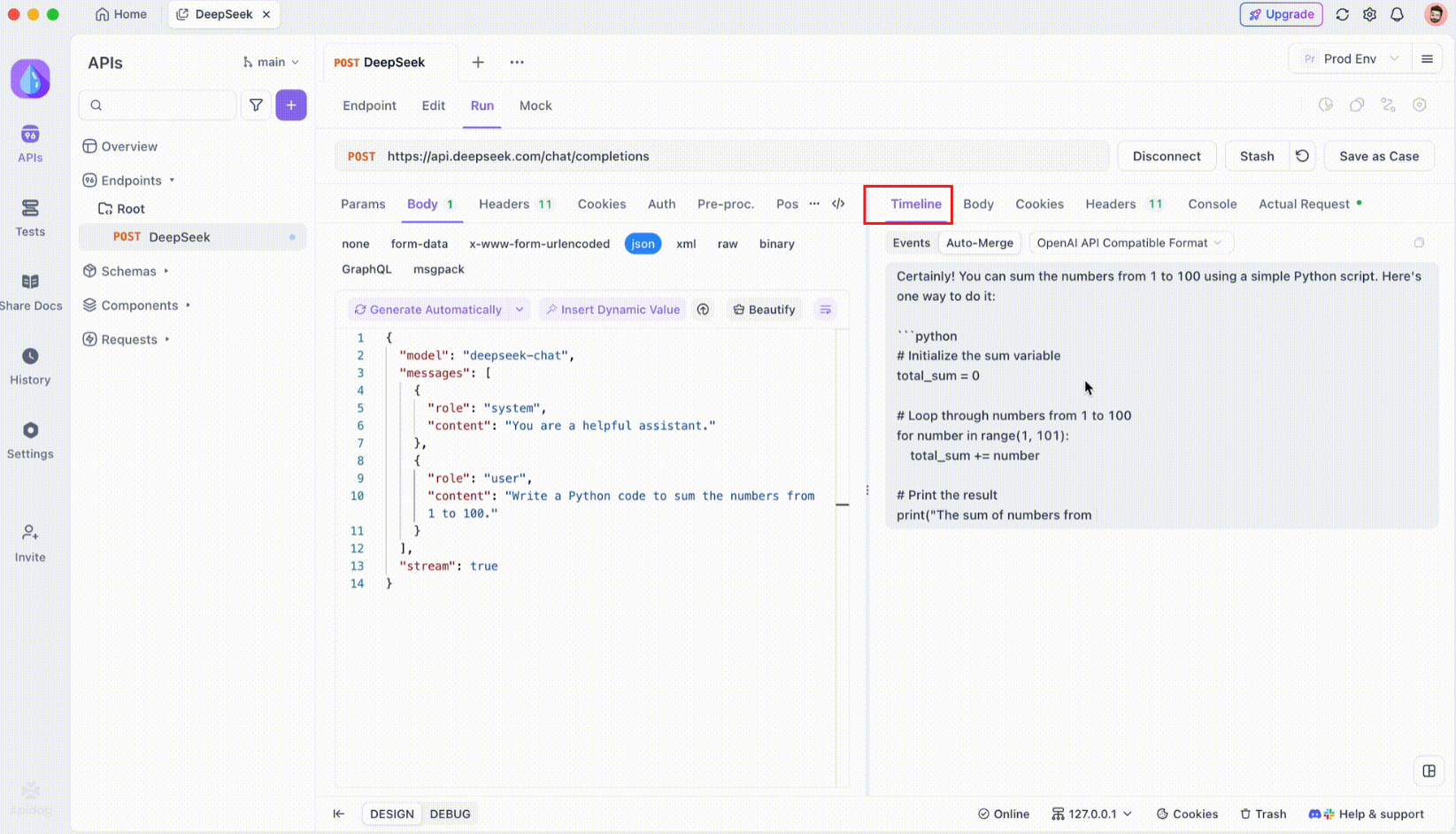
Paso 4: Mensaje de fusión automática
Aquí es donde ocurre la magia. Con las mejoras de Auto-Merge, Apidog reconoce automáticamente los formatos de modelos de IA populares y fusiona las respuestas SSE fragmentadas en una respuesta completa. Este paso incluye:
- Reconocimiento automático: Apidog comprueba si la respuesta está en un formato compatible (OpenAI, Gemini o Claude).
- Fusión de mensajes: Si se reconoce el formato, la plataforma combina automáticamente todos los fragmentos SSE, entregando una respuesta completa y sin interrupciones.
- Visualización mejorada: Para ciertos modelos de IA, como DeepSeek R1, la línea de tiempo también muestra el proceso de pensamiento del modelo, ofreciendo una capa adicional de información sobre el razonamiento detrás de la respuesta generada.
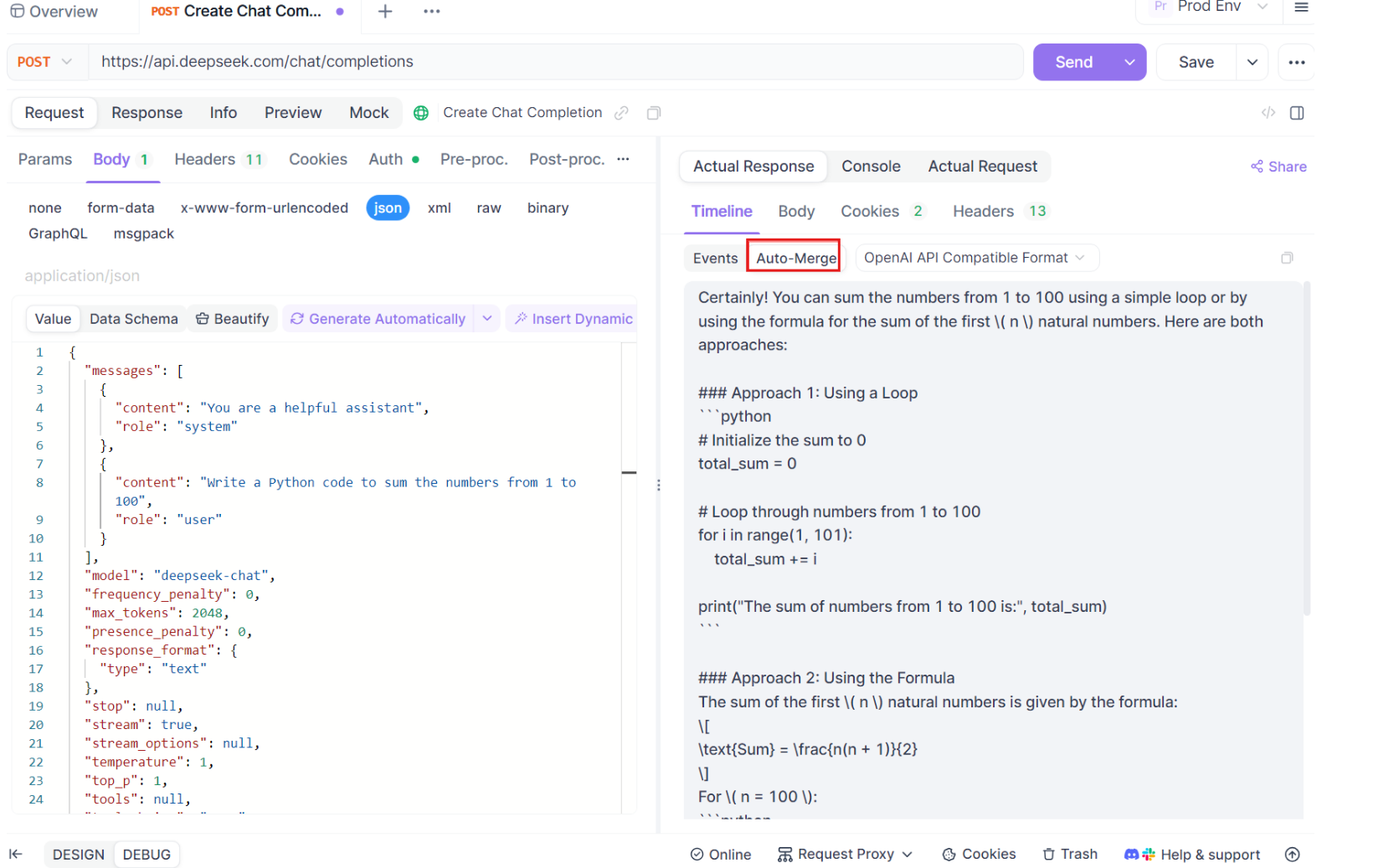
Esta función es particularmente útil cuando se trata de aplicaciones impulsadas por IA, asegurando que cada parte de la respuesta se capture y se presente en su totalidad sin intervención manual.
Paso 5: Configura las reglas de extracción de JSONPath
No todas las respuestas SSE se ajustarán automáticamente a los formatos integrados. Cuando se trata de respuestas JSON que requieren una extracción personalizada, Apidog te permite configurar reglas JSONPath. Por ejemplo, si tu respuesta SSE sin procesar contiene un objeto JSON y necesitas extraer el campo content, puedes configurar una configuración JSONPath de la siguiente manera:
- JSONPath:
$.choices[0].message.content - Explicación:
$se refiere a la raíz del objeto JSON.choices[0]selecciona el primer elemento de la matrizchoices.message.contentespecifica el campo de contenido dentro del objeto de mensaje.
Esta configuración le indica a Apidog cómo extraer los datos deseados de tu respuesta SSE, asegurando que incluso las respuestas no estándar se manejen de manera efectiva.
Conclusión
Ejecutar Gemma 3 localmente con Ollama es una forma emocionante de aprovechar las capacidades avanzadas de IA de Google sin salir de tu máquina. Desde la instalación de Ollama y la descarga del modelo hasta la interacción a través del terminal o la API, esta guía te ha guiado a través de cada paso. Con sus características multimodales, soporte multilingüe y un rendimiento impresionante, Gemma 3 es un cambio de juego para los desarrolladores y entusiastas de la IA por igual. ¡No olvides aprovechar herramientas como Apidog para pruebas e integración de API sin problemas, descárgalo gratis hoy mismo para mejorar tus proyectos de Gemma 3!
Ya sea que estés experimentando con el modelo 1B en un portátil o superando los límites del modelo 27B en una plataforma GPU, ahora estás listo para explorar las posibilidades. ¡Feliz codificación, y veamos qué cosas increíbles construyes con Gemma 3!


