
Desarrolladores y entusiastas de la IA buscan constantemente modelos eficientes que funcionen bien sin exigir recursos masivos. Google presenta Gemma 3 270M, un modelo de lenguaje compacto con 270 millones de parámetros. Este modelo se destaca como el más pequeño de la familia Gemma 3, optimizado para tareas en el dispositivo. Obtiene capacidades en generación de texto, respuesta a preguntas, resumen y razonamiento, todo mientras mantiene las operaciones localmente.
Gemma 3 270M admite una longitud de contexto de 32.000 tokens, lo que le permite manejar entradas sustanciales de manera efectiva. Además, incorpora técnicas de cuantificación como el Entrenamiento Consciente de Cuantificación Q4_0 (QAT), reduciendo las necesidades de recursos sin sacrificar la calidad. Como resultado, se logra un rendimiento cercano al de los modelos de precisión completa, pero con menores demandas de memoria y computación.
Sin embargo, lo que hace que Gemma 3 270M sea particularmente atractivo radica en su accesibilidad. Se ejecuta en hardware estándar, incluyendo computadoras portátiles o incluso dispositivos móviles, promoviendo la privacidad y aplicaciones de baja latencia. A continuación, considere cómo este modelo encaja en las tendencias más amplias del desarrollo de la IA, donde la eficiencia impulsa la innovación.
Comprendiendo la Arquitectura de Gemma 3 270M
Google construye Gemma 3 270M sobre una arquitectura basada en transformadores, con 170 millones de parámetros para incrustaciones con un vocabulario de 256.000 tokens y 100 millones para bloques de transformadores. Esta configuración permite el soporte multilingüe y el manejo de tareas específicas. Se beneficia de técnicas como la cuantificación INT4, las incrustaciones de posición rotatorias y la atención de consulta grupal, que mejoran la velocidad y la ligereza de la inferencia.
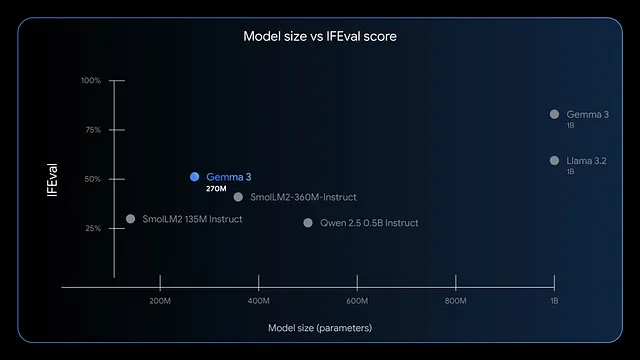
Además, el modelo sobresale en el seguimiento de instrucciones y la extracción de datos. Los puntos de referencia muestran altas puntuaciones F1 en IFEval, lo que indica un fuerte rendimiento en las tareas de evaluación. En comparación con modelos más grandes como GPT-4 o Phi-3 Mini, Gemma 3 270M prioriza la eficiencia, utilizando menos de 200 MB en modo de 4 bits en dispositivos como el M4 Max de Apple.
En consecuencia, se implementa para escenarios que exigen respuestas rápidas, como el análisis de sentimientos en tiempo real o la extracción de entidades en el sector sanitario. Sin embargo, su pequeño tamaño no limita la creatividad; se aplica a la escritura creativa o a las comprobaciones de cumplimiento financiero. De cara al futuro, evalúe las ventajas de ejecutar este modelo localmente.
Beneficios de Ejecutar Gemma 3 270M Localmente
Mejora la privacidad al mantener los datos en su dispositivo, evitando transmisiones en la nube que arriesgan la exposición. Gemma 3 270M reduce la latencia, entregando respuestas en milisegundos en lugar de segundos. Además, reduce los costos ya que evita las tarifas de suscripción para las API basadas en la nube.
Además, destaca la eficiencia energética del modelo. Consume solo el 0,75% de la batería de un Pixel 9 Pro para 25 conversaciones en modo cuantificado INT4. Esta característica es adecuada para la computación móvil y de borde, donde la energía es importante. También puede personalizar el modelo fácilmente mediante el ajuste fino con herramientas como LoRA, requiriendo datos mínimos.
Sin embargo, la ejecución local empodera a pequeños equipos o desarrolladores individuales. Puede experimentar libremente, iterando en aplicaciones como el enrutamiento de consultas de comercio electrónico o la estructuración de texto legal. A medida que avanza, verifique si su sistema cumple con los requisitos.
Requisitos del Sistema para la Inferencia de Gemma 3 270M
Gemma 3 270M exige hardware modesto, lo que lo hace accesible. Para la inferencia solo con CPU, necesita al menos 4 GB de RAM y un procesador moderno como Intel Core i5 o equivalente. Sin embargo, la aceleración de GPU mejora la velocidad; una tarjeta NVIDIA con 2 GB de VRAM es suficiente para las versiones cuantificadas.
Específicamente, en modo de 4 bits, el modelo cabe dentro de 200 MB de memoria, lo que permite ejecuciones en dispositivos con recursos limitados. Los usuarios de Apple Silicon se benefician de MLX-LM, logrando más de 650 tokens por segundo en un M4 Max. Para el ajuste fino, asigne 8 GB de RAM y una GPU con 4 GB de VRAM para manejar conjuntos de datos pequeños de manera eficiente.
Es importante destacar que funcionan sistemas operativos como Windows, macOS o Linux, pero asegúrese de tener Python 3.10+ para la compatibilidad de la biblioteca. El almacenamiento requiere aproximadamente 1 GB para los archivos del modelo. Con esto en su lugar, instala y ejecuta sin problemas. Ahora, explore los métodos de instalación.
Eligiendo la Herramienta Correcta para Ejecutar Gemma 3 270M Localmente
Varios frameworks soportan Gemma 3 270M, cada uno ofreciendo fortalezas únicas. Hugging Face Transformers proporciona flexibilidad para la escritura de scripts en Python y la integración. LM Studio ofrece una interfaz fácil de usar para la gestión de modelos.
Además, llama.cpp permite una inferencia eficiente basada en C++, perfecta para la optimización de bajo nivel. Para dispositivos Apple, MLX optimiza el rendimiento en chips de la serie M. Usted selecciona según su experiencia; los principiantes prefieren LM Studio, mientras que los desarrolladores se inclinan por Transformers.
Así, estas herramientas democratizan el acceso. En las siguientes secciones, siga las guías paso a paso para los métodos populares.
Guía Paso a Paso: Ejecutando Gemma 3 270M con Hugging Face Transformers
Comienza instalando las bibliotecas necesarias. Abra su terminal y ejecute:
pip install transformers torch
Este comando descarga Transformers y PyTorch. A continuación, importe los componentes en un script de Python:
from transformers import AutoTokenizer, AutoModelForCausalLM
Cargue el modelo y el tokenizador:
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
El device_map="auto" coloca el modelo en la GPU si está disponible. Prepare su entrada:
input_text = "Explain quantum computing in simple terms."
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
Genere la salida:
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Esto produce una explicación coherente. Para optimizar, añada cuantificación:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
La cuantificación reduce el uso de memoria. Maneje los errores asegurando el inicio de sesión de Hugging Face para modelos con acceso restringido:
from huggingface_hub import login
login(token="your_hf_token")
Obtenga el token de su cuenta de Hugging Face. Con esta configuración, ejecuta inferencias repetidamente. Sin embargo, para usuarios que no sean de Python, considere LM Studio a continuación.
Guía Paso a Paso: Ejecutando Gemma 3 270M con LM Studio
LM Studio proporciona una interfaz intuitiva. Descárguelo desde lmstudio.ai e instálelo.
Inicie la aplicación, luego busque "gemma-3-270m" en el centro de modelos.
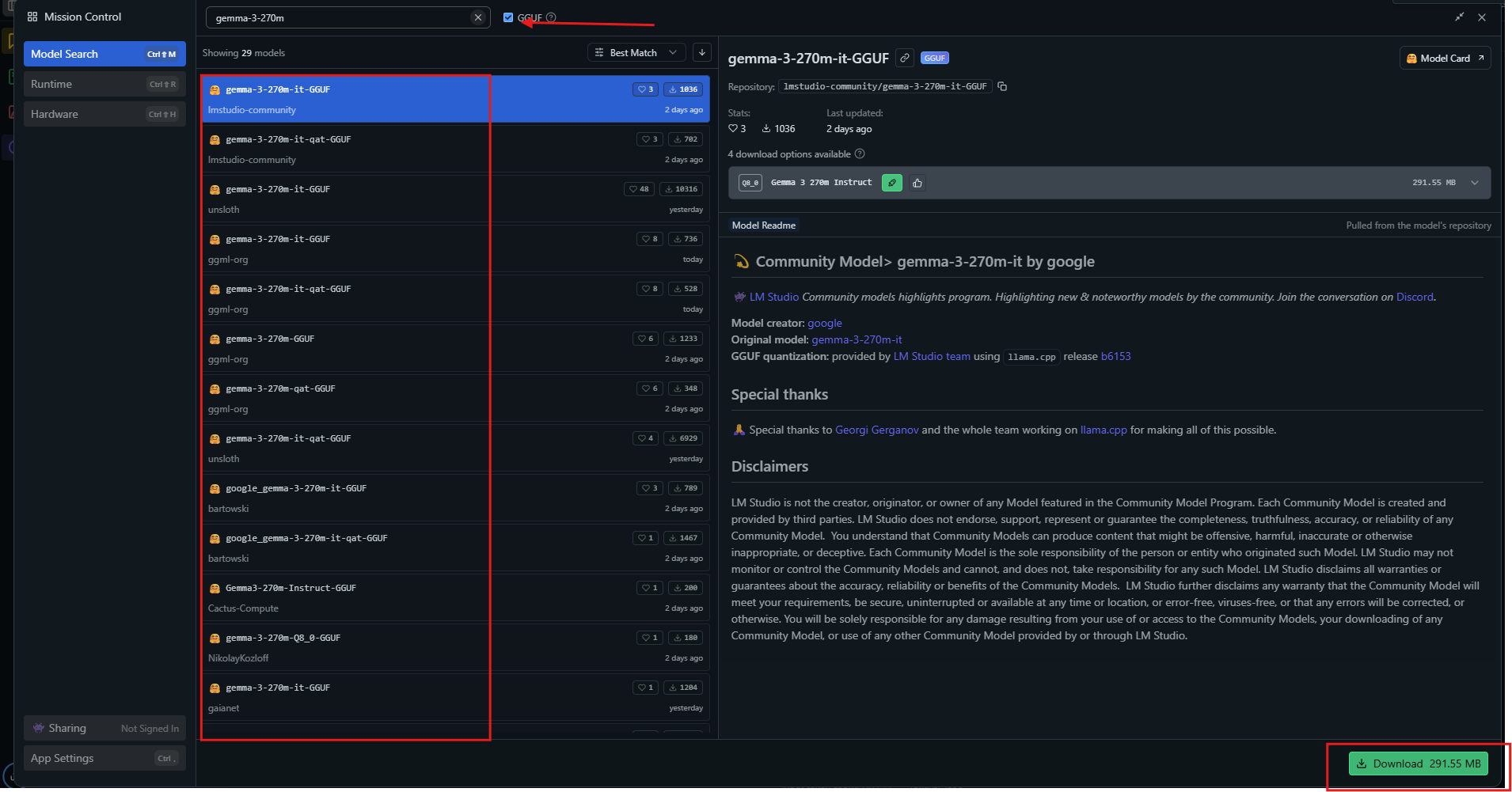
Seleccione una variante cuantificada como Q4_0 y descárguela. Una vez listo, cargue el modelo desde la barra lateral. Ajuste la configuración: establezca el contexto en 32k, la temperatura en 1.0.
Introduzca un prompt en la ventana de chat y pulse enviar. LM Studio muestra las respuestas con velocidades de token. Exporte chats o realice un ajuste fino a través de herramientas integradas.
Para uso avanzado, habilite la descarga de GPU en la configuración. LM Studio selecciona automáticamente las fuentes óptimas, asegurando la compatibilidad. Este método es adecuado para estudiantes visuales. Además, explore llama.cpp para ajustes de rendimiento.
Guía Paso a Paso: Ejecutando Gemma 3 270M con llama.cpp
llama.cpp ofrece inferencia de alta eficiencia. Clone el repositorio:
git clone https://github.com/ggerganov/llama.cpp
Compílelo:
make -j
Descargue los archivos GGUF de Hugging Face:
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"
Ejecute la inferencia:
./llama.cpp/llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "Build a simple AI app."
Especifique parámetros como --n-gpu-layers 999 para el uso completo de la GPU. llama.cpp soporta niveles de cuantificación, equilibrando velocidad y precisión. Compile con CUDA para GPUs NVIDIA:
make GGML_CUDA=1
Esto acelera el procesamiento. llama.cpp sobresale en sistemas embebidos. Ahora, aplique el modelo en ejemplos prácticos.
Ejemplos Prácticos de Uso de Gemma 3 270M Localmente
Usted crea un analizador de sentimientos. Introduzca reseñas de clientes, y el modelo las clasifica como positivas o negativas. Escríbalo en Python:
prompt = "Classify: This product is amazing!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))
Gemma 3 270M produce "Positivo". Extienda al resumen:
text = "Long article here..."
prompt = f"Summarize: {text}"
# Generate summary
Condensa el contenido de manera efectiva. Para la respuesta a preguntas, consulte:
"¿Qué causa el cambio climático?"
El modelo explica los gases de efecto invernadero. En el sector sanitario, extraiga entidades de las notas. Estos usos demuestran versatilidad. Además, ajuste fino para la especialización.
Ajuste Fino de Gemma 3 270M Localmente
El ajuste fino adapta el modelo. Use la biblioteca PEFT de Hugging Face:
pip install peft
Cargue con la configuración de LoRA:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
Prepare un conjunto de datos, luego entrene:
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()
LoRA requiere pocos datos, terminando rápidamente en hardware modesto. Guarde y recargue el adaptador. Esto mejora el rendimiento en tareas personalizadas como la predicción de movimientos de ajedrez. Sin embargo, supervise el sobreajuste.
Consejos de Optimización de Rendimiento para Gemma 3 270M
Maximice la velocidad cuantificando a 4 o 8 bits. Use el procesamiento por lotes para múltiples inferencias. Establezca la temperatura en 1.0, top_k=64, top_p=0.95 según lo recomendado.
En las GPU, habilite la precisión mixta. Para contextos largos, gestione la caché KV con cuidado. Supervise la VRAM con herramientas como nvidia-smi. Actualice las bibliotecas regularmente para optimizaciones.
En consecuencia, estos ajustes producen más de 130 tokens por segundo en hardware adecuado. Evite errores comunes como los tokens BOS dobles en los prompts. Con la práctica, logrará ejecuciones eficientes.
Conclusión
Ahora posee el conocimiento para ejecutar Gemma 3 270M localmente. Desde la configuración hasta la optimización, cada paso construye capacidad. Experimente, ajuste fino e implemente para realizar su potencial. Modelos pequeños como este tienen un gran impacto en la accesibilidad de la IA.