
Ejecutar modelos de codificación avanzados localmente permite a los desarrolladores aprovechar la IA de vanguardia sin depender de servicios en la nube. DeepCoder, un modelo de codificación de código abierto completo de 14B parámetros, ofrece un rendimiento excepcional comparable a O3-mini. Cuando se combina con Ollama, un marco de trabajo ligero para ejecutar modelos de lenguaje grandes (LLM), puedes implementar DeepCoder en tu máquina de manera eficiente. Esta guía técnica te guía a través del proceso, desde la configuración hasta la ejecución, mientras integra herramientas como Apidog para las pruebas de API.
¿Qué es DeepCoder?
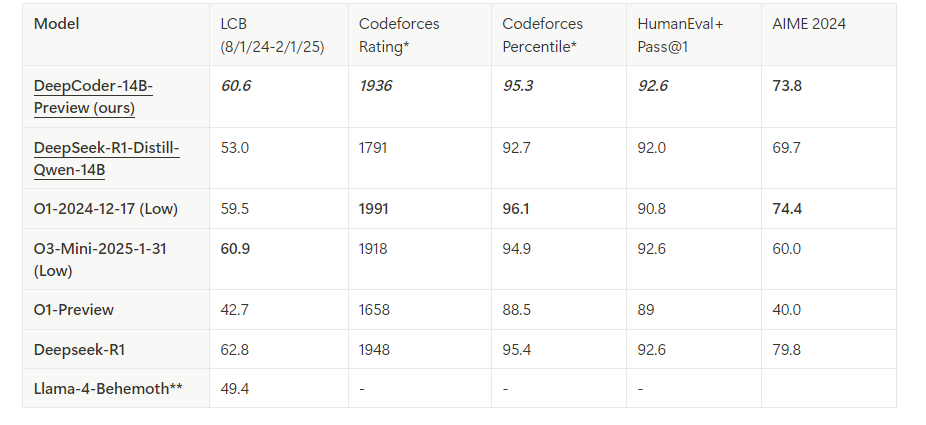
DeepCoder es un modelo de codificación de código abierto de 14B parámetros desarrollado a través de una colaboración entre Agentica y Together AI. Construido mediante el ajuste fino de Deepseek-R1-Distilled-Qwen-14B con aprendizaje por refuerzo distribuido (RL), destaca en tareas de razonamiento y generación de código. Además, existe una versión más pequeña de 1.5B para entornos con recursos limitados. A diferencia de los modelos propietarios, la naturaleza de código abierto de DeepCoder permite una transparencia y personalización completas, lo que lo convierte en un favorito entre los desarrolladores.
Ollama, por otro lado, simplifica la implementación de LLM como DeepCoder. Proporciona un tiempo de ejecución ligero y una API para una integración perfecta en los flujos de trabajo de desarrollo. Al combinar estas herramientas, desbloqueas un asistente de codificación local y potente.
Requisitos previos para ejecutar DeepCoder localmente
Antes de continuar, asegúrate de que tu sistema cumple con los requisitos. Esto es lo que necesitas:
Hardware:
- Una máquina con al menos 32 GB de RAM (se recomiendan 64 GB para el modelo de 14B).
- Una GPU moderna (por ejemplo, NVIDIA RTX 3090 o superior) con 24 GB+ de VRAM para un rendimiento óptimo.
- Alternativamente, una CPU con suficientes núcleos (por ejemplo, Intel i9 o AMD Ryzen 9) funciona para el modelo de 1.5B.
Software:
- Sistema operativo: Linux (Ubuntu 20.04+), macOS o Windows (a través de WSL2).
- Git: Para clonar repositorios.
- Docker (opcional): Para la implementación en contenedores.
- Python 3.9+: Para scripting e interacciones de API.
Dependencias:
- Ollama: Instalado y configurado.
- Archivos del modelo DeepCoder: Descargados de la biblioteca oficial de Ollama.
Con estos en su lugar, estás listo para instalar y configurar el entorno.
Paso 1: Instala Ollama en tu máquina
Ollama sirve como la columna vertebral para ejecutar DeepCoder localmente. Sigue estos pasos para instalarlo:
Descarga Ollama:
Visita el sitio web oficial de Ollama o utiliza un administrador de paquetes. Para Linux, ejecuta:
curl -fsSL https://ollama.com/install.sh | sh
En macOS, usa Homebrew:
brew install ollama
Verifica la instalación:
Comprueba la versión para confirmar que Ollama se instaló correctamente:
ollama --version

Inicia el servicio Ollama:
Inicia Ollama en segundo plano:
ollama serve &
Esto ejecuta el servidor en localhost:11434, exponiendo una API para las interacciones del modelo.
Ollama ahora está operativo. A continuación, obtendrás el modelo DeepCoder.
Paso 2: Descarga DeepCoder de la biblioteca de Ollama
DeepCoder está disponible en la biblioteca de modelos de Ollama. Aquí te mostramos cómo obtenerlo:
Obtén DeepCoder:
Descarga el modelo de 14B (o 1.5B para configuraciones más ligeras):
ollama pull deepcoder

Este comando obtiene la última versión etiquetada. Para una etiqueta específica, usa:
ollama pull deepcoder:14b-preview
Supervisa el progreso de la descarga:
El proceso transmite actualizaciones, mostrando resúmenes de archivos y el estado de finalización. Espera una descarga de varios gigabytes para el modelo de 14B, así que asegúrate de tener una conexión a Internet estable.
Verifica la instalación:
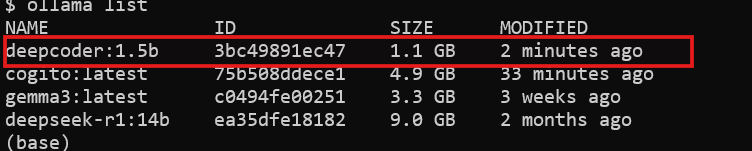
Comprueba si DeepCoder está disponible:
ollama list
Verás deepcoder listado entre los modelos instalados.
Con DeepCoder descargado, estás listo para ejecutarlo.
Paso 3: Ejecuta DeepCoder localmente con Ollama
Ahora, ejecuta DeepCoder y prueba sus capacidades:
Inicia DeepCoder:
Inicia el modelo en una sesión interactiva:
ollama run deepcoder
Esto abre un mensaje donde puedes ingresar consultas de codificación.
Ajusta los parámetros (opcional):
Para un uso avanzado, ajusta la configuración como la temperatura a través de un archivo de configuración o una llamada API (que se tratará más adelante).
DeepCoder ahora se está ejecutando localmente. Sin embargo, para integrarlo en los flujos de trabajo, usarás su API.
Paso 4: Interactúa con DeepCoder a través de la API de Ollama
Ollama expone una API RESTful para el acceso programático. Aquí te mostramos cómo aprovecharla:
Comprueba la disponibilidad de la API:
Asegúrate de que el servidor Ollama se esté ejecutando:
curl http://localhost:11434
Una respuesta confirma que el servidor está activo.
Envía una solicitud:
Usa curl para consultar DeepCoder:
curl http://localhost:11434/api/generate -d '{
"model": "deepcoder",
"prompt": "Generate a REST API endpoint in Flask",
"stream": false
}'
La respuesta incluye el código generado, como:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api/data', methods=['GET'])
def get_data():
return jsonify({"message": "Hello, World!"})
if __name__ == "__main__":
app.run(debug=True)
Intégralo con Python:
Usa la biblioteca requests de Python para una interacción más limpia:
import requests
url = "http://localhost:11434/api/generate"
payload = {
"model": "deepcoder",
"prompt": "Write a Node.js Express API",
"stream": False
}
response = requests.post(url, json=payload)
print(response.json()["response"])
La API desbloquea el potencial de DeepCoder para la automatización y la integración.
Paso 5: Mejora las pruebas de API con Apidog
DeepCoder sobresale en la generación de código API, pero probar esas API es crucial. Apidog simplifica este proceso:
Instala Apidog:
Descarga e instala Apidog desde su sitio oficial.
Prueba la API generada:
Toma el punto final de Flask de antes. En Apidog:
- Crea una nueva solicitud.
- Establece la URL en
http://localhost:5000/api/datay envía una solicitud GET.
- Verifica la respuesta:
{"message": "Hello, World!"}.
Automatiza las pruebas:
Usa el scripting de Apidog para automatizar la validación, asegurando que la salida de DeepCoder cumpla con las expectativas.
Apidog une la brecha entre la generación de código y la implementación, mejorando la productividad.
Paso 6: Optimiza el rendimiento de DeepCoder
Para maximizar la eficiencia, ajusta la configuración de DeepCoder:
Aceleración de GPU:
Asegúrate de que Ollama descarga la computación a tu GPU. Comprueba con:
nvidia-smi
El uso de la GPU indica una aceleración exitosa.
Gestión de la memoria:
Para el modelo de 14B, asigna suficiente VRAM. Ajusta el espacio de intercambio en Linux si es necesario:
sudo fallocate -l 32G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
Cuantificación del modelo:
Usa una cuantificación más pequeña (por ejemplo, 4 bits) para el modelo de 1.5B:
ollama pull deepcoder:1.5b-q4
Estos ajustes aseguran que DeepCoder se ejecute sin problemas en tu hardware.
¿Por qué elegir DeepCoder con Ollama?
Ejecutar DeepCoder localmente ofrece distintas ventajas:
- Privacidad: Mantén el código confidencial fuera de los servidores en la nube.
- Costo: Evita las tarifas de suscripción.
- Personalización: Adapta el modelo a tus necesidades.
Emparejarlo con el marco de trabajo ligero de Ollama y las capacidades de prueba de Apidog crea un ecosistema de desarrollo potente y autónomo.
Conclusión
Configurar DeepCoder localmente con Ollama es sencillo pero transformador. Instalas Ollama, obtienes DeepCoder, lo ejecutas y lo integras a través de la API, todo en unos pocos pasos. Herramientas como Apidog mejoran aún más la experiencia al garantizar que las API generadas funcionen a la perfección. Ya seas un desarrollador individual o parte de un equipo, esta configuración ofrece un asistente de codificación robusto y de código abierto.


