
Los modelos Cogito, lanzados por DeepCogito, han ganado rápidamente atención en la comunidad de la IA por su notable capacidad para superar a modelos establecidos como LLaMA y DeepSeek en varias escalas. Estos modelos de código abierto, que van desde 3B hasta 70B parámetros, proporcionan a los desarrolladores una herramienta poderosa para explorar la superinteligencia general directamente en sus máquinas locales.
Lo que necesitas saber sobre Cogito y Ollama
Cogito representa una serie de modelos de IA de código abierto desarrollados por el equipo de DeepCogito, con un claro enfoque en lograr la superinteligencia general. Estos modelos aprovechan una técnica llamada destilación y amplificación iterada (IDA), que mejora iterativamente las capacidades de razonamiento del modelo utilizando más computación para llegar a mejores soluciones y luego destilando ese proceso en los parámetros del modelo. Disponibles en tamaños como 3B, 8B, 14B, 32B y 70B, los modelos Cogito están configurados para expandirse aún más con los próximos lanzamientos de modelos de parámetros de 109B y 400B.

Por otro lado, Ollama es un marco versátil que permite a los desarrolladores ejecutar LLMs localmente en sus máquinas, eliminando la necesidad de APIs basadas en la nube. Al admitir múltiples plataformas como MacOS, Windows y Linux, Ollama garantiza la accesibilidad para una amplia gama de usuarios. Al ejecutar Cogito localmente con Ollama, puedes experimentar con modelos avanzados de IA en el dispositivo, lo que no solo ahorra costos sino que también mejora la privacidad de los datos para aplicaciones confidenciales.

¿Por qué ejecutar Cogito localmente?
Ejecutar Cogito localmente ofrece varias ventajas para los desarrolladores. Primero, elimina la dependencia de APIs externas, lo que reduce la latencia y garantiza que tus datos permanezcan privados. Esto es particularmente importante para aplicaciones donde la seguridad de los datos es una prioridad. Además, los modelos Cogito han demostrado un rendimiento superior en comparación con competidores como LLaMA 4 Scout, incluso en escalas más pequeñas, lo que los convierte en una excelente opción para tareas de alto rendimiento.

La ejecución local también es ideal para desarrolladores que trabajan en entornos con recursos limitados o áreas con acceso limitado a Internet, ya que permite un funcionamiento perfecto sin conectividad. Además, la sencilla interfaz de línea de comandos de Ollama simplifica el proceso de gestión y ejecución de múltiples modelos, incluido Cogito. Finalmente, una configuración local permite una iteración más rápida durante el desarrollo, especialmente al probar integraciones de API, que se pueden gestionar de manera eficiente utilizando herramientas como Apidog para diseñar y depurar tus endpoints.
Requisitos previos para ejecutar Cogito con Ollama
Antes de sumergirte en el proceso de configuración, asegúrate de que tu sistema cumpla con los requisitos necesarios. Para modelos más pequeños como las versiones de parámetros de 3B u 8B, tu máquina debe tener al menos 16 GB de RAM, mientras que los modelos más grandes como el de 70B pueden requerir 64 GB o más para funcionar sin problemas. Se recomienda encarecidamente una GPU compatible, como una tarjeta NVIDIA con soporte CUDA, ya que acelera significativamente la inferencia del modelo.
También necesitarás instalar Python 3.8 o superior, ya que es una dependencia para la biblioteca Python de Ollama y otras herramientas relacionadas.
A continuación, descarga e instala Ollama desde su sitio web oficial o repositorio de GitHub, siguiendo las instrucciones específicas para tu sistema operativo. El almacenamiento es otro factor crítico: los modelos Cogito pueden variar desde unos pocos gigabytes para el modelo 3B hasta más de 100 GB para el modelo 70B, así que asegúrate de que tu sistema tenga suficiente espacio. Por último, si planeas integrar Cogito con APIs, tener Apidog instalado te ayudará a diseñar y probar tus endpoints de API de manera eficiente, asegurando una experiencia de desarrollo fluida.
Paso 1: Instala Ollama en tu máquina
El primer paso para ejecutar Cogito localmente es instalar Ollama en tu máquina. Comienza visitando el sitio web de Ollama o la página de GitHub para descargar el instalador para tu sistema operativo. Para los usuarios de MacOS y Windows, simplemente ejecuta el instalador y sigue las indicaciones en pantalla para completar la configuración. Si estás usando Linux, puedes instalar Ollama directamente ejecutando el comando :
curl -fsSL https://ollama.com/install.sh | sh en tu terminal.
Una vez que se complete la instalación, abre una terminal y escribe ollama --version para confirmar que Ollama se ha instalado correctamente.

Para asegurarte de que Ollama se está ejecutando, ejecuta ollama serve, que inicia el servidor local para la gestión de modelos. Este paso también configura la interfaz de línea de comandos de Ollama, que utilizarás para extraer y ejecutar modelos como Cogito en los siguientes pasos.
Paso 2: Extrae el modelo Cogito de la biblioteca de Ollama
Con Ollama instalado, el siguiente paso es descargar el modelo Cogito. Abre tu terminal y ejecuta el comando ollama pull cogito para obtener el modelo Cogito de la biblioteca de Ollama.

De forma predeterminada, este comando extrae la última versión del modelo Cogito, pero puedes especificar un tamaño particular utilizando una etiqueta, como ollama pull cogito:3b para el modelo de parámetro 3B. Puedes explorar los tamaños de modelo disponibles en https://ollama.com/library/cogito.
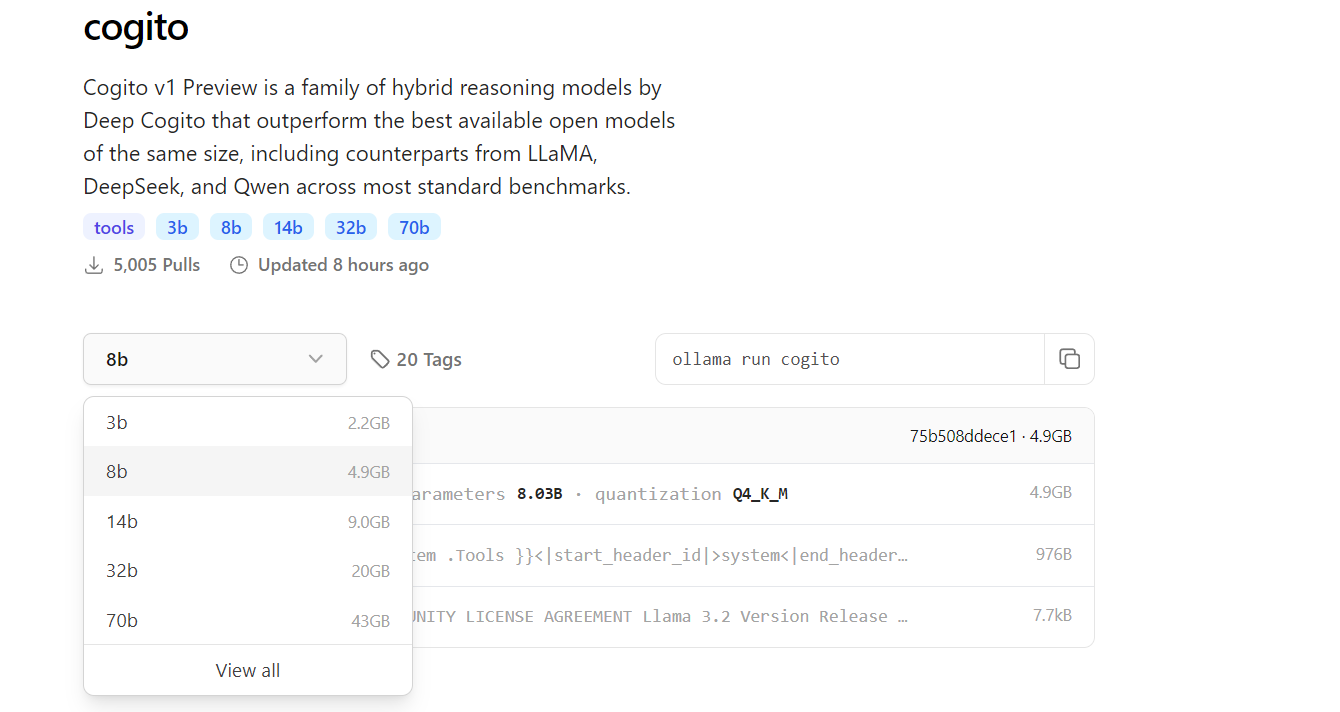
Dependiendo de tu velocidad de Internet y el tamaño del modelo, el proceso de descarga puede llevar algún tiempo; espera alrededor de 2.2 GB para el modelo 3B y hasta 43 GB para el modelo 70B. Una vez que se complete la descarga, verifica que el modelo esté disponible en tu sistema ejecutando ollama list, que muestra todos los modelos instalados. En este punto, Cogito está listo para ejecutarse localmente y puedes pasar al siguiente paso.

Paso 3: Ejecuta Cogito localmente con Ollama
Ahora que el modelo está descargado, puedes comenzar a ejecutar Cogito en tu máquina. En tu terminal, ejecuta el comando ollama run cogito para iniciar el modelo Cogito.

Paso 4: Mejora las pruebas de API con Apidog
Cogito sobresale en la generación de código API, pero probar esas APIs es crucial. Apidog simplifica este proceso:
Instala Apidog:
Descarga e instala Apidog desde su sitio oficial.
Prueba la API generada:
Toma el endpoint de Flask anterior. En Apidog:
- Crea una nueva solicitud.
- Establece la URL a
http://localhost:5000/api/datay envía una solicitud GET.
- Verifica la respuesta:
{"message": "Hello, World!"}.
Automatiza las pruebas:
Utiliza el scripting de Apidog para automatizar la validación, asegurando que la salida de DeepCoder cumpla con las expectativas.
Apidog cierra la brecha entre la generación de código y la implementación, mejorando la productividad.
Solución de problemas comunes
Ejecutar Cogito localmente puede presentar desafíos ocasionalmente, pero la mayoría de los problemas se pueden resolver con algunas comprobaciones. Si Ollama no se inicia, verifica que ningún otro proceso esté utilizando el puerto 11434; puedes finalizar el proceso en conflicto o cambiar el puerto en la configuración de Ollama. Para los errores de "falta de memoria", considera reducir el tamaño del modelo o aumentar el espacio de intercambio de tu sistema para acomodar modelos más grandes. Si el modelo no responde, asegúrate de haberlo extraído correctamente usando ollama pull cogito y de que aparezca en la salida de ollama list. Los tiempos de inferencia lentos a menudo indican que se está ejecutando solo en la CPU; verifica la compatibilidad con la GPU ejecutando nvidia-smi para confirmar que CUDA está activo.
Cuando utilices Apidog para la integración de API, pueden surgir errores debido a cargas útiles JSON incorrectas, así que verifica tu esquema en el editor de Apidog. Para diagnósticos más detallados, revisa los registros de Ollama en ~/.ollama/logs para identificar y resolver problemas rápidamente.
Conclusión
Ejecutar Cogito localmente con Ollama abre un mundo de posibilidades para los desarrolladores que buscan explorar la superinteligencia general. Siguiendo los pasos descritos en esta guía, puedes configurar Cogito en tu máquina, optimizar su rendimiento e incluso integrarlo en aplicaciones más grandes utilizando APIs gestionadas con Apidog. Ya sea que estés construyendo un sistema RAG, un asistente de codificación o una aplicación web, las capacidades avanzadas de Cogito lo convierten en una herramienta poderosa para la innovación. A medida que el equipo de DeepCogito continúa lanzando modelos más grandes y refinando sus técnicas, el potencial para el desarrollo local de IA solo crecerá, lo que permitirá a los desarrolladores crear soluciones innovadoras.


