
Si alguna vez has deseado poder hacer preguntas directamente a un PDF o manual técnico, esta guía es para ti. Hoy, construiremos un sistema de Generación Aumentada por Recuperación (RAG) utilizando DeepSeek R1, una potencia de razonamiento de código abierto, y Ollama, el marco de trabajo ligero para ejecutar modelos de IA locales.
¿Listo para potenciar tus pruebas de API? ¡No olvides echar un vistazo a Apidog! Apidog actúa como una plataforma integral para crear, gestionar y ejecutar pruebas y servidores mock, permitiéndote identificar cuellos de botella y mantener tus APIs fiables.
En lugar de hacer malabarismos con múltiples herramientas o escribir scripts extensos, puedes automatizar partes críticas de tu flujo de trabajo, lograr pipelines de CI/CD fluidos y dedicar más tiempo a pulir las características de tu producto.
Si eso suena como algo que podría simplificar tu vida, ¡dale una oportunidad a Apidog!
En esta publicación, exploraremos cómo DeepSeek R1—un modelo que rivaliza con el o1 de OpenAI en rendimiento pero cuesta un 95% menos—puede potenciar tus sistemas RAG. Analicemos por qué los desarrolladores están acudiendo en masa a esta tecnología y cómo tú puedes construir tu propio pipeline RAG con ella.
¿Cuánto Cuesta Este Sistema RAG Local?
| Componente | Costo |
|---|---|
| DeepSeek R1 1.5B | Gratis |
| Ollama | Gratis |
| PC con 16GB de RAM | $0 |
El modelo 1.5B de DeepSeek R1 brilla aquí porque:
- Recuperación enfocada: Solo 3 fragmentos de documento se introducen en cada respuesta
- Indicaciones estrictas: "No lo sé" previene las alucinaciones
- Ejecución local: Latencia cero frente a las APIs en la nube
Qué Necesitarás
Antes de codificar, configuremos nuestros kits de herramientas:
1. Ollama
Ollama te permite ejecutar modelos como DeepSeek R1 localmente.
- Descarga: https://ollama.com/
- Instala, luego abre tu terminal y ejecuta:
ollama run deepseek-r1 # Para el modelo 7B (predeterminado)
2. Variantes del Modelo DeepSeek R1
DeepSeek R1 viene en tamaños desde 1.5B hasta 671B parámetros. Para esta demostración, usaremos el modelo 1.5B—perfecto para RAG ligero:
ollama run deepseek-r1:1.5b
Consejo profesional: Los modelos más grandes como 70B ofrecen un mejor razonamiento pero requieren más RAM. ¡Comienza pequeño, luego escala!

Construyendo el Pipeline RAG: Recorrido por el Código
Paso 1: Importar Librerías
Usaremos:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
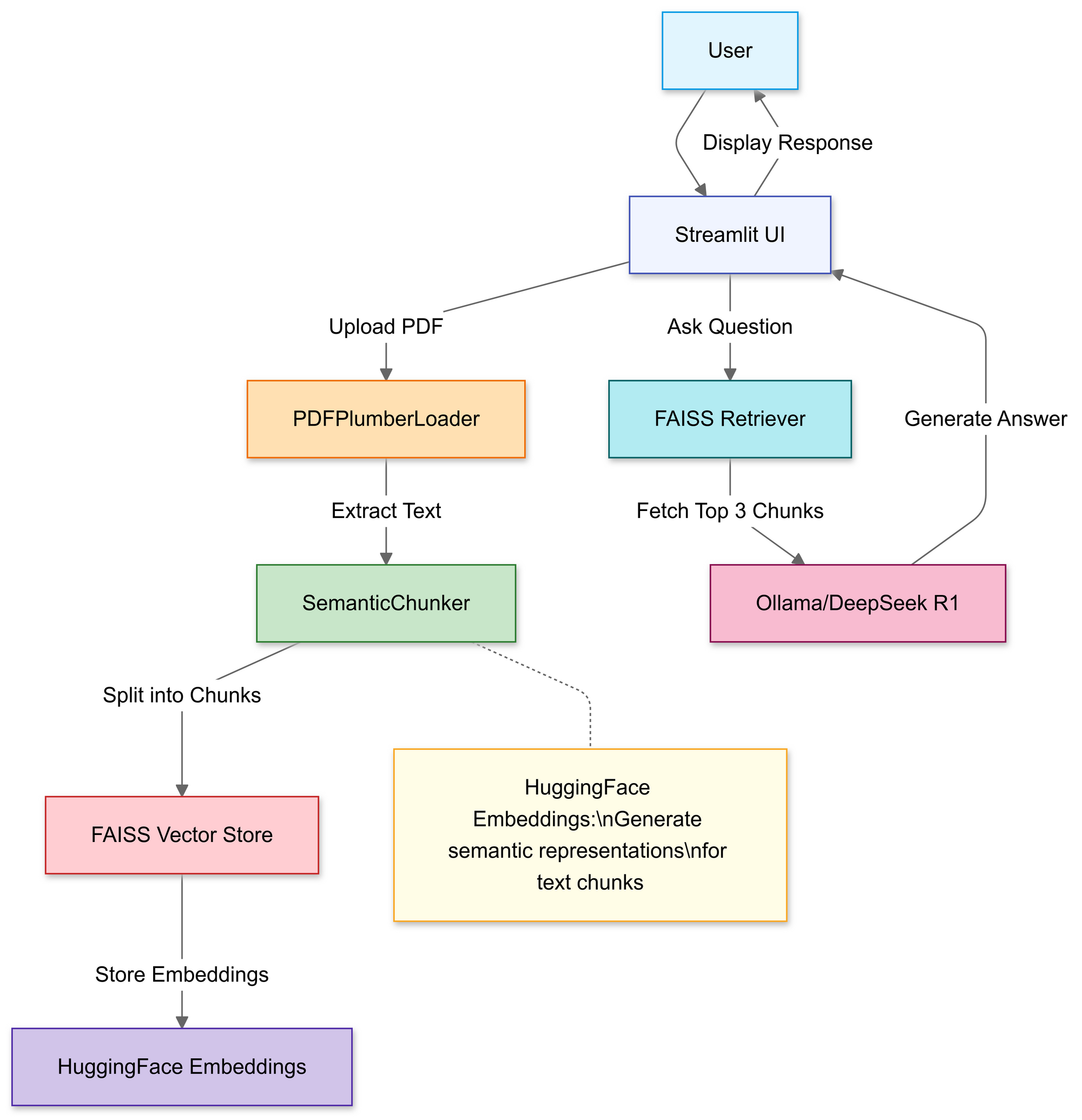
Paso 2: Cargar y Procesar PDFs
En esta sección, usas el cargador de archivos de Streamlit para permitir a los usuarios seleccionar un archivo PDF local.
# Cargador de archivos de Streamlit
uploaded_file = st.file_uploader("Cargar un archivo PDF", type="pdf")
if uploaded_file:
# Guardar PDF temporalmente
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Cargar texto del PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
Una vez cargado, la función PDFPlumberLoader extrae el texto del PDF, preparándolo para la siguiente etapa del pipeline. Este enfoque es conveniente porque se encarga de leer el contenido del archivo sin exigir un análisis manual extenso.
Paso 3: Dividir Documentos Estratégicamente
Queremos usar el RecursiveCharacterTextSplitter, el código divide el texto PDF original en segmentos más pequeños (chunks). Expliquemos los conceptos de buena división vs mala división aquí:
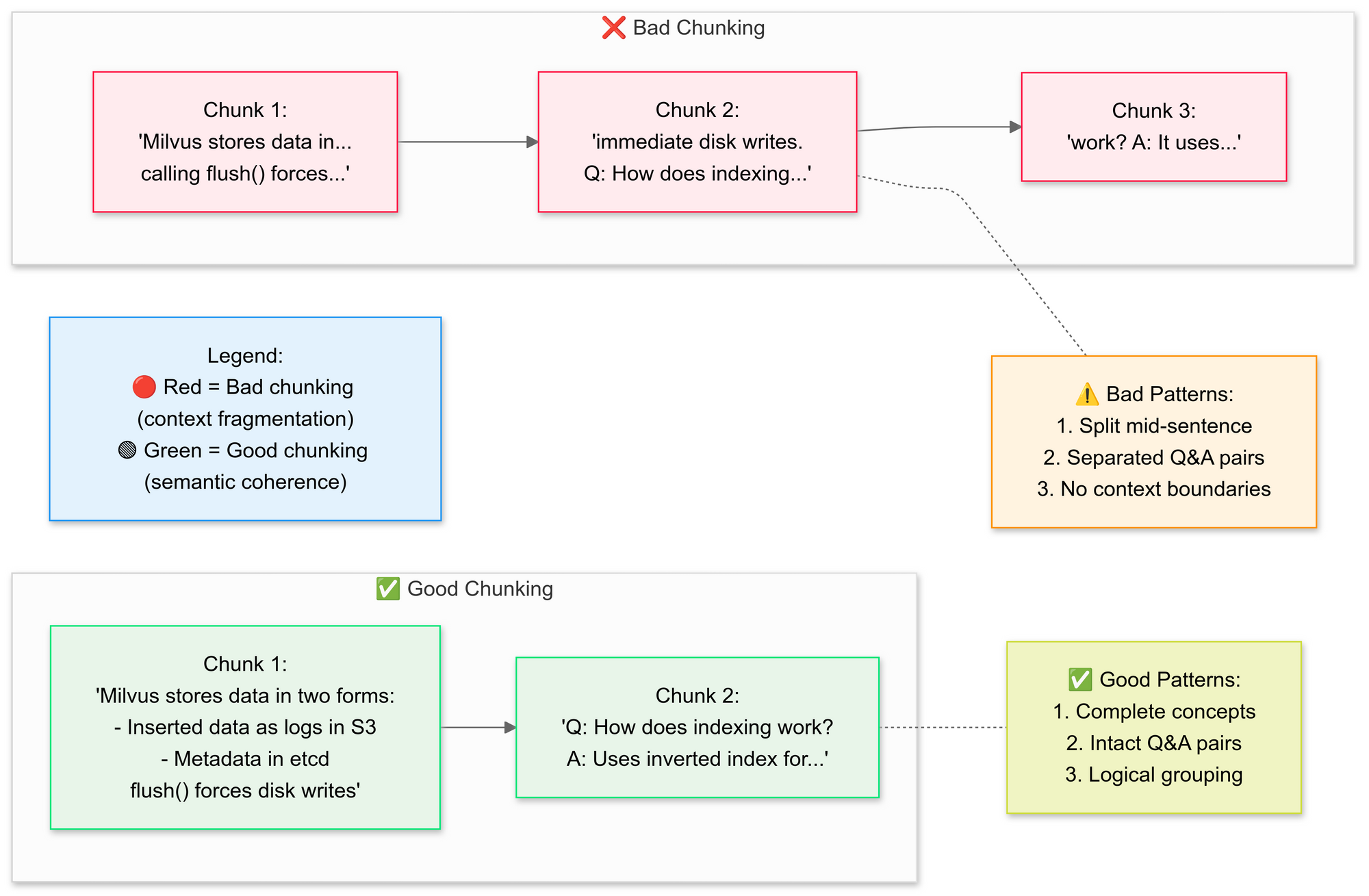
¿Por qué la división semántica?
- Agrupa oraciones relacionadas (por ejemplo, "Cómo Milvus almacena datos" permanece intacto)
- Evita dividir tablas o diagramas
# Dividir el texto en chunks semánticos
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
Este paso preserva el contexto superponiendo ligeramente los segmentos, lo que ayuda al modelo de lenguaje a responder preguntas con mayor precisión. Los chunks de documento pequeños y bien definidos también hacen que las búsquedas sean más eficientes y relevantes.
Paso 4: Crear una Base de Conocimiento Buscable
Después de la división, el pipeline genera incrustaciones vectoriales para los segmentos y los almacena en un índice FAISS.
# Generar incrustaciones
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Conectar el recuperador
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Obtener los 3 chunks principales
Esto transforma el texto en una representación numérica que es mucho más fácil de consultar. Las consultas se ejecutan posteriormente contra este índice para encontrar los chunks contextualmente más relevantes.
Paso 5: Configurar DeepSeek R1
Aquí, instancias una cadena RetrievalQA usando Deepseek R1 1.5B como el LLM local.
llm = Ollama(model="deepseek-r1:1.5b") # Nuestro modelo de 1.5B parámetros
# Elaborar la plantilla de prompt
prompt = """
1. Usa SOLO el contexto a continuación.
2. Si no estás seguro, di "No lo sé".
3. Mantén las respuestas por debajo de 4 oraciones.
Contexto: {context}
Pregunta: {question}
Respuesta:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
Esta plantilla obliga al modelo a basar las respuestas en el contenido de tu PDF. Al envolver el modelo de lenguaje con un recuperador vinculado al índice FAISS, cualquier consulta realizada a través de la cadena buscará contexto en el contenido del PDF, haciendo que las respuestas se basen en el material de origen.
Paso 6: Ensamblar la Cadena RAG
A continuación, puedes unir los pasos de carga, división y recuperación en un pipeline coherente.
# Cadena 1: Generar respuestas
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Cadena 2: Combinar chunks de documento
document_prompt = PromptTemplate(
template="Contexto:\ncontenido:{page_content}\nfuente:{source}",
input_variables=["page_content", "source"]
)
# Pipeline RAG final
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
Este es el núcleo del diseño RAG (Generación Aumentada por Recuperación), que proporciona al modelo de lenguaje grande un contexto verificado en lugar de hacer que dependa puramente de su entrenamiento interno.
Paso 7: Lanzar la Interfaz Web
Finalmente, el código usa la entrada de texto y las funciones de escritura de Streamlit para que los usuarios puedan escribir preguntas y ver las respuestas de inmediato.
# Interfaz de usuario de Streamlit
user_input = st.text_input("Hazle una pregunta a tu PDF:")
if user_input:
with st.spinner("Pensando..."):
response = qa(user_input)["result"]
st.write(response)
Tan pronto como el usuario ingresa una consulta, la cadena recupera los mejores chunks coincidentes, los introduce en el modelo de lenguaje y muestra una respuesta. Con la biblioteca langchain instalada correctamente, el código debería funcionar ahora sin activar el error de módulo faltante.
¡Pregunta y envía preguntas y obtén respuestas instantáneas!
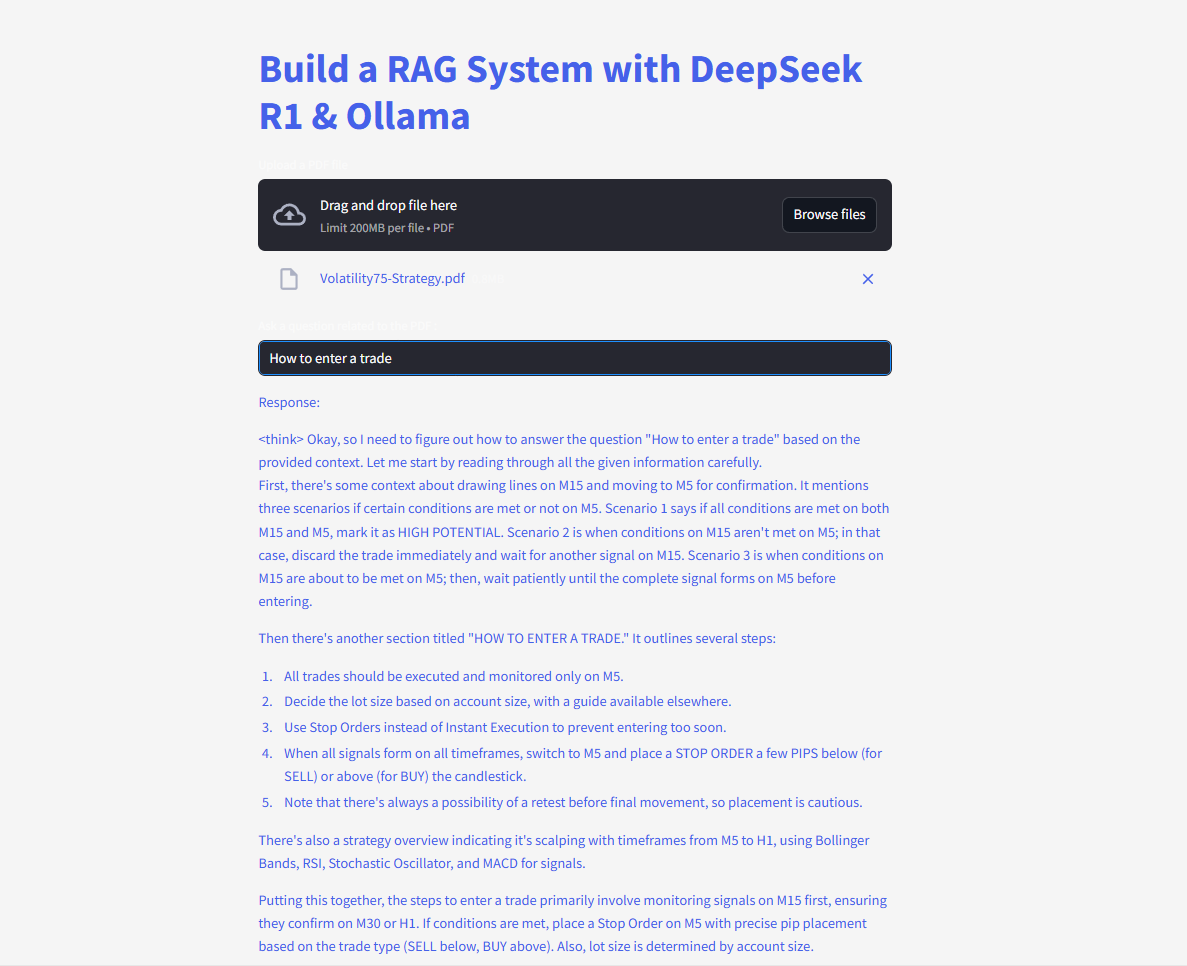
Aquí está el código completo:
El Futuro de RAG con DeepSeek
Con características como la auto-verificación y el razonamiento multi-salto en desarrollo, DeepSeek R1 está preparado para desbloquear aplicaciones RAG aún más avanzadas. Imagina una IA que no solo responde preguntas sino que debate su propia lógica—de forma autónoma.


