
Los modelos de lenguaje grandes (LLMs) como Qwen3 están revolucionando el panorama de la IA con sus impresionantes capacidades en codificación, razonamiento y comprensión del lenguaje natural. Desarrollado por el equipo de Qwen en Alibaba, Qwen3 ofrece modelos cuantizados que permiten una implementación local eficiente, haciéndolo accesible para desarrolladores, investigadores y entusiastas para ejecutar estos potentes modelos en su propio hardware. Ya sea que estés utilizando Ollama, LM Studio o vLLM, esta guía te guiará a través del proceso de configuración y ejecución local de los modelos cuantizados de Qwen3.
En esta guía técnica, exploraremos el proceso de configuración, la selección de modelos, los métodos de implementación y la integración de API. ¡Comencemos!
¿Qué son los modelos cuantizados de Qwen3?
Qwen3 es la última generación de LLMs de Alibaba, diseñada para un alto rendimiento en tareas como codificación, matemáticas y razonamiento general. Los modelos cuantizados, como los formatos BF16, FP8, GGUF, AWQ y GPTQ, reducen los requisitos computacionales y de memoria, haciéndolos ideales para la implementación local en hardware de consumo.
La familia Qwen3 incluye varios modelos:
- Qwen3-235B-A22B (MoE): Un modelo de mezcla de expertos con formatos BF16, FP8, GGUF y GPTQ-int4.
- Qwen3-30B-A3B (MoE): Otra variante MoE con opciones de cuantización similares.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): Modelos densos disponibles en formatos BF16, FP8, GGUF, AWQ y GPTQ-int8.
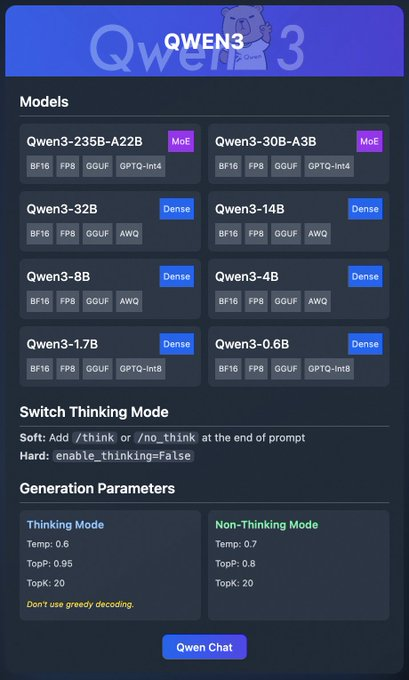
Estos modelos admiten una implementación flexible a través de plataformas como Ollama, LM Studio y vLLM, que cubriremos en detalle. Además, Qwen3 ofrece funciones como el "modo de pensamiento", que se puede activar para mejorar el razonamiento, y parámetros de generación para ajustar la calidad de la salida.
Ahora que entendemos los conceptos básicos, pasemos a los requisitos previos para ejecutar Qwen3 localmente.
Requisitos previos para ejecutar Qwen3 localmente
Antes de implementar los modelos cuantizados de Qwen3, asegúrate de que tu sistema cumpla los siguientes requisitos:
Hardware:
- Una CPU o GPU moderna (se recomiendan GPUs NVIDIA para vLLM).
- Al menos 16GB de RAM para modelos más pequeños como Qwen3-4B; 32GB o más para modelos más grandes como Qwen3-32B.
- Suficiente almacenamiento (por ejemplo, Qwen3-235B-A22B GGUF puede requerir ~150GB).
Software:
- Un sistema operativo compatible (Windows, macOS o Linux).
- Python 3.8+ para vLLM e interacciones de API.
- Docker (opcional, para vLLM).
- Git para clonar repositorios.
Dependencias:
- Instala las bibliotecas necesarias como
torch,transformersyvllm(para vLLM). - Descarga los binarios de Ollama o LM Studio desde sus sitios web oficiales.
Con estos requisitos previos en su lugar, procedamos a descargar los modelos cuantizados de Qwen3.
Paso 1: Descargar modelos cuantizados de Qwen3
Primero, necesitas descargar los modelos cuantizados de fuentes confiables. El equipo de Qwen proporciona modelos Qwen3 en Hugging Face y ModelScope
- Hugging Face: Colección Qwen3
- ModelScope: Colección Qwen3
Cómo descargar desde Hugging Face
- Visita la colección Qwen3 en Hugging Face.
- Selecciona un modelo, como Qwen3-4B en formato GGUF para una implementación ligera.
- Haz clic en el botón "Download" o usa el comando
git clonepara obtener los archivos del modelo:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- Almacena los archivos del modelo en un directorio, como
/models/qwen3-4b-gguf.
Cómo descargar desde ModelScope
- Navega a la colección Qwen3 en ModelScope.
- Elige el modelo y el formato de cuantización deseados (por ejemplo, AWQ o GPTQ).
- Descarga los archivos manualmente o utiliza su API para acceso programático.
Una vez que los modelos estén descargados, exploremos cómo implementarlos usando Ollama.
Paso 2: Implementar Qwen3 usando Ollama
Ollama proporciona una forma fácil de usar para ejecutar LLMs localmente con una configuración mínima. Soporta el formato GGUF de Qwen3, lo que lo hace ideal para principiantes.
Instalar Ollama
- Visita el sitio web oficial de Ollama y descarga el binario para tu sistema operativo.
- Instala Ollama ejecutando el instalador o siguiendo las instrucciones de la línea de comandos:
curl -fsSL https://ollama.com/install.sh | sh
- Verifica la instalación:
ollama --version
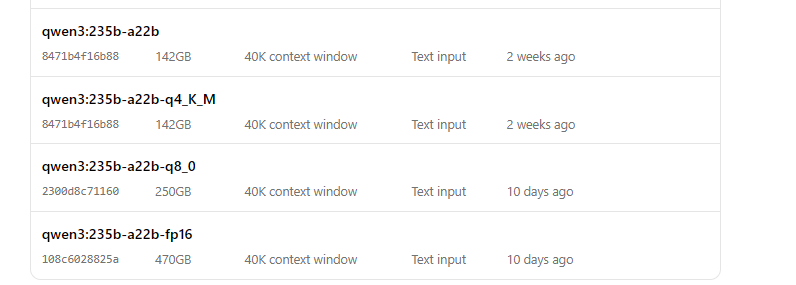
Ejecutar Qwen3 con Ollama
- Inicia el modelo:
ollama run qwen3:235b-a22b-q8_0- Una vez que el modelo esté en ejecución, puedes interactuar con él a través de la línea de comandos:
>>> Hello, how can I assist you today?
Ollama también proporciona un punto final de API local (generalmente http://localhost:11434) para acceso programático, que probaremos más adelante usando Apidog.
A continuación, exploremos cómo usar LM Studio para ejecutar Qwen3.
Paso 3: Implementar Qwen3 usando LM Studio
LM Studio es otra herramienta popular para ejecutar LLMs localmente, ofreciendo una interfaz gráfica para la gestión de modelos.
Instalar LM Studio
- Descarga LM Studio desde su sitio web oficial.
- Instala la aplicación siguiendo las instrucciones en pantalla.
- Inicia LM Studio y asegúrate de que esté en ejecución.
Cargar Qwen3 en LM Studio
En LM Studio, ve a la sección "Local Models".
Haz clic en "Add Model" y busca el modelo para descargarlo:
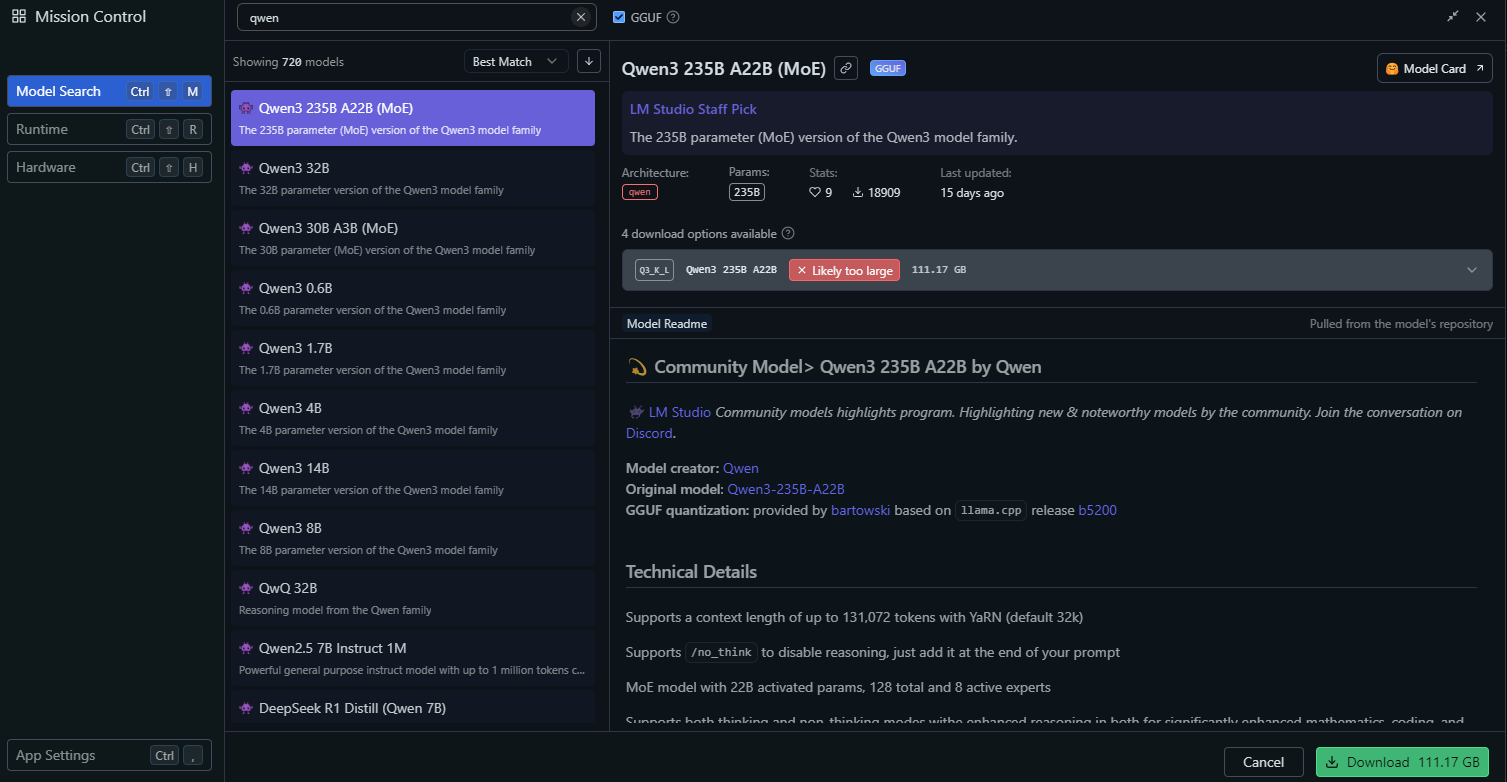
Configura los ajustes del modelo, como:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
Estos ajustes coinciden con los parámetros recomendados del modo de pensamiento de Qwen3.
Inicia el servidor del modelo haciendo clic en "Start Server". LM Studio proporcionará un punto final de API local (por ejemplo, http://localhost:1234).
Interactuar con Qwen3 en LM Studio
- Usa la interfaz de chat integrada de LM Studio para probar el modelo.
- Alternativamente, accede al modelo a través de su punto final de API, que exploraremos en la sección de prueba de API.
Con LM Studio configurado, pasemos a un método de implementación más avanzado usando vLLM.
Paso 4: Implementar Qwen3 usando vLLM
vLLM es una solución de servicio de alto rendimiento optimizada para LLMs, que soporta los modelos cuantizados FP8 y AWQ de Qwen3. Es ideal para desarrolladores que construyen aplicaciones robustas.
Instalar vLLM
- Asegúrate de que Python 3.8+ esté instalado en tu sistema.
- Instala vLLM usando pip:
pip install vllm
- Verifica la instalación:
python -c "import vllm; print(vllm.__version__)"
Ejecutar Qwen3 con vLLM
Inicia un servidor vLLM con tu modelo Qwen3
# Load and run the model:
vllm serve "Qwen/Qwen3-235B-A22B"La bandera --enable-thinking=False deshabilita el modo de pensamiento de Qwen3.
Una vez que el servidor se inicie, proporcionará un punto final de API en http://localhost:8000.
Configurar vLLM para un rendimiento óptimo
vLLM soporta configuraciones avanzadas, como:
- Paralelismo de Tensor: Ajusta
--tensor-parallel-sizesegún la configuración de tu GPU. - Longitud del Contexto: Qwen3 soporta hasta 32,768 tokens, lo que se puede establecer a través de
--max-model-len 32768. - Parámetros de Generación: Usa la API para establecer
temperature,top_pytop_k(por ejemplo, 0.7, 0.8, 20 para el modo sin pensamiento).
Con vLLM en ejecución, probemos el punto final de API usando Apidog.
Paso 5: Probar la API de Qwen3 con Apidog
Apidog es una herramienta potente para probar puntos finales de API, lo que la hace perfecta para interactuar con tu modelo Qwen3 implementado localmente.
Configurar Apidog
- Descarga e instala Apidog desde el sitio web oficial.
- Inicia Apidog y crea un nuevo proyecto.
Probar la API de Ollama
- Crea una nueva solicitud de API en Apidog.
- Establece el punto final a
http://localhost:11434/api/generate. - Configura la solicitud:
- Método: POST
- Cuerpo (JSON):
{
"model": "qwen3-4b",
"prompt": "Hello, how can I assist you today?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- Envía la solicitud y verifica la respuesta.
Probar la API de vLLM
- Crea otra solicitud de API en Apidog.
- Establece el punto final a
http://localhost:8000/v1/completions. - Configura la solicitud:
- Método: POST
- Cuerpo (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Write a Python script to calculate factorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- Envía la solicitud y verifica la salida.
Apidog facilita la validación de tu implementación de Qwen3 y asegura que la API funcione correctamente. Ahora, afinemos el rendimiento del modelo.
Paso 6: Ajustar el rendimiento de Qwen3
Para optimizar el rendimiento de Qwen3, ajusta las siguientes configuraciones según tu caso de uso:
Modo de Pensamiento
Qwen3 soporta un "modo de pensamiento" para un razonamiento mejorado, como se destaca en la imagen de la publicación de X. Puedes controlarlo de dos maneras:
- Interruptor Suave: Añade
/thinko/no_thinka tu prompt.
- Ejemplo:
Resuelve este problema matemático /think.
- Interruptor Duro: Deshabilita el pensamiento por completo en vLLM con
--enable-thinking=False.
Parámetros de Generación
Ajusta los parámetros de generación para una mejor calidad de salida:
- Temperature: Usa 0.6 para el modo de pensamiento o 0.7 para el modo sin pensamiento.
- Top-P: Establece en 0.95 (pensamiento) o 0.8 (sin pensamiento).
- Top-K: Usa 20 para ambos modos.
- Evita la decodificación codiciosa (greedy decoding), como recomienda el equipo de Qwen.
Experimenta con estas configuraciones para lograr el equilibrio deseado entre creatividad y precisión.
Resolución de Problemas Comunes
Al implementar Qwen3, puedes encontrar algunos problemas. Aquí hay soluciones a problemas comunes:
El modelo no se carga en Ollama:
- Asegúrate de que la ruta del archivo GGUF en el
Modelfilesea correcta. - Verifica si tu sistema tiene suficiente memoria para cargar el modelo.
Error de paralelismo de tensor en vLLM:
- Si ves un error como "output_size is not divisible by weight quantization block_n", reduce el
--tensor-parallel-size(por ejemplo, a 4).
La solicitud de API falla en Apidog:
- Verifica que el servidor (Ollama, LM Studio o vLLM) esté en ejecución.
- Revisa cuidadosamente la URL del punto final y la carga útil de la solicitud.
Al abordar estos problemas, puedes asegurar una experiencia de implementación fluida.
Conclusión
Ejecutar modelos cuantizados de Qwen3 localmente es un proceso sencillo con herramientas como Ollama, LM Studio y vLLM. Ya seas un desarrollador que construye aplicaciones o un investigador que experimenta con LLMs, Qwen3 ofrece la flexibilidad y el rendimiento que necesitas. Siguiendo esta guía, has aprendido a descargar modelos de Hugging Face y ModelScope, implementarlos usando varios frameworks y probar sus puntos finales de API con Apidog.
¡Comienza a explorar Qwen3 hoy mismo y desbloquea el poder de los LLMs locales para tus proyectos!