
La serie Qwen de Alibaba sigue superando los límites en los grandes modelos de lenguaje, y Qwen3-Next-80B-A3B destaca como un excelente ejemplo de eficiencia que se une al alto rendimiento. Los ingenieros y desarrolladores buscan modelos que ofrezcan un razonamiento robusto sin la sobrecarga computacional de los gigantes densos. Este modelo aborda esa demanda de frente, presumiendo de 80 mil millones de parámetros, pero activando solo 3 mil millones por token. En consecuencia, los equipos logran velocidades de inferencia más rápidas y gastos de entrenamiento reducidos, lo que lo hace ideal para implementaciones en el mundo real.
En esta publicación, explorará los componentes centrales de Qwen3-Next-80B-A3B, analizará su arquitectura innovadora, revisará los datos empíricos de rendimiento y dominará su API a través de pasos prácticos. Además, integrará herramientas como Apidog para mejorar su flujo de trabajo. Al final, poseerá el conocimiento para implementar este modelo de manera efectiva en sus aplicaciones.
¿Qué define a Qwen3-Next-80B-A3B? Características principales e innovaciones
Qwen3-Next-80B-A3B surge de la familia Qwen de Alibaba como un modelo de Mezcla de Expertos (MoE) disperso optimizado tanto para la velocidad como para la capacidad. Los desarrolladores activan solo una fracción de sus parámetros durante la inferencia, lo que se traduce en un ahorro sustancial de recursos. Específicamente, este modelo emplea una configuración MoE ultra-dispersa con 512 expertos, enrutando a 10 por token junto con un experto compartido. Como resultado, rivaliza con el rendimiento de contrapartes más densas como Qwen3-32B mientras consume mucha menos energía.
Además, el modelo admite la predicción de múltiples tokens, una técnica que acelera la decodificación especulativa. Esta característica permite que el modelo genere múltiples tokens simultáneamente, lo que aumenta el rendimiento en las etapas de decodificación. Los desarrolladores aprecian esto para aplicaciones que requieren respuestas rápidas, como chatbots o herramientas de análisis en tiempo real.
La serie incluye variantes adaptadas a necesidades específicas: el modelo base para el preentrenamiento general, la versión instruct para tareas conversacionales ajustadas y la variante thinking para cadenas de razonamiento avanzadas. Por ejemplo, Qwen3-Next-80B-A3B-Thinking destaca en la resolución de problemas complejos, superando a modelos como Gemini-2.5-Flash-Thinking en los benchmarks. Además, maneja 119 idiomas, lo que permite implementaciones multilingües sin reentrenamiento.
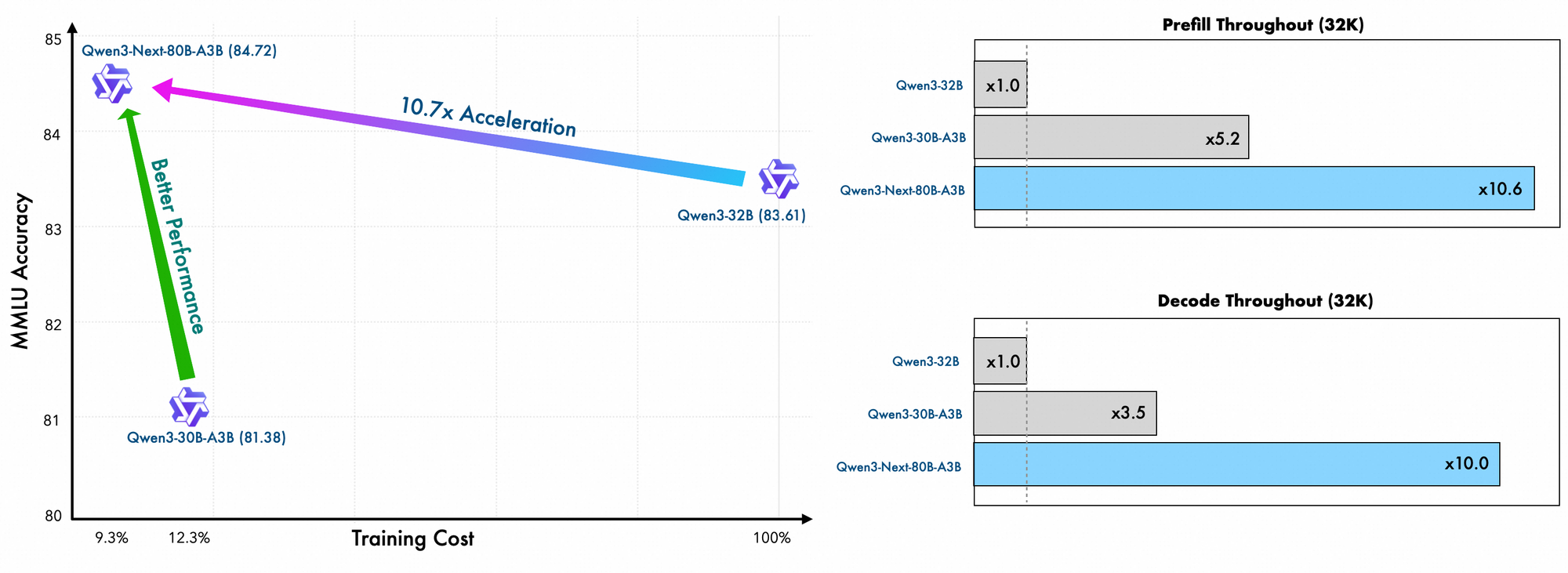
Los detalles del entrenamiento revelan eficiencias adicionales. Los ingenieros de Alibaba preentrenan este modelo utilizando métodos eficientes en escala, incurriendo solo en el 10% del costo en comparación con Qwen3-32B. Aprovechan un diseño híbrido a través de 48 capas con una dimensión oculta de 2048, asegurando una distribución equilibrada de la computación. En consecuencia, el modelo demuestra una comprensión superior de contextos largos, manteniendo la precisión más allá de los 32K tokens donde otros fallan.
En la práctica, estas características permiten a los desarrolladores escalar soluciones de IA de manera rentable. Ya sea que construya motores de búsqueda empresariales o generadores de contenido automatizados, Qwen3-Next-80B-A3B proporciona la base para aplicaciones innovadoras. Basándose en esta base, la siguiente sección examina los elementos arquitectónicos que hacen posibles tales eficiencias.
Análisis de la arquitectura de Qwen3-Next-80B-A3B: Un plan técnico
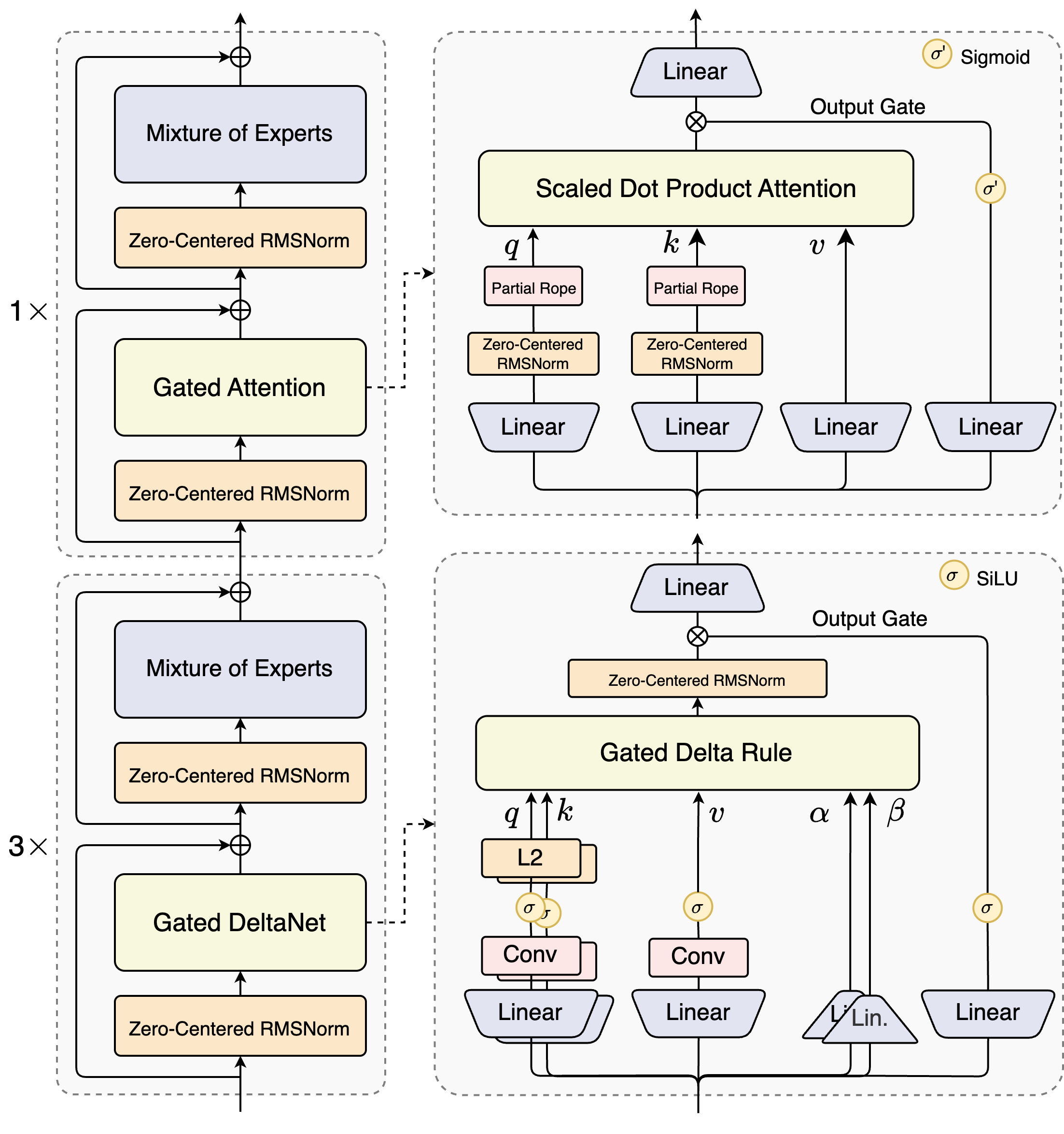
Los arquitectos de Qwen3-Next-80B-A3B introducen un diseño híbrido que combina mecanismos con puertas con técnicas avanzadas de normalización. En su corazón se encuentra una capa de Mezcla de Expertos (MoE), donde los expertos se especializan en distintas rutas computacionales. El modelo enruta las entradas dinámicamente, activando un subconjunto para minimizar la sobrecarga. Por ejemplo, el bloque de atención con puertas procesa consultas, claves y valores a través de incrustaciones RoPE parciales y capas RMSNorm centradas en cero, mejorando la estabilidad en secuencias largas.
Considere el módulo de atención de producto escalar escalado. Integra proyecciones lineales seguidas de puertas de salida moduladas por activaciones sigmoides. Esta configuración permite un control preciso sobre el flujo de información, evitando la dilución en espacios de alta dimensión. Además, RMSNorm centrada en cero precede y sigue estas operaciones, centrando las activaciones alrededor de cero para mitigar los problemas de gradiente durante el entrenamiento.
El diagrama ilustra dos bloques principales: el superior se centra en la atención con puertas con atención de producto escalar escalado, mientras que el inferior enfatiza el DeltaNet con puertas. En la ruta de atención (expansión 1x), las entradas fluyen a través de una RMSNorm centrada en cero, luego hacia el núcleo de atención con puertas. Aquí, las proyecciones de consulta (q), clave (k) y valor (v) utilizan RoPE parcial para la codificación posicional. Después de la atención, otra RMSNorm y capas lineales alimentan al MoE, que emplea una salida con puerta sigmoide.
Pasando a la ruta DeltaNet (expansión 3x), la arquitectura emplea una regla Delta con puertas para predicciones refinadas. Cuenta con normalización L2 en q y k, capas convolucionales para la extracción de características locales y activaciones SiLU para la no linealidad. La puerta de salida, combinada con una proyección lineal, asegura salidas coherentes de múltiples tokens. El diseño de este bloque soporta la decodificación especulativa del modelo, donde predice varios tokens por adelantado, verificados en pasadas subsiguientes.
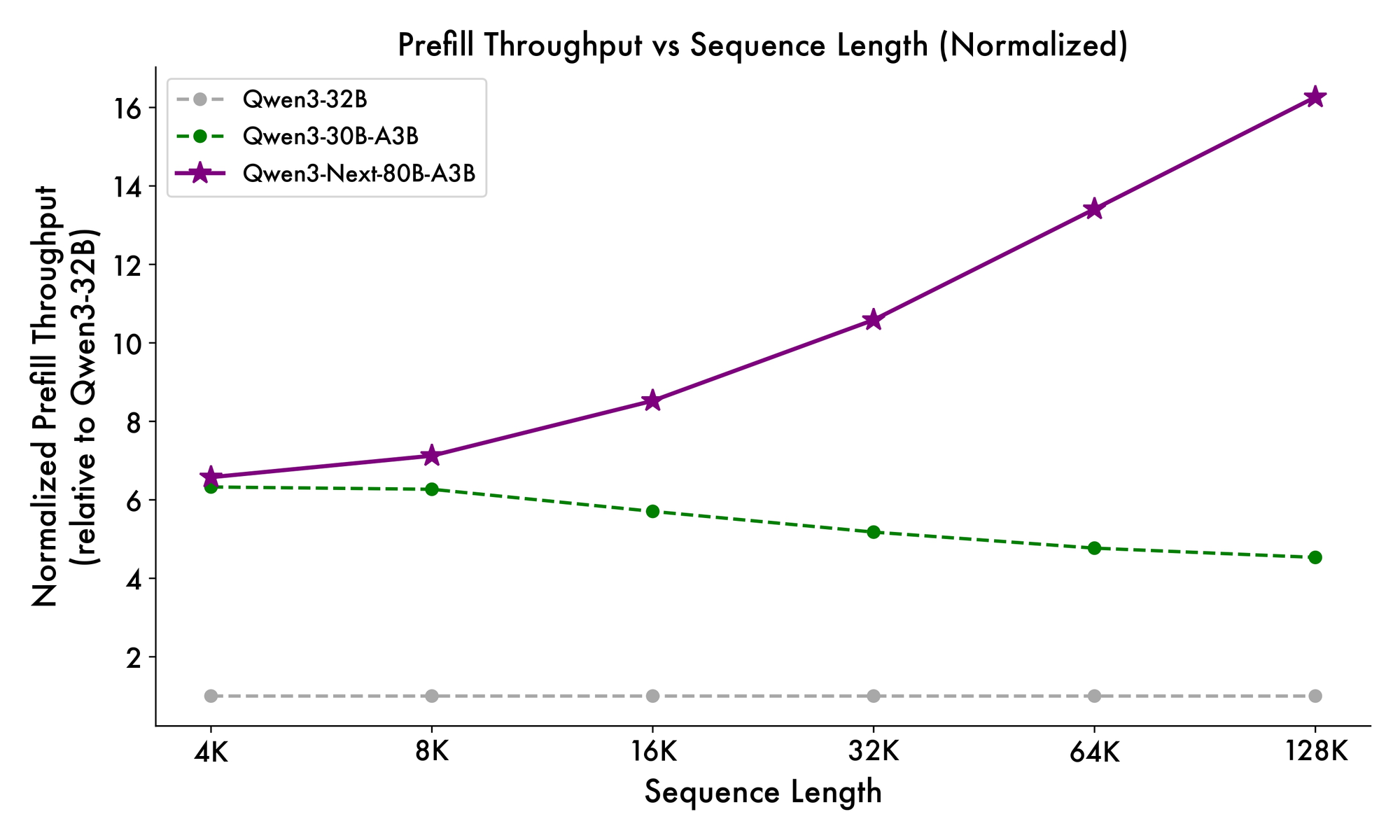
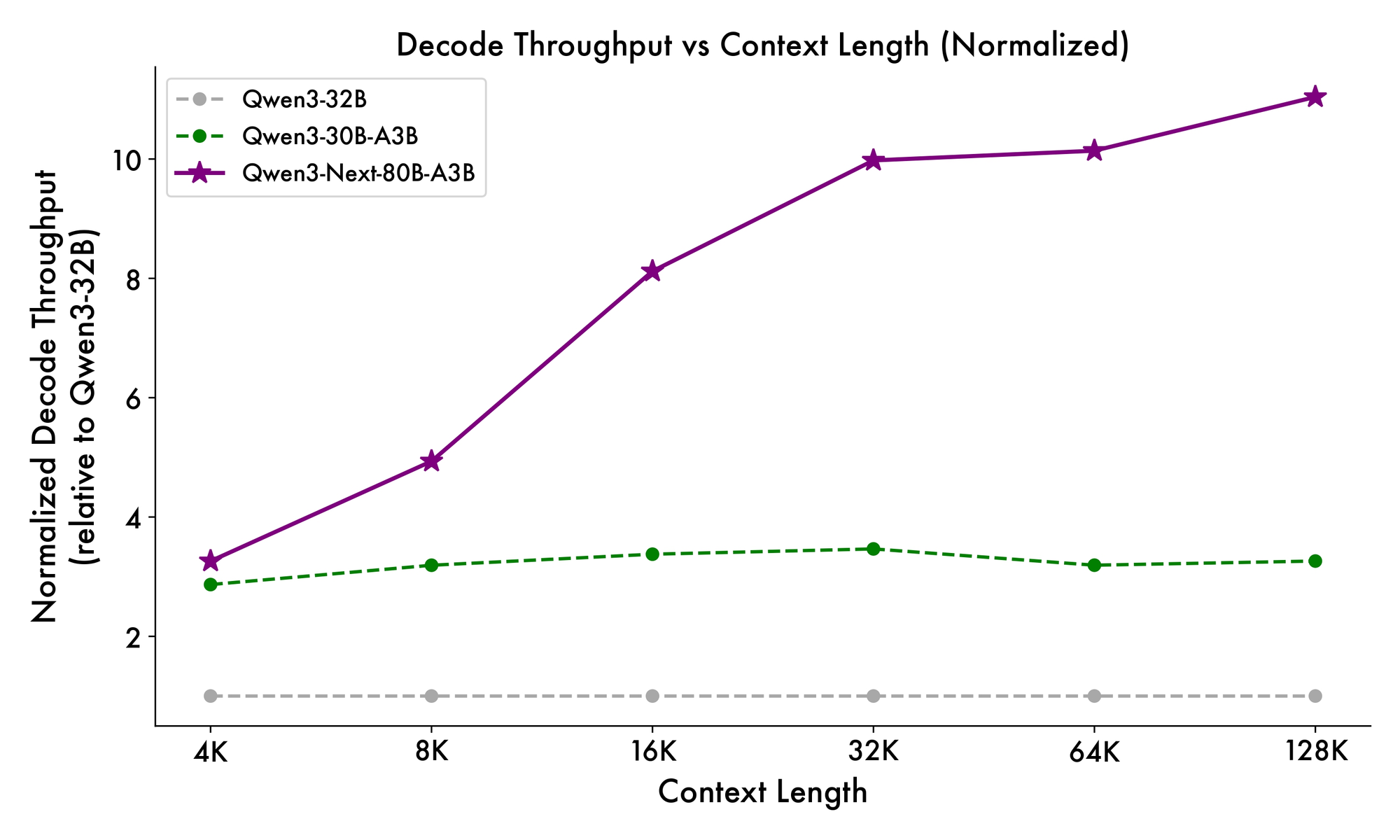
Además, la estructura general incorpora un experto compartido en el MoE para manejar patrones comunes entre tokens, reduciendo la redundancia. Las incrustaciones de cuerda parciales en las proyecciones preservan la invarianza rotacional para contextos extendidos. Como se evidencia en los benchmarks, esta configuración produce un rendimiento casi 7 veces mayor con longitudes de contexto de 4K en comparación con Qwen3-32B. Más allá de los 32K tokens, las velocidades superan las 10 veces, lo que lo hace adecuado para el análisis de documentos o tareas de generación de código.
Los desarrolladores se benefician de esta modularidad al realizar ajustes finos. Puede intercambiar expertos o ajustar los umbrales de enrutamiento para especializar el modelo en dominios como finanzas o atención médica. En esencia, la arquitectura no solo optimiza la computación, sino que también fomenta la adaptabilidad. Con estas ideas, ahora pasamos a cómo estos elementos se traducen en ganancias de rendimiento medibles.
Benchmarking Qwen3-Next-80B-A3B: Métricas de rendimiento que importan
Las evaluaciones empíricas posicionan a Qwen3-Next-80B-A3B como un líder en IA impulsada por la eficiencia. En benchmarks estándar como MMLU y HumanEval, el modelo base supera a Qwen3-32B a pesar de usar una décima parte de los parámetros activos. Específicamente, logra un 78.5% en MMLU para conocimientos generales, superando a los competidores en 2-3 puntos en subconjuntos de razonamiento.
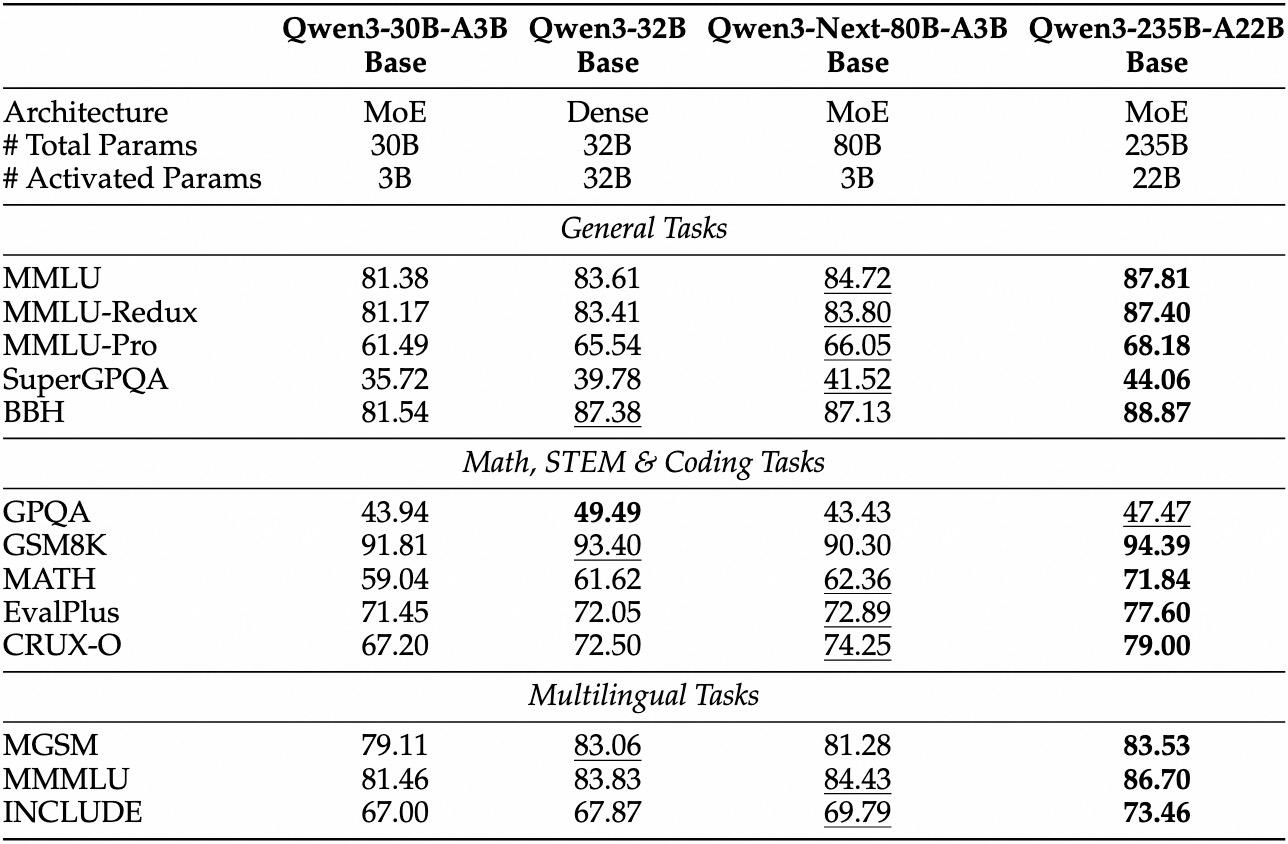
Para la variante instruct, las tareas conversacionales revelan fortalezas en el seguimiento de instrucciones. Obtiene un 85% en MT-Bench, demostrando diálogos coherentes de múltiples turnos. Mientras tanto, el modelo thinking brilla en escenarios de cadena de pensamiento, alcanzando un 92% en GSM8K para problemas de matemáticas, superando a Qwen3-30B-A3B-Thinking en un 4%.
La velocidad de inferencia es una piedra angular de su atractivo. Con un contexto de 4K, el rendimiento de decodificación alcanza 4 veces el de Qwen3-32B, escalando a 10 veces en longitudes mayores. Las etapas de prellenado, críticas para el procesamiento de prompts, muestran mejoras de 7 veces, gracias al MoE disperso. El consumo de energía disminuye en consecuencia, con costos de entrenamiento del 10% de los modelos más densos.
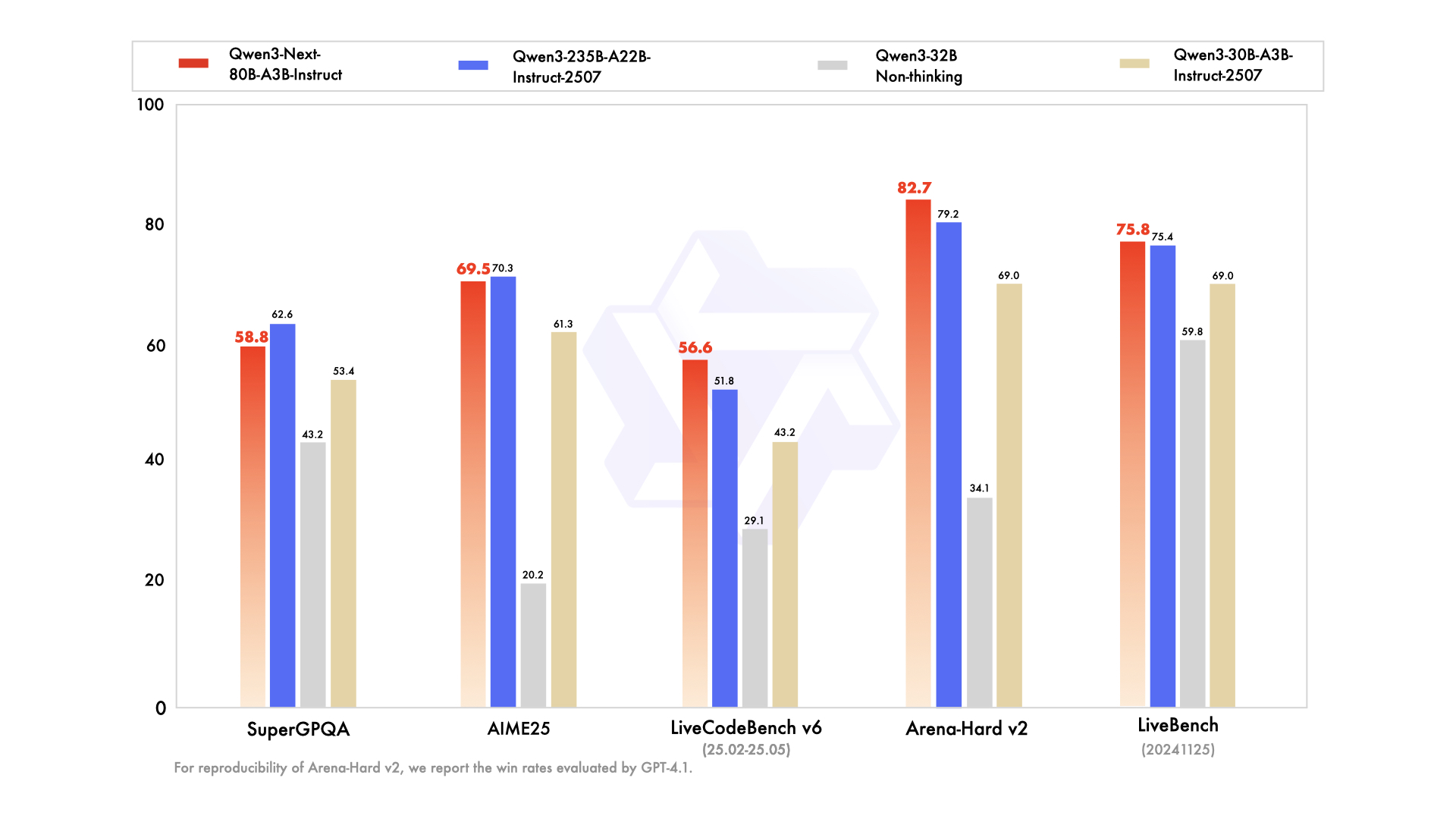
Las comparaciones con sus rivales resaltan su ventaja. Frente a Llama 3.1-70B, Qwen3-Next-80B-A3B-Thinking lidera en RULER (recuperación de contexto largo) en un 15%, recordando detalles de 128K tokens con precisión. Frente a DeepSeek-V2, ofrece un mejor soporte multilingüe sin sacrificar velocidad.

| Benchmark | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Instruct) | 81.9% | 83.5% |
Esta tabla subraya un rendimiento superior constante. Como resultado, las organizaciones lo adoptan para producción, equilibrando calidad y costo. Pasando de la teoría a la práctica, ahora se equipa con herramientas de acceso a la API.
Configuración del acceso a la API de Qwen3-Next-80B-A3B: Requisitos previos y autenticación
Alibaba proporciona la API de Qwen a través de DashScope, su plataforma en la nube, lo que garantiza una integración perfecta. Primero, cree una cuenta de Alibaba Cloud y navegue a la consola de Model Studio. Seleccione Qwen3-Next-80B-A3B de la lista de modelos, disponible en los modos base, instruct y thinking.
Obtenga su clave API desde el panel de control en "API Keys". Esta clave autentica las solicitudes, con límites de tasa basados en su nivel (el nivel gratuito ofrece 1 millón de tokens/mes). Para llamadas compatibles con OpenAI, establezca la URL base en https://dashscope.aliyuncs.com/compatible-mode/v1. Los puntos finales nativos de DashScope usan https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation.
Instale el SDK de Python a través de pip: pip install dashscope. Esta biblioteca maneja la serialización, los reintentos y el análisis de errores. Alternativamente, use clientes HTTP como requests para implementaciones personalizadas.
Las mejores prácticas de seguridad dictan almacenar las claves en variables de entorno: export DASHSCOPE_API_KEY='su_clave_aquí'. En consecuencia, su código sigue siendo portátil en diferentes entornos. Con la configuración completa, procede a elaborar su primera llamada a la API.
Guía práctica: Uso de la API de Qwen3-Next-80B-A3B con Python y DashScope
DashScope simplifica las interacciones con Qwen3-Next-80B-A3B. Comience con una solicitud de generación básica utilizando la variante instruct para respuestas tipo chat.
Aquí hay un script de inicio:
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
Este código envía un prompt y recupera hasta 200 tokens. El modelo responde con una explicación concisa, destacando las ganancias de eficiencia. Para el modo thinking, cambie a 'qwen3-next-80b-a3b-thinking' y añada instrucciones de razonamiento: "Piensa paso a paso antes de responder."
Los parámetros avanzados mejoran el control. Establezca top_p=0.9 para muestreo de núcleo, o repetition_penalty=1.1 para evitar bucles. Para contextos largos, especifique max_context_length=131072 para aprovechar la capacidad de 128K del modelo.
Maneje el streaming para aplicaciones en tiempo real:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
Esto produce una salida token por token, ideal para integraciones de UI. El manejo de errores incluye la verificación de response.code para problemas de cuota (por ejemplo, 10402 por saldo insuficiente).
Además, la llamada a funciones amplía la utilidad. Defina herramientas en esquema JSON:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
El modelo analiza la intención y devuelve una llamada de herramienta, que usted ejecuta externamente. Este patrón impulsa los flujos de trabajo basados en agentes. Con estos ejemplos, construirá pipelines robustos. A continuación, incorpore Apidog para probar y refinar estas llamadas sin codificar cada vez.
Mejora de su flujo de trabajo: Integre Apidog para probar la API de Qwen3-Next-80B-A3B
Apidog transforma el desarrollo de API en un proceso optimizado, particularmente para puntos finales de IA como Qwen3-Next-80B-A3B. Esta plataforma combina diseño, mocking, pruebas y documentación en una sola interfaz, impulsada por IA para la automatización inteligente.
Comience importando el esquema de DashScope en Apidog. Cree un nuevo proyecto, añada el punto final POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation y pegue su clave API como encabezado: X-DashScope-API-Key: su_clave.
Diseñe solicitudes visualmente: Establezca el parámetro del modelo en 'qwen3-next-80b-a3b-instruct', introduzca un prompt en el cuerpo como JSON {"input": {"messages": [{"role": "user", "content": "Su prompt aquí"}]}}. La IA de Apidog sugiere casos de prueba, generando variaciones como prompts de casos extremos o muestras de alta temperatura.
Ejecute colecciones de pruebas secuencialmente. Por ejemplo, compare la latencia en diferentes temperaturas:
- Prueba 1: Temperatura 0.1, longitud del prompt 100 tokens.
- Prueba 2: Temperatura 1.0, contexto 10K tokens.
La herramienta rastrea métricas (tiempo de respuesta, uso de tokens, tasas de error) y visualiza tendencias en paneles. Simule respuestas para el desarrollo sin conexión: Apidog simula las salidas de Qwen basándose en datos históricos, acelerando las construcciones de frontend.
La documentación se genera automáticamente a partir de sus colecciones. Exporte especificaciones OpenAPI con ejemplos, incluyendo detalles específicos de Qwen3-Next-80B-A3B como notas de enrutamiento MoE. Las funciones de colaboración permiten a los equipos compartir entornos, asegurando pruebas consistentes.
En un escenario, un desarrollador prueba prompts multilingües. La IA de Apidog detecta inconsistencias, sugiriendo correcciones como añadir pistas de idioma. Como resultado, el tiempo de integración se reduce en un 40%, según los informes de los usuarios. Para pruebas específicas de IA, aproveche su generación inteligente de datos: Introduzca un esquema y elaborará prompts realistas que imitan el tráfico de producción.
Además, Apidog soporta ganchos de CI/CD, ejecutando pruebas de API en pipelines. Conéctese a GitHub Actions para la validación automatizada después de la implementación. Este enfoque de circuito cerrado minimiza los errores en las aplicaciones impulsadas por Qwen.
Estrategias avanzadas: Optimización de las llamadas a la API de Qwen3-Next-80B-A3B para producción
La optimización eleva el uso básico a una fiabilidad de nivel empresarial. Primero, agrupe las solicitudes siempre que sea posible: DashScope admite hasta 10 prompts por llamada, lo que reduce la sobrecarga para tareas paralelas como granjas de resumen.
Monitoree la economía de tokens: el modelo cobra por parámetro activo, por lo que los prompts concisos generan ahorros. Use result_format='message' de la API para salidas estructuradas, analizando JSON directamente para evitar el post-procesamiento.
Para una alta disponibilidad, implemente reintentos con retroceso exponencial:
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
Esto maneja errores transitorios como los límites de tasa 429. Escale horizontalmente distribuyendo las llamadas entre regiones: DashScope ofrece puntos finales en Singapur y EE. UU.
Las consideraciones de seguridad incluyen la sanitización de entradas para evitar la inyección de prompts. Valide las entradas del usuario contra listas blancas antes de enviarlas a la API. Además, registre las respuestas anonimizadas para auditorías, cumpliendo con el GDPR.
En casos extremos, como contextos ultra-largos, divida las entradas y encadene las predicciones. La variante thinking ayuda aquí: Solicite con "Paso 1: Analizar la sección A; Paso 2: Sintetizar con B." Esto mantiene la coherencia en más de 100K tokens.
Los desarrolladores también exploran el ajuste fino a través de la plataforma de Alibaba, aunque los usuarios de la API se adhieren a la ingeniería de prompts. En consecuencia, estas tácticas aseguran implementaciones escalables y seguras.
Conclusión: Por qué Qwen3-Next-80B-A3B merece su atención
Qwen3-Next-80B-A3B redefine la IA eficiente con su MoE disperso, puertas híbridas y benchmarks superiores. Los desarrolladores aprovechan su API a través de DashScope para prototipos rápidos, mejorados con herramientas como Apidog para la rigurosidad de las pruebas.
Ahora posee el plan: desde los matices arquitectónicos hasta las optimizaciones de producción. Implemente estas ideas para construir sistemas más rápidos e inteligentes. Experimente hoy: el futuro de la inteligencia escalable le espera.