El equipo de Qwen en Alibaba Cloud ha lanzado dos potentes adiciones a su línea de modelos de lenguaje grandes (LLM): Qwen3-4B-Instruct-2507 y Qwen3-4B-Thinking-2507. Estos modelos aportan avances significativos en el razonamiento, el seguimiento de instrucciones y la comprensión de contextos largos, con soporte nativo para una longitud de contexto de 256K tokens. Diseñados para desarrolladores, investigadores y entusiastas de la IA, estos modelos ofrecen capacidades robustas para tareas que van desde la codificación hasta la resolución de problemas complejos. Además, herramientas como Apidog, una plataforma gratuita de gestión de API, pueden agilizar las pruebas y la integración de estos modelos en sus aplicaciones.
Comprendiendo los modelos Qwen3-4B
La serie Qwen3 representa la última evolución en la familia de modelos de lenguaje grandes de Alibaba Cloud, sucediendo a la serie Qwen2.5. Específicamente, Qwen3-4B-Instruct-2507 y Qwen3-4B-Thinking-2507 están diseñados para casos de uso distintos: el primero sobresale en el diálogo de propósito general y el seguimiento de instrucciones, mientras que el segundo está optimizado para tareas de razonamiento complejas. Ambos modelos admiten una longitud de contexto nativa de 262.144 tokens, lo que les permite procesar conjuntos de datos extensos, documentos largos o conversaciones de múltiples turnos con facilidad. Además, su compatibilidad con frameworks como Hugging Face Transformers y herramientas de implementación como Apidog los hace accesibles tanto para aplicaciones locales como basadas en la nube.
Qwen3-4B-Instruct-2507: Optimizado para la eficiencia
El modelo Qwen3-4B-Instruct-2507 opera en modo no pensante, centrándose en respuestas eficientes y de alta calidad para tareas de propósito general. Este modelo ha sido ajustado para mejorar el seguimiento de instrucciones, el razonamiento lógico, la comprensión de texto y las capacidades multilingües. En particular, no genera bloques <think></think>, lo que lo hace ideal para escenarios donde se prefieren respuestas rápidas y directas sobre el razonamiento paso a paso.
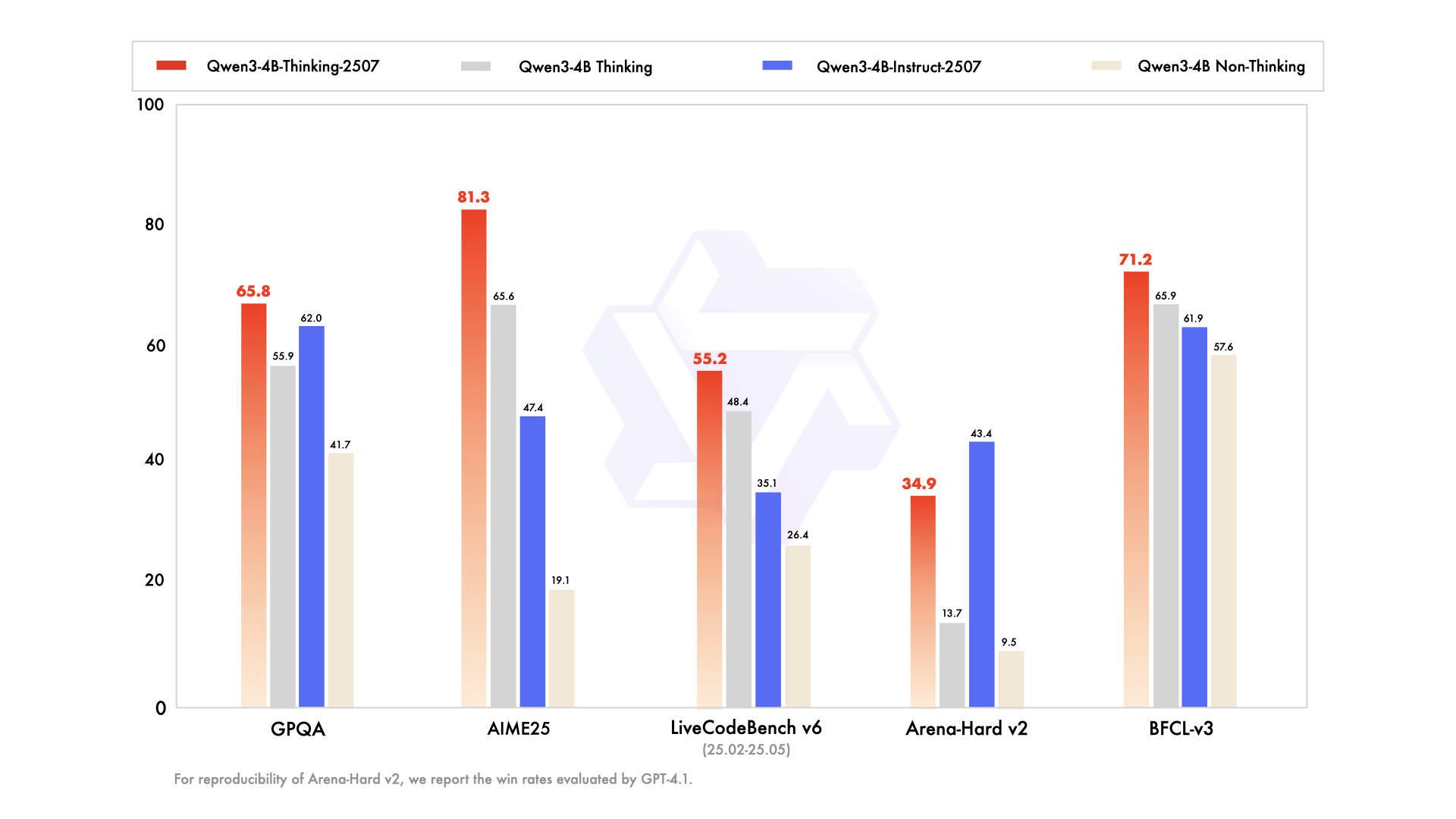
Las mejoras clave incluyen:
- Capacidades generales mejoradas: El modelo demuestra un rendimiento superior en matemáticas, ciencias, codificación y uso de herramientas, lo que lo hace versátil para aplicaciones técnicas.
- Soporte multilingüe: Cubre más de 100 idiomas y dialectos, asegurando un rendimiento robusto en aplicaciones globales.
- Comprensión de contexto largo: Con una longitud de contexto de 256K tokens, maneja entradas extendidas, como documentos legales o bases de código extensas, sin truncamiento.
- Alineación con las preferencias del usuario: El modelo ofrece respuestas más naturales y atractivas, destacando en la escritura creativa y los diálogos de múltiples turnos.
Para los desarrolladores que integran este modelo en las API, Apidog proporciona una interfaz fácil de usar para probar y gestionar los puntos finales de la API, garantizando una implementación perfecta. Esta eficiencia hace que Qwen3-4B-Instruct-2507 sea una opción preferida para aplicaciones que requieren respuestas rápidas y precisas.
Qwen3-4B-Thinking-2507: Construido para el razonamiento profundo
En contraste, Qwen3-4B-Thinking-2507 está diseñado para tareas que exigen un razonamiento intensivo, como la resolución lógica de problemas, las matemáticas y los benchmarks académicos. Este modelo opera exclusivamente en modo de pensamiento, incorporando automáticamente procesos de cadena de pensamiento (CoT) para desglosar problemas complejos. Su salida puede incluir una etiqueta de cierre </think> sin una etiqueta de apertura <think>, ya que la plantilla de chat predeterminada incorpora el comportamiento de pensamiento.
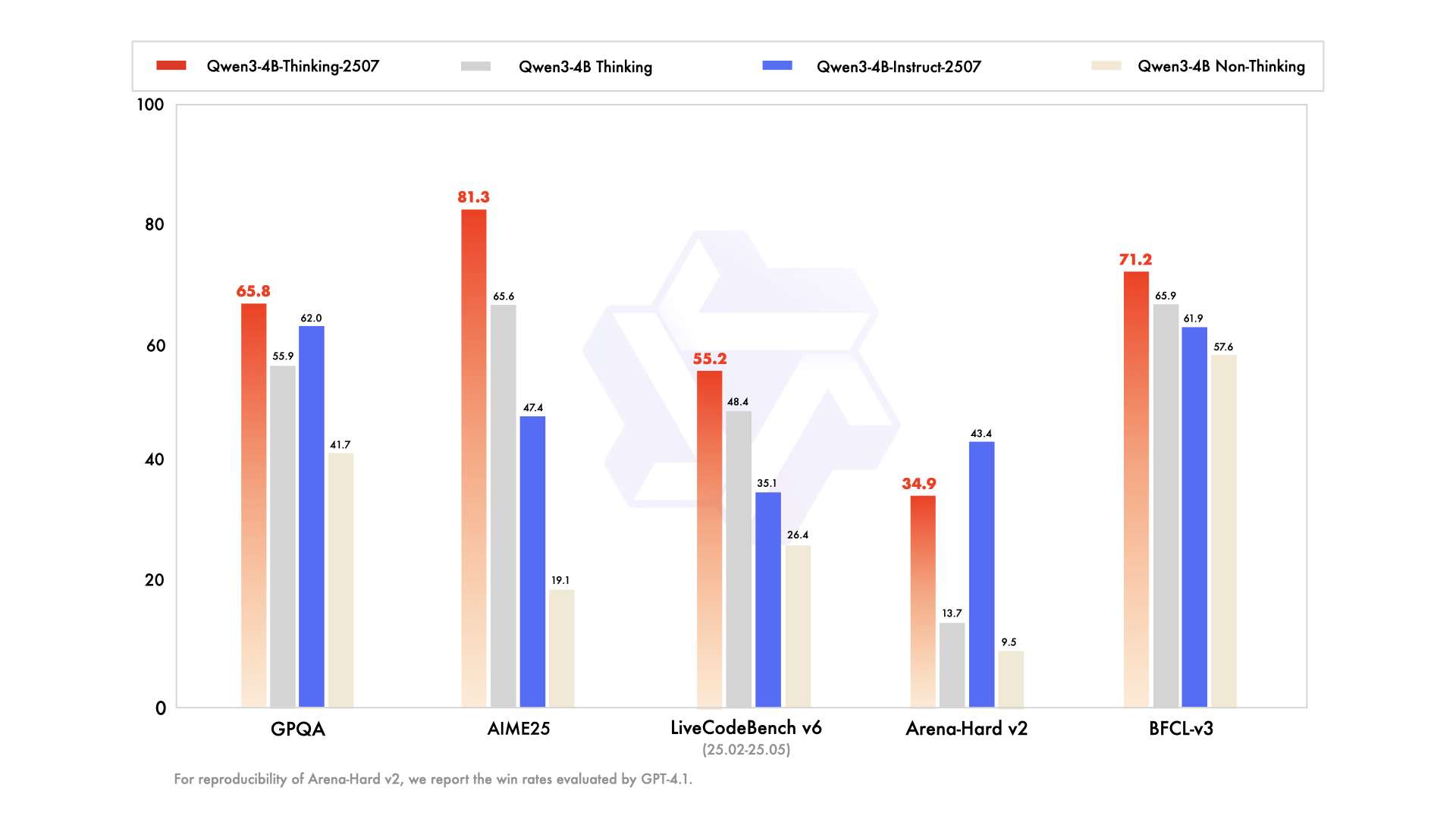
Las mejoras clave incluyen:
- Capacidades de razonamiento avanzadas: El modelo logra resultados de vanguardia entre los modelos de pensamiento de código abierto, particularmente en campos STEM y codificación.
- Mayor profundidad de pensamiento: Destaca en tareas que requieren un razonamiento a nivel de experto humano, con una longitud de pensamiento extendida para un análisis exhaustivo.
- Longitud de contexto de 256K: Al igual que su contraparte Instruct, admite ventanas de contexto masivas, ideales para procesar grandes conjuntos de datos o consultas intrincadas.
- Integración de herramientas: El modelo aprovecha herramientas como Qwen-Agent para flujos de trabajo de agente optimizados, mejorando su utilidad en sistemas automatizados.
Para los desarrolladores que trabajan con aplicaciones intensivas en razonamiento, Apidog puede facilitar las pruebas de API, asegurando que las salidas del modelo se alineen con los resultados esperados. Este modelo es particularmente adecuado para entornos de investigación y escenarios complejos de resolución de problemas.
Especificaciones técnicas y arquitectura
Ambos modelos Qwen3-4B forman parte de la familia Qwen3, que incluye arquitecturas densas y de mezcla de expertos (MoE). La designación 4B se refiere a sus 4 mil millones de parámetros, logrando un equilibrio entre la eficiencia computacional y el rendimiento. En consecuencia, estos modelos son accesibles en hardware de consumo, a diferencia de modelos más grandes como Qwen3-235B-A22B, que requieren recursos sustanciales.
Aspectos destacados de la arquitectura
- Diseño de modelo denso: A diferencia de los modelos MoE, los modelos Qwen3-4B utilizan una arquitectura densa, lo que garantiza un rendimiento consistente en todas las tareas sin necesidad de activación selectiva de parámetros.
- YaRN para extensión de contexto: Los modelos aprovechan YaRN para extender su longitud de contexto de 32.768 a 262.144 tokens, lo que permite el procesamiento de contexto largo sin una degradación significativa del rendimiento.
- Pipeline de entrenamiento: El equipo de Qwen empleó un proceso de entrenamiento de cuatro etapas, que incluyó un arranque en frío de cadena de pensamiento larga, aprendizaje por refuerzo basado en el razonamiento, fusión del modo de pensamiento y aprendizaje por refuerzo general. Este enfoque mejora tanto las capacidades de razonamiento como las de diálogo.
- Soporte de cuantificación: Ambos modelos admiten la cuantificación FP8, lo que reduce los requisitos de memoria manteniendo la precisión. Por ejemplo, Qwen3-4B-Thinking-2507-FP8 está disponible para entornos con recursos limitados.
Requisitos de hardware
Para ejecutar estos modelos de manera eficiente, considere lo siguiente:
- Memoria de GPU: Se recomienda un mínimo de 8 GB de VRAM para los modelos cuantificados en FP8, mientras que los modelos bfloat16 pueden requerir 16 GB o más.
- RAM: Para un rendimiento óptimo, 16 GB de memoria unificada (VRAM + RAM) son suficientes para la mayoría de las tareas.
- Frameworks de inferencia: Ambos modelos son compatibles con Hugging Face Transformers (versión ≥4.51.0), vLLM (≥0.8.5) y SGLang (≥0.4.6.post1). Herramientas locales como Ollama y LMStudio también son compatibles con Qwen3.
Para los desarrolladores que implementan estos modelos, Apidog simplifica el proceso al proporcionar herramientas para monitorear y probar el rendimiento de la API, asegurando una integración eficiente con los frameworks de inferencia.
Integración con Hugging Face y ModelScope
Los modelos Qwen3-4B están disponibles tanto en Hugging Face como en ModelScope, ofreciendo flexibilidad para los desarrolladores. A continuación, proporcionamos un fragmento de código para demostrar cómo usar Qwen3-4B-Instruct-2507 con Hugging Face Transformers.

from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Write a Python function to calculate Fibonacci numbers."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=16384)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()content = tokenizer.decode(output_ids, skip_special_tokens=True)print("Generated Code:\n", content)Para Qwen3-4B-Thinking-2507, se requiere un análisis adicional para manejar el contenido de pensamiento:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Solve the equation 2x^2 + 3x - 5 = 0."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:index = len(output_ids) - output_ids[::-1].index(151668) # tokenexcept ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("Thinking Process:\n", thinking_content)print("Solution:\n", content)Estos fragmentos demuestran la facilidad de integrar los modelos Qwen en los flujos de trabajo de Python. Para implementaciones basadas en API, Apidog puede ayudar a probar estos puntos finales, asegurando un rendimiento fiable.
Optimización del rendimiento y mejores prácticas
Para maximizar el rendimiento de los modelos Qwen3-4B, considere las siguientes recomendaciones:
- Parámetros de muestreo: Para Qwen3-4B-Instruct-2507, use
temperature=0.7,top_p=0.8,top_k=20ymin_p=0. Para Qwen3-4B-Thinking-2507, usetemperature=0.6,top_p=0.95,top_k=20ymin_p=0. Evite la decodificación codiciosa para prevenir la degradación del rendimiento. - Gestión de la longitud del contexto: Si encuentra problemas de falta de memoria, reduzca la longitud del contexto a 32.768 tokens. Sin embargo, para tareas de razonamiento, mantenga una longitud de contexto superior a 131.072 tokens.
- Penalización de presencia: Establezca
presence_penaltyentre 0 y 2 para reducir las repeticiones, pero evite valores altos para prevenir la mezcla de idiomas. - Frameworks de inferencia: Use vLLM o SGLang para inferencia de alto rendimiento, y aproveche Apidog para monitorear el rendimiento de la API.
Comparando Qwen3-4B-Instruct-2507 y Qwen3-4B-Thinking-2507
Si bien ambos modelos comparten la misma arquitectura de 4 mil millones de parámetros, sus filosofías de diseño difieren:
- Qwen3-4B-Instruct-2507: Prioriza la velocidad y la eficiencia, lo que lo hace adecuado para chatbots, atención al cliente y aplicaciones de propósito general.
- Qwen3-4B-Thinking-2507: Se centra en el razonamiento profundo, ideal para la investigación académica, la resolución de problemas complejos y las tareas que requieren procesos de cadena de pensamiento.
Los desarrolladores pueden cambiar entre modos usando los prompts /think y /no_think, lo que permite flexibilidad según los requisitos de la tarea. Apidog puede ayudar a probar estos cambios de modo en aplicaciones impulsadas por API.
Soporte de la comunidad y del ecosistema
Los modelos Qwen3-4B se benefician de un ecosistema robusto, con soporte de Hugging Face, ModelScope y herramientas como Ollama, LMStudio y llama.cpp. La naturaleza de código abierto de estos modelos, con licencia Apache 2.0, fomenta las contribuciones de la comunidad y el ajuste fino. Por ejemplo, Unsloth proporciona herramientas para un ajuste fino 2 veces más rápido con un 70% menos de VRAM, haciendo que estos modelos sean accesibles a un público más amplio.
Conclusión
Los modelos Qwen3-4B-Instruct-2507 y Qwen3-4B-Thinking-2507 marcan un salto significativo en la serie Qwen de Alibaba Cloud, ofreciendo capacidades inigualables en el seguimiento de instrucciones, el razonamiento y el procesamiento de contextos largos. Con una longitud de contexto de 256K tokens, soporte multilingüe y compatibilidad con herramientas como Apidog, estos modelos empoderan a los desarrolladores para construir aplicaciones inteligentes y escalables. Ya sea que esté generando código, resolviendo ecuaciones o creando chatbots multilingües, estos modelos ofrecen un rendimiento excepcional. Comience a explorar su potencial hoy mismo y utilice Apidog para agilizar sus integraciones de API para una experiencia de desarrollo fluida.