
Hoy es otro gran día para la comunidad de IA de código abierto, en particular, que prospera en estos momentos, deconstruyendo, probando y construyendo ávidamente sobre el nuevo estado del arte. En julio de 2025, el equipo Qwen de Alibaba desencadenó uno de esos eventos con el lanzamiento de su serie Qwen3, una potente nueva familia de modelos listos para redefinir los puntos de referencia de rendimiento. En el corazón de este lanzamiento se encuentra una variante fascinante y altamente especializada: Qwen3-235B-A22B-Thinking-2507.
Este modelo no es solo otra actualización incremental; representa un paso deliberado y estratégico hacia la creación de sistemas de IA con profundas capacidades de razonamiento. Su nombre por sí solo es una declaración de intenciones, señalando un enfoque en la lógica, la planificación y la resolución de problemas en múltiples pasos. Este artículo ofrece un análisis en profundidad de la arquitectura, el propósito y el impacto potencial de Qwen3-Thinking, examinando su lugar dentro del ecosistema Qwen3 más amplio y lo que significa para el futuro del desarrollo de la IA.
¿Quieres una plataforma integrada, todo en uno para que tu equipo de desarrolladores trabaje con máxima productividad?
¡Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!
La familia Qwen3: Un ataque multifacético al estado del arte
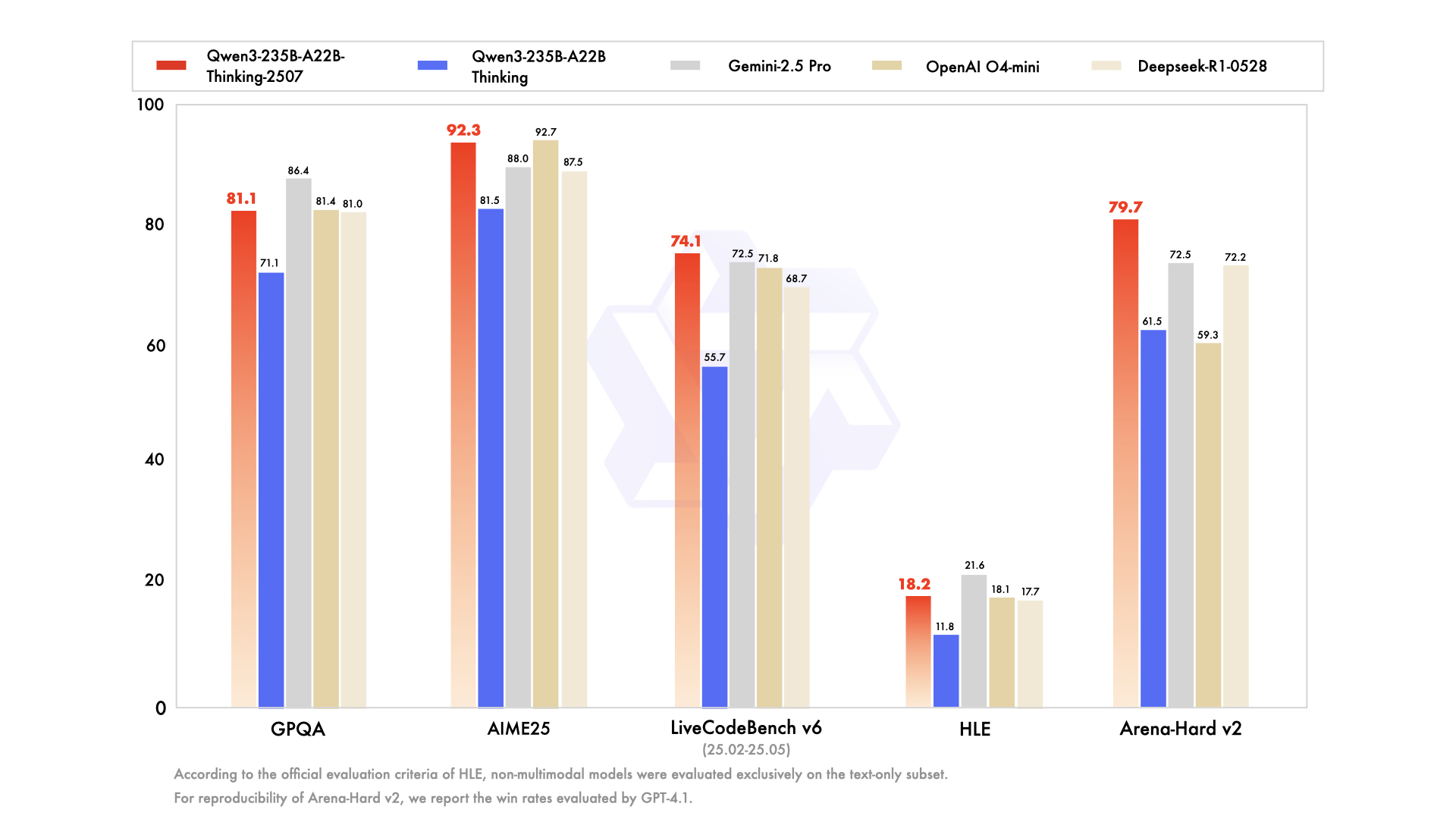
Para entender el modelo Thinking, primero hay que apreciar el contexto de su nacimiento. No llegó de forma aislada, sino como parte de una familia de modelos Qwen3 integral y estratégicamente diversa. La serie Qwen ya ha cultivado un seguimiento masivo, con un historial de descargas que asciende a cientos de millones y fomentando una comunidad vibrante que ha creado más de 100.000 modelos derivados en plataformas como Hugging Face.
La serie Qwen3 incluye varias variantes clave, cada una adaptada para diferentes dominios:
- Qwen3-Instruct: Un modelo de propósito general para seguir instrucciones diseñado para una amplia gama de aplicaciones conversacionales y orientadas a tareas. La variante
Qwen3-235B-A22B-Instruct-2507, por ejemplo, destaca por su alineación mejorada con las preferencias del usuario en tareas abiertas y una amplia cobertura de conocimiento. - Qwen3-Coder: Una serie de modelos diseñados explícitamente para la codificación agéntica. El más potente de ellos, un modelo masivo de 480 mil millones de parámetros, establece un nuevo estándar para la generación de código de código abierto y la automatización del desarrollo de software. Incluso viene con una herramienta de línea de comandos, Qwen Code, para aprovechar mejor sus capacidades agénticas.
- Qwen3-Thinking: El foco de nuestro análisis, especializado en tareas cognitivas complejas que van más allá del simple seguimiento de instrucciones o la generación de código.
Este enfoque familiar demuestra una estrategia sofisticada: en lugar de un único modelo monolítico que intenta ser un todoterreno, Alibaba está proporcionando un conjunto de herramientas especializadas, lo que permite a los desarrolladores elegir la base adecuada para sus necesidades específicas.
Hablemos de la parte "Thinking" de Qwen3-235B-A22B-Thinking-2507
El nombre del modelo, Qwen3-235B-A22B-Thinking-2507, está cargado de información que revela su arquitectura subyacente y su filosofía de diseño. Desglosemoslo pieza por pieza.
Qwen3: Esto significa que el modelo pertenece a la tercera generación de la serie Qwen, construyendo sobre el conocimiento y los avances de sus predecesores.235B-A22B(Mezcla de Expertos - MoE): Este es el detalle arquitectónico más crucial. El modelo no es una red densa de 235 mil millones de parámetros, donde cada parámetro se usa para cada cálculo. En cambio, emplea una arquitectura de Mezcla de Expertos (MoE).Thinking: Este sufijo denota la especialización del modelo, ajustado con datos que recompensan la deducción lógica y el análisis paso a paso.2507: Esta es una etiqueta de versionado, que probablemente significa julio de 2025, indicando la fecha de lanzamiento o finalización del entrenamiento del modelo.
La arquitectura MoE es la clave de la combinación de potencia y eficiencia de este modelo. Se puede considerar como un gran equipo de "expertos" especializados (redes neuronales más pequeñas) gestionados por una "red de compuerta" o "enrutador". Para cualquier token de entrada dado, el enrutador selecciona dinámicamente un pequeño subconjunto de los expertos más relevantes para procesar la información.
En el caso de Qwen3-235B-A22B, los detalles son:
- Parámetros totales (
235B): Esto representa el vasto repositorio de conocimiento distribuido entre todos los expertos disponibles. El modelo contiene un total de 128 expertos distintos. - Parámetros activos (
A22B): Para una sola pasada de inferencia, la red de compuerta selecciona 8 expertos para activar. El tamaño combinado de estos expertos activos es de aproximadamente 22 mil millones de parámetros.
Los beneficios de este enfoque son inmensos. Permite que el modelo posea el vasto conocimiento, el matiz y las capacidades de un modelo de 235B parámetros, mientras que tiene un costo computacional y una velocidad de inferencia más cercanos a los de un modelo denso mucho más pequeño de 22B parámetros. Esto hace que la implementación y ejecución de un modelo tan grande sea más factible sin sacrificar su profundidad de conocimiento.
Especificaciones técnicas y perfil de rendimiento
Más allá de la arquitectura de alto nivel, las especificaciones detalladas del modelo pintan una imagen más clara de sus capacidades.
- Arquitectura del modelo: Mezcla de Expertos (MoE)
- Parámetros totales: ~235 mil millones
- Parámetros activos: ~22 mil millones por token
- Número de expertos: 128
- Expertos activados por token: 8
- Longitud del contexto: El modelo admite una ventana de contexto de 128.000 tokens. Esta es una mejora masiva que le permite procesar y razonar sobre documentos extremadamente largos, bases de código enteras o historiales de conversación extensos sin perder el rastro de información crucial desde el principio de la entrada.
- Tokenizador: Utiliza un tokenizador personalizado de codificación de pares de bytes (BPE) con un vocabulario de más de 150.000 tokens. Este gran tamaño de vocabulario es indicativo de su fuerte entrenamiento multilingüe, lo que le permite codificar eficientemente texto de una amplia gama de idiomas, incluidos inglés, chino, alemán, español y muchos otros, así como lenguajes de programación.
- Datos de entrenamiento: Si bien la composición exacta del corpus de entrenamiento es propietaria, un modelo
Thinkingestá ciertamente entrenado en una mezcla especializada de datos diseñada para fomentar el razonamiento. Este conjunto de datos iría mucho más allá del texto web estándar y probablemente incluiría: - Artículos Académicos y Científicos: Grandes volúmenes de texto de fuentes como arXiv, PubMed y otros repositorios de investigación para absorber razonamiento científico y matemático complejo.
- Conjuntos de Datos Lógicos y Matemáticos: Conjuntos de datos como GSM8K (Matemáticas de Primaria) y el conjunto de datos MATH, que contienen problemas de palabras que requieren soluciones paso a paso.
- Problemas de Programación y Código: Conjuntos de datos como HumanEval y MBPP, que prueban el razonamiento lógico a través de la generación de código.
- Textos Filosóficos y Legales: Documentos que requieren la comprensión de argumentos lógicos densos, abstractos y altamente estructurados.
- Datos de Cadena de Pensamiento (CoT): Ejemplos generados sintéticamente o curados por humanos donde se le muestra explícitamente al modelo cómo "pensar paso a paso" para llegar a una respuesta.
Esta mezcla de datos curada es lo que separa el modelo Thinking de su hermano Instruct. No solo está entrenado para ser útil; está entrenado para ser riguroso.
El poder de "Pensar": Un enfoque en la cognición compleja
La promesa del modelo Qwen3-Thinking reside en su capacidad para abordar problemas que históricamente han sido grandes desafíos para los grandes modelos de lenguaje. Estas son tareas en las que el simple reconocimiento de patrones o la recuperación de información es insuficiente. La especialización "Thinking" sugiere competencia en áreas como:
- Razonamiento Multi-Paso: Resolver problemas que requieren descomponer una consulta en una secuencia de pasos lógicos. Por ejemplo, calcular las implicaciones financieras de una decisión empresarial basándose en múltiples variables de mercado o planificar la trayectoria de un proyectil dadas un conjunto de restricciones físicas.
- Deducción Lógica: Analizar un conjunto de premisas y extraer una conclusión válida. Esto podría implicar resolver un rompecabezas de cuadrícula lógica, identificar falacias lógicas en un texto o determinar las consecuencias de un conjunto de reglas en un contexto legal o contractual.
- Planificación Estratégica: Diseñar una secuencia de acciones para lograr un objetivo. Esto tiene aplicaciones en juegos complejos (como ajedrez o Go), simulaciones de estrategia empresarial, optimización de la cadena de suministro y gestión automatizada de proyectos.
- Inferencia Causal: Intentar identificar relaciones de causa y efecto dentro de un sistema complejo descrito en texto, una piedra angular del razonamiento científico y analítico con la que los modelos a menudo tienen dificultades.
- Razonamiento Abstracto: Comprender y manipular conceptos abstractos y analogías. Esto es esencial para la resolución creativa de problemas y la verdadera inteligencia a nivel humano, yendo más allá de los hechos concretos a las relaciones entre ellos.
El modelo está diseñado para sobresalir en puntos de referencia que miden específicamente estas habilidades cognitivas avanzadas, como MMLU (Comprensión del Lenguaje Multitarea Masiva) para el conocimiento general y la resolución de problemas, y los mencionados GSM8K y MATH para el razonamiento matemático.
Accesibilidad, cuantificación y compromiso comunitario
El poder de un modelo solo es significativo si puede ser accedido y utilizado. Manteniéndose fiel a su compromiso de código abierto, Alibaba ha puesto la familia Qwen3, incluida la variante Thinking, ampliamente disponible en plataformas como Hugging Face y ModelScope.
Reconociendo los significativos recursos computacionales necesarios para ejecutar un modelo de esta escala, también están disponibles versiones cuantificadas. El modelo Qwen3-235B-A22B-Thinking-2507-FP8 es un excelente ejemplo. FP8 (punto flotante de 8 bits) es una técnica de cuantificación de vanguardia que reduce drásticamente la huella de memoria del modelo y aumenta la velocidad de inferencia.
Desglosemos el impacto:
- Un modelo de 235B parámetros en precisión estándar de 16 bits (BF16/FP16) requeriría más de 470 GB de VRAM, una cantidad prohibitiva para todos, excepto los clústeres de servidores de grado empresarial más grandes.
- La versión cuantificada FP8, sin embargo, reduce este requisito a menos de 250 GB. Aunque sigue siendo sustancial, esto lleva el modelo al ámbito de lo posible para instituciones de investigación, startups e incluso individuos con estaciones de trabajo multi-GPU equipadas con hardware de consumo o prosumer de gama alta.
Esto hace que el razonamiento avanzado sea accesible para una audiencia mucho más amplia. Para los usuarios empresariales que prefieren servicios gestionados, los modelos también se están integrando en las plataformas en la nube de Alibaba. El acceso a la API a través de Model Studio y la integración en el asistente de IA insignia de Alibaba, Quark, garantizan que la tecnología pueda ser aprovechada a cualquier escala.
Conclusión: Una nueva herramienta para una nueva clase de problemas
El lanzamiento de Qwen3-235B-A22B-Thinking-2507 es más que solo otro punto en el gráfico en constante ascenso del rendimiento de los modelos de IA. Es una declaración sobre la dirección futura del desarrollo de la IA: un cambio de modelos monolíticos de propósito general hacia un ecosistema diverso de herramientas potentes y especializadas. Al emplear una eficiente arquitectura de Mezcla de Expertos, Alibaba ha entregado un modelo con el vasto conocimiento de una red de 235 mil millones de parámetros y la relativa amabilidad computacional de una de 22 mil millones de parámetros.
Al ajustar explícitamente este modelo para "Pensar", el equipo de Qwen proporciona al mundo una herramienta dedicada a resolver los desafíos analíticos y de razonamiento más difíciles. Tiene el potencial de acelerar el descubrimiento científico ayudando a los investigadores a analizar datos complejos, capacitar a las empresas para tomar mejores decisiones estratégicas y servir como una capa fundamental para una nueva generación de aplicaciones inteligentes que pueden planificar, deducir y razonar con una sofisticación sin precedentes. A medida que la comunidad de código abierto comience a explorar completamente sus profundidades, Qwen3-Thinking se convertirá en un bloque de construcción crítico en la búsqueda continua de una IA más capaz y verdaderamente inteligente.
¿Quieres una plataforma integrada, todo en uno para que tu equipo de desarrolladores trabaje con máxima productividad?
¡Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!