
El equipo Qwen de Alibaba ha vuelto a superar los límites de la inteligencia artificial con el lanzamiento del modelo Qwen2.5-VL-32B-Instruct, un innovador modelo de lenguaje de visión (VLM) que promete ser más inteligente y ligero.
Anunciado el 24 de marzo de 2025, este modelo de 32.000 millones de parámetros logra un equilibrio óptimo entre rendimiento y eficiencia, lo que lo convierte en una opción ideal para desarrolladores e investigadores. Basándose en el éxito de la serie Qwen2.5-VL, esta nueva iteración introduce avances significativos en el razonamiento matemático, la alineación de preferencias humanas y las tareas de visión, todo ello manteniendo un tamaño manejable para la implementación local.
Para los desarrolladores ansiosos por integrar este potente modelo en sus proyectos, es esencial explorar herramientas API robustas. Por eso recomendamos descargar Apidog gratis, una plataforma de desarrollo de API fácil de usar que simplifica las pruebas y la integración de modelos como Qwen en sus aplicaciones. Con Apidog, puede interactuar sin problemas con la API de Qwen, optimizar los flujos de trabajo y desbloquear todo el potencial de este innovador VLM. ¡Descargue Apidog hoy mismo y empiece a crear aplicaciones más inteligentes!
Esta herramienta API le permite probar y depurar los endpoints de su modelo sin esfuerzo. ¡Descargue Apidog gratis hoy mismo y optimice su flujo de trabajo mientras explora las capacidades de Mistral Small 3.1!
Qwen2.5-VL-32B: Un modelo de lenguaje de visión más inteligente
¿Qué hace que Qwen2.5-VL-32B sea único?
Qwen2.5-VL-32B destaca como un modelo de lenguaje de visión de 32.000 millones de parámetros diseñado para abordar las limitaciones de los modelos más grandes y más pequeños de la familia Qwen. Si bien los modelos de 72.000 millones de parámetros como Qwen2.5-VL-72B ofrecen capacidades robustas, a menudo requieren importantes recursos computacionales, lo que los hace poco prácticos para la implementación local. Por el contrario, los modelos de 7.000 millones de parámetros, aunque más ligeros, pueden carecer de la profundidad necesaria para tareas complejas. Qwen2.5-VL-32B llena este vacío ofreciendo un alto rendimiento con una huella más manejable.
Este modelo se basa en la serie Qwen2.5-VL, que obtuvo un amplio reconocimiento por sus capacidades multimodales. Sin embargo, Qwen2.5-VL-32B introduce mejoras críticas, incluida la optimización mediante el aprendizaje por refuerzo (RL). Este enfoque mejora la alineación del modelo con las preferencias humanas, garantizando resultados más detallados y fáciles de usar. Además, el modelo demuestra un razonamiento matemático superior, una característica vital para las tareas que implican la resolución de problemas complejos y el análisis de datos.

Mejoras técnicas clave
Qwen2.5-VL-32B aprovecha el aprendizaje por refuerzo para refinar su estilo de salida, haciendo que las respuestas sean más coherentes, detalladas y formateadas para una mejor interacción humana. Además, sus capacidades de razonamiento matemático han experimentado mejoras significativas, como lo demuestra su rendimiento en benchmarks como MathVista y MMMU. Estas mejoras provienen de procesos de entrenamiento afinados que priorizan la precisión y la deducción lógica, particularmente en contextos multimodales donde el texto y los datos visuales se cruzan.
El modelo también destaca en la comprensión y el razonamiento de imágenes de grano fino, lo que permite un análisis preciso del contenido visual, como gráficos, diagramas y documentos. Esta capacidad posiciona a Qwen2.5-VL-32B como un contendiente superior para aplicaciones que requieren deducción lógica visual avanzada y reconocimiento de contenido.
Benchmarks de rendimiento de Qwen2.5-VL-32B: Superando a los modelos más grandes
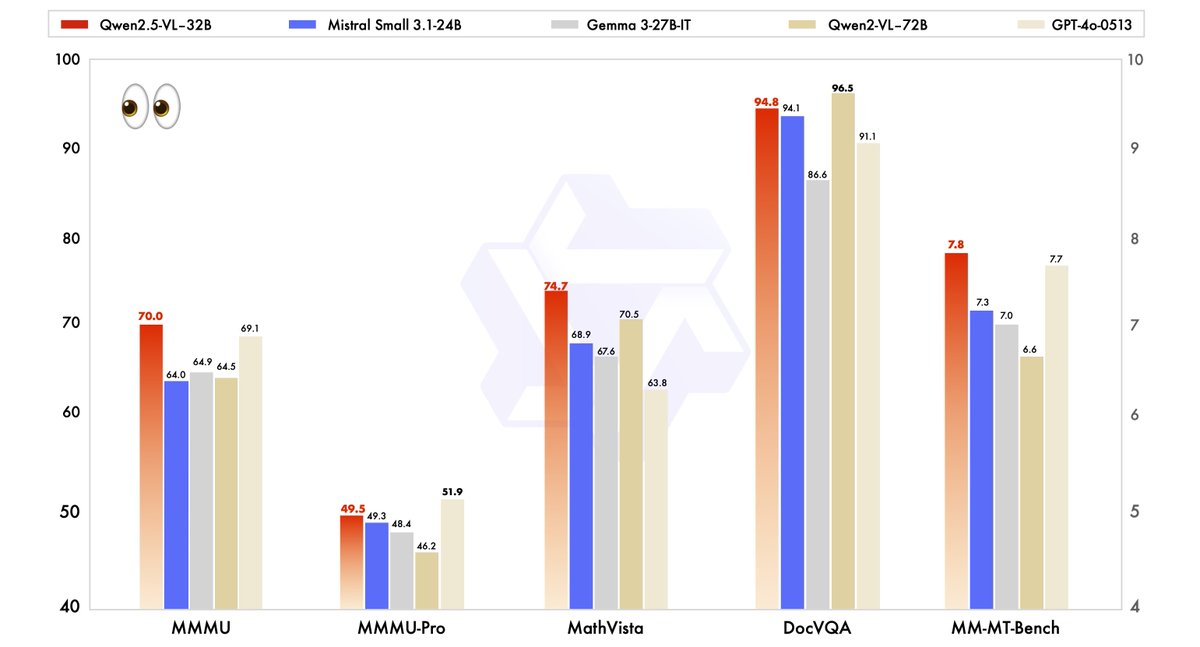
El rendimiento de Qwen2.5-VL-32B se ha evaluado rigurosamente con respecto a los modelos de última generación, incluido su hermano mayor, Qwen2.5-VL-72B, así como competidores como Mistral-Small-3.1–24B y Gemma-3–27B-IT. Los resultados destacan la superioridad del modelo en varias áreas clave.
- MMMU (Comprensión masiva del lenguaje multitarea): Qwen2.5-VL-32B alcanza una puntuación de 70,0, superando los 64,5 de Qwen2.5-VL-72B. Este benchmark prueba el razonamiento complejo de varios pasos en diversas tareas, lo que demuestra las capacidades cognitivas mejoradas del modelo.
- MathVista: Con una puntuación de 74,7, Qwen2.5-VL-32B supera los 70,5 de Qwen2.5-VL-72B, lo que subraya su fortaleza en tareas de razonamiento matemático y visual.
- MM-MT-Bench: Este benchmark de evaluación subjetiva de la experiencia del usuario muestra a Qwen2.5-VL-32B liderando a su predecesor por un margen significativo, lo que refleja una mejor alineación de las preferencias humanas.
- Tareas basadas en texto (por ejemplo, MMLU, MATH, HumanEval): El modelo compite eficazmente con modelos más grandes como GPT-4o-Mini, alcanzando puntuaciones de 78,4 en MMLU, 82,2 en MATH y 91,5 en HumanEval, a pesar de su menor número de parámetros.
Estos benchmarks ilustran que Qwen2.5-VL-32B no solo iguala, sino que a menudo supera el rendimiento de los modelos más grandes, todo ello requiriendo menos recursos computacionales. Este equilibrio de potencia y eficiencia lo convierte en una opción atractiva para desarrolladores e investigadores que trabajan con hardware limitado.
Por qué el tamaño importa: La ventaja de 32B
El tamaño de 32.000 millones de parámetros de Qwen2.5-VL-32B logra un punto óptimo para la implementación local. A diferencia de los modelos 72B, que exigen amplios recursos de GPU, este modelo más ligero se integra a la perfección con motores de inferencia como SGLang y vLLM, como se señala en los resultados web relacionados. Esta compatibilidad garantiza una implementación más rápida y un menor uso de memoria, lo que lo hace accesible para una gama más amplia de usuarios, desde startups hasta grandes empresas.
Además, la optimización del modelo para la velocidad y la eficiencia no compromete sus capacidades. Su capacidad para manejar tareas multimodales, como reconocer objetos, analizar gráficos y procesar salidas estructuradas como facturas y tablas, sigue siendo robusta, lo que lo posiciona como una herramienta versátil para aplicaciones del mundo real.

Ejecución de Qwen2.5-VL-32B localmente con MLX
Para ejecutar este potente modelo localmente en su Mac con Apple Silicon, siga estos pasos:
Requisitos del sistema
- Un Mac con Apple Silicon (chip M1, M2 o M3)
- Al menos 32 GB de RAM (se recomiendan 64 GB)
- Más de 60 GB de espacio de almacenamiento libre
- macOS Sonoma o posterior
Pasos de instalación
- Instale las dependencias de Python
pip install mlx mlx-llm transformers pillow
- Descargue el modelo
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- Convierta el modelo al formato MLX
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- Cree un script simple para interactuar con el modelo
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# Load the model
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# Load an image
image = Image.open("path/to/your/image.jpg")
# Create a prompt with the image
prompt = "What do you see in this image?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
Aplicaciones prácticas: Aprovechamiento de Qwen2.5-VL-32B
Tareas de visión y más allá
Las capacidades visuales avanzadas de Qwen2.5-VL-32B abren las puertas a una amplia gama de aplicaciones. Por ejemplo, puede servir como un agente visual, interactuando dinámicamente con interfaces de ordenador o teléfono para realizar tareas como la navegación o la extracción de datos. Su capacidad para comprender vídeos largos (hasta una hora) y señalar segmentos relevantes mejora aún más su utilidad en el análisis de vídeo y la localización temporal.
En el análisis de documentos, el modelo destaca en el procesamiento de contenido multiescena y multilingüe, incluido texto manuscrito, tablas, gráficos y fórmulas químicas. Esto lo hace invaluable para industrias como las finanzas, la educación y la atención médica, donde la extracción precisa de datos estructurados es fundamental.
Razonamiento textual y matemático
Más allá de las tareas de visión, Qwen2.5-VL-32B brilla en aplicaciones basadas en texto, particularmente aquellas que involucran razonamiento matemático y codificación. Sus altas puntuaciones en benchmarks como MATH y HumanEval indican su competencia en la resolución de problemas algebraicos complejos, la interpretación de gráficos de funciones y la generación de fragmentos de código precisos. Esta doble competencia en visión y texto posiciona a Qwen2.5-VL-32B como una solución holística para los desafíos de la IA multimodal.

Dónde puede utilizar Qwen2.5-VL-32B
Código abierto y acceso a la API
Qwen2.5-VL-32B está disponible bajo la licencia Apache 2.0, lo que lo convierte en código abierto y accesible para desarrolladores de todo el mundo. Puede acceder al modelo a través de varias plataformas:
- Hugging Face: El modelo está alojado en Hugging Face, donde puede descargarlo para uso local o integrarlo a través de la biblioteca Transformers.
- ModelScope: La plataforma ModelScope de Alibaba proporciona otra vía para acceder e implementar el modelo.
Para una integración perfecta, los desarrolladores pueden utilizar la API de Qwen, que simplifica la interacción con el modelo. Ya sea que esté creando una aplicación personalizada o experimentando con tareas multimodales, la API de Qwen garantiza una conectividad eficiente y un rendimiento robusto.
Implementación con motores de inferencia
Qwen2.5-VL-32B admite la implementación con motores de inferencia como SGLang y vLLM. Estas herramientas optimizan el modelo para una inferencia rápida, reduciendo la latencia y el uso de memoria. Al aprovechar estos motores, los desarrolladores pueden implementar el modelo en hardware local o plataformas en la nube, adaptándolo a casos de uso específicos.
Para empezar, instale las bibliotecas necesarias (por ejemplo, transformers, vllm) y siga las instrucciones en la página de GitHub de Qwen o en la documentación de Hugging Face. Este proceso garantiza una integración fluida, lo que le permite aprovechar todo el potencial del modelo.
Optimización del rendimiento local
Cuando ejecute Qwen2.5-VL-32B localmente, tenga en cuenta estos consejos de optimización:
- Cuantificación: Añada el flag
--quantizedurante la conversión para reducir los requisitos de memoria - Gestione la longitud del contexto: Limite los tokens de entrada para obtener respuestas más rápidas
- Cierre las aplicaciones que consumen muchos recursos al ejecutar el modelo
- Procesamiento por lotes: Para varias imágenes, procéselas en lotes en lugar de individualmente
Conclusión: Por qué Qwen2.5-VL-32B importa
Qwen2.5-VL-32B representa un hito significativo en la evolución de los modelos de lenguaje de visión. Al combinar un razonamiento más inteligente, requisitos de recursos más ligeros y un rendimiento robusto, este modelo de 32.000 millones de parámetros satisface las necesidades de desarrolladores e investigadores por igual. Sus avances en el razonamiento matemático, la alineación de las preferencias humanas y las tareas de visión lo posicionan como una opción superior para la implementación local y las aplicaciones del mundo real.
Ya sea que esté creando herramientas educativas, sistemas de inteligencia empresarial o soluciones de atención al cliente, Qwen2.5-VL-32B ofrece la versatilidad y la eficiencia que necesita. Con acceso a través de plataformas de código abierto y la API de Qwen, integrar este modelo en sus proyectos es más fácil que nunca. A medida que el equipo de Qwen continúa innovando, podemos esperar desarrollos aún más emocionantes en el futuro de la IA multimodal.
Esta herramienta API le permite probar y depurar los endpoints de su modelo sin esfuerzo. ¡Descargue Apidog gratis hoy mismo y optimice su flujo de trabajo mientras explora las capacidades de Mistral Small 3.1!


