
Qwen, la iniciativa de modelos fundacionales abiertos de Alibaba, supera constantemente los límites de la inteligencia artificial mediante rápidas iteraciones y lanzamientos. Desarrolladores e investigadores esperan con entusiasmo cada actualización, ya que los modelos Qwen a menudo establecen nuevos estándares en rendimiento y versatilidad. Recientemente, Qwen lanzó tres modelos innovadores: Qwen-Image-Edit-2509, Qwen3-TTS-Flash y Qwen3-Omni. Estas versiones mejoran las capacidades en edición de imágenes, síntesis de texto a voz y procesamiento omnimodal, respectivamente.
Además, estos modelos llegan en un momento crucial del desarrollo de la IA, donde la integración multimodal se vuelve esencial para las aplicaciones prácticas. Qwen-Image-Edit-2509 aborda la demanda de manipulaciones visuales precisas, mientras que Qwen3-TTS-Flash resuelve los problemas de latencia en la generación de voz. Mientras tanto, la introducción de Qwen3-Omni unifica diversas entradas en un marco cohesivo. Juntos, demuestran el compromiso de Qwen con una IA accesible y de alto rendimiento. Sin embargo, comprender sus fundamentos técnicos requiere un examen más detallado. Este artículo analiza cada modelo, destacando sus características, arquitecturas, puntos de referencia e impactos potenciales.
Qwen-Image-Edit-2509: Elevando la Precisión en la Edición de Imágenes
Qwen-Image-Edit-2509 representa un avance significativo en la manipulación de imágenes impulsada por IA. Los ingenieros de Qwen reconstruyeron este modelo para satisfacer a creadores, diseñadores y desarrolladores que requieren un control granular sobre el contenido visual. A diferencia de las iteraciones anteriores, esta versión admite la edición de múltiples imágenes, lo que permite a los usuarios combinar elementos como una persona con un producto o una escena sin esfuerzo. En consecuencia, elimina artefactos comunes como fusiones no coincidentes, produciendo resultados coherentes.

El modelo destaca en la consistencia de una sola imagen. Preserva las identidades faciales a través de poses, estilos y filtros, lo que resulta invaluable para aplicaciones en publicidad y personalización. Para imágenes de productos, Qwen-Image-Edit-2509 mantiene la integridad del objeto, asegurando que las ediciones no distorsionen atributos clave. Además, maneja elementos de texto de manera integral, permitiendo modificaciones de contenido, fuentes, colores e incluso texturas. Esta versatilidad proviene de los mecanismos integrados de ControlNet, que incorporan mapas de profundidad, detección de bordes y puntos clave para una guía precisa.
Técnicamente, Qwen-Image-Edit-2509 se basa en la arquitectura fundamental de Qwen-Image, pero incorpora técnicas de entrenamiento avanzadas. Los desarrolladores lo entrenaron utilizando métodos de concatenación de imágenes para facilitar entradas de múltiples imágenes. Por ejemplo, la combinación de "persona + persona" o "persona + escena" aprovecha flujos de datos concatenados, mejorando la capacidad del modelo para fusionar visuales dispares. Además, la arquitectura integra procesos basados en difusión, donde el ruido se elimina progresivamente para generar imágenes refinadas. Este enfoque, común en variantes de difusión estable, permite la generación condicional basada en las indicaciones del usuario.
En cuanto a los puntos de referencia, Qwen-Image-Edit-2509 demuestra un rendimiento superior en métricas de consistencia. Las evaluaciones internas muestran que supera a sus competidores en la preservación facial, con puntuaciones de similitud que superan el 95% en diversas ediciones. Los puntos de referencia de consistencia de productos revelan una distorsión mínima, lo que lo hace ideal para el comercio electrónico. Sin embargo, los datos cuantitativos de fuentes externas siguen siendo limitados debido a su reciente lanzamiento. No obstante, las demostraciones de usuarios en plataformas como Hugging Face resaltan su ventaja sobre modelos como Stable Diffusion XL en la mezcla de múltiples elementos.
Las aplicaciones abundan para Qwen-Image-Edit-2509. Los especialistas en marketing lo utilizan para crear anuncios personalizados editando sin problemas la ubicación de los productos. Los diseñadores lo emplean para la creación rápida de prototipos, alterando escenas sin retoques manuales. Además, en los videojuegos, facilita la generación dinámica de activos. Un ejemplo ilustrativo implica transformar el atuendo de una persona: una imagen de entrada de una mujer con ropa informal, combinada con una referencia de vestido negro, produce un resultado donde el vestido se ajusta naturalmente, preservando la postura y la iluminación. Esta capacidad, como se muestra en las demostraciones visuales, subraya su utilidad práctica.


Pasando a la implementación, los desarrolladores acceden a Qwen-Image-Edit-2509 a través de repositorios de GitHub y espacios de Hugging Face. La instalación generalmente implica clonar el repositorio y configurar dependencias como PyTorch. Un script de uso básico podría verse así:
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
Dicho código permite iteraciones rápidas. Sin embargo, los usuarios deben considerar los requisitos computacionales, ya que la inferencia exige aceleración por GPU para una velocidad óptima.
A pesar de sus puntos fuertes, Qwen-Image-Edit-2509 enfrenta desafíos. Las ediciones de alta resolución pueden consumir una memoria significativa, y las indicaciones complejas ocasionalmente conducen a inconsistencias. No obstante, las contribuciones continuas de la comunidad a través de canales de código abierto mitigan estos problemas. En general, este modelo redefine la edición de imágenes combinando precisión con accesibilidad.
Qwen3-TTS-Flash: Acelerando la Síntesis de Texto a Voz
Qwen3-TTS-Flash emerge como una potencia en la tecnología de texto a voz (TTS), priorizando la velocidad y la naturalidad. Los ingenieros de Qwen lo diseñaron para ofrecer voces similares a las humanas con una latencia mínima, abordando los cuellos de botella en aplicaciones en tiempo real. Específicamente, logra una latencia del primer paquete de solo 97 ms en entornos de un solo hilo, lo que permite interacciones fluidas en chatbots y asistentes virtuales.
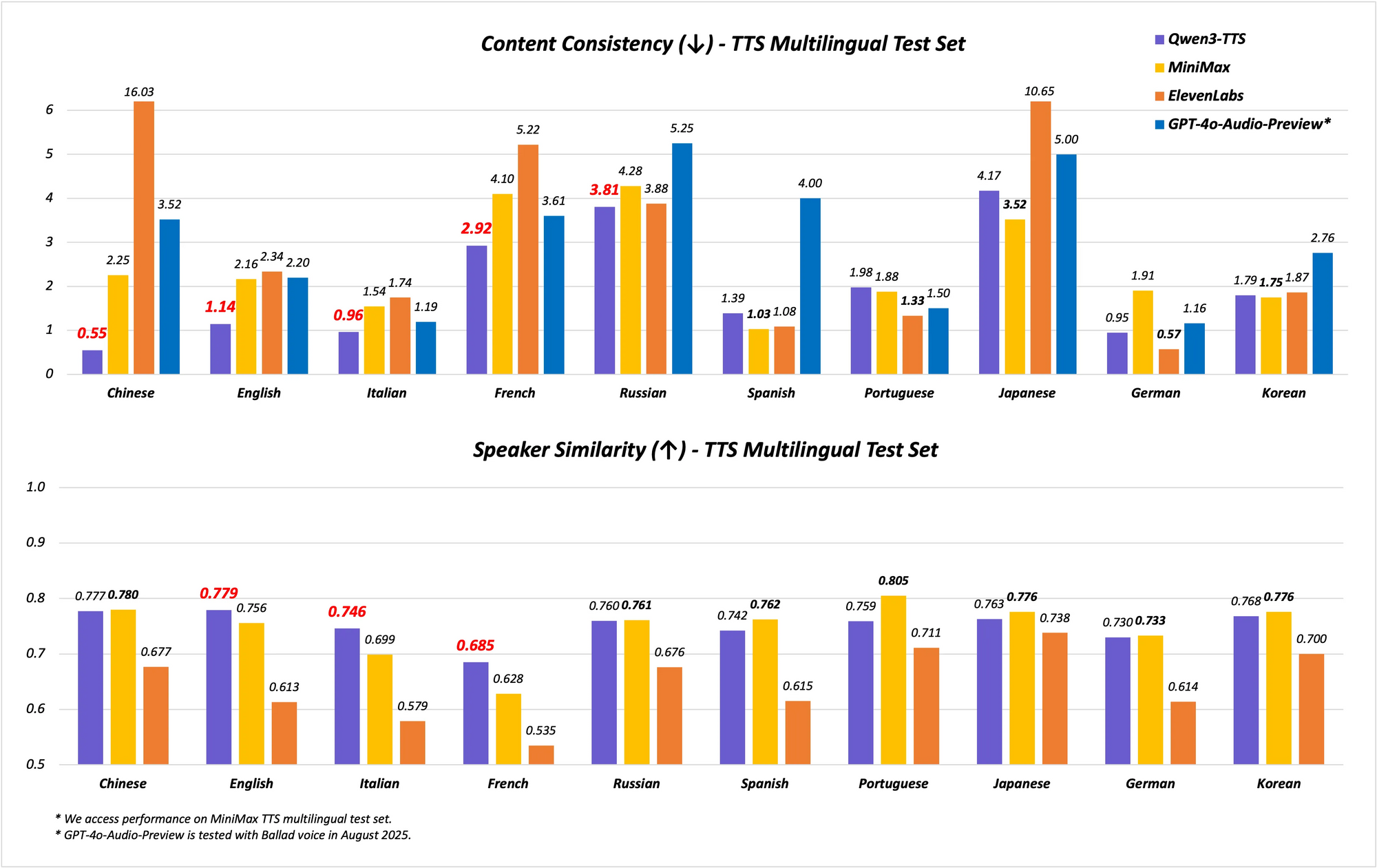
El modelo admite capacidades multilingües y multidialectales, cubriendo 10 idiomas con 17 voces expresivas. Destaca en la estabilidad del chino y el inglés, logrando un rendimiento de vanguardia (SOTA) en puntos de referencia como el conjunto de pruebas Seed-TTS-Eval. Aquí, supera a modelos como SeedTTS, MiniMax y GPT-4o-Audio-Preview en métricas de estabilidad. Además, en evaluaciones multilingües en el conjunto de pruebas MiniMax TTS, Qwen3-TTS-Flash registra la tasa de error de palabras (WER) más baja para chino, inglés, italiano y francés.
El soporte de dialectos distingue a Qwen3-TTS-Flash. Maneja nueve dialectos chinos, incluyendo cantonés, hokkien, sichuanés, pekinés, nankinés, tianjinés y shaanxi. Esta característica permite un habla culturalmente matizada, esencial en mercados diversos. Además, el modelo adapta los tonos automáticamente, extrayendo de grandes volúmenes de datos de entrenamiento para coincidir con el sentimiento de entrada. El manejo robusto de texto mejora aún más la fiabilidad, ya que extrae información clave de formatos complejos como fechas, números y acrónimos.

Arquitectónicamente, Qwen3-TTS-Flash emplea un marco codificador-decodificador basado en transformadores, optimizado para inferencia de baja latencia. Utiliza representaciones de múltiples libros de códigos para un modelado de voz más rico, mejorando la expresividad. El entrenamiento involucró vastos conjuntos de datos que abarcan 119 idiomas para texto y 19 para comprensión del habla, aunque la salida se centra en 10 idiomas. Esta configuración permite la generación interlingüística, donde las entradas en un idioma producen salidas en otro sin problemas.
Los puntos de referencia ilustran su destreza. En las pruebas de estabilidad, Qwen3-TTS-Flash obtiene una puntuación más alta en similitud de timbre y naturalidad en comparación con ElevenLabs y GPT-4o. Por ejemplo:
| Punto de Referencia | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| Estabilidad en Chino | SOTA | Inferior | Inferior |
| WER en Inglés | Más bajo | Superior | Superior |
| Similitud de Timbre Multilingüe | SOTA | Inferior | Inferior |
Estos resultados provienen de evaluaciones rigurosas, posicionándolo como líder en TTS.
En las demostraciones, Qwen3-TTS-Flash genera habla expresiva, como describir un "latte de miel y lavanda" con entusiasmo o manejar diálogos en dialectos. Las transcripciones de video revelan su capacidad para procesar entradas en idiomas mixtos, como "I'm really happy today. I know that girl from China", entregadas con voces acentuadas. Las aplicaciones incluyen sistemas de respuesta de voz interactiva (IVR), NPCs de juegos y creación de contenido, donde la baja latencia duplica la eficiencia.
La implementación requiere acceder al modelo a través de APIs o demostraciones de Hugging Face. Una invocación de Python de ejemplo:
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
Esta simplicidad acelera el desarrollo. Sin embargo, la precisión del dialecto puede variar con entradas poco comunes, lo que requiere un ajuste fino.
Qwen3-TTS-Flash transforma el TTS al equilibrar velocidad, calidad y diversidad, haciéndolo indispensable para los sistemas de IA modernos.
Presentando Qwen3-Omni: La Potencia Multimodal Unificada
La introducción de Qwen3-Omni marca un hito en la IA multimodal, ya que Qwen integra texto, imagen, audio y video en un único modelo de extremo a extremo. Esta unificación nativa evita las compensaciones de modalidad, permitiendo un razonamiento transmodal más profundo. El modelo procesa 119 idiomas para texto, 19 para entrada de voz y 10 para salida de voz, con una notable latencia de 211 ms para las respuestas.
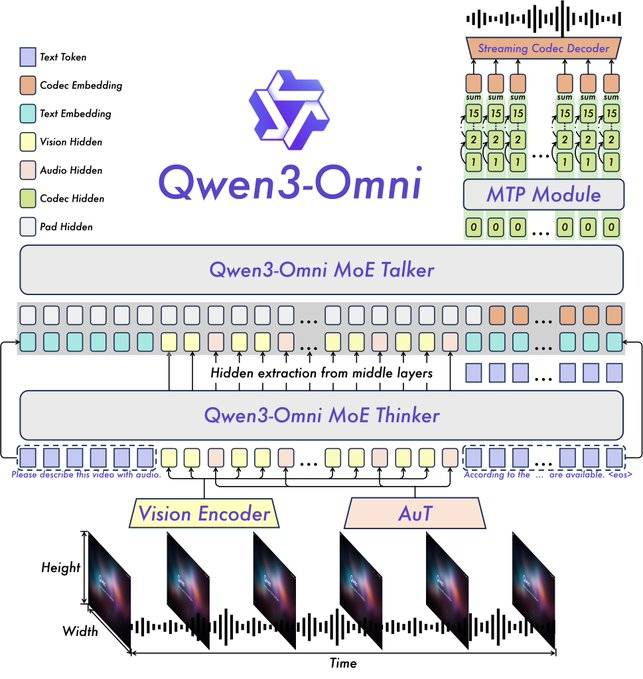
Las características clave incluyen un rendimiento SOTA en 22 de 36 puntos de referencia de audio y audio-visuales, indicaciones de sistema personalizables, llamada de herramientas incorporada y un modelo de subtitulado de código abierto con bajas tasas de alucinación. Qwen ha lanzado variantes de código abierto como Qwen3-Omni-30B-A3B-Instruct para seguir instrucciones y Qwen3-Omni-30B-A3B-Thinking para un razonamiento mejorado.
La arquitectura se basa en el marco Thinker-Talker de Qwen2.5-Omni, con mejoras como la sustitución del codificador de audio Whisper por un Audio Transformer (AuT) para una mejor representación. El manejo de voz con múltiples libros de códigos enriquece la salida de voz, mientras que el contexto extendido admite más de 30 minutos de audio. Esto permite un razonamiento de modalidad completa, donde las entradas de video informan las respuestas de audio.
Los puntos de referencia confirman su dominio. Logra un rendimiento SOTA general en 32 puntos de referencia, destacando en la comprensión y generación de audio. Por ejemplo, en tareas audiovisuales, supera a modelos como GPT-4o en latencia y precisión. Una tabla de comparación:
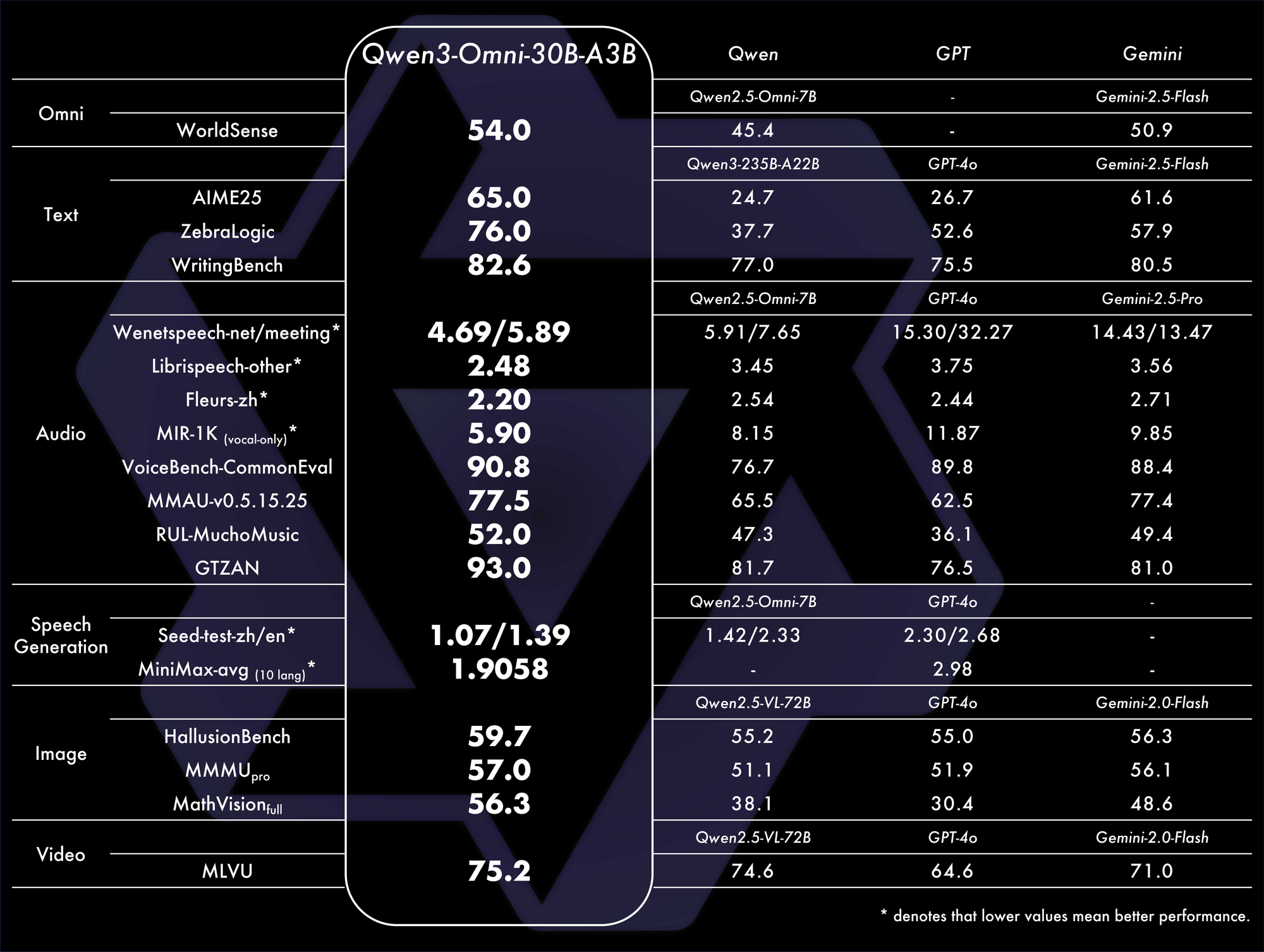
Estas métricas resaltan su eficiencia en escenarios del mundo real.
Las aplicaciones abarcan chat de voz, análisis de video y agentes multimodales. Por ejemplo, analiza un clip de video y genera resúmenes hablados, ideal para herramientas de accesibilidad. Las demostraciones en Qwen Chat muestran interacciones de voz y video, donde los usuarios consultan imágenes o audios verbalmente.
Desde GitHub, el archivo README lo describe como capaz de generar voz en tiempo real a partir de diversas entradas. La configuración implica:
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
Este enfoque modular facilita la personalización. Los desafíos incluyen altas demandas computacionales para el procesamiento de video, pero optimizaciones como la cuantificación ayudan.
La introducción de Qwen3-Omni consolida las modalidades, fomentando ecosistemas de IA innovadores.
Sinergias entre los Nuevos Modelos de Qwen e Implicaciones Futuras
Qwen-Image-Edit-2509, Qwen3-TTS-Flash y Qwen3-Omni se complementan entre sí, permitiendo flujos de trabajo de extremo a extremo. Por ejemplo, edite una imagen con Qwen-Image-Edit-2509, descríbala a través de Qwen3-Omni y vocalice la salida con Qwen3-TTS-Flash. Esta integración amplifica la utilidad en la creación de contenido y la automatización.
Además, su naturaleza de código abierto invita a mejoras por parte de la comunidad. Los desarrolladores que utilizan Apidog pueden probar las APIs de manera eficiente, asegurando integraciones robustas.
Sin embargo, surgen consideraciones éticas, como el uso indebido en deepfakes. Qwen lo mitiga a través de salvaguardias.
En conclusión, los lanzamientos de Qwen redefinen los paisajes de la IA. Al avanzar las fronteras técnicas, empoderan a los usuarios para lograr más. A medida que la adopción crezca, estos modelos impulsarán la próxima ola de innovación.