
Qwen-Image, un modelo fundacional de imagen MMDiT de 20B de vanguardia del equipo Qwen de Alibaba Cloud, redefine las posibilidades de la creación visual impulsada por la IA. Lanzado el 4 de agosto de 2025, este modelo ofrece capacidades inigualables en la generación de imágenes de alta calidad, la representación de texto multilingüe complejo y la realización de ediciones de imagen precisas. Ya sea que esté creando elementos visuales de marketing dinámicos o analizando datos de imagen complejos, Qwen-Image equipa a los desarrolladores con herramientas robustas para dar vida a las ideas.
¿Qué es Qwen-Image? Una visión técnica general
Qwen-Image, parte de la serie Qwen de Alibaba Cloud, es un modelo de transformador de difusión multimodal (MMDiT) con 20 mil millones de parámetros, diseñado tanto para la generación como para la edición de imágenes. A diferencia de los modelos tradicionales que se centran únicamente en generar elementos visuales, Qwen-Image integra una representación de texto avanzada y una comprensión de imágenes, lo que lo convierte en una herramienta versátil para tareas creativas y analíticas. El modelo, de código abierto bajo la licencia Apache 2.0, es accesible a través de plataformas como GitHub, Hugging Face y ModelScope, lo que permite a los desarrolladores integrarlo en diversos flujos de trabajo.

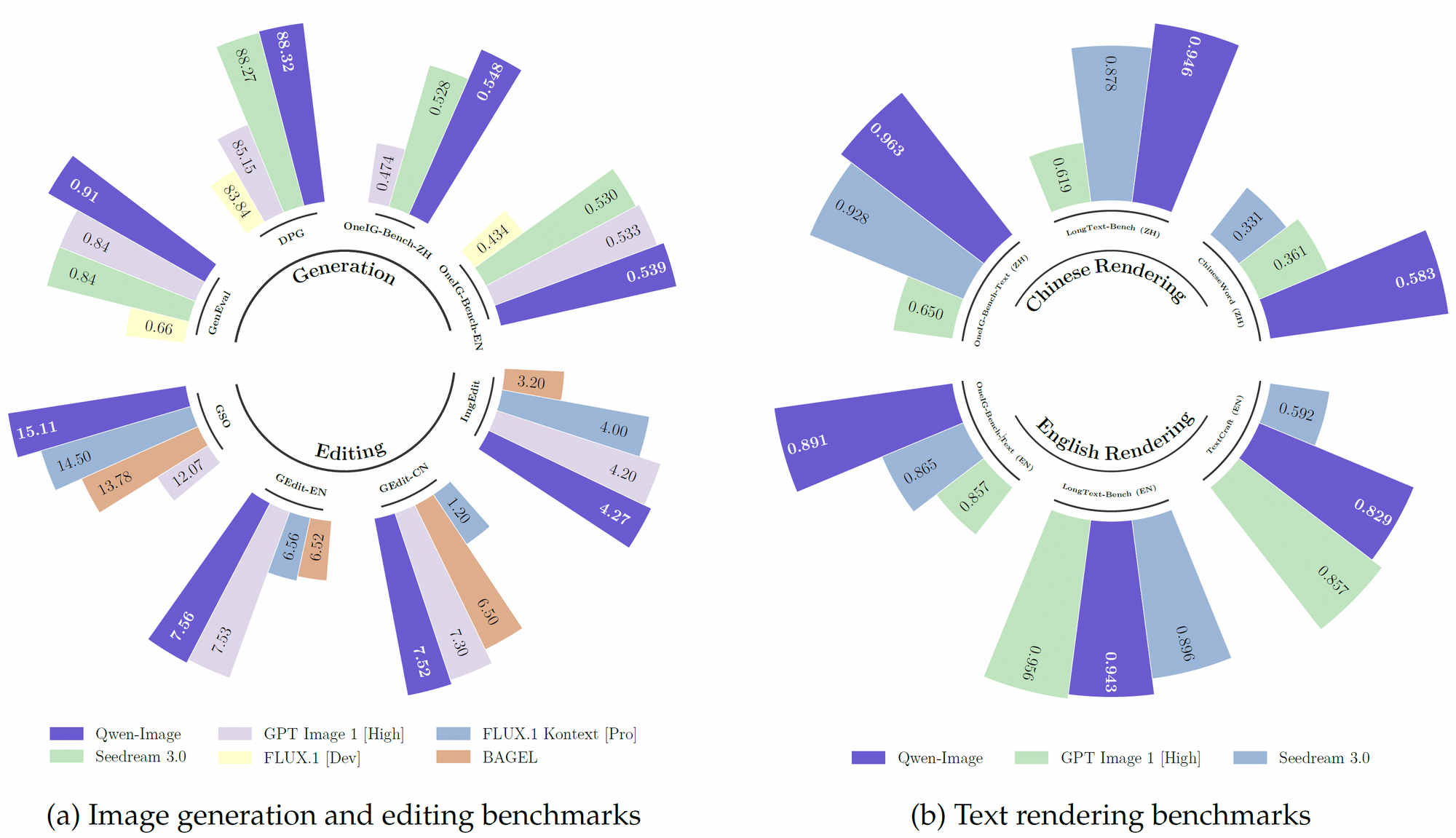
Además, Qwen-Image aprovecha un robusto conjunto de datos de preentrenamiento, que incorpora más de 30 billones de tokens en 119 idiomas, con un enfoque en chino e inglés. Este extenso conjunto de datos, combinado con técnicas de aprendizaje por refuerzo, permite al modelo manejar tareas complejas como la representación de texto multilingüe y la manipulación precisa de objetos. En consecuencia, supera a muchos modelos existentes en puntos de referencia como GenEval, DPG y LongText-Bench.
Características clave de Qwen-Image
Representación de texto superior para elementos visuales multilingües
Qwen-Image destaca en la representación de texto complejo dentro de las imágenes, una característica que lo diferencia de la competencia. Admite tanto idiomas alfabéticos (por ejemplo, inglés) como escrituras logográficas (por ejemplo, chino), lo que garantiza una integración de texto de alta fidelidad. Por ejemplo, el modelo puede generar un póster de película con diseños de texto precisos, como un título como "Imaginación Desatada" y subtítulos en varias filas, manteniendo la coherencia tipográfica. Esta capacidad se deriva de su entrenamiento en diversos conjuntos de datos, incluidos LongText-Bench y ChineseWord, donde logra un rendimiento de vanguardia.
Además, Qwen-Image maneja diseños de varias líneas y semántica a nivel de párrafo con una precisión notable. En un escenario de prueba, representó con precisión un poema manuscrito en papel amarillento dentro de una imagen, a pesar de que el texto ocupaba menos de una décima parte del espacio visual. Esta precisión lo hace ideal para aplicaciones como señalización digital, diseño de pósters y visualización de documentos.
Capacidades avanzadas de edición de imágenes
Más allá de la representación de texto, Qwen-Image ofrece sofisticadas funciones de edición de imágenes. Admite operaciones como la transferencia de estilo, la inserción de objetos, la mejora de detalles y la manipulación de la pose humana. Por ejemplo, los usuarios pueden indicar al modelo que "añada un cielo soleado a esta imagen" o "cambie esta pintura a un estilo Van Gogh", y Qwen-Image ofrece resultados coherentes. Su paradigma de entrenamiento multitarea mejorado garantiza que las ediciones conserven el significado semántico y el realismo visual.
Además, la capacidad del modelo para editar texto dentro de las imágenes es particularmente notable. Los desarrolladores pueden modificar el texto en letreros o pósters sin alterar el contexto visual circundante, una característica valiosa para la publicidad y la creación de contenido. Estas capacidades son compatibles con la profunda comprensión visual de Qwen-Image, que le permite interpretar y manipular elementos de imagen con precisión.
Comprensión visual integral
Qwen-Image no solo crea o edita, sino que comprende. El modelo admite un conjunto de tareas de comprensión de imágenes, que incluyen detección de objetos, segmentación semántica, estimación de profundidad, detección de bordes (Canny), síntesis de nuevas vistas y superresolución. Estas tareas son impulsadas por su capacidad para procesar entradas de alta resolución y extraer detalles finos. Por ejemplo, Qwen-Image puede generar cuadros delimitadores para objetos descritos en lenguaje natural, como "detectar al perro Husky en la escena del metro", lo que lo convierte en una herramienta poderosa para el análisis visual.
Además, su soporte para múltiples idiomas mejora su usabilidad en aplicaciones globales. Al integrarse con herramientas como la Herramienta de Mejora de Prompts Qwen-Plus, los desarrolladores pueden optimizar los prompts para un mejor rendimiento multilingüe, asegurando resultados precisos en diversos contextos lingüísticos.
Excelencia en el rendimiento en diferentes benchmarks
Qwen-Image supera consistentemente a sus competidores en múltiples benchmarks públicos, incluyendo GenEval, DPG, OneIG-Bench, GEdit, ImgEdit y GSO. Su rendimiento superior en la representación de texto, particularmente para el chino, es evidente en benchmarks como TextCraft, donde supera a los modelos de vanguardia existentes. Además, sus capacidades generales de generación de imágenes admiten una amplia gama de estilos artísticos, desde escenas fotorrealistas hasta estéticas de anime, lo que lo convierte en una opción versátil para profesionales creativos.
Arquitectura técnica de Qwen-Image
Transformador de Difusión Multimodal (MMDiT)
En su esencia, Qwen-Image emplea una arquitectura de Transformador de Difusión Multimodal (MMDiT), que combina las fortalezas de los modelos de difusión y los transformadores. Este enfoque híbrido permite al modelo procesar de manera eficiente tanto entradas visuales como textuales. El proceso de difusión refina iterativamente las entradas ruidosas en imágenes coherentes, mientras que el componente del transformador maneja relaciones complejas entre el texto y los elementos visuales.
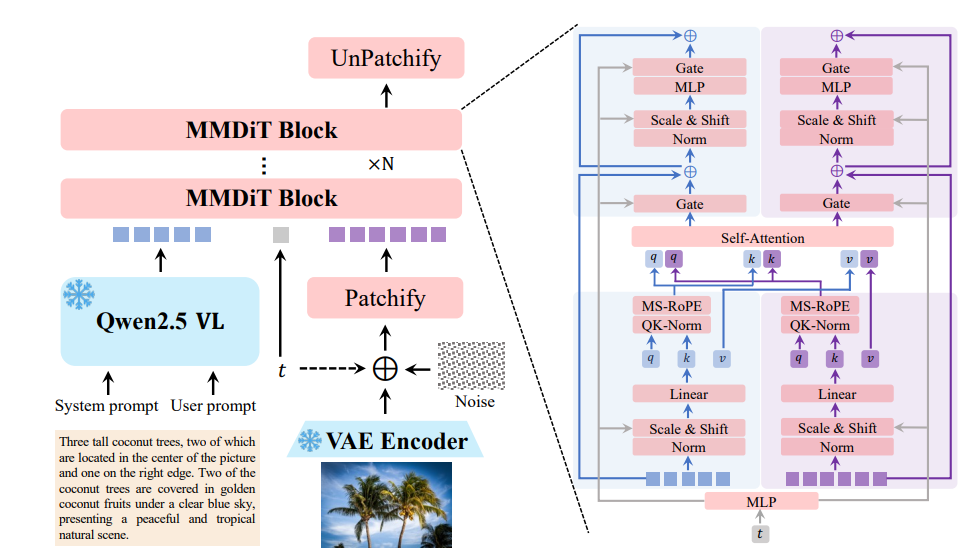
Los 20 mil millones de parámetros del modelo están optimizados para la eficiencia, lo que le permite ejecutarse en hardware de consumo con tan solo 4 GB de VRAM al utilizar técnicas como la cuantificación FP8 y la descarga capa por capa. Esta accesibilidad hace que Qwen-Image sea adecuado tanto para desarrolladores empresariales como individuales.
Preentrenamiento y ajuste fino
El conjunto de datos de preentrenamiento de Qwen-Image es una piedra angular de su rendimiento. Abarcando más de 30 billones de tokens, el conjunto de datos incluye datos web, documentos similares a PDF y datos sintéticos generados por modelos como Qwen2.5-VL y Qwen2.5-Coder. El proceso de preentrenamiento ocurre en tres etapas:

- Etapa 1 (S1): El modelo se preentrena con 30 billones de tokens con una longitud de contexto de 4K tokens, estableciendo habilidades fundamentales de lenguaje y visuales.
- Etapa 2: El aprendizaje por refuerzo mejora las capacidades de razonamiento y específicas de la tarea del modelo.
- Etapa 3: El ajuste fino con conjuntos de datos curados mejora la alineación con las preferencias del usuario y tareas específicas como la representación de texto y la edición de imágenes.
Este enfoque multietapa garantiza que Qwen-Image sea robusto y adaptable, capaz de manejar diversas tareas con alta precisión.
Integración con herramientas de desarrollo
Qwen-Image se integra perfectamente con frameworks de desarrollo populares como Diffusers y DiffSynth-Studio. Por ejemplo, los desarrolladores pueden usar el siguiente código Python para generar imágenes con Qwen-Image:
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "La entrada de una cafetería con un cartel de pizarra que dice 'Qwen Coffee 😊 $2 por taza'."
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
Este fragmento de código demuestra cómo los desarrolladores pueden aprovechar las capacidades de Qwen-Image para generar elementos visuales de alta calidad con una configuración mínima. Herramientas como Apidog simplifican aún más la integración de la API, permitiendo la creación rápida de prototipos y la implementación.
Aplicaciones prácticas de Qwen-Image
Generación de contenido creativo
La capacidad de Qwen-Image para generar escenas fotorrealistas, pinturas impresionistas y elementos visuales de estilo anime lo convierte en una herramienta poderosa para artistas y diseñadores. Por ejemplo, un diseñador gráfico puede crear un póster de película con diseños de texto dinámicos e imágenes vibrantes, como se demostró en un caso de prueba donde Qwen-Image produjo un póster para "Imaginación Desatada" con una computadora futurista emitiendo criaturas caprichosas.

Publicidad y Marketing
En publicidad, las capacidades de representación y edición de texto de Qwen-Image permiten la creación de campañas visualmente atractivas. Los especialistas en marketing pueden generar pósters con una ubicación precisa del texto o editar elementos visuales existentes para actualizar mensajes promocionales, asegurando la coherencia de la marca y la cohesión visual.

Análisis visual y automatización
Para industrias como el comercio electrónico y los sistemas autónomos, las tareas de comprensión de imágenes de Qwen-Image, como la detección de objetos y la segmentación semántica, ofrecen un valor significativo. Las plataformas minoristas pueden usar el modelo para etiquetar automáticamente productos en imágenes, mientras que los vehículos autónomos pueden aprovechar su estimación de profundidad para la navegación.
Herramientas educativas
La capacidad de Qwen-Image para generar elementos visuales educativos, como diagramas con anotaciones de texto precisas, es compatible con las plataformas de e-learning. Por ejemplo, puede crear una ilustración detallada de un concepto científico con componentes etiquetados, mejorando el compromiso y la comprensión de los estudiantes.

Comparando Qwen-Image con la competencia
En comparación con modelos como DALL-E 3 y Stable Diffusion, Qwen-Image destaca por su representación de texto multilingüe y sus capacidades de edición avanzadas. Si bien DALL-E 3 sobresale en la generación creativa de imágenes, tiene dificultades con diseños de texto complejos, particularmente para escrituras logográficas. Stable Diffusion, aunque versátil, carece de la profunda comprensión visual que ofrece el conjunto de tareas de comprensión de Qwen-Image.
Además, la naturaleza de código abierto de Qwen-Image y su compatibilidad con hardware de baja memoria le dan una ventaja para los desarrolladores con recursos limitados. Su rendimiento en benchmarks como TextCraft y GEdit solidifica aún más su posición como un modelo líder en IA multimodal.
Desafíos y limitaciones
A pesar de sus puntos fuertes, Qwen-Image se enfrenta a desafíos. La dependencia del modelo de conjuntos de datos a gran escala plantea preocupaciones sobre la privacidad de los datos y el abastecimiento ético, aunque Alibaba Cloud se adhiere a directrices estrictas. Además, si bien el modelo admite más de 100 idiomas, su rendimiento puede variar para dialectos menos representados, lo que requiere un ajuste fino adicional.
Además, las demandas computacionales del modelo de 20B parámetros pueden ser significativas sin técnicas de optimización como la cuantificación FP8. Los desarrolladores deben equilibrar el rendimiento y las limitaciones de recursos al implementar Qwen-Image en entornos de producción.
Perspectivas futuras para Qwen-Image
De cara al futuro, Qwen-Image está preparado para evolucionar aún más. El equipo de Qwen planea lanzar una versión del modelo específica para edición, mejorando sus capacidades para aplicaciones de nivel profesional. La integración con frameworks emergentes como vLLM y el soporte continuo para LoRA y flujos de trabajo de ajuste fino ampliarán su accesibilidad.
Además, los avances en el aprendizaje por refuerzo, como se ve en modelos como Qwen3, sugieren que Qwen-Image podría incorporar capacidades de razonamiento más profundas, permitiendo tareas de razonamiento visual más complejas. A medida que la comunidad de IA continúe contribuyendo a su desarrollo, Qwen-Image tiene el potencial de redefinir la creación y comprensión visual.
Primeros pasos con Qwen-Image
Para comenzar a usar Qwen-Image, los desarrolladores pueden acceder a los pesos del modelo en GitHub o Hugging Face. El blog oficial en qwenlm.github.io proporciona instrucciones detalladas de configuración y casos de uso. Para una experiencia práctica, visite Qwen Chat y seleccione "Generación de imágenes" para probar las capacidades del modelo.
Para la integración de API, herramientas como Apidog simplifican el proceso al ofrecer una interfaz fácil de usar para probar e implementar las características de Qwen-Image. Descargue Apidog de forma gratuita para optimizar su flujo de trabajo de desarrollo.
Conclusión: Por qué Qwen-Image es importante
Qwen-Image representa un salto significativo en la IA multimodal, combinando la representación de texto avanzada, la edición precisa de imágenes y una sólida comprensión visual. Su disponibilidad de código abierto, su extenso preentrenamiento y su compatibilidad con herramientas de desarrollo lo convierten en una opción versátil para creadores, desarrolladores e investigadores. Al abordar desafíos como el soporte multilingüe y la eficiencia de recursos, Qwen-Image establece un nuevo estándar para la creación visual impulsada por la IA.
A medida que la IA continúa evolucionando, modelos como Qwen-Image desempeñarán un papel fundamental en la reducción de la brecha entre el lenguaje y las imágenes, abriendo nuevas posibilidades para aplicaciones creativas y analíticas. Ya sea que esté construyendo una campaña de marketing, analizando datos visuales o creando contenido educativo, Qwen-Image ofrece las herramientas para dar vida a su visión.