
En el mundo de la inteligencia artificial, que evoluciona rápidamente, se ha alcanzado un nuevo hito con el lanzamiento de Qwen 2.5 Omni 7B. Este revolucionario modelo de Alibaba Cloud representa un importante avance en la IA multimodal, combinando la capacidad de procesar y comprender múltiples formas de entrada al tiempo que genera salidas de texto y voz. Profundicemos en lo que hace que este modelo sea realmente especial y en cómo está remodelando nuestra comprensión de las capacidades de la IA.
El verdadero significado de "Omni" dentro de Qwen 2.5 Omni 7B
El término "Omni" en Qwen 2.5 Omni 7B no es solo una marca inteligente, es una descripción fundamental de las capacidades del modelo. A diferencia de muchos modelos multimodales que sobresalen en uno o dos tipos de datos, Qwen 2.5 Omni 7B está diseñado desde cero para percibir y comprender:
- Texto (lenguaje escrito)
- Imágenes (información visual)
- Audio (sonidos y lenguaje hablado)
- Vídeo (contenido visual en movimiento con dimensión temporal)
Voice Chat + Video Chat! Just in Qwen Chat (https://t.co/FmQ0B9tiE7)! You can now chat with Qwen just like making a phone call or making a video call! Check the demo in https://t.co/42iDe4j1Hs
— Qwen (@Alibaba_Qwen) March 26, 2025
What's more, we opensource the model behind all this, Qwen2.5-Omni-7B, under the… pic.twitter.com/LHQOQrl9Ha
Lo que es aún más impresionante es que este modelo no solo recibe estas variadas entradas, sino que puede responder con salidas de texto y voz natural de forma continua. Esta capacidad "de cualquier a cualquier" representa un avance significativo hacia interacciones de IA más naturales y similares a las humanas.
La innovadora arquitectura de Qwen 2.5 Omni 7B: Explicada
Thinker-Talker: Un nuevo paradigma
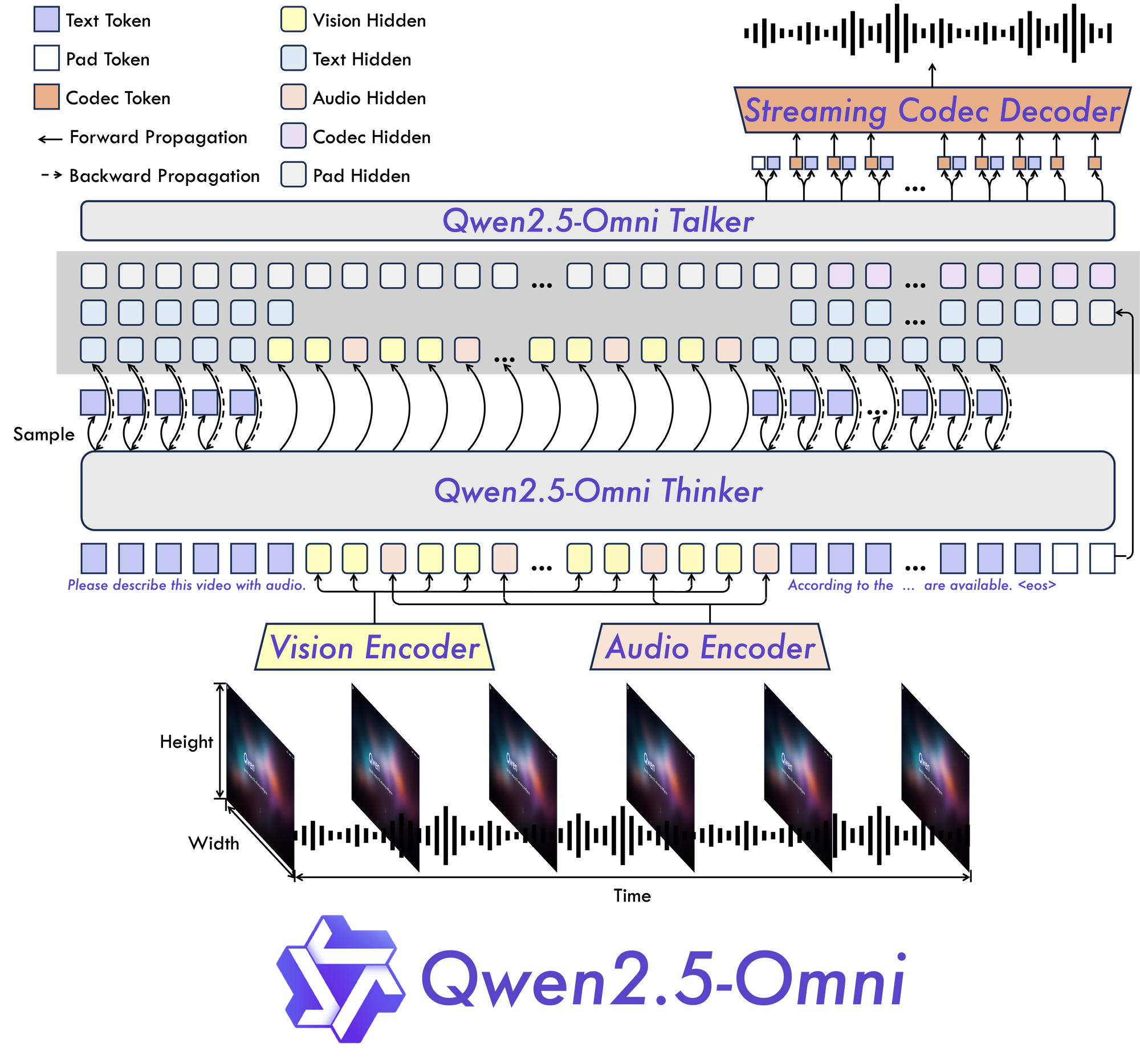
En el corazón de Qwen 2.5 Omni 7B se encuentra su arquitectura fundamental "Thinker-Talker". Este novedoso diseño crea un modelo construido específicamente para ser multimodal de extremo a extremo, lo que permite un procesamiento perfecto a través de diferentes tipos de información.
Como sugiere el nombre, esta arquitectura separa el procesamiento cognitivo de la información (pensar) de la generación de salidas (hablar). Esta separación permite que el modelo gestione eficazmente las complejidades inherentes de los datos multimodales y produzca respuestas adecuadas en múltiples formatos.
TMRoPE: Resolviendo el desafío de la alineación temporal
Una de las innovaciones más significativas en Qwen 2.5 Omni 7B es su mecanismo RoPE multimodal alineado en el tiempo (TMRoPE). Este avance aborda uno de los aspectos más desafiantes de la IA multimodal: la sincronización de datos temporales de diferentes fuentes.
Al procesar vídeo y audio simultáneamente, el modelo necesita comprender cómo los eventos visuales se alinean con los sonidos o el habla correspondientes. Por ejemplo, hacer coincidir los movimientos de los labios de una persona con sus palabras habladas requiere una alineación temporal precisa. TMRoPE proporciona el marco sofisticado para lograr esta sincronización, lo que permite que el modelo construya una comprensión coherente de las entradas multimodales que se desarrollan con el tiempo.
Diseñado para la interacción en tiempo real
Qwen 2.5 Omni 7B se construyó teniendo en cuenta las aplicaciones en tiempo real. La arquitectura admite la transmisión de baja latencia, lo que permite el procesamiento de entrada en fragmentos y la generación de salida inmediata. Esto lo hace ideal para aplicaciones que requieren interacciones receptivas, como asistentes de voz, análisis de vídeo en vivo o servicios de traducción en tiempo real.
Rendimiento de Qwen 2.5 Omni 7B: Los puntos de referencia hablan por sí solos
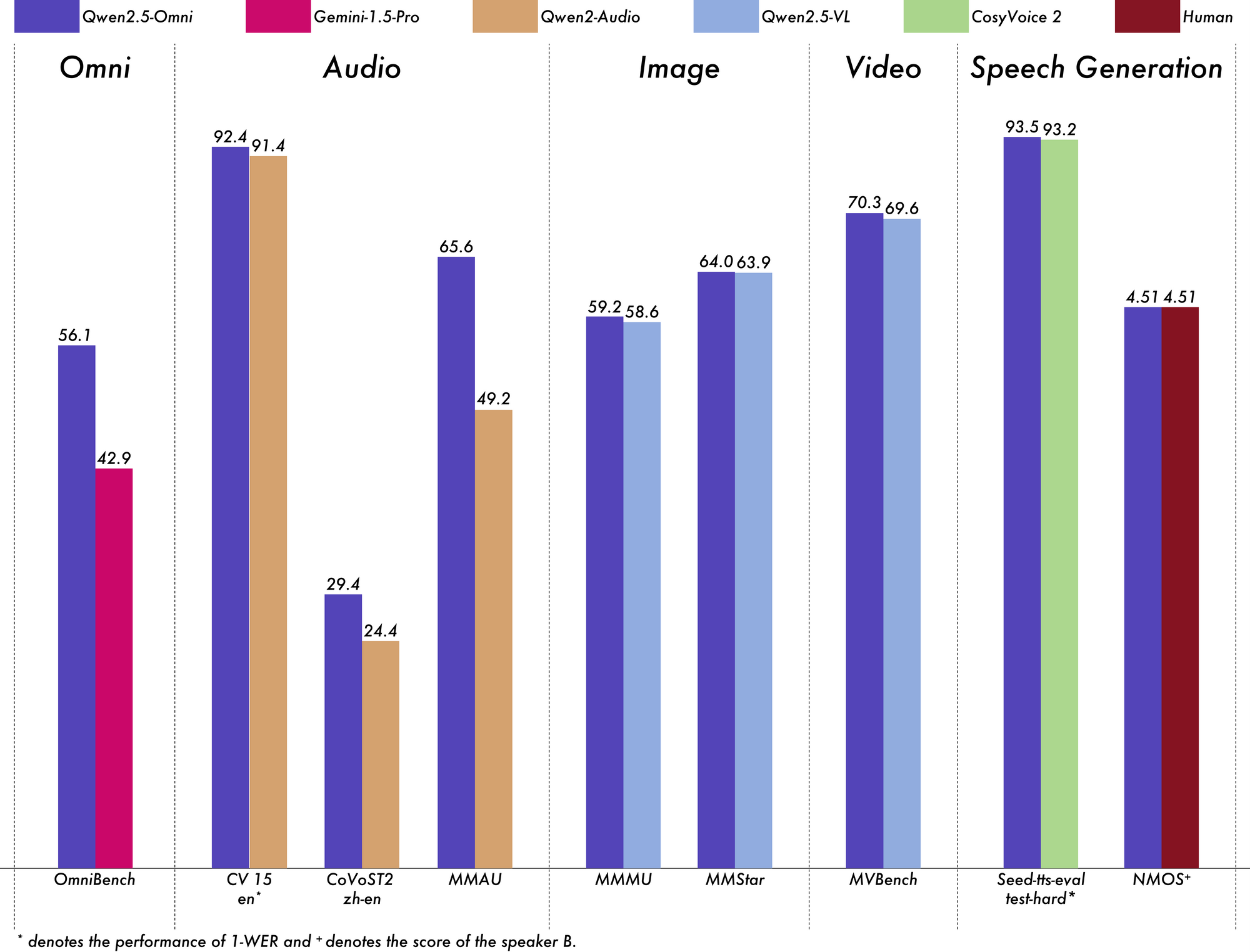
La verdadera prueba de cualquier modelo de IA es su rendimiento en puntos de referencia rigurosos, y Qwen 2.5 Omni 7B ofrece resultados impresionantes en todos los ámbitos.
Liderando en la comprensión multimodal
En el punto de referencia OmniBench para la comprensión multimodal general, Qwen 2.5 Omni 7B alcanza una puntuación media del 56,13%. Esto supera significativamente a otros modelos como Gemini-1.5-Pro (42,91%) y MIO-Instruct (33,80%). Su rendimiento excepcional en categorías específicas de OmniBench es particularmente notable:
- Tareas de voz: 55,25%
- Tareas de eventos de sonido: 60,00%
- Tareas de música: 52,83%
Este rendimiento integral demuestra la capacidad del modelo para integrar y razonar eficazmente a través de múltiples modalidades.
Sobresaliendo en el procesamiento de audio
Para las tareas de audio a texto, Qwen 2.5 Omni 7B muestra resultados casi de última generación en el reconocimiento automático del habla (ASR). En el conjunto de datos Librispeech, alcanza tasas de error de palabras (WER) que oscilan entre el 1,6% y el 3,5%, comparables a modelos especializados como Whisper-large-v3.
En el reconocimiento de eventos de sonido en el conjunto de datos Meld, alcanza el mejor rendimiento de su clase con una puntuación de 0,570. El modelo incluso sobresale en la comprensión de la música, con una puntuación de 0,88 en el punto de referencia GiantSteps Tempo.
Fuerte comprensión de la imagen
Cuando se trata de tareas de imagen a texto, Qwen 2.5 Omni 7B alcanza una puntuación de 59,2 en el punto de referencia MMMU, notablemente cerca del 60,0 de GPT-4o-mini. En la tarea RefCOCO Grounding, alcanza una precisión del 90,5%, superando el 73,2% de Gemini 1.5 Pro.
Impresionante comprensión de vídeo
Para las tareas de vídeo a texto sin subtítulos, el modelo obtiene una puntuación de 64,3 en Video-MME, casi igualando el rendimiento de los modelos de vídeo especializados. Cuando se añaden subtítulos, el rendimiento salta a 72,4, lo que demuestra la capacidad del modelo para integrar múltiples fuentes de información de forma eficaz.
Generación de voz natural
Qwen 2.5 Omni 7B no solo entiende, sino que habla. Para la generación de voz, alcanza puntuaciones de similitud de hablantes que oscilan entre 0,754 y 0,752, comparables a modelos dedicados de texto a voz como Seed-TTS_RL. Esto demuestra su capacidad para generar voz con un sonido natural que mantiene las características de la voz del hablante original.
Manteniendo fuertes capacidades de texto
A pesar de su enfoque multimodal, Qwen 2.5 Omni 7B sigue funcionando admirablemente en tareas de solo texto. Logra buenos resultados en el razonamiento matemático (puntuación GSM8K: 88,7%) y la generación de código. Si bien hay una pequeña compensación en comparación con el modelo Qwen2.5-7B de solo texto (que obtiene una puntuación del 91,6% en GSM8K), esta ligera caída es un compromiso razonable para obtener capacidades multimodales tan completas.
Aplicaciones del mundo real de Qwen 2.5 Omni 7B:
Qwen 2.5 Omni is NUTS!
— Jeff Boudier 🤗 (@jeffboudier) March 26, 2025
I can't believe a 7B model
can take text, images, audio, video as input
give text and audio as output
and work so well!
Open source Apache 2.0
Try it, link below!
You really cooked @Alibaba_Qwen ! pic.twitter.com/pn0dnwOqjY
La versatilidad de Qwen 2.5 Omni 7B abre una amplia gama de aplicaciones prácticas en numerosos dominios.
Interfaces de comunicación mejoradas
Sus capacidades de transmisión de baja latencia lo hacen ideal para aplicaciones de chat de voz y vídeo en tiempo real. Imagina asistentes virtuales que puedan ver, oír y hablar de forma natural, comprendiendo tanto las señales de comunicación verbales como las no verbales, al tiempo que responden con voz natural.
Análisis de contenido avanzado
La capacidad del modelo para procesar y comprender diversas modalidades lo posiciona como una herramienta poderosa para el análisis integral de contenido. Puede extraer información de documentos multimedia, identificando automáticamente información clave de texto, imágenes, audio y vídeo simultáneamente.
Interfaces de voz accesibles
Con su sólido rendimiento en el seguimiento de instrucciones de voz de extremo a extremo, Qwen 2.5 Omni 7B permite una interacción más natural y verdaderamente manos libres con la tecnología. Esto podría revolucionar las funciones de accesibilidad para usuarios con discapacidades o situaciones en las que la operación manos libres es esencial.
Generación de contenido creativo
La capacidad del modelo para generar tanto texto como voz natural abre nuevas posibilidades para la creación de contenido. Desde la generación automática de narración para vídeos hasta la creación de materiales educativos interactivos que responden a las preguntas de los estudiantes con explicaciones adecuadas, las aplicaciones son vastas.
Servicio de atención al cliente multimodal
Las empresas podrían implementar Qwen 2.5 Omni 7B para impulsar sistemas de servicio al cliente que puedan analizar las consultas de los clientes desde múltiples canales (llamadas de voz, chats de vídeo, mensajes escritos) y responder de forma natural y adecuada a cada uno.
Consideraciones prácticas y limitaciones
Si bien Qwen 2.5 Omni 7B representa un avance significativo en la IA multimodal, hay algunas consideraciones prácticas que debes tener en cuenta al trabajar con él.
Requisitos de hardware
Las capacidades integrales del modelo conllevan importantes demandas computacionales. El procesamiento incluso de un vídeo relativamente corto de 15 segundos en precisión FP32 requiere aproximadamente 93,56 GB de memoria de GPU. Incluso con precisión BF16, un vídeo de 60 segundos todavía necesita alrededor de 60,19 GB.
Estos requisitos pueden limitar la accesibilidad para los usuarios sin acceso a hardware de alta gama. Sin embargo, el modelo admite varias optimizaciones como Flash Attention 2, que puede ayudar a mejorar el rendimiento en hardware compatible.
Personalización del tipo de voz
Curiosamente, Qwen 2.5 Omni 7B admite múltiples tipos de voz para sus salidas de audio. Actualmente, ofrece dos opciones de voz:
- Chelsie: Una voz femenina descrita como "melosa, aterciopelada" con "calidez suave y claridad luminosa"
- Ethan: Una voz masculina caracterizada como "brillante, optimista" con "energía contagiosa y un ambiente cálido y accesible"
Esta personalización añade otra dimensión a la flexibilidad del modelo en aplicaciones del mundo real.
Consideraciones técnicas de integración
Al implementar Qwen 2.5 Omni 7B, se deben prestar atención a varios detalles técnicos:
- El modelo requiere patrones de indicaciones específicos para la salida de audio
- Se necesitan ajustes coherentes para los parámetros
use_audio_in_videopara conversaciones multirredondas adecuadas - La compatibilidad de la URL de vídeo depende de versiones de biblioteca específicas (torchvision ≥ 0.19.0 para compatibilidad con HTTPS)
- El modelo no está disponible actualmente a través de la API de inferencia de Hugging Face debido a las limitaciones para admitir modelos "de cualquier a cualquier"
El futuro de la IA multimodal
Qwen 2.5 Omni 7B representa más que solo otro modelo de IA: es una visión del futuro de la inteligencia artificial. Al reunir múltiples modalidades sensoriales en una arquitectura unificada de extremo a extremo, nos acerca a los sistemas de IA que pueden percibir e interactuar con el mundo más como lo hacen los humanos.
La integración de TMRoPE para la alineación temporal resuelve un desafío fundamental en el procesamiento multimodal, mientras que la arquitectura Thinker-Talker proporciona un marco para combinar eficazmente diversas entradas y generar salidas adecuadas. Su sólido rendimiento en los puntos de referencia demuestra que los modelos multimodales unificados pueden competir con los modelos especializados de una sola modalidad y, a veces, superarlos.
A medida que los recursos computacionales se vuelven más accesibles y las técnicas para la implementación eficiente de modelos mejoran, podemos esperar ver una adopción más generalizada de la IA verdaderamente multimodal como Qwen 2.5 Omni 7B. Las aplicaciones abarcan prácticamente todas las industrias, desde la atención médica y la educación hasta el entretenimiento y el servicio al cliente.
Conclusión
Qwen 2.5 Omni 7B se erige como un logro notable en la evolución de la IA multimodal. Sus capacidades integrales "Omni", su arquitectura innovadora y su impresionante rendimiento entre modalidades lo establecen como un ejemplo destacado de la próxima generación de sistemas de inteligencia artificial.
Al combinar la capacidad de ver, oír, leer y hablar en un solo modelo unificado, Qwen 2.5 Omni 7B rompe las barreras tradicionales entre las diferentes capacidades de la IA. Representa un paso significativo hacia la creación de sistemas de IA que puedan interactuar con los humanos y comprender el mundo de una manera más natural e intuitiva.
Si bien hay limitaciones prácticas a tener en cuenta, particularmente con respecto a los requisitos de hardware, los logros del modelo apuntan a un futuro emocionante donde la IA puede procesar y responder sin problemas al rico mundo multimodal que habitamos. A medida que estas tecnologías continúan evolucionando y volviéndose más accesibles, podemos esperar que transformen la forma en que interactuamos con la tecnología en innumerables aplicaciones y dominios.
Qwen 2.5 Omni 7B no es solo un logro tecnológico, es una visión de un futuro donde los límites entre las diferentes formas de comunicación comienzan a disolverse, creando formas más naturales e intuitivas para que los humanos y la IA interactúen.


