
Los desarrolladores buscan cada vez más herramientas robustas para incorporar capacidades de búsqueda web en tiempo real en sus aplicaciones impulsadas por IA. La API de Búsqueda de Perplexity se destaca como una solución potente, ofreciendo acceso a un extenso índice de contenido web con alta precisión y velocidad. Esta API permite una integración perfecta de funcionalidades de búsqueda que rivalizan con los principales motores de respuesta, permitiéndole construir sistemas sofisticados sin gestionar una infraestructura compleja.
Además, comprender la API de Búsqueda de Perplexity requiere un conocimiento de sus componentes principales, desde la autenticación hasta las consultas avanzadas. Los ingenieros valoran su diseño priorizando la IA, que prioriza la relevancia y la eficiencia. En consecuencia, esta guía proporciona un enfoque paso a paso, basándose en la documentación oficial y en conocimientos técnicos. Encontrará explicaciones detalladas, fragmentos de código y consejos prácticos para implementarla de manera efectiva. Sin embargo, antes de continuar, considere la evolución de la API, lanzada para democratizar el acceso al conocimiento a escala de internet, aborda las brechas en las API de búsqueda tradicionales al centrarse en la compatibilidad con la IA.
¿Qué es la API de Búsqueda de Perplexity?
La API de Búsqueda de Perplexity ofrece resultados de búsqueda web sin procesar, lo que permite a los desarrolladores realizar búsquedas híbridas que combinan la comprensión semántica con la coincidencia léxica. Accede a un índice que abarca cientos de miles de millones de páginas web, procesando actualizaciones a una velocidad de decenas de miles por segundo para garantizar la frescura. A diferencia de las herramientas de búsqueda convencionales, esta API enfatiza las cargas de trabajo de IA, proporcionando respuestas estructuradas con unidades de documento puntuadas individualmente para una clasificación precisa de fragmentos.
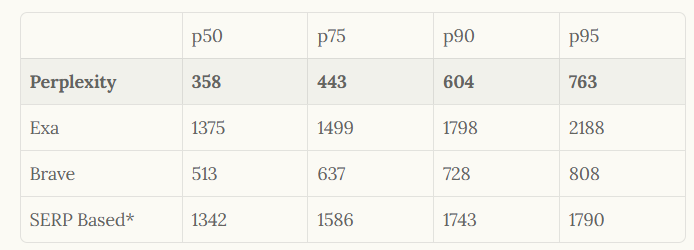
Los ingenieros de Perplexity diseñaron la API para estar a la vanguardia de la relevancia y la velocidad, superando a los competidores en métricas de latencia y calidad. Por ejemplo, logra una latencia media de 358 milisegundos, muy por debajo de alternativas como Exa con 1375 milisegundos. Además, la API incorpora bucles de retroalimentación humana y clasificación LLM para refinar los resultados, lo que la hace ideal para aplicaciones que requieren una recuperación de información confiable.
Además, la API de Búsqueda de Perplexity se distingue por sus compromisos de privacidad —ningún dato de usuario entrena los LLM subyacentes— y su asequibilidad, con precios líderes para las solicitudes de búsqueda. Los desarrolladores la emplean en diversos escenarios, desde simples bots de preguntas y respuestas hasta complejos agentes de investigación. Por lo tanto, sirve como una capa fundamental para construir agentes de IA que realizan investigaciones profundas en la web.
Características clave y beneficios de la API de Búsqueda de Perplexity
La API de Búsqueda de Perplexity cuenta con varias características destacadas que mejoran su utilidad para implementaciones técnicas. Primero, ofrece una comprensión granular del contenido, segmentando documentos en subunidades para una recuperación dirigida. Este enfoque reduce las necesidades de preprocesamiento y acelera la integración en los pipelines de IA. Además, la API admite filtrado avanzado, lo que le permite especificar parámetros para datos en tiempo real y excluir contenido irrelevante.
Otra característica crítica implica su sistema de recuperación híbrido, que fusiona señales léxicas y semánticas para generar conjuntos de candidatos completos. Los ingenieros aprecian esto porque garantiza la exhaustividad mientras mantiene una baja latencia. Además, la API proporciona salidas estructuradas, incluyendo fragmentos puntuados y citas, lo que fomenta la confianza en los resultados.
Los beneficios se extienden más allá de la destreza técnica. Los desarrolladores ahorran costos con su modelo de precios —$5 por cada 1,000 solicitudes para búsquedas sin procesar— lo que lo hace más económico que sus pares. Además, escala sin esfuerzo, manejando hasta 200 millones de consultas diarias sin comprometer el rendimiento. Como resultado, tanto startups como empresas lo adoptan para innovar rápidamente, prototipando productos en menos de una hora utilizando el SDK asociado.
Sin embargo, la verdadera ventaja reside en sus mejoras continuas. Perplexity integra señales de usuario de millones de interacciones para mejorar iterativamente la API, asegurando que evolucione con la dinámica del contenido web. En consecuencia, usted obtiene acceso a una herramienta que no solo satisface las necesidades actuales sino que anticipa las demandas futuras en la búsqueda de IA.
Comprendiendo la Arquitectura de la API de Búsqueda de Perplexity
Perplexity diseña la API de Búsqueda con un enfoque en la escalabilidad y la inteligencia. En su núcleo, el sistema emplea una configuración de almacenamiento de múltiples niveles, incluyendo más de 400 petabytes en almacenamiento en caliente, para gestionar miles de millones de documentos de manera eficiente. Los modelos de aprendizaje automático priorizan el rastreo y la indexación, prediciendo la importancia de la URL basándose en factores como la frecuencia de actualización.
Además, el módulo de comprensión de contenido utiliza lógica de análisis dinámico, impulsada por LLM de vanguardia, para adaptarse a diversos diseños de sitios web. Este módulo procesa millones de consultas por hora, mejorándose a sí mismo a través de bucles de evaluación para optimizar la exhaustividad y la calidad. Los ingenieros segmentan los documentos en subunidades, abordando las limitaciones de contexto en los modelos de IA y permitiendo una clasificación precisa.
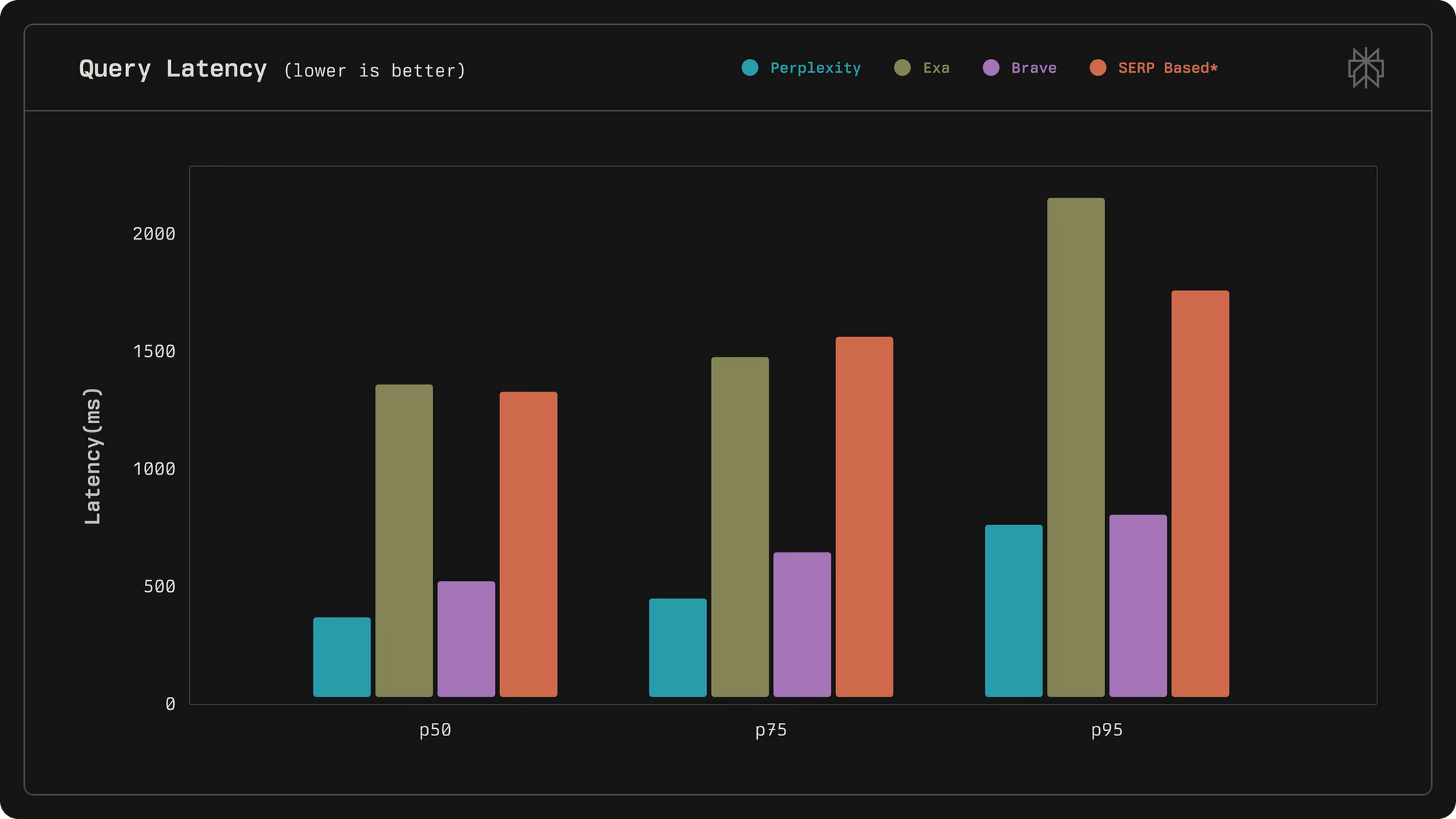
El pipeline de recuperación sigue un proceso de varias etapas: la recuperación híbrida inicial genera candidatos, el prefiltrado elimina el ruido y la clasificación progresiva aplica modelos léxicos, basados en incrustaciones y de codificador cruzado. Este diseño aprovecha las señales en vivo para el entrenamiento, codesarrollado con los productos de Perplexity para aumentar la precisión.
Los desafíos en esta arquitectura incluyen equilibrar la frescura con la exhaustividad bajo restricciones presupuestarias. Perplexity los resuelve mediante la priorización impulsada por ML y la escalabilidad horizontal. Como mejor práctica, el equipo recomienda señales híbridas y evaluaciones rigurosas utilizando su marco de código abierto, search_evals.
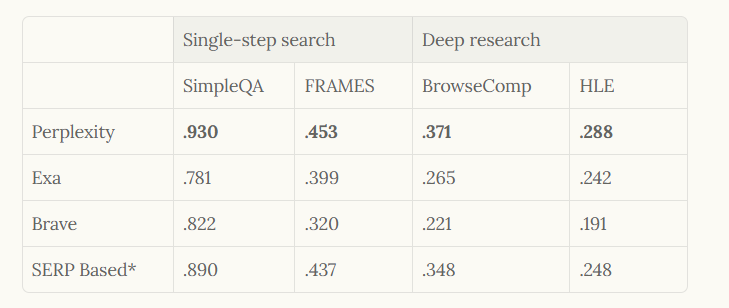
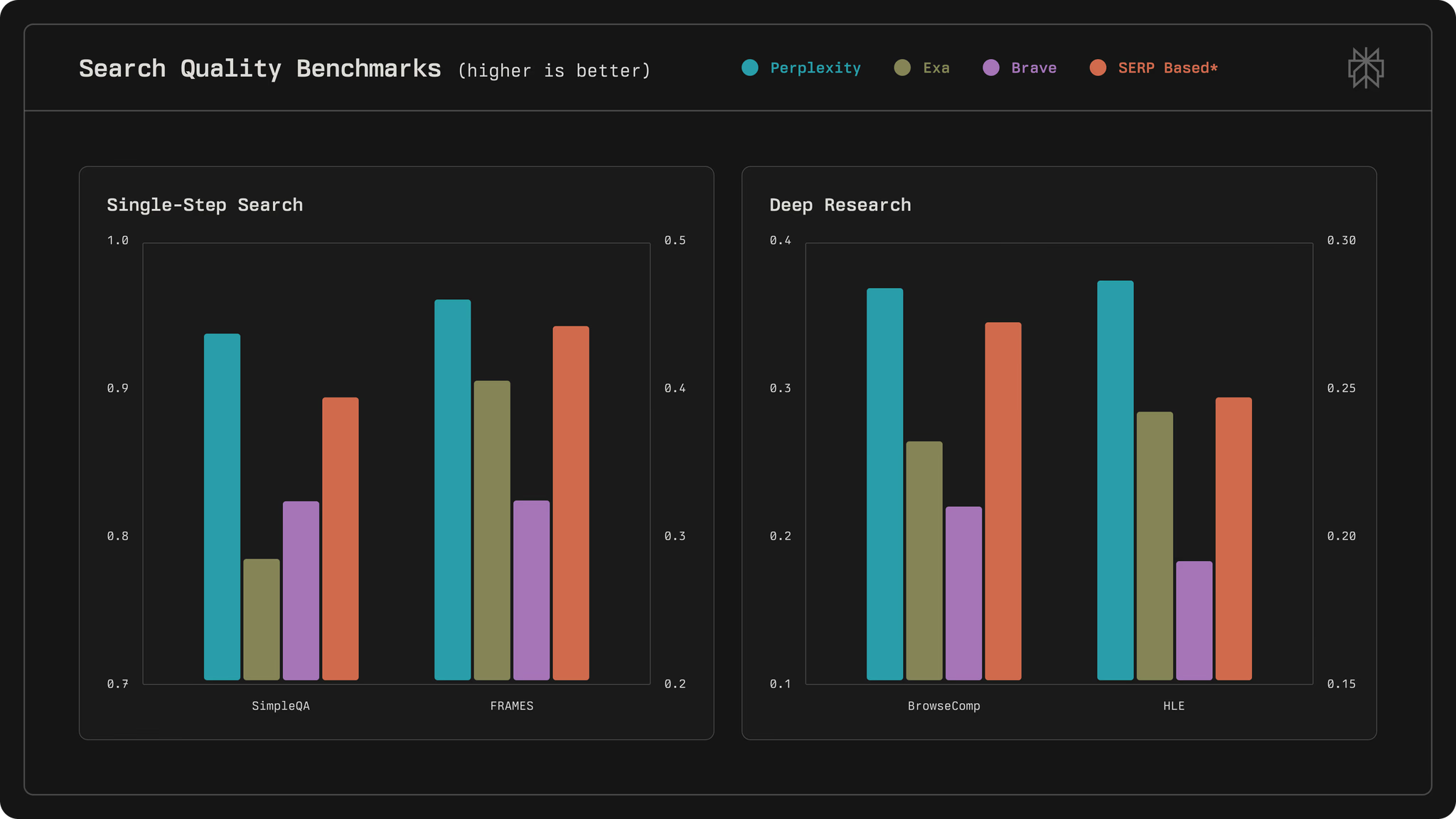
En la evaluación, Perplexity emplea puntos de referencia como SimpleQA para búsquedas de un solo paso y BrowseComp para investigación profunda, logrando puntuaciones máximas como 0.930 en SimpleQA. Por lo tanto, esta arquitectura no solo admite el uso de alto volumen, sino que también establece un estándar para los sistemas de búsqueda basados en IA.
Precios y planes de suscripción para la API de Búsqueda de Perplexity
Perplexity estructura los precios de la API de Búsqueda para priorizar la asequibilidad y la transparencia. El costo base para los resultados de búsqueda web sin procesar es de $5 por cada 1,000 solicitudes, sin tarifas adicionales basadas en tokens para este endpoint. Este modelo es adecuado para desarrolladores que requieren una integración de búsqueda sencilla sin una facturación compleja.
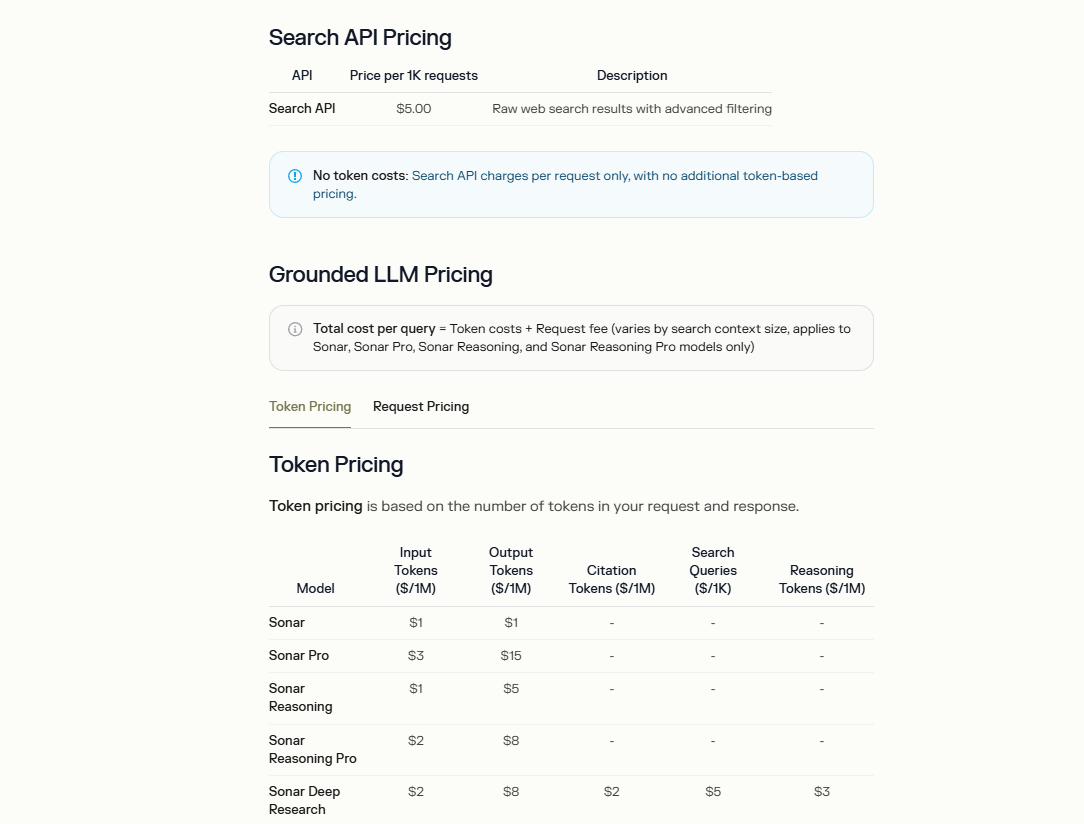
Para integraciones de LLM fundamentadas, los precios incorporan costos de tokens más una tarifa por solicitud, que varían según el modelo. Por ejemplo, el modelo Sonar cobra $1 por millón de tokens de entrada y $1 por millón de tokens de salida. Las variantes avanzadas como Sonar Pro aumentan a $3 por millón de entrada y $15 por millón de salida. Además, Sonar Deep Research incluye cargos por tokens de citación ($2 por millón), consultas de búsqueda ($5 por cada 1,000) y tokens de razonamiento ($3 por millón).
Los límites de uso están directamente relacionados con estas métricas, donde un token equivale aproximadamente a cuatro caracteres en texto en inglés. Los desarrolladores monitorean el consumo a través de la sección de administración del portal de la API, que maneja la facturación y los pagos. Sin embargo, la documentación no describe niveles gratuitos para la API de Búsqueda, enfatizando el acceso de pago para uso en producción.
En consecuencia, este precio permite una adopción escalable. Los equipos pequeños comienzan con búsquedas básicas, mientras que las empresas aprovechan modelos avanzados para aplicaciones completas. Revise siempre los últimos detalles en el portal oficial para alinearse con el presupuesto de su proyecto.
Primeros pasos: Registro y obtención de una clave API
Para comenzar a usar la API de Búsqueda de Perplexity, navegue a la Plataforma API. Cree una cuenta si no tiene una, luego acceda a la pestaña Claves API para generar una nueva clave. Esta clave autentica todas las solicitudes, así que guárdela de forma segura.
A continuación, establezca la clave como una variable de entorno. En Windows, use el comando setx PERPLEXITY_API_KEY "your_api_key_here". Para otros sistemas, expórtela en su shell. Esta configuración permite a los clientes del SDK detectar automáticamente la clave, simplificando la autenticación.
Además, considere usar herramientas como python-dotenv para gestionar secretos en entornos de desarrollo. Cargue el archivo .env en su código para evitar codificar información sensible. Una vez configurado, puede instanciar clientes en Python o Node.js sin problemas.
Sin embargo, verifique su configuración realizando una solicitud de prueba. Si surgen problemas, consulte los foros de la comunidad o la documentación para solucionar problemas. Este paso inicial asegura un progreso fluido hacia la implementación.
Instalación del SDK de Perplexity para Python y Node.js
El SDK de Perplexity facilita la interacción con la API de Búsqueda en Python 3.8+ y Node.js. Para Python, instálelo a través de pip: pip install perplexityai. Este comando descarga el paquete, incluyendo las definiciones de tipo para los parámetros y las respuestas.
En Node.js, aunque los detalles específicos de la instalación varían, normalmente se utiliza npm o yarn para añadir el paquete. El SDK admite operaciones síncronas y asíncronas, lo que mejora la flexibilidad para diferentes arquitecturas de aplicación.
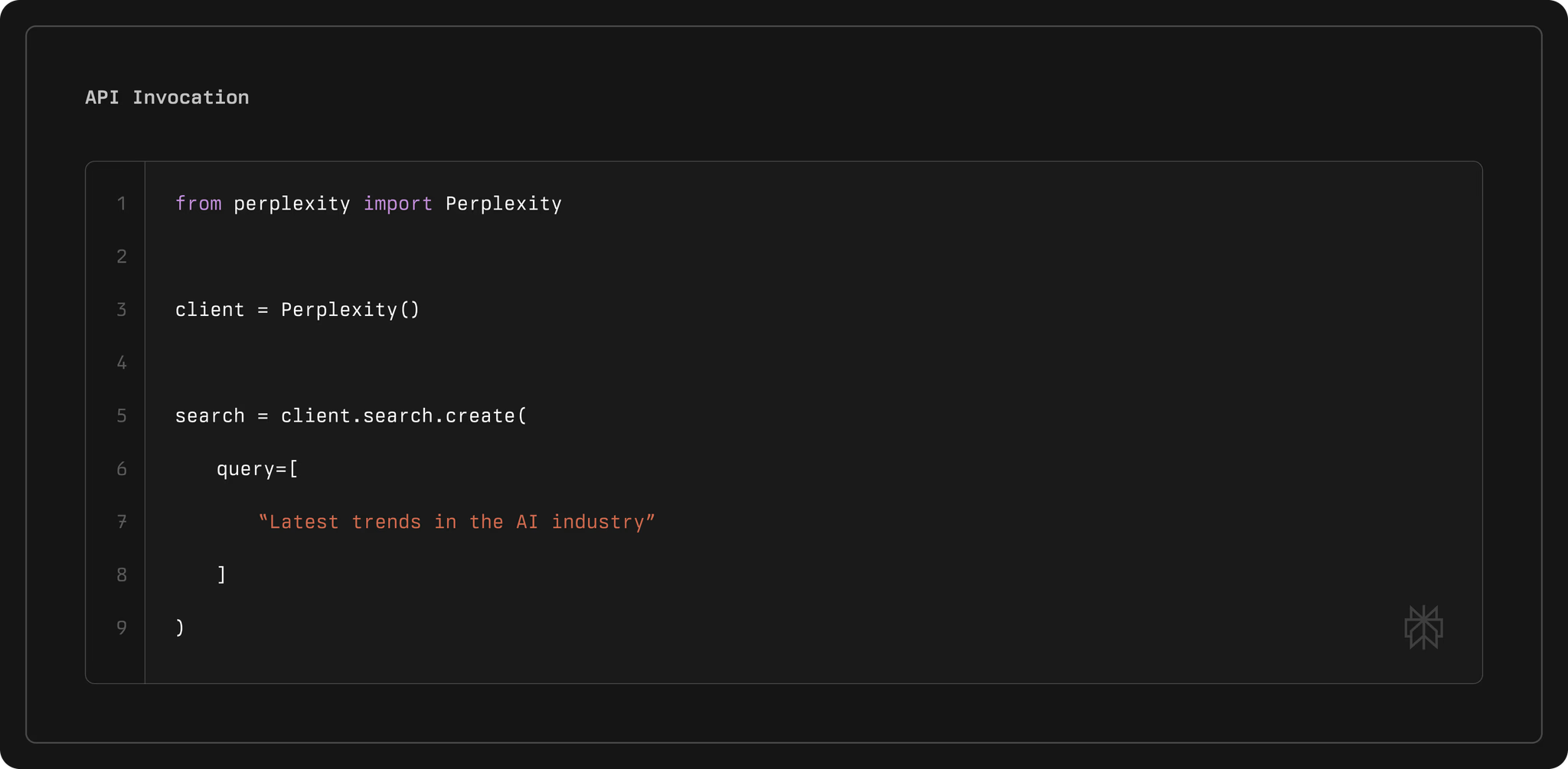
Después de la instalación, importe la biblioteca. En Python, use from perplexity import Perplexity y cree un cliente: client = Perplexity(). Este cliente obtiene la clave API de las variables de entorno automáticamente.
Además, el SDK proporciona soporte integral para todos los endpoints de la API, asegurando que maneje las solicitudes de manera eficiente. Pruebe la instalación importando sin errores, confirmando la preparación para la codificación.
Realizando su primera solicitud de búsqueda con la API de Búsqueda de Perplexity
Con el SDK instalado, inicie su primera solicitud. En Python, use el método de búsqueda del cliente con un parámetro de consulta. Por ejemplo:
import os
from perplexity import Perplexity
client = Perplexity()
response = client.search("example query")
print(response)
Este código envía una búsqueda básica e imprime la respuesta estructurada, incluyendo resultados y puntuaciones.
Además, personalice la solicitud añadiendo filtros, como rangos de fechas o dominios, para refinar los resultados. La API devuelve JSON con unidades de documento, fragmentos y puntuaciones de relevancia, listos para ser analizados en su aplicación.
Sin embargo, maneje los errores con elegancia. Implemente bloques try-except para capturar problemas de autenticación o límites de velocidad. A medida que experimente, registre las respuestas para comprender profundamente el formato de salida.
En consecuencia, esta sencilla solicitud demuestra la facilidad de uso de la API, allanando el camino para integraciones más complejas.
Uso avanzado: Parámetros, filtrado y personalización
La API de Búsqueda de Perplexity admite parámetros extensos para búsquedas personalizadas. Especifique query como entrada principal, luego agregue filter para tipos de medios o since/until para restricciones basadas en el tiempo. Por ejemplo, incluya geocode para resultados específicos de la ubicación, aunque úselo con moderación debido a las limitaciones de geolocalización.
Además, aproveche operadores avanzados como frases exactas o exclusiones para mejorar la precisión. El sistema híbrido aplica automáticamente la clasificación semántica, pero puede influir en ella mediante la selección del modelo en llamadas fundamentadas.
En el código, extienda la solicitud básica:
response = client.search(
query="AI search APIs",
filter="news",
since="2025-01-01"
)
Esto recupera artículos de noticias recientes, puntuados por relevancia.
Además, para una investigación profunda, integre con los modelos Sonar Deep Research, lo que implica costos de tokens adicionales pero permite un razonamiento paso a paso. Ajuste reasoning_effort para controlar la profundidad de la consulta.
Por lo tanto, dominar estos parámetros le permite optimizar para casos de uso específicos, desde búsquedas rápidas hasta análisis exhaustivos.
Integrando la API de Búsqueda de Perplexity en sus aplicaciones
Los desarrolladores integran la API de Búsqueda de Perplexity en aplicaciones web, chatbots y agentes de IA sin esfuerzo. Para un backend de Node.js, use el SDK para manejar solicitudes asíncronas, alimentando los resultados a los componentes del frontend.
Por ejemplo, en una herramienta de investigación, consulte la API con la entrada del usuario, analice las respuestas y muestre fragmentos citados. Asegúrese de cumplir con los límites de velocidad implementando almacenamiento en caché o colas.
Además, combínelo con otros servicios. Empareje con bibliotecas de procesamiento de lenguaje natural para preprocesar consultas, mejorando la precisión.
Sin embargo, considere la escalabilidad. Monitoree el uso para evitar exceder los presupuestos y use webhooks si están disponibles para actualizaciones.
Como resultado, esta integración transforma las aplicaciones estáticas en sistemas dinámicos y basados en el conocimiento.
Pruebas y depuración con Apidog
Apidog sirve como una plataforma todo en uno para el desarrollo de API, lo que le permite diseñar, depurar, simular y probar endpoints como la API de Búsqueda de Perplexity. Agiliza los flujos de trabajo simulando escenarios del mundo real y detectando errores temprano.
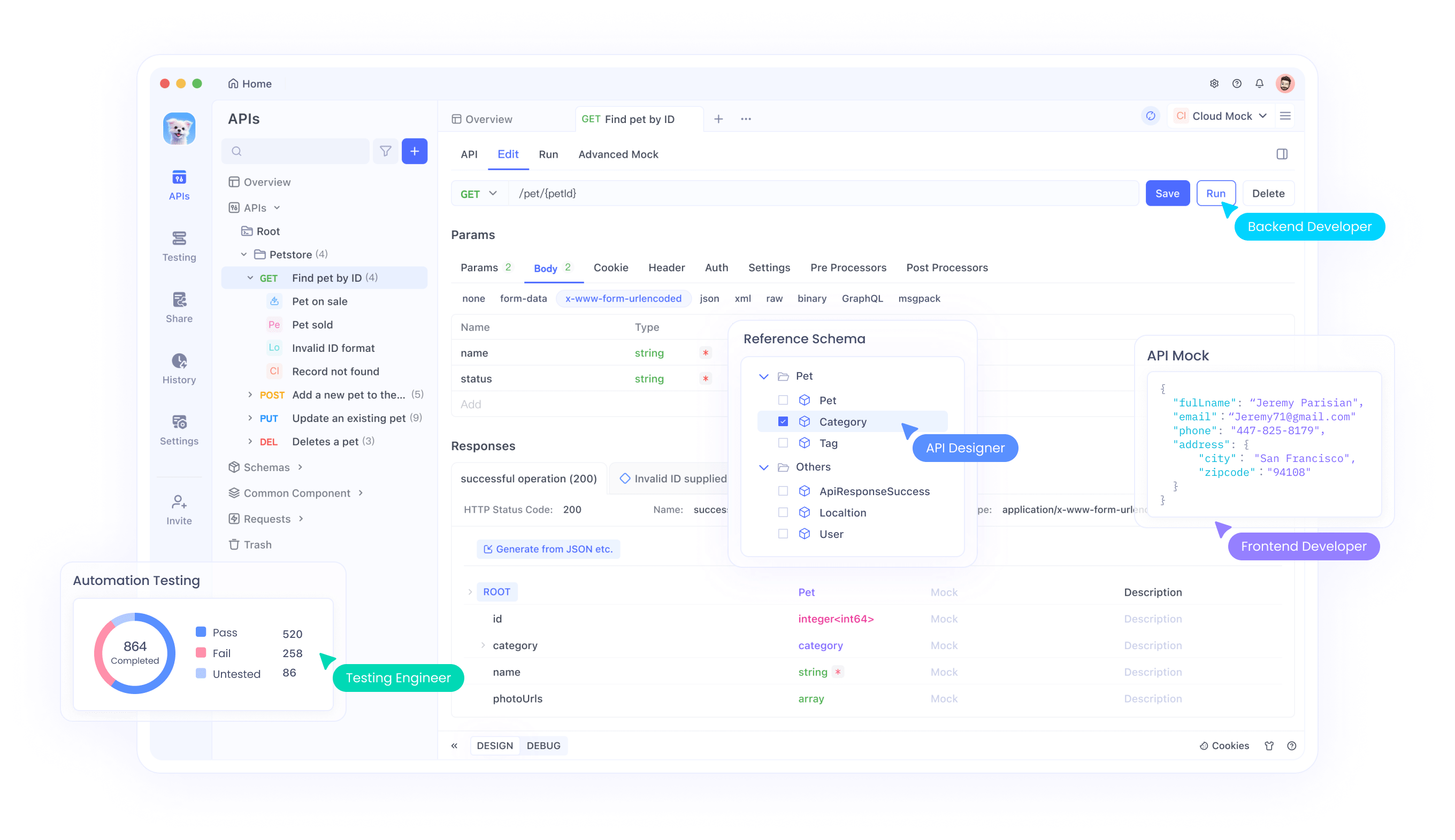
Para usar Apidog con la API de Búsqueda de Perplexity, importe la especificación de la API a la interfaz de Apidog. Cree casos de prueba para varias consultas, validando las respuestas con las estructuras esperadas. Las funciones de IA de Apidog automatizan la documentación y las pruebas, reduciendo el esfuerzo manual.
Además, simule la API para el desarrollo sin conexión, asegurándose de que su aplicación maneje casos extremos. Genere referencias e informes para mantener la calidad.
En consecuencia, Apidog acelera la depuración, haciéndolo indispensable para integraciones robustas.
Mejores prácticas para evaluar y optimizar el rendimiento
Evalúe la API de Búsqueda de Perplexity utilizando el marco de código abierto search_evals, comparándolo con suites como FRAMES y HLE. Esta herramienta evalúa la latencia y la calidad de forma neutral.
Implemente la recuperación híbrida en sus pipelines para obtener resultados equilibrados. Actualice regularmente la lógica de análisis para adaptarse a los cambios web.
Además, incorpore la retroalimentación del usuario para afinar las consultas, reflejando el enfoque de Perplexity.
Sin embargo, evite la dependencia excesiva de los valores predeterminados; personalice los parámetros para su dominio.
Por lo tanto, estas prácticas garantizan un rendimiento y una fiabilidad óptimos.
Desafíos comunes y consejos para la resolución de problemas
Los usuarios encuentran errores de autenticación; verifique dos veces las variables de entorno. Para problemas de latencia, optimice la complejidad de la consulta.
Además, maneje los límites de velocidad con retroceso exponencial en el código.
Si los resultados carecen de relevancia, refine los filtros o use modelos avanzados.
Como resultado, la resolución proactiva de problemas mantiene las operaciones sin problemas.
Desarrollos futuros y recursos de la comunidad
Perplexity continúa mejorando la API con actualizaciones impulsadas por la investigación. Únase a la comunidad de desarrolladores para obtener información y eventos.
Además, explore las contribuciones de código abierto para mantenerse a la vanguardia.
Conclusión
La API de Búsqueda de Perplexity permite a los desarrolladores aprovechar la búsqueda avanzada en aplicaciones de IA. Siguiendo esta guía, la implementará de manera efectiva, utilizando herramientas como Apidog para la eficiencia. Continúe experimentando para desbloquear todo su potencial.