
Introducción al Framework de la API OpenAI Evals
La API OpenAI Evals, introducida el 9 de abril de 2025, representa un avance significativo en la evaluación sistemática de los Modelos de Lenguaje Grandes (LLMs). Si bien las capacidades de evaluación han estado disponibles a través del panel de control de OpenAI durante algún tiempo, la API Evals ahora permite a los desarrolladores definir pruebas de forma programática, automatizar las ejecuciones de evaluación e iterar rápidamente en los prompts y las implementaciones de modelos dentro de sus propios flujos de trabajo. Esta potente interfaz admite la evaluación metódica de las salidas del modelo, lo que facilita la toma de decisiones basada en la evidencia al seleccionar modelos o refinar las estrategias de ingeniería de prompts.
Este tutorial proporciona una guía técnica completa para implementar y aprovechar la API OpenAI Evals. Exploraremos la arquitectura subyacente, los patrones de implementación y las técnicas avanzadas para crear pipelines de evaluación robustos que puedan medir objetivamente el rendimiento de sus aplicaciones LLM.
API OpenAI Evals: ¿Cómo Funciona?
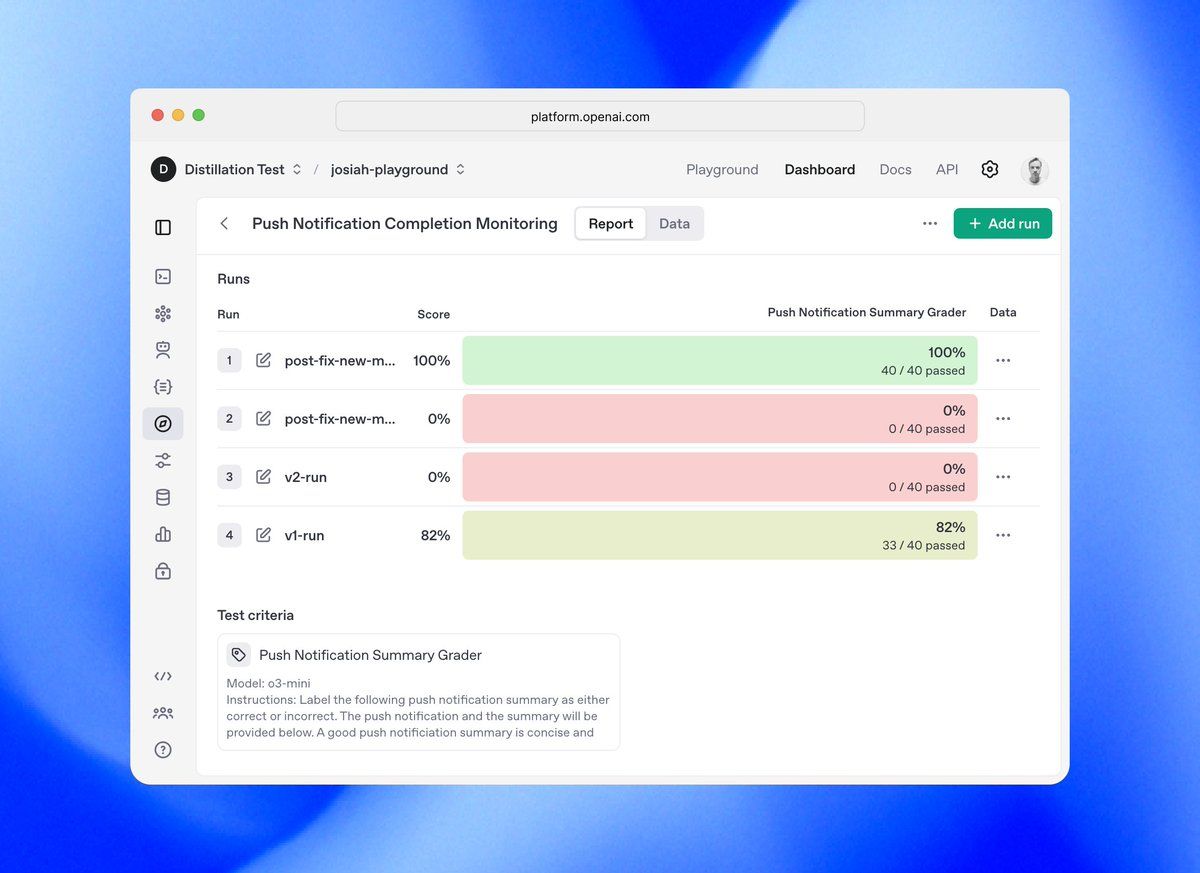
La API OpenAI Evals sigue una estructura jerárquica construida en torno a dos abstracciones principales:
- Configuración de Eval: el contenedor para las especificaciones de evaluación que incluye:
- Definición del esquema de la fuente de datos
- Configuración de los criterios de prueba
- Metadatos para la organización y la recuperación
2. Ejecuciones de Eval: ejecuciones de evaluación individuales que incluyen:
- Referencia a una configuración de eval principal
- Muestras de datos específicas para la evaluación
- Respuestas del modelo y resultados de la evaluación
Esta separación de responsabilidades permite la reutilización en múltiples escenarios de prueba, manteniendo la coherencia en los estándares de evaluación.
El Modelo de Objetos de la API Evals
Los objetos centrales dentro de la API Evals siguen esta relación:
- data_source_config (definición del esquema)
- testing_criteria (métodos de evaluación)
- metadata (descripción, etiquetas, etc.)
- Run 1 (contra datos específicos)
- Run 2 (implementación alternativa)
- ...
- Run N (comparación de versiones)
Configurando su Entorno para la API OpenAI Evals
Al implementar la API OpenAI Evals, su elección de herramientas de prueba y desarrollo puede afectar significativamente su productividad y la calidad de los resultados.

Apidog destaca como la principal plataforma de API que supera a las soluciones tradicionales como Postman en varios aspectos clave, lo que la convierte en el compañero ideal para trabajar con la API Evals, técnicamente compleja.
Antes de implementar las evaluaciones, deberá configurar correctamente su entorno de desarrollo:
import openai
import os
import pydantic
import json
from typing import Dict, List, Any, Optional
# Configure API access with appropriate permissions
os.environ["OPENAI_API_KEY"] = os.environ.get("OPENAI_API_KEY", "your-api-key")
# For production environments, consider using a more secure method
# such as environment variables loaded from a .env file
La biblioteca cliente de Python de OpenAI proporciona la interfaz para interactuar con la API Evals. Asegúrese de estar utilizando la última versión que incluye soporte para la API Evals:
pip install --upgrade openai>=1.20.0 # Version that includes Evals API support
Creando su Primera Evaluación con la API OpenAI Evals
Implementemos un flujo de trabajo de evaluación completo utilizando la API OpenAI Evals. Crearemos un sistema de evaluación para una tarea de resumen de texto, demostrando el proceso completo desde el diseño de la evaluación hasta el análisis de los resultados.
Definiendo Modelos de Datos para la API OpenAI Evals
Primero, necesitamos definir la estructura de nuestros datos de prueba utilizando modelos Pydantic:
class ArticleSummaryData(pydantic.BaseModel):
"""Data structure for article summarization evaluation."""
article: str
reference_summary: Optional[str] = None # Optional reference for comparison
class Config:
frozen = True # Ensures immutability for consistent evaluation
Este modelo define el esquema para nuestros datos de evaluación, que será utilizado por la API Evals para validar las entradas y proporcionar variables de plantilla para nuestros criterios de prueba.
Implementando la Función Objetivo para las Pruebas de la API Evals
A continuación, implementaremos la función que genera las salidas que queremos evaluar:
def generate_article_summary(article_text: str) -> Dict[str, Any]:
"""
Generate a concise summary of an article using OpenAI's models.
Args:
article_text: The article content to summarize
Returns:
Completion response object with summary
"""
summarization_prompt = """
Summarize the following article in a concise, informative manner.
Capture the key points while maintaining accuracy and context.
Keep the summary to 1-2 paragraphs.
Article:
{{article}}
"""
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": summarization_prompt.replace("{{article}}", article_text)},
],
temperature=0.3, # Lower temperature for more consistent summaries
max_tokens=300
)
return response.model_dump() # Convert to serializable dictionary
Configurando la Fuente de Datos para la API OpenAI Evals
La API Evals requiere una configuración de fuente de datos definida que especifique el esquema de sus datos de evaluación:
data_source_config = {
"type": "custom",
"item_schema": ArticleSummaryData.model_json_schema(),
"include_sample_schema": True, # Includes model output schema automatically
}
print("Data Source Schema:")
print(json.dumps(data_source_config, indent=2))
Esta configuración le dice a la API Evals qué campos esperar en sus datos de evaluación y cómo procesarlos.
Implementando Criterios de Prueba con la API OpenAI Evals
Ahora definiremos cómo la API Evals debe evaluar las salidas del modelo. Crearemos una evaluación integral con múltiples criterios:
# 1. Accuracy evaluation using model-based judgment
accuracy_grader = {
"name": "Summary Accuracy Evaluation",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
You are an expert evaluator assessing the accuracy of article summaries.
Evaluate if the summary accurately represents the main points of the original article.
Label the summary as one of:
- "accurate": Contains all key information, no factual errors
- "partially_accurate": Contains most key information, minor errors or omissions
- "inaccurate": Significant errors, missing critical information, or misrepresentation
Provide a detailed explanation for your assessment.
"""
},
{
"role": "user",
"content": """
Original Article:
{{item.article}}
Summary to Evaluate:
{{sample.choices[0].message.content}}
Assessment:
"""
}
],
"passing_labels": ["accurate", "partially_accurate"],
"labels": ["accurate", "partially_accurate", "inaccurate"],
}
# 2. Conciseness evaluation
conciseness_grader = {
"name": "Summary Conciseness Evaluation",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
You are an expert evaluator assessing the conciseness of article summaries.
Evaluate if the summary expresses information efficiently without unnecessary details.
Label the summary as one of:
- "concise": Perfect length, no unnecessary information
- "acceptable": Slightly verbose but generally appropriate
- "verbose": Excessively long or containing unnecessary details
Provide a detailed explanation for your assessment.
"""
},
{
"role": "user",
"content": """
Summary to Evaluate:
{{sample.choices[0].message.content}}
Assessment:
"""
}
],
"passing_labels": ["concise", "acceptable"],
"labels": ["concise", "acceptable", "verbose"],
}
# 3. If reference summaries are available, add a reference comparison
reference_comparison_grader = {
"name": "Reference Comparison Evaluation",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
Compare the generated summary with the reference summary.
Evaluate how well the generated summary captures the same key information as the reference.
Label the comparison as one of:
- "excellent": Equivalent or better than reference
- "good": Captures most important information from reference
- "inadequate": Missing significant information present in reference
Provide a detailed explanation for your assessment.
"""
},
{
"role": "user",
"content": """
Reference Summary:
{{item.reference_summary}}
Generated Summary:
{{sample.choices[0].message.content}}
Assessment:
"""
}
],
"passing_labels": ["excellent", "good"],
"labels": ["excellent", "good", "inadequate"],
"condition": "item.reference_summary != null" # Only apply when reference exists
}
Creando la Configuración de Evaluación con la API OpenAI Evals
Con nuestro esquema de datos y criterios de prueba definidos, ahora podemos crear la configuración de evaluación:
eval_create_result = openai.evals.create(
name="Article Summarization Quality Evaluation",
metadata={
"description": "Comprehensive evaluation of article summarization quality across multiple dimensions",
"version": "1.0",
"created_by": "Your Organization",
"tags": ["summarization", "content-quality", "accuracy"]
},
data_source_config=data_source_config,
testing_criteria=[
accuracy_grader,
conciseness_grader,
reference_comparison_grader
],
)
eval_id = eval_create_result.id
print(f"Created evaluation with ID: {eval_id}")
print(f"View in dashboard: {eval_create_result.dashboard_url}")
Ejecutando Ejecuciones de Evaluación con la API OpenAI Evals
Preparando Datos de Evaluación
Ahora prepararemos los datos de prueba para nuestra evaluación:
test_articles = [
{
"article": """
The European Space Agency (ESA) announced today the successful deployment of its new Earth observation satellite, Sentinel-6.
This satellite will monitor sea levels with unprecedented accuracy, providing crucial data on climate change impacts.
The Sentinel-6 features advanced radar altimetry technology capable of measuring sea-level changes down to millimeter precision.
Scientists expect this data to significantly improve climate models and coastal planning strategies.
The satellite, launched from Vandenberg Air Force Base in California, is part of the Copernicus program, a collaboration
between ESA, NASA, NOAA, and other international partners.
""",
"reference_summary": """
The ESA has successfully deployed the Sentinel-6 Earth observation satellite, designed to monitor sea levels
with millimeter precision using advanced radar altimetry. This mission, part of the international Copernicus program,
will provide crucial data for climate change research and coastal planning.
"""
},
# Additional test articles would be added here
]
# Process our test data for evaluation
run_data = []
for item in test_articles:
# Generate summary using our function
article_data = ArticleSummaryData(**item)
result = generate_article_summary(article_data.article)
# Prepare the run data entry
run_data.append({
"item": article_data.model_dump(),
"sample": result
})
Creando y Ejecutando una Ejecución de Evaluación
Con nuestros datos preparados, podemos crear una ejecución de evaluación:
eval_run_result = openai.evals.runs.create(
eval_id=eval_id,
name="baseline-summarization-run",
metadata={
"model": "gpt-4o",
"temperature": 0.3,
"max_tokens": 300
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": run_data,
}
},
)
print(f"Evaluation run created: {eval_run_result.id}")
print(f"View detailed results: {eval_run_result.report_url}")
Recuperando y Analizando los Resultados de la Evaluación desde la API Evals
Una vez que se completa una ejecución de evaluación, puede recuperar los resultados detallados:
def analyze_run_results(run_id: str) -> Dict[str, Any]:
"""
Retrieve and analyze results from an evaluation run.
Args:
run_id: The ID of the evaluation run
Returns:
Dictionary containing analyzed results
"""
# Retrieve the run details
run_details = openai.evals.runs.retrieve(run_id)
# Extract the results
results = {}
# Calculate overall pass rate
if run_details.results and "pass_rate" in run_details.results:
results["overall_pass_rate"] = run_details.results["pass_rate"]
# Extract criterion-specific metrics
if run_details.criteria_results:
results["criteria_performance"] = {}
for criterion, data in run_details.criteria_results.items():
results["criteria_performance"][criterion] = {
"pass_rate": data.get("pass_rate", 0),
"sample_count": data.get("total_count", 0)
}
# Extract failures for further analysis
if run_details.raw_results:
results["failure_analysis"] = [
{
"item": item.get("item", {}),
"result": item.get("result", {}),
"criteria_results": item.get("criteria_results", {})
}
for item in run_details.raw_results
if not item.get("passed", True)
]
return results
# Analyze our run
results_analysis = analyze_run_results(eval_run_result.id)
print(json.dumps(results_analysis, indent=2))
Técnicas Avanzadas de la API OpenAI Evals
Implementando Pruebas A/B con la API Evals
La API Evals destaca en la comparación de diferentes implementaciones. Aquí se explica cómo configurar una prueba A/B entre dos configuraciones de modelo:
def generate_summary_alternative_model(article_text: str) -> Dict[str, Any]:
"""Alternative implementation using a different model configuration."""
response = openai.chat.completions.create(
model="gpt-4o-mini", # Using a different model
messages=[
{"role": "system", "content": "Summarize this article concisely."},
{"role": "user", "content": article_text},
],
temperature=0.7, # Higher temperature for comparison
max_tokens=250
)
return response.model_dump()
# Process our test data with the alternative model
alternative_run_data = []
for item in test_articles:
article_data = ArticleSummaryData(**item)
result = generate_summary_alternative_model(article_data.article)
alternative_run_data.append({
"item": article_data.model_dump(),
"sample": result
})
# Create the alternative evaluation run
alternative_eval_run = openai.evals.runs.create(
eval_id=eval_id,
name="alternative-model-run",
metadata={
"model": "gpt-4o-mini",
"temperature": 0.7,
"max_tokens": 250
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": alternative_run_data,
}
},
)
# Compare the results programmatically
def compare_evaluation_runs(run_id_1: str, run_id_2: str) -> Dict[str, Any]:
"""
Compare results from two evaluation runs.
Args:
run_id_1: ID of first evaluation run
run_id_2: ID of second evaluation run
Returns:
Dictionary containing comparative analysis
"""
run_1_results = analyze_run_results(run_id_1)
run_2_results = analyze_run_results(run_id_2)
comparison = {
"overall_comparison": {
"run_1_pass_rate": run_1_results.get("overall_pass_rate", 0),
"run_2_pass_rate": run_2_results.get("overall_pass_rate", 0),
"difference": run_1_results.get("overall_pass_rate", 0) - run_2_results.get("overall_pass_rate", 0)
},
"criteria_comparison": {}
}
# Compare each criterion
all_criteria = set(run_1_results.get("criteria_performance", {}).keys()) | set(run_2_results.get("criteria_performance", {}).keys())
for criterion in all_criteria:
run_1_criterion = run_1_results.get("criteria_performance", {}).get(criterion, {})
run_2_criterion = run_2_results.get("criteria_performance", {}).get(criterion, {})
comparison["criteria_comparison"][criterion] = {
"run_1_pass_rate": run_1_criterion.get("pass_rate", 0),
"run_2_pass_rate": run_2_criterion.get("pass_rate", 0),
"difference": run_1_criterion.get("pass_rate", 0) - run_2_criterion.get("pass_rate", 0)
}
return comparison
# Compare our two runs
comparison_results = compare_evaluation_runs(eval_run_result.id, alternative_eval_run.id)
print(json.dumps(comparison_results, indent=2))
Detectando Regresiones con la API OpenAI Evals
Una de las aplicaciones más valiosas de la API Evals es la detección de regresiones al actualizar los prompts:
def create_regression_detection_pipeline(eval_id: str, baseline_run_id: str) -> None:
"""
Create a regression detection pipeline that compares a new prompt
against a baseline run.
Args:
eval_id: The ID of the evaluation configuration
baseline_run_id: The ID of the baseline run to compare against
"""
def test_prompt_for_regression(new_prompt: str, threshold: float = 0.95) -> Dict[str, Any]:
"""
Test if a new prompt causes regression compared to baseline.
Args:
new_prompt: The new prompt to test
threshold: Minimum acceptable performance ratio (new/baseline)
Returns:
Dictionary containing regression analysis
"""
# Define function using new prompt
def generate_summary_new_prompt(article_text: str) -> Dict[str, Any]:
response = openai.chat.completions.create(
model="gpt-4o", # Same model as baseline
messages=[
{"role": "system", "content": new_prompt},
{"role": "user", "content": article_text},
],
temperature=0.3,
max_tokens=300
)
return response.model_dump()
# Process test data with new prompt
new_prompt_run_data = []
for item in test_articles:
article_data = ArticleSummaryData(**item)
result = generate_summary_new_prompt(article_data.article)
new_prompt_run_data.append({
"item": article_data.model_dump(),
"sample": result
})
# Create evaluation run for new prompt
new_prompt_run = openai.evals.runs.create(
eval_id=eval_id,
name=f"regression-test-{int(time.time())}",
metadata={
"prompt": new_prompt,
"test_type": "regression"
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": new_prompt_run_data,
}
},
)
# Wait for completion (in production, you might want to implement async handling)
# This is a simplified implementation
time.sleep(10) # Wait for evaluation to complete
# Compare against baseline
comparison = compare_evaluation_runs(baseline_run_id, new_prompt_run.id)
# Determine if there's a regression
baseline_pass_rate = comparison["overall_comparison"]["run_1_pass_rate"]
new_pass_rate = comparison["overall_comparison"]["run_2_pass_rate"]
regression_detected = (new_pass_rate / baseline_pass_rate if baseline_pass_rate > 0 else 0) < threshold
return {
"regression_detected": regression_detected,
"baseline_pass_rate": baseline_pass_rate,
"new_pass_rate": new_pass_rate,
"performance_ratio": new_pass_rate / baseline_pass_rate if baseline_pass_rate > 0 else 0,
"threshold": threshold,
"detailed_comparison": comparison,
"report_url": new_prompt_run.report_url
}
return test_prompt_for_regression
# Create a regression detection pipeline
regression_detector = create_regression_detection_pipeline(eval_id, eval_run_result.id)
# Test a potentially problematic prompt
problematic_prompt = """
Summarize this article in excessive detail, making sure to include every minor point.
The summary should be comprehensive and leave nothing out.
"""
regression_analysis = regression_detector(problematic_prompt)
print(json.dumps(regression_analysis, indent=2))
Trabajando con Métricas Personalizadas en la API OpenAI Evals
Para necesidades de evaluación especializadas, puede implementar métricas personalizadas:
# Example of a custom numeric score evaluation
numeric_score_grader = {
"name": "Summary Quality Score",
"type": "score_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
You are an expert evaluator assessing the quality of article summaries.
Rate the overall quality of the summary on a scale from 1.0 to 10.0, where:
- 1.0-3.9: Poor quality, significant issues
- 4.0-6.9: Acceptable quality with room for improvement
- 7.0-8.9: Good quality, meets expectations
- 9.0-10.0: Excellent quality, exceeds expectations
Provide a specific numeric score and detailed justification.
"""
},
{
"role": "user",
"content": """
Original Article:
{{item.article}}
Summary to Evaluate:
{{sample.choices[0].message.content}}
Score (1.0-10.0):
"""
}
],
"passing_threshold": 7.0, # Minimum score to pass
"min_score": 1.0,
"max_score": 10.0
}
# Add this to your testing criteria when creating an eval
Integrando la API OpenAI Evals en los Flujos de Trabajo de Desarrollo
Integración de CI/CD con la API Evals
La integración de la API Evals en su pipeline de CI/CD garantiza una calidad constante:
def ci_cd_evaluation_workflow(
prompt_file_path: str,
baseline_eval_id: str,
baseline_run_id: str,
threshold: float = 0.95
) -> bool:
"""
CI/CD integration for evaluating model prompts before deployment.
Args:
prompt_file_path: Path to the prompt file being updated
baseline_eval_id: ID of the baseline evaluation configuration
baseline_run_id: ID of the baseline run to compare against
threshold: Minimum acceptable performance ratio
Returns:
Boolean indicating whether the new prompt passed evaluation
"""
# Load the new prompt from version control
with open(prompt_file_path, 'r') as f:
new_prompt = f.read()
# Create regression detector using the baseline
regression_detector = create_regression_detection_pipeline(baseline_eval_id, baseline_run_id)
# Test the new prompt
regression_analysis = regression_detector(new_prompt)
# Determine if the prompt is safe to deploy
is_approved = not regression_analysis["regression_detected"]
# Log the evaluation results
print(f"Evaluation Results for {prompt_file_path}")
print(f"Baseline Pass Rate: {regression_analysis['baseline_pass_rate']:.2f}")
print(f"New Prompt Pass Rate: {regression_analysis['new_pass_rate']:.2f}")
print(f"Performance Ratio: {regression_analysis['performance_ratio']:.2f}")
print(f"Deployment Decision: {'APPROVED' if is_approved else 'REJECTED'}")
print(f"Detailed Report: {regression_analysis['report_url']}")
return is_approved
Monitoreo Programado con la API OpenAI Evals
La evaluación regular ayuda a detectar la deriva o degradación del modelo:
def schedule_periodic_evaluation(
eval_id: str,
baseline_run_id: str,
interval_hours: int = 24
) -> None:
"""
Schedule periodic evaluations to monitor for performance changes.
Args:
eval_id: ID of the evaluation configuration
baseline_run_id: ID of the baseline run to compare against
interval_hours: Frequency of evaluations in hours
"""
# In a production system, you would use a task scheduler like Airflow,
# Celery, or cloud-native solutions. This is a simplified example.
def perform_periodic_evaluation():
while True:
try:
# Run the current production configuration against the eval
print(f"Running scheduled evaluation at {datetime.now()}")
# Implement your evaluation logic here, similar to regression testing
# Sleep until next scheduled run
time.sleep(interval_hours * 60 * 60)
except Exception as e:
print(f"Error in scheduled evaluation: {e}")
# Implement error handling and alerting
# In a real implementation, you would manage this thread properly
# or use a dedicated scheduling system
import threading
evaluation_thread = threading.Thread(target=perform_periodic_evaluation)
evaluation_thread.daemon = True
evaluation_thread.start()
Patrones de Uso Avanzados de la API OpenAI Evals
Pipelines de Evaluación Multi-etapa
Para aplicaciones complejas, implemente pipelines de evaluación multi-etapa:
def create_multi_stage_evaluation_pipeline(
article_data: List[Dict[str, str]]
) -> Dict[str, Any]:
"""
Create a multi-stage evaluation pipeline for content generation.
Args:
article_data: List of articles for evaluation
Returns:
Dictionary containing evaluation results from each stage
"""
# Stage 1: Content generation evaluation
generation_eval_id = create_content_generation_eval()
generation_run_id = run_content_generation_eval(generation_eval_id, article_data)
# Stage 2: Factual accuracy evaluation
accuracy_eval_id = create_factual_accuracy_eval()
accuracy_run_id = run_factual_accuracy_eval(accuracy_eval_id, article_data)
# Stage 3: Tone and style evaluation
tone_eval_id = create_tone_style_eval()
tone_run_id = run_tone_style_eval(tone_eval_id, article_data)
# Aggregate results from all stages
results = {
"generation": analyze_run_results(generation_run_id),
"accuracy": analyze_run_results(accuracy_run_id),
"tone": analyze_run_results(tone_run_id)
}
# Calculate composite score
composite_score = (
results["generation"].get("overall_pass_rate", 0) * 0.4 +
results["accuracy"].get("overall_pass_rate", 0) * 0.4 +
results["tone"].get("overall_pass_rate", 0) * 0.2
)
results["composite_score"] = composite_score
return results
Conclusión: Dominando la API OpenAI Evals
La API OpenAI Evals representa un avance significativo en la evaluación sistemática de LLM, proporcionando a los desarrolladores herramientas poderosas para evaluar objetivamente el rendimiento del modelo y tomar decisiones basadas en datos.
A medida que los LLM se integran cada vez más en aplicaciones críticas, la importancia de la evaluación sistemática crece de manera correspondiente. La API OpenAI Evals proporciona la infraestructura necesaria para implementar estas prácticas de evaluación a escala, asegurando que sus sistemas de IA sigan siendo robustos, confiables y alineados con sus expectativas a lo largo del tiempo.
Pero, ¿por qué detenerse aquí? La integración de Apidog en su flujo de trabajo de la API OpenAI Evals proporciona ventajas significativas:
- Pruebas Simplificadas: Las plantillas de solicitud de Apidog y las capacidades de prueba automatizadas reducen el tiempo de desarrollo para implementar pipelines de evaluación
- Documentación Mejorada: La generación automática de documentación de la API garantiza que sus criterios de evaluación e implementaciones estén bien documentados
- Colaboración en Equipo: Los espacios de trabajo compartidos facilitan estándares de evaluación consistentes en todos los equipos de desarrollo
- Integración de CI/CD: Las capacidades de la línea de comandos permiten la integración con los pipelines de CI/CD existentes para pruebas automatizadas
- Análisis Visual: Las herramientas de visualización integradas ayudan a interpretar rápidamente los resultados de evaluación complejos
<


