
¡Bienvenido! Si alguna vez te has preguntado cómo aprovechar las herramientas de IA de vanguardia para el web scraping y el análisis de contenido, entonces estás en el lugar correcto. Hoy, profundizaremos en un emocionante proyecto que combina OpenAI SWARM, Streamlit y sistemas multiagente para hacer que el web scraping sea más inteligente y el análisis de contenido más perspicaz. También exploraremos cómo Apidog puede simplificar las pruebas de API y servir como una alternativa más asequible para tus necesidades de API.
¡Ahora, comencemos a construir un sistema de web scraping y análisis de contenido completamente funcional!
1. ¿Qué es OpenAI SWARM?
OpenAI SWARM es un enfoque emergente para aprovechar la IA y los sistemas multiagente para automatizar diversas tareas, incluido el web scraping y el análisis de contenido. En esencia, SWARM se centra en el uso de múltiples agentes que pueden trabajar de forma independiente o colaborar en tareas específicas para lograr un objetivo común.

Cómo funciona SWARM
Imagina que quieres extraer datos de varios sitios web para recopilar datos para el análisis. El uso de un solo bot de scraping puede funcionar, pero es propenso a cuellos de botella, errores o incluso a ser bloqueado por el sitio web. SWARM, sin embargo, te permite implementar varios agentes para abordar diferentes aspectos de la tarea: algunos agentes se centran en la extracción de datos, otros en la limpieza de datos y otros en la transformación de los datos para el análisis. Estos agentes pueden comunicarse entre sí, lo que garantiza un manejo eficiente de las tareas.
Al combinar los potentes modelos de lenguaje de OpenAI y las metodologías SWARM, puedes construir sistemas inteligentes y adaptables que imiten la resolución de problemas humanos. Utilizaremos técnicas SWARM para un web scraping y procesamiento de datos más inteligentes en este tutorial.
2. Introducción a los sistemas multiagente
Un sistema multiagente (SMA) es una colección de agentes autónomos que interactúan en un entorno compartido para resolver problemas complejos. Los agentes pueden realizar tareas en paralelo, lo que hace que los SMA sean ideales para situaciones en las que los datos deben recopilarse de diversas fuentes o se necesitan diferentes etapas de procesamiento.
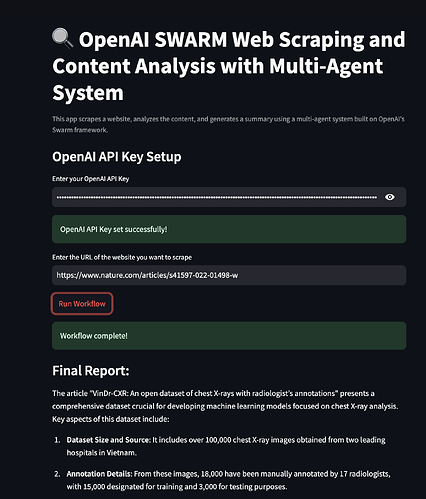
En el contexto del web scraping, un sistema multiagente podría involucrar agentes para:
- Extracción de datos: Rastrear diferentes páginas web para recopilar datos relevantes.
- Análisis de contenido: Limpiar y organizar los datos para el análisis.
- Análisis de datos: Aplicar algoritmos para obtener información de los datos recopilados.
- Informes: Presentar los resultados en un formato fácil de usar.
¿Por qué utilizar sistemas multiagente para el web scraping?
Los sistemas multiagente son robustos contra fallos y pueden operar de forma asíncrona. Esto significa que incluso si un agente falla o encuentra un problema, el resto puede continuar con sus tareas. El enfoque SWARM garantiza así una mayor eficiencia, escalabilidad y tolerancia a fallos en los proyectos de web scraping.
3. Streamlit: Una visión general
Streamlit es una popular biblioteca de Python de código abierto que facilita la creación y el intercambio de aplicaciones web personalizadas para el análisis de datos, el aprendizaje automático y los proyectos de automatización. Proporciona un marco donde puedes construir interfaces de usuario interactivas sin ninguna experiencia en frontend.
¿Por qué Streamlit?
- Facilidad de uso: Escribe código Python y Streamlit lo convierte en una interfaz web fácil de usar.
- Prototipado rápido: Permite la prueba e implementación rápidas de nuevas ideas.
- Integración con modelos de IA: Se integra perfectamente con bibliotecas de aprendizaje automático y API.
- Personalización: Lo suficientemente flexible como para construir aplicaciones sofisticadas para diferentes casos de uso.
En nuestro proyecto, utilizaremos Streamlit para visualizar los resultados del web scraping, mostrar las métricas de análisis de contenido y crear una interfaz interactiva para controlar nuestro sistema multiagente.
4. Por qué Apidog es un cambio de juego
Apidog es una alternativa robusta a las herramientas tradicionales de desarrollo y prueba de API. Admite todo el ciclo de vida de la API, desde el diseño hasta la prueba y la implementación, todo dentro de una plataforma unificada.
Características clave de Apidog:
- Interfaz fácil de usar: Diseño de API fácil de usar con la función de arrastrar y soltar.
- Pruebas automatizadas: Realiza pruebas de API integrales sin escribir scripts adicionales.
- Documentación integrada: Genera documentación detallada de la API automáticamente.
- Planes de precios más económicos: Ofrece una opción más asequible en comparación con la competencia.
Apidog es una combinación perfecta para proyectos donde la integración y las pruebas de API son esenciales, lo que la convierte en una solución rentable e integral.
Descarga Apidog gratis para experimentar estos beneficios de primera mano.
5. Configuración de tu entorno de desarrollo
Antes de sumergirnos en el código, asegurémonos de que nuestro entorno esté listo. Necesitarás:
- Python 3.7+
- Streamlit: Instala con
pip install streamlit - BeautifulSoup para web scraping: Instala con
pip install beautifulsoup4 - Requests: Instala con
pip install requests - Apidog: Para las pruebas de API, puedes descargarlo desde el sitio web oficial de Apidog
Asegúrate de tener todo lo anterior instalado. Ahora, configuremos el entorno.
6. Construcción de un sistema multiagente para el web scraping
Construyamos un sistema multiagente para el web scraping utilizando OpenAI SWARM y bibliotecas de Python. El objetivo aquí es crear múltiples agentes para realizar tareas como rastrear, analizar y analizar datos de varios sitios web.
Paso 1: Definición de los agentes
Crearemos agentes para diferentes tareas:
- Agente rastreador: Recopila HTML sin procesar de páginas web.
- Agente analizador: Extrae información significativa.
- Agente analizador: Procesa los datos para obtener información.
Aquí te mostramos cómo puedes definir un CrawlerAgent simple en Python:
import requests
from bs4 import BeautifulSoup
class CrawlerAgent:
def __init__(self, url):
self.url = url
def fetch_content(self):
try:
response = requests.get(self.url)
if response.status_code == 200:
return response.text
else:
print(f"Failed to fetch content from {self.url}")
except Exception as e:
print(f"Error: {str(e)}")
return None
crawler = CrawlerAgent("https://example.com")
html_content = crawler.fetch_content()
Paso 2: Adición de un agente analizador
El ParserAgent limpiará y estructurará el HTML sin procesar:
class ParserAgent:
def __init__(self, html_content):
self.html_content = html_content
def parse(self):
soup = BeautifulSoup(self.html_content, 'html.parser')
parsed_data = soup.find_all('p') # Example: Extracting all paragraphs
return [p.get_text() for p in parsed_data]
parser = ParserAgent(html_content)
parsed_data = parser.parse()
Paso 3: Adición de un agente analizador
Este agente aplicará técnicas de procesamiento del lenguaje natural (PNL) para analizar el contenido.
from collections import Counter
class AnalyzerAgent:
def __init__(self, text_data):
self.text_data = text_data
def analyze(self):
word_count = Counter(" ".join(self.text_data).split())
return word_count.most_common(10) # Example: Top 10 most common words
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
print(analysis_result)
7. Análisis de contenido con SWARM y Streamlit
Ahora que tenemos a los agentes trabajando juntos, visualicemos los resultados utilizando Streamlit.
Paso 1: Creación de una aplicación Streamlit
Comienza importando Streamlit y configurando la estructura básica de la aplicación:
import streamlit as st
st.title("Web Scraping and Content Analysis with Multi-Agent Systems")
st.write("Using OpenAI SWARM and Streamlit for smarter data extraction.")
Paso 2: Integración de agentes
Integraremos nuestros agentes en la aplicación Streamlit, permitiendo a los usuarios ingresar una URL y ver los resultados del scraping y el análisis.
url = st.text_input("Enter a URL to scrape:")
if st.button("Scrape and Analyze"):
if url:
crawler = CrawlerAgent(url)
html_content = crawler.fetch_content()
if html_content:
parser = ParserAgent(html_content)
parsed_data = parser.parse()
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
st.subheader("Top 10 Most Common Words")
st.write(analysis_result)
else:
st.error("Failed to fetch content. Please try a different URL.")
else:
st.warning("Please enter a valid URL.")
Paso 3: Implementación de la aplicación
Puedes implementar la aplicación utilizando el comando:
streamlit run your_script_name.py

8. Pruebas de API con Apidog
Ahora, veamos cómo Apidog puede ayudar con las pruebas de API en nuestra aplicación de web scraping.
Paso 1: Configuración de Apidog
Descarga e instala Apidog desde el sitio web oficial de Apidog. Sigue la guía de instalación para configurar el entorno.
Paso 2: Creación de solicitudes de API
Puedes crear y probar tus solicitudes de API directamente dentro de Apidog. Admite varios tipos de solicitud, como GET, POST, PUT y DELETE, lo que lo hace versátil para cualquier escenario de web scraping.
Paso 3: Automatización de las pruebas de API
Con Apidog, automatiza los scripts de prueba para validar la respuesta de tu sistema multiagente al conectarse a servicios externos. Esto garantiza que tu sistema siga siendo robusto y coherente con el tiempo.
9. Implementación de tu aplicación Streamlit
Una vez que tu aplicación esté completa, impleméntala para acceso público. Streamlit lo facilita con su servicio Streamlit Sharing.
- Aloja tu código en GitHub.
- Navega a Streamlit Sharing y conecta tu repositorio de GitHub.
- Implementa tu aplicación con un solo clic.
10. Conclusión
¡Enhorabuena! Has aprendido a construir un potente sistema de web scraping y análisis de contenido utilizando OpenAI SWARM, Streamlit y sistemas multiagente. Exploramos cómo las técnicas SWARM pueden hacer que el scraping sea más inteligente y el análisis de contenido más preciso. Al integrar Apidog, también obtuviste información sobre las pruebas y la validación de API para garantizar la fiabilidad de tu sistema.
Ahora, adelante y descarga Apidog gratis para mejorar aún más tus proyectos con potentes funciones de prueba de API. Apidog destaca como una alternativa más asequible y eficiente a otras soluciones, ofreciendo una experiencia perfecta para los desarrolladores.
Con este tutorial, estás listo para abordar tareas complejas de scraping y análisis de datos de manera más efectiva. ¡Buena suerte y feliz codificación!


