
El procesamiento de audio ha ganado rápidamente importancia en la inteligencia artificial, impulsando aplicaciones como asistentes virtuales, herramientas de transcripción e interfaces controladas por voz. OpenAI, un pionero en la innovación de la IA, reveló recientemente sus modelos de audio de próxima generación, estableciendo un nuevo estándar para las capacidades de voz a texto y de texto a voz. Estos modelos, concretamente gpt-4o-transcribe, gpt-4o-mini-transcribe y gpt-4o-mini-tts, ofrecen un rendimiento excepcional, lo que permite a los desarrolladores crear soluciones basadas en la voz más precisas y receptivas. En esta entrada de blog, profundizaremos en cómo puedes acceder a estos modelos a través de la API de OpenAI, ofreciendo una hoja de ruta técnica detallada para que empieces.
Procedamos explorando lo que ofrecen estos nuevos modelos.
¿Cuáles son los nuevos modelos de audio de OpenAI?
Los últimos modelos de audio de OpenAI abordan los desafíos del mundo real en el procesamiento de audio, como entornos ruidosos y diversos patrones de habla. Para utilizar eficazmente la API, primero debes comprender las capacidades de cada modelo.

Aquí tienes un desglose.
Gpt-4o-transcribe: Voz a texto de precisión
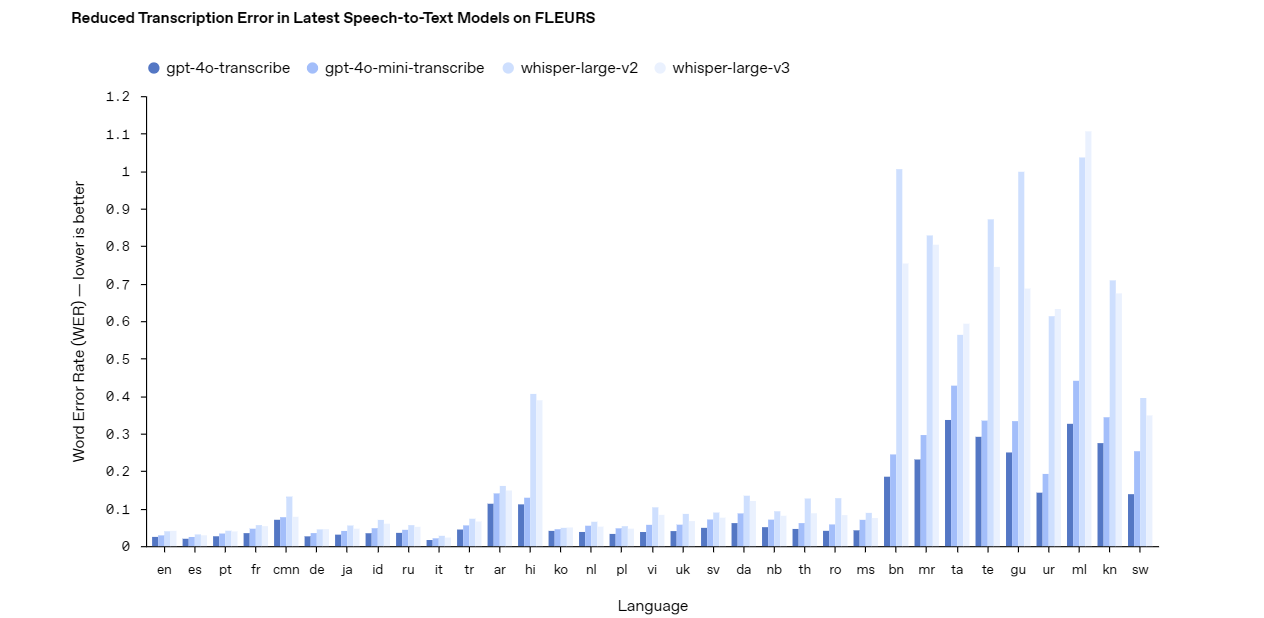
El modelo gpt-4o-transcribe destaca como una solución robusta de voz a texto. Ofrece una alta precisión, incluso en condiciones difíciles como ruido de fondo o habla rápida. Los desarrolladores pueden confiar en este modelo para aplicaciones que requieran una transcripción precisa, como subtitulado en vivo, sistemas de comandos de voz o herramientas de análisis de audio. Su diseño avanzado lo convierte en una opción superior para proyectos complejos y de alto riesgo.
Gpt-4o-mini-transcribe: Transcripción ligera
En contraste, el modelo gpt-4o-mini-transcribe ofrece una alternativa más ligera y eficiente. Si bien sacrifica algo de precisión en comparación con gpt-4o-transcribe, consume menos recursos, lo que lo hace ideal para tareas más sencillas. Utiliza este modelo para aplicaciones como notas de voz informales o reconocimiento básico de comandos donde la velocidad y la eficiencia superan la necesidad de una precisión perfecta.

Gpt-4o-mini-tts: Texto a voz personalizable
Cambiando a texto a voz, el modelo gpt-4o-mini-tts brilla con su salida de sonido natural. A diferencia de los sistemas tradicionales de texto a voz, este modelo permite la personalización del tono, el estilo y la emoción a través de instrucciones. Esta flexibilidad se adapta a proyectos como agentes de voz personalizados, narración de audiolibros o bots de servicio al cliente que necesitan una experiencia de voz a medida.
Con estos modelos en mente, pasemos a comprender la estructura de precios antes de acceder a ellos a través de la API.
Precios para la API de los modelos de audio de OpenAI
Antes de integrar los modelos de audio de OpenAI en tus proyectos, es crucial comprender los costes asociados. OpenAI ofrece un modelo de precios basado en el uso para sus APIs de audio, que varía según el modelo específico y el volumen de uso. A continuación, describimos los detalles clave de los precios para gpt-4o-transcribe, gpt-4o-mini-transcribe y gpt-4o-mini-tts.
Modelos de voz a texto: gpt-4o-transcribe y gpt-4o-mini-transcribe
Para los servicios de voz a texto, OpenAI cobra en función de la duración del audio procesado. Las tarifas difieren entre el modelo completo gpt-4o-transcribe y el ligero gpt-4o-mini-transcribe:
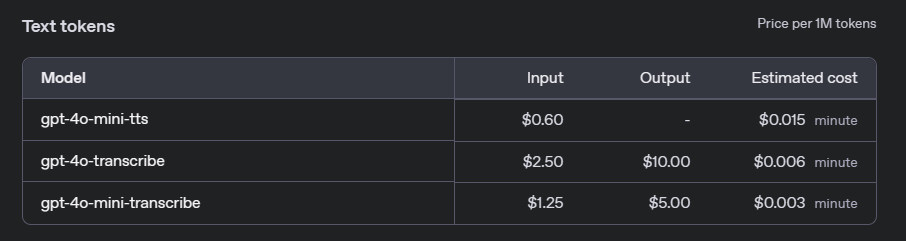
- gpt-4o-transcribe: 0,006 $ por minuto de audio.
- gpt-4o-mini-transcribe: 0,003 $ por minuto de audio.
Estas tarifas hacen de gpt-4o-mini-transcribe una opción rentable para aplicaciones donde la precisión extrema no es crítica, mientras que gpt-4o-transcribe es más adecuado para tareas de alta precisión.
Modelo de texto a voz: gpt-4o-mini-tts
Para texto a voz, el precio se basa en el número de caracteres del texto de entrada:
- gpt-4o-mini-tts: 0,015 $ por carácter.
Este precio permite flexibilidad, especialmente para aplicaciones que generan longitudes variables de salida de audio, como respuestas de voz interactivas o generación de audiolibros.
Nivel gratuito y límites de uso
OpenAI proporciona un nivel gratuito para que los desarrolladores experimenten con los modelos de audio antes de comprometerse con el uso de pago. Los nuevos usuarios reciben 5 $ en créditos gratuitos, que se pueden aplicar a cualquier servicio de API, incluidos los modelos de audio. Además, el uso está sujeto a límites de velocidad para garantizar un acceso justo. Por ejemplo, la API de voz a texto tiene un límite de 100 solicitudes por minuto, mientras que la API de texto a voz permite hasta 50 solicitudes por minuto.
Comprender estos costes te ayudará a presupuestar eficazmente a medida que integres los modelos de audio en tus aplicaciones. Ahora, pasemos a acceder a estos modelos a través de la API.
Cómo acceder a la API de los modelos de audio de OpenAI: Paso a paso
Acceder a la API de OpenAI requiere un enfoque estructurado. Sigue estos pasos para integrar los modelos de audio en tus proyectos.
Paso 1: Obtén una clave API
Primero, obtén una clave API de OpenAI. Visita la plataforma OpenAI, crea una cuenta si aún no lo has hecho y genera una clave en el panel de control del desarrollador. Guarda esta clave de forma segura: es tu puerta de entrada a la API y debe permanecer confidencial.

Paso 2: Instala la biblioteca de Python de OpenAI
A continuación, instala la biblioteca de Python de OpenAI para simplificar las interacciones de la API. Abre tu terminal y ejecuta este comando:
pip install openai
Esta biblioteca proporciona una interfaz limpia para enviar solicitudes, lo que te ahorra llamadas HTTP manuales.
Paso 3: Autentica tu clave API
Antes de enviar solicitudes, autentica tu script con la clave API. Añade este código a tu archivo de Python:
import openai
openai.api_key = 'tu-clave-api-aquí'
Reemplaza 'tu-clave-api-aquí' con tu clave real. Este paso garantiza que tus solicitudes estén autorizadas.
Paso 4: Envía solicitudes a los modelos de audio
Ahora, hagamos solicitudes a los modelos de audio. Cada modelo utiliza puntos finales y parámetros específicos. A continuación, se muestran ejemplos tanto para voz a texto como para texto a voz.
Voz a texto con gpt-4o-transcribe
Para transcribir audio utilizando gpt-4o-transcribe, envía un archivo de audio a la API. Aquí tienes un script de ejemplo:
with open('archivo_audio.wav', 'rb') as archivo_audio:
response = openai.Audio.transcribe(
model="gpt-4o-transcribe",
file=archivo_audio
)
print(response['text'])
Este código abre un archivo de audio (por ejemplo, archivo_audio.wav) e imprime el texto transcrito. Asegúrate de que tu archivo esté en un formato compatible como WAV o MP3.
Texto a voz con gpt-4o-mini-tts
Para texto a voz con gpt-4o-mini-tts, proporciona texto e instrucciones de voz opcionales. Prueba este ejemplo:
response = openai.Audio.synthesize(
model="gpt-4o-mini-tts",
text="¡Bienvenido a nuestro servicio! ¿Cómo puedo ayudarte?",
voice_instructions="Utiliza un tono cálido y profesional."
)
with open('audio_salida.wav', 'wb') as archivo_audio:
archivo_audio.write(response['audio'])
Esto genera un archivo de audio (audio_salida.wav) con una voz personalizada. Experimenta con voice_instructions para ajustar la salida.
Con estos pasos completos, estás listo para integrar los modelos en aplicaciones del mundo real.
Aplicaciones prácticas de los modelos de audio de OpenAI
Los modelos de audio de OpenAI desbloquean numerosas posibilidades. Aquí tienes algunos ejemplos para despertar la inspiración.
Asistentes de voz
Crea un asistente de voz que escuche y responda de forma natural. Combina gpt-4o-transcribe para el reconocimiento de comandos y gpt-4o-mini-tts para las respuestas habladas, creando una experiencia de usuario perfecta.
Servicios de transcripción
Desarrolla una herramienta de transcripción para reuniones o conferencias. Utiliza gpt-4o-transcribe para convertir audio a texto con alta precisión, luego ofrece a los usuarios transcripciones descargables.
Soluciones de accesibilidad
Mejora la accesibilidad convirtiendo texto a voz para usuarios con discapacidad visual. La personalización del modelo gpt-4o-mini-tts garantiza una experiencia de lectura atractiva y similar a la humana.
Automatización de la atención al cliente
Crea un agente de soporte impulsado por IA. Empareja gpt-4o-transcribe para comprender las consultas con gpt-4o-mini-tts para responder con una voz de marca, mejorando la satisfacción del cliente.
Estos ejemplos resaltan la versatilidad de la API. Ahora, analicemos las mejores prácticas para optimizar tu implementación.
Mejores prácticas para usar la API de los modelos de audio de OpenAI
Para maximizar el rendimiento, sigue estas pautas.
Optimiza la calidad del audio
Utiliza siempre entradas de audio de alta calidad. Reduce el ruido de fondo y elige un micrófono claro para mejorar la precisión de la transcripción con gpt-4o-transcribe o gpt-4o-mini-transcribe.
Selecciona el modelo correcto
Adapta el modelo a tus necesidades. Para una precisión crítica, elige gpt-4o-transcribe. Para tareas ligeras, gpt-4o-mini-transcribe es suficiente. Evalúa las limitaciones de recursos antes de decidir.
Aprovecha la personalización
Con gpt-4o-mini-tts, experimenta con instrucciones de voz. Adapta la salida a tu aplicación, ya sea un saludo alegre o una narración tranquila.
Prueba a fondo
Prueba tu integración con diversas muestras de audio. Verifica que gpt-4o-transcribe maneje acentos y ruido, y asegúrate de que gpt-4o-mini-tts ofrezca una calidad de voz consistente.
¿Por qué usar Apidog para las pruebas de API?
Hablando de herramientas, Apidog merece una mirada más de cerca. Esta plataforma agiliza el desarrollo de API al ofrecer funciones como simulación de solicitudes, validación de respuestas y supervisión del rendimiento. Cuando trabajas con la API de OpenAI, Apidog te permite probar puntos finales como gpt-4o-transcribe sin escribir código extenso. Su interfaz intuitiva ahorra tiempo, lo que te permite concentrarte en la construcción en lugar de la depuración.

Conclusión
Los nuevos modelos de audio de OpenAI (gpt-4o-transcribe, gpt-4o-mini-transcribe y gpt-4o-mini-tts) marcan un gran avance en la tecnología de procesamiento de audio. Esta guía te ha mostrado cómo acceder a ellos a través de la API, desde obtener una clave hasta codificar ejemplos prácticos. Ya sea que estés mejorando la accesibilidad o automatizando el soporte, estos modelos ofrecen soluciones potentes.
Para que tu viaje sea más fluido, utiliza Apidog. Descarga Apidog gratis y simplifica tus pruebas de API, asegurando que tus integraciones se ejecuten sin problemas. Comienza a experimentar con los modelos de audio de OpenAI hoy mismo y desbloquea todo su potencial.



