
Ejecutar modelos de lenguaje grandes (LLM) localmente solía ser el dominio de usuarios avanzados de la CLI y de quienes modificaban sistemas. Pero eso está cambiando rápidamente. Ollama, conocido por su sencilla interfaz de línea de comandos para ejecutar LLM de código abierto en máquinas locales, acaba de lanzar aplicaciones de escritorio nativas para macOS y Windows.
Y no son solo envoltorios básicos. Estas aplicaciones incorporan potentes funciones que facilitan drásticamente a los desarrolladores la conversación con modelos, el análisis de documentos, la redacción de documentación e incluso el trabajo con imágenes.
En este artículo, exploraremos cómo la nueva experiencia de escritorio mejora el flujo de trabajo del desarrollador, qué características destacan y dónde estas herramientas realmente brillan en la vida diaria de la codificación.
Por qué los LLM Locales Siguen Siendo Importantes
Aunque las herramientas basadas en la nube como ChatGPT, Claude y Gemini dominan los titulares, hay un movimiento creciente hacia el desarrollo de IA local-first. Los desarrolladores quieren herramientas que sean:
- Privado - Tu código y documentos permanecen en tu máquina.
- Personalizable - Eliges los modelos, los límites de memoria y el hardware.
- Compatible con el modo sin conexión - Sin dependencia de APIs externas ni de tiempo de actividad.
- Rápido - Sin latencia de red ni cuellos de botella del servidor.
Ollama se inserta directamente en esta tendencia, permitiéndote ejecutar modelos como LLaMA, Mistral, Gemma, Codellama, Mixtral y otros de forma nativa en tu máquina, ahora con una experiencia mucho más fluida.
Paso 1: Descarga Ollama para Escritorio
Ve a ollama.com y descarga la última versión para tu sistema:
- macOS (Apple Silicon o Intel)
- Windows 10/11 (x64)
Instálala como una aplicación de escritorio normal. No se requiere configuración de línea de comandos para empezar.
Paso 2: Inicia y Elige un Modelo
Una vez instalada, abre la aplicación de escritorio de Ollama. La interfaz es limpia y parece una ventana de chat sencilla.
Se te pedirá que elijas un modelo para descargar y ejecutar. Algunas opciones incluyen:
llama3– asistente de propósito generalcodellama– ideal para la generación y refactorización de códigomistral– rápido, pequeño y precisogemma– modelo de peso abierto, respaldado por Google
Elige uno y la aplicación lo descargará y cargará automáticamente.
Una Incorporación Más Fluida para Desarrolladores - Una Forma Más Fácil de Chatear con Modelos
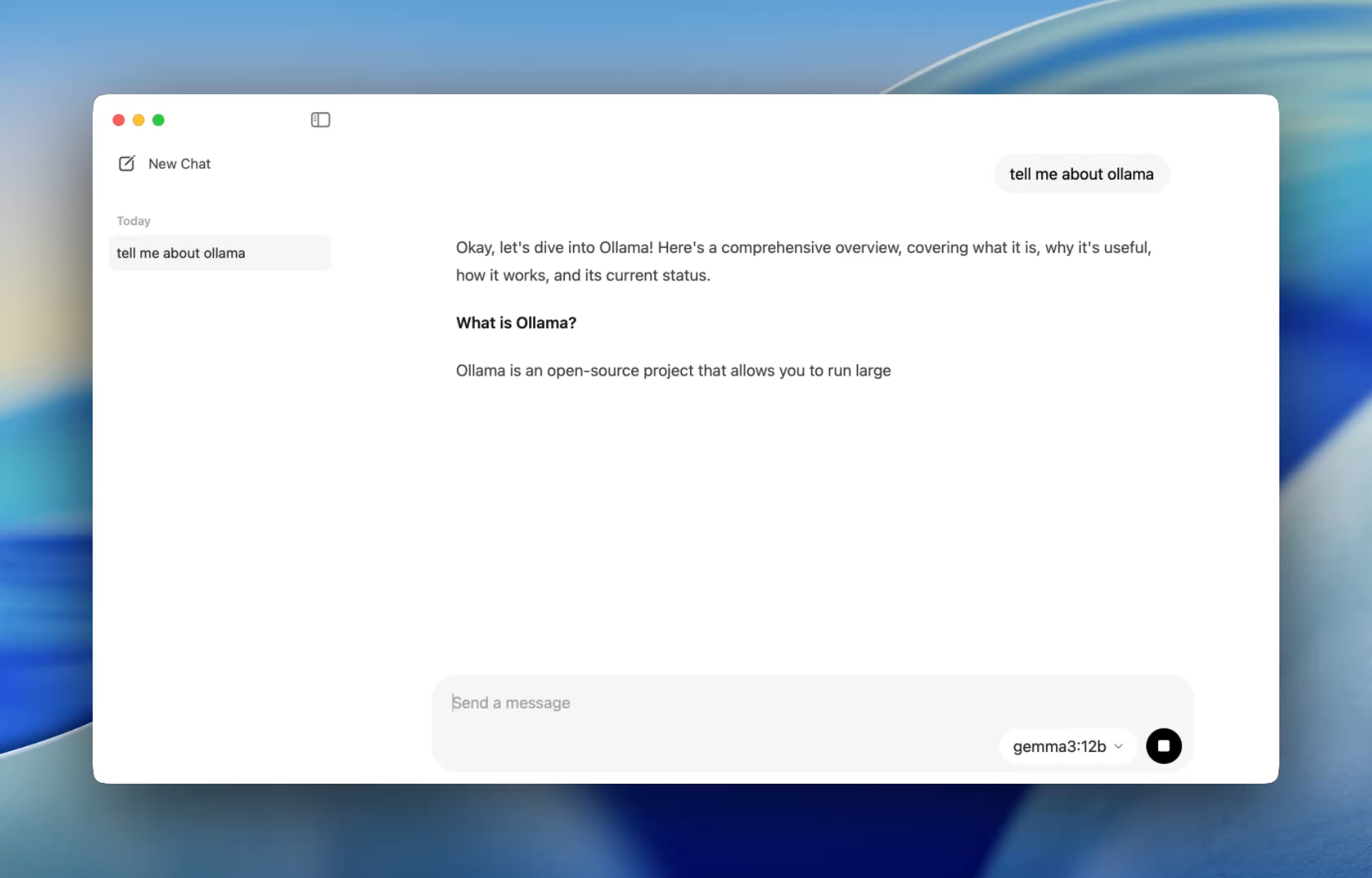
Anteriormente, usar Ollama significaba abrir un terminal y emitir comandos ollama run para iniciar una sesión de modelo. Ahora, la aplicación de escritorio se abre como cualquier aplicación nativa, ofreciendo una interfaz de chat sencilla y limpia.
Ahora puedes hablar con los modelos de la misma manera que lo harías en ChatGPT, pero completamente sin conexión. Esto es perfecto para:
- Asistencia en la revisión de código
- Generación de pruebas
- Consejos de refactorización
- Aprender nuevas APIs o lenguajes
La aplicación te da acceso inmediato a modelos locales como codellama o mistral sin ninguna configuración más allá de una simple instalación.
Y para los desarrolladores que aman la personalización, la CLI sigue funcionando en segundo plano, permitiéndote alternar la longitud del contexto, los prompts del sistema y las versiones del modelo a través del terminal si es necesario.
Arrastrar. Soltar. Hacer Preguntas.
Chatear con Archivos
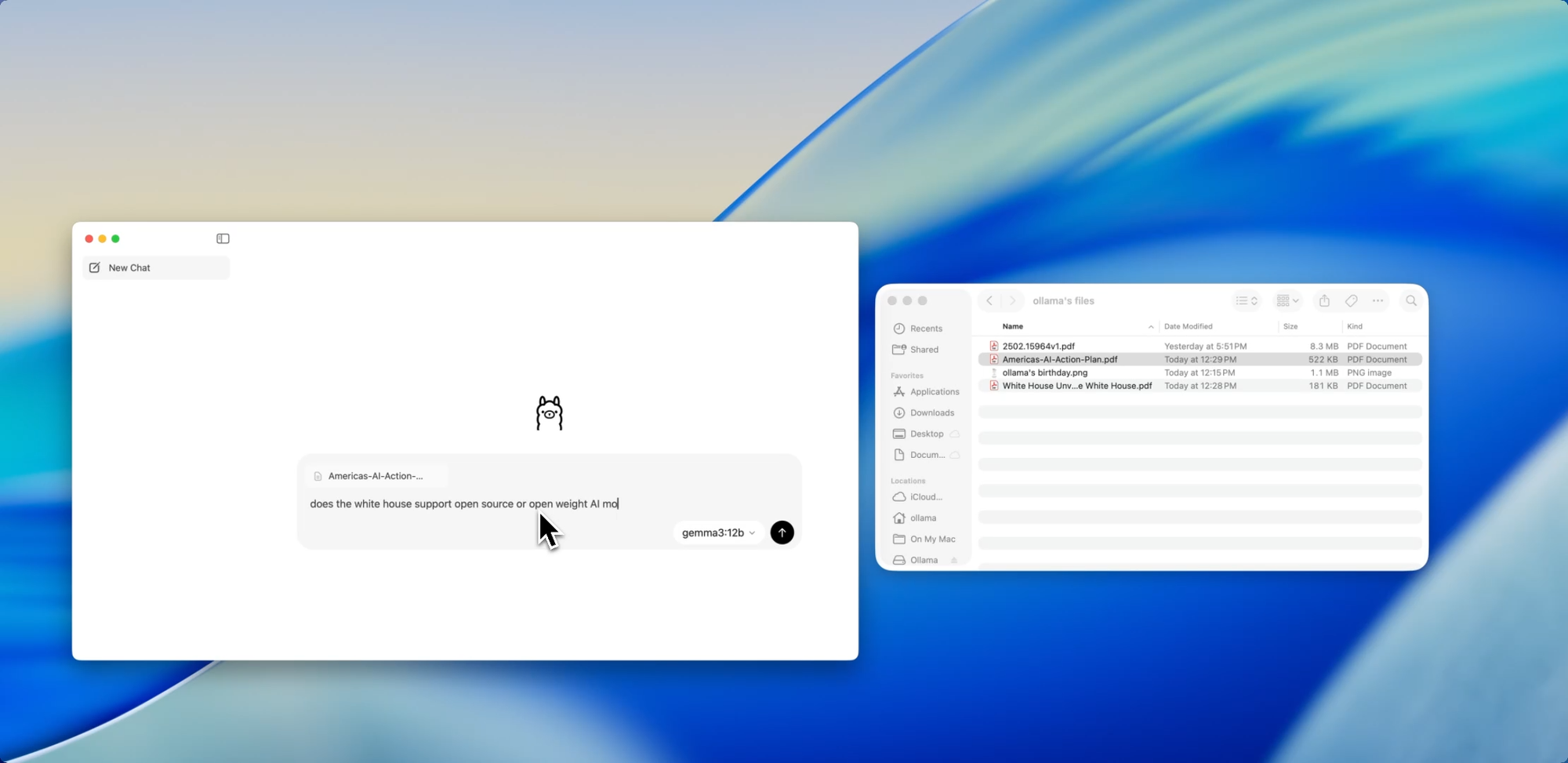
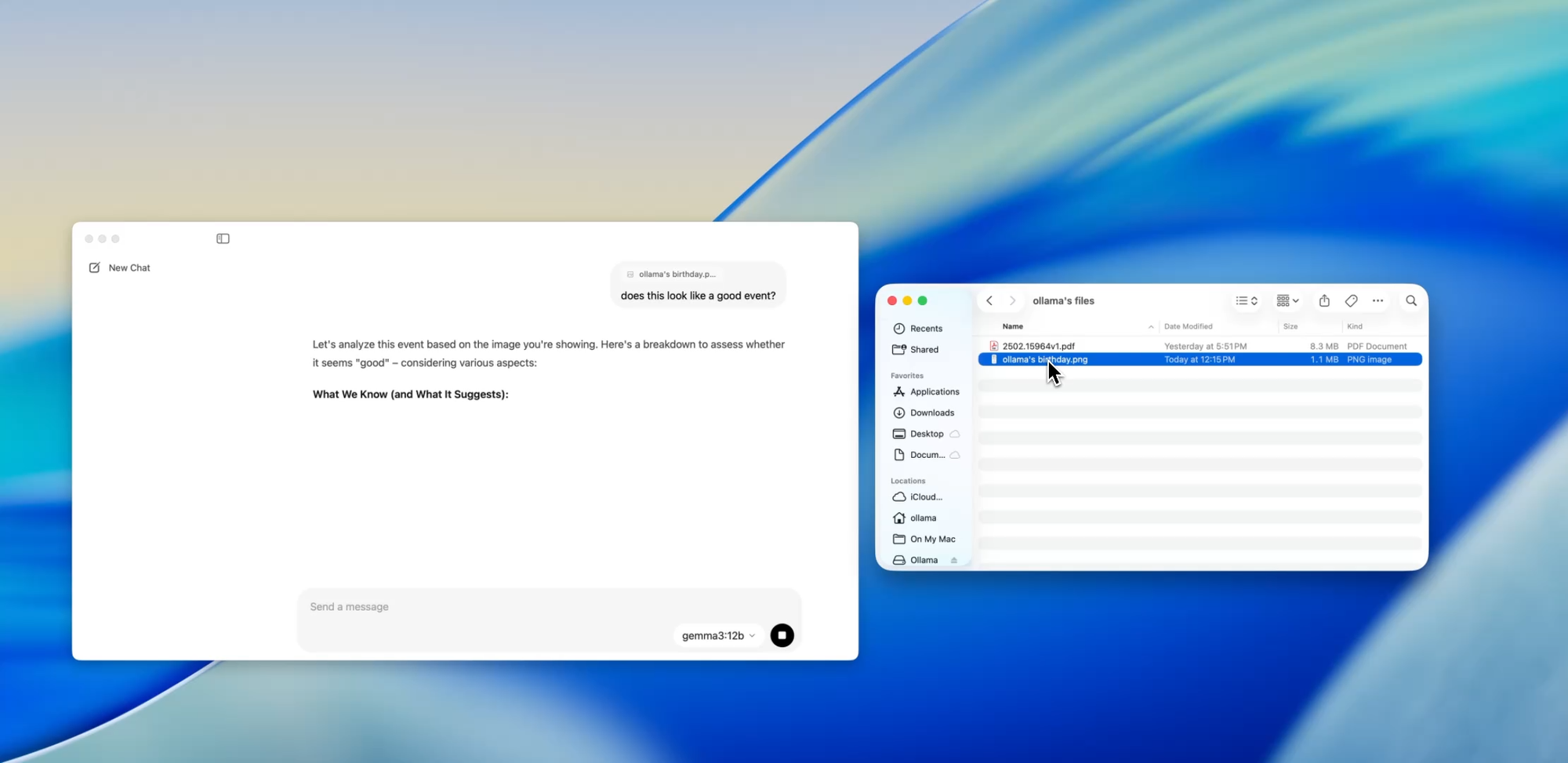
Una de las características más amigables para el desarrollador en la nueva aplicación es la ingesta de archivos. Simplemente arrastra un archivo a la ventana de chat, ya sea un .pdf, .md o .txt, y el modelo leerá su contenido.
¿Necesitas entender un documento de diseño de 60 páginas? ¿Quieres extraer TODOs de un README desordenado? ¿O resumir el resumen de producto de un cliente? Arrástralo y haz preguntas en lenguaje natural como:
- “¿Cuáles son las características principales discutidas en este documento?”
- “Resume esto en un párrafo.”
- “¿Hay alguna sección faltante o inconsistencia?”
Esta característica puede reducir drásticamente el tiempo dedicado a escanear documentación, revisar especificaciones o incorporarse a nuevos proyectos.
Ir Más Allá del Texto
Soporte Multimodal
Modelos seleccionados dentro de Ollama (como los basados en Llava) ahora soportan entrada de imagen. Esto significa que puedes subir una imagen, y el modelo la interpretará y responderá.
Algunos casos de uso incluyen:
- Leer diagramas o gráficos de una captura de pantalla
- Describir maquetas de UI
- Revisar notas manuscritas escaneadas
- Analizar infografías sencillas
Aunque esto todavía está en una etapa temprana en comparación con herramientas como GPT-4 Vision, tener soporte multimodal integrado en una aplicación local-first es un gran paso para los desarrolladores que construyen sistemas de entrada múltiple o prueban interfaces de IA.
Documentos Privados y Locales — a tu Disposición
Escritura de Documentación
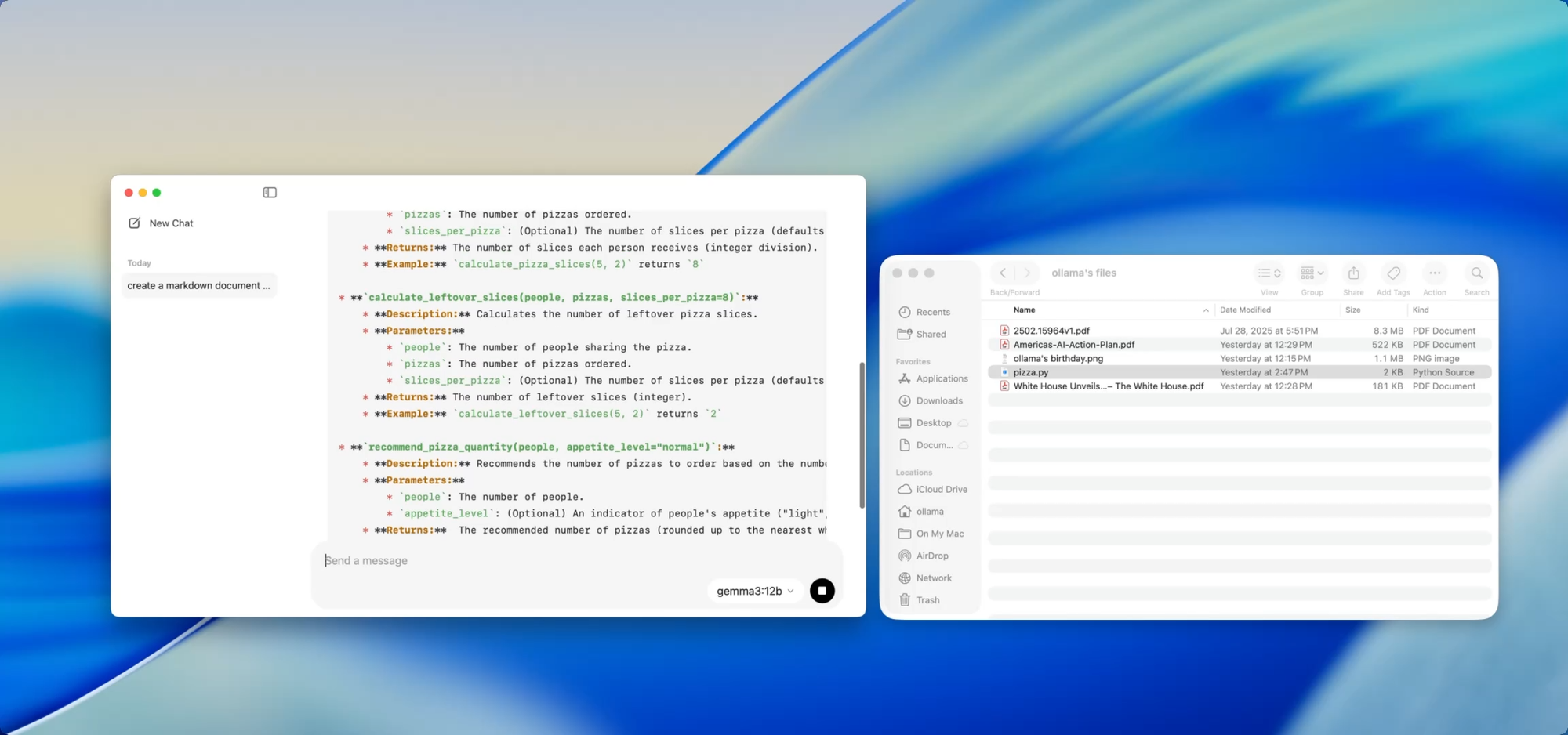
Si mantienes una base de código en crecimiento, conoces el dolor de la deriva de la documentación. Con Ollama, puedes usar modelos locales para ayudar a generar o actualizar documentación sin tener que subir código sensible a la nube.
Simplemente arrastra un archivo — por ejemplo utils.py — a la aplicación y pregunta:
- “Escribe docstrings para estas funciones.”
- “Crea un resumen en Markdown de lo que hace este archivo.”
- “¿Qué dependencias utiliza este módulo?”
Esto se vuelve aún más potente cuando se combina con herramientas como [Deepdocs] que automatizan los flujos de trabajo de documentación usando IA. Puedes precargar los archivos README o de esquema de tu proyecto, luego hacer preguntas de seguimiento o generar registros de cambios, notas de migración o guías de actualización — todo localmente.
Ajuste del Rendimiento Bajo el Capó
Con esta nueva versión, Ollama también mejoró el rendimiento en general:
- La aceleración de GPU está mejor optimizada para Apple Silicon y tarjetas Nvidia/AMD modernas.
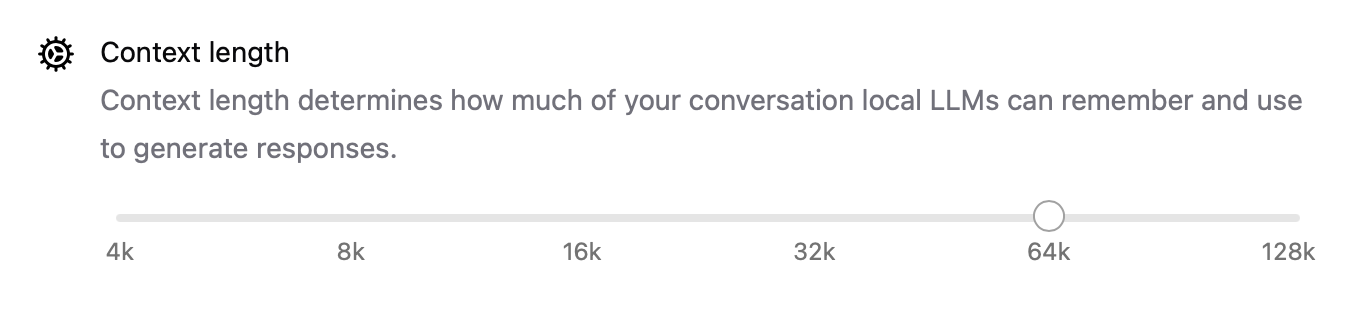
- La longitud del contexto ahora es configurable con ajustes como
num_ctx=8192, para que puedas manejar entradas más largas. - El modo de red permite que Ollama se ejecute como un servidor API local al que puedes llamar desde otras aplicaciones o dispositivos en tu LAN.
- Ahora puedes cambiar la ubicación de almacenamiento para los modelos descargados — perfecto si estás trabajando desde una unidad externa o quieres aislar modelos por proyecto.
Estas mejoras hacen que la aplicación sea flexible para todo, desde agentes locales hasta herramientas de desarrollo y asistentes de investigación personal.
CLI y GUI: Lo Mejor de Ambos Mundos
¿La mejor parte? La nueva aplicación de escritorio no reemplaza el terminal, lo complementa.
Aún puedes:
ollama pull codellama
ollama run codellama
O exponer el servidor del modelo:
ollama serve --host 0.0.0.0
Así que, si estás construyendo una interfaz de IA personalizada, un agente o un plugin que dependa de un LLM local, ahora puedes construir sobre la API de Ollama y usar la GUI para interacción directa o pruebas.
Prueba la API de Ollama Localmente con Apidog
¿Quieres integrar Ollama en tu aplicación de IA o probar sus puntos finales de API locales? Puedes iniciar la API REST de Ollama usando:
bash tollama serve
Luego, usa Apidog para probar, depurar y documentar tus puntos finales de LLM locales.

Por qué usar Apidog con Ollama:
- Interfaz visual para enviar solicitudes POST a tu servidor local
http://localhost:11434 - Soporta la generación de solicitudes asistida por IA y la validación de respuestas
- Perfecto para aplicaciones de IA autoalojadas, frameworks de agentes o herramientas internas
- Funciona sin problemas con flujos de trabajo de LLM locales y servidores de modelos personalizados
Casos de Uso para Desarrolladores que Realmente Funcionan
Aquí es donde la nueva aplicación de Ollama brilla en los flujos de trabajo reales de los desarrolladores:
| Caso de Uso | Cómo Ayuda Ollama |
|---|---|
| Asistente de Revisión de Código | Ejecuta codellama localmente para obtener retroalimentación de refactorización |
| Actualizaciones de Documentación | Pide a los modelos que reescriban, resuman o corrijan archivos de documentación |
| Chatbot de Desarrollo Local | Incrústalo en tu aplicación como un asistente consciente del contexto |
| Herramienta de Investigación sin Conexión | Carga PDFs o documentos técnicos y haz preguntas clave |
| Espacio de Juego Personal para LLM | Experimenta con ingeniería de prompts y ajuste fino |
Para los equipos preocupados por la privacidad de los datos o las alucinaciones del modelo, los flujos de trabajo de LLM local-first ofrecen una alternativa cada vez más atractiva.
Reflexiones Finales
La versión de escritorio de Ollama hace que los LLM locales se sientan menos como un experimento científico improvisado y más como una herramienta de desarrollo pulida.
Con soporte para interacción con archivos, entradas multimodales, escritura de documentos y rendimiento nativo, es una opción seria para los desarrolladores que se preocupan por la velocidad, la flexibilidad y el control.
Sin claves de API en la nube. Sin seguimiento en segundo plano. Sin facturación por token. Solo inferencia rápida y local con la elección del modelo abierto que mejor se adapte a tus necesidades.
Si has tenido curiosidad por ejecutar LLM en tu máquina, o si ya estás usando Ollama y quieres una experiencia más fluida, ahora es el momento de probarlo de nuevo.