
El campo de la inteligencia artificial continúa evolucionando rápidamente, presentando modelos innovadores que redefinen los límites computacionales. Entre estos avances, MiniMax-M1 emerge como un desarrollo revolucionario, marcando su lugar como el primer modelo de razonamiento de atención híbrida a gran escala y de peso abierto del mundo. Desarrollado por MiniMax, este modelo promete transformar la forma en que abordamos tareas de razonamiento complejas, ofreciendo una impresionante ventana de contexto de entrada de 1 millón de tokens y de salida de 80,000 tokens.
Comprendiendo la Arquitectura Central de MiniMax-M1
MiniMax-M1 destaca por su arquitectura única híbrida de Mezcla de Expertos (MoE), combinada con un mecanismo de atención ultrarrápido. Este diseño se basa en los cimientos establecidos por su predecesor, MiniMax-Text-01, que cuenta con la asombrosa cifra de 456 mil millones de parámetros, con 45.9 mil millones activados por token. El enfoque MoE permite que el modelo active solo un subconjunto de sus parámetros según la entrada, optimizando la eficiencia computacional y permitiendo la escalabilidad. Mientras tanto, el mecanismo de atención híbrida mejora la capacidad del modelo para procesar datos de contexto largo, haciéndolo ideal para tareas que requieren una comprensión profunda sobre secuencias extendidas.

La integración de estos componentes resulta en un modelo que equilibra eficazmente el rendimiento y el uso de recursos. Al activar selectivamente a los expertos dentro del marco MoE, MiniMax-M1 reduce la sobrecarga computacional típicamente asociada con los modelos a gran escala. Además, el mecanismo de atención ultrarrápido acelera el procesamiento de los pesos de atención, asegurando que el modelo mantenga un alto rendimiento incluso con su amplia ventana de contexto.
Eficiencia del Entrenamiento: El Papel del Aprendizaje por Refuerzo
Uno de los aspectos más notables de MiniMax-M1 es su proceso de entrenamiento, que aprovecha el aprendizaje por refuerzo (RL) a gran escala con una eficiencia sin precedentes. El modelo fue entrenado a un costo de solo $534,700, una cifra que subraya el innovador marco de escalado de RL desarrollado por MiniMax. Este marco introduce CISPO (Clipped Importance Sampling with Policy Optimization), un algoritmo novedoso que recorta los pesos de muestreo de importancia en lugar de las actualizaciones de tokens. Este enfoque supera a las variantes tradicionales de RL, proporcionando un proceso de entrenamiento más estable y eficiente.

Además, el diseño de atención híbrida juega un papel crucial en la mejora de la eficiencia de RL. Al abordar desafíos únicos asociados con la escalada de RL dentro de una arquitectura híbrida, MiniMax-M1 logra un nivel de rendimiento que rivaliza con los modelos de peso cerrado, a pesar de su naturaleza de código abierto. Esta metodología de entrenamiento no solo reduce los costos, sino que también establece un nuevo punto de referencia para el desarrollo de modelos de IA de alto rendimiento con recursos limitados.
Métricas de Rendimiento: Benchmarking de MiniMax-M1
Para evaluar las capacidades de MiniMax-M1, los desarrolladores realizaron extensas pruebas de rendimiento en una variedad de tareas, incluyendo matemáticas a nivel de competición, codificación, ingeniería de software, uso de herramientas agentivas y comprensión de contexto largo. Los resultados destacan la superioridad del modelo sobre otros modelos de peso abierto como DeepSeek-R1 y Qwen3-235B-A22B.
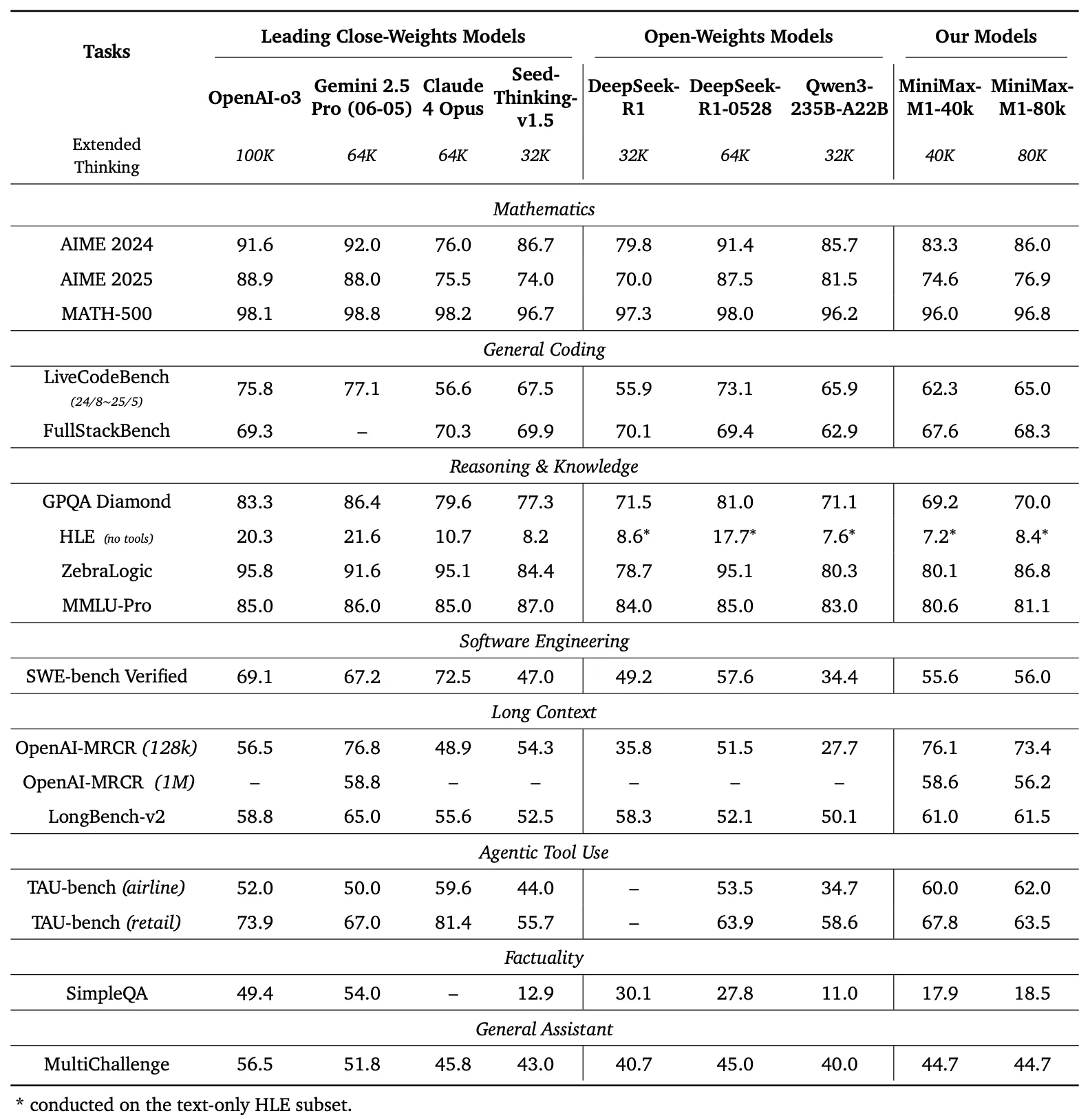
Comparación de Benchmarks
El panel izquierdo de la Figura 1 compara el rendimiento de MiniMax-M1 con los principales modelos comerciales y de peso abierto en varios benchmarks.

- AIME 2024: MiniMax-M1 alcanza una precisión del 86.0%, superando a OpenAI o3 (88.0%) y Claude 4 Opus (80.0%), demostrando su destreza en el razonamiento matemático.
- LiveCodeBench: Con una puntuación del 65.0%, MiniMax-M1 supera a DeepSeek-R1-0528 (56.0%) e iguala el rendimiento de Seed-Thinking v1.5 (65.0%), indicando sólidas capacidades de codificación.
- SW-E Bench Verified: El modelo obtiene una puntuación del 62.8%, superando a Qwen3-235B-A22B (60.0%) en tareas de ingeniería de software.
- TAU-bench: MiniMax-M1 registra una precisión del 73.4%, superando a Gemini 2.5 Pro (70.0%) en el uso de herramientas agentivas.
- MRCR (4-needle): Con una precisión del 74.4%, lidera sobre otros modelos en tareas de comprensión de contexto largo.
Estos resultados subrayan la versatilidad de MiniMax-M1 y su capacidad para competir con modelos propietarios, convirtiéndolo en un activo valioso para las comunidades de código abierto.

MiniMax-M1 demuestra un aumento lineal en FLOPs (Operaciones de Punto Flotante) a medida que la longitud de generación se extiende de 32k a 128k tokens. Esta escalabilidad asegura que el modelo mantenga la eficiencia y el rendimiento incluso con salidas extendidas, un factor crítico para aplicaciones que requieren respuestas detalladas y extensas.
Razonamiento de Contexto Largo: Una Nueva Frontera
La característica más distintiva de MiniMax-M1 es su ventana de contexto ultra larga, que admite hasta 1 millón de tokens de entrada y 80,000 tokens de salida. Esta capacidad permite que el modelo procese vastas cantidades de datos —equivalentes a una novela completa o una serie de libros— en una sola pasada, superando con creces el límite de 128,000 tokens de modelos como GPT-4 de OpenAI. El modelo ofrece dos modos de inferencia —presupuestos de pensamiento de 40k y 80k— atendiendo a diversas necesidades de escenarios y permitiendo una implementación flexible.

Esta ventana de contexto extendida mejora el rendimiento del modelo en tareas de contexto largo, como resumir documentos extensos, mantener conversaciones de múltiples turnos o analizar conjuntos de datos complejos. Al retener información contextual sobre millones de tokens, MiniMax-M1 proporciona una base sólida para aplicaciones en investigación, análisis legal y generación de contenido, donde mantener la coherencia en secuencias largas es primordial.
Uso de Herramientas Agentivas y Aplicaciones Prácticas
Más allá de su impresionante ventana de contexto, MiniMax-M1 sobresale en el uso de herramientas agentivas, un dominio donde los modelos de IA interactúan con herramientas externas para resolver problemas. La capacidad del modelo para integrarse con plataformas como MiniMax Chat y generar aplicaciones web funcionales —como pruebas de velocidad de escritura y generadores de laberintos— demuestra su utilidad práctica. Estas aplicaciones, construidas con una configuración mínima y sin complementos, muestran la capacidad del modelo para producir código listo para producción.

Por ejemplo, el modelo puede generar una aplicación web limpia y funcional para rastrear palabras por minuto (WPM) en tiempo real o crear un generador de laberintos visualmente atractivo con visualización del algoritmo A*. Tales capacidades posicionan a MiniMax-M1 como una herramienta poderosa para desarrolladores que buscan automatizar flujos de trabajo de desarrollo de software o crear experiencias de usuario interactivas.
Accesibilidad de Código Abierto e Impacto en la Comunidad
El lanzamiento de MiniMax-M1 bajo la licencia Apache 2.0 marca un hito significativo para la comunidad de código abierto. Disponible en GitHub y Hugging Face, el modelo invita a desarrolladores, investigadores y empresas a explorar, modificar e implementar sin restricciones propietarias. Esta apertura fomenta la innovación, permitiendo la creación de soluciones personalizadas adaptadas a necesidades específicas.
La accesibilidad del modelo también democratiza el acceso a tecnología de IA avanzada, permitiendo que organizaciones más pequeñas y desarrolladores independientes compitan con entidades más grandes. Al proporcionar documentación detallada y un informe técnico, MiniMax asegura que los usuarios puedan replicar y extender las capacidades del modelo, acelerando aún más los avances en el ecosistema de la IA.
Implementación Técnica: Despliegue y Optimización
El despliegue de MiniMax-M1 requiere una cuidadosa consideración de los recursos computacionales y las técnicas de optimización. El informe técnico recomienda usar vLLM (Virtual Large Language Model) para el despliegue en producción, que optimiza la velocidad de inferencia y el uso de memoria. Esta herramienta aprovecha la arquitectura híbrida del modelo para distribuir eficientemente la carga computacional, asegurando una operación fluida incluso con entradas a gran escala.
Los desarrolladores pueden ajustar MiniMax-M1 para tareas específicas ajustando el presupuesto de pensamiento (40k u 80k) según sus requisitos. Además, el eficiente marco de entrenamiento de RL del modelo permite una mayor personalización a través del aprendizaje por refuerzo, permitiendo la adaptación a aplicaciones de nicho como la traducción en tiempo real o el soporte automatizado al cliente.
Conclusión: Abrazando la Revolución de MiniMax-M1
MiniMax-M1 representa un avance significativo en el ámbito de los modelos de razonamiento de atención híbrida a gran escala y de peso abierto. Su impresionante ventana de contexto, su eficiente proceso de entrenamiento y su rendimiento superior en los benchmarks lo posicionan como líder en el panorama de la IA. Al ofrecer esta tecnología como un recurso de código abierto, MiniMax empodera a desarrolladores e investigadores para explorar nuevas posibilidades, desde ingeniería de software avanzada hasta análisis de contexto largo.
A medida que la comunidad de IA continúa creciendo, MiniMax-M1 sirve como testimonio del poder de la innovación y la colaboración. Para aquellos listos para explorar su potencial, descargar Apidog de forma gratuita ofrece un punto de entrada práctico para experimentar con este modelo transformador. El viaje con MiniMax-M1 apenas comienza, y su impacto sin duda dará forma al futuro de la inteligencia artificial.
