
Desarrolladores e investigadores buscan cada vez más LLM sin restricciones para ampliar los límites de las aplicaciones de inteligencia artificial. Estos modelos de lenguaje grandes sin censura operan sin filtros de contenido incorporados, lo que permite respuestas sin restricciones a través de diversas consultas. A medida que el panorama de la IA evoluciona, los LLM sin censura empoderan a los usuarios para explorar temas complejos, desde dilemas éticos hasta narraciones creativas, sin restricciones morales o de seguridad predefinidas.
En este artículo, los expertos examinan los fundamentos técnicos de los LLM sin censura, sus arquitecturas y sus implementaciones en el mundo real. Los usuarios deben manejar estos modelos de manera responsable, ya que su falta de filtros puede generar contenido sensible.
Comprendiendo los LLM sin Censura: Fundamentos Técnicos
Los ingenieros diseñan LLM sin censura ajustando modelos base en conjuntos de datos que omiten las instrucciones de alineación, que típicamente aplican pautas éticas en las variantes estándar. Modelos base como Llama 2 o Mistral se someten a este proceso, donde los desarrolladores eliminan los mecanismos de negación —como rechazar consultas sobre violencia o sesgos— y ajustan las indicaciones del sistema para fomentar respuestas exhaustivas. Por ejemplo, técnicas como el Aprendizaje por Refuerzo a partir de Retroalimentación Humana (RLHF) se omiten o se invierten para priorizar la utilidad sobre la seguridad.
Además, los LLM sin censura aprovechan las arquitecturas de transformadores, prediciendo los siguientes tokens en secuencias con miles de millones de parámetros. Las comunidades de código abierto contribuyen compartiendo versiones ajustadas en plataformas como Hugging Face, donde los modelos logran la falta de censura a través de la "abliteración" —un método que erosiona las alineaciones de seguridad mediante un ajuste fino dirigido. Este enfoque asegura que los modelos respondan a cualquier indicación, pero exige hardware robusto para la inferencia, a menudo requiriendo GPU con una VRAM amplia.
Estos modelos difieren de los propietarios como GPT-4, que incorporan filtros estrictos para cumplir con las regulaciones. Las variantes sin censura, sin embargo, fomentan la innovación en campos como la investigación y la simulación, donde las salidas sin restricciones revelan capacidades puras. No obstante, los desarrolladores mitigan los riesgos implementando salvaguardas personalizadas en las aplicaciones.
Beneficios y Riesgos de los LLM sin Restricciones
Los usuarios obtienen ventajas significativas de los LLM sin restricciones, ya que estos modelos ofrecen información sin filtros que mejora la resolución de problemas. Por ejemplo, los investigadores los utilizan para la prueba de hipótesis en dominios sensibles, donde los modelos estándar podrían retener información. Además, los programadores se benefician de la generación de código sin restricciones, acelerando los ciclos de desarrollo sin interrupciones éticas.
Además, estos LLM promueven la transparencia en la IA, permitiendo a los ingenieros inspeccionar y modificar comportamientos directamente. Las comunidades construyen sobre ellos, creando variantes especializadas para tareas como el procesamiento multilingüe o el razonamiento de contexto largo. Sin embargo, surgen riesgos por el posible uso indebido, como la generación de contenido dañino, lo que requiere una supervisión ética por parte de los implementadores.
Plataformas como Ollama permiten ejecuciones locales, minimizando las preocupaciones sobre la privacidad de los datos y maximizando el control. Sin embargo, las altas demandas computacionales plantean barreras, aunque optimizaciones como la cuantificación abordan esto al reducir el tamaño del modelo sin sacrificar mucho rendimiento.
Criterios para Clasificar los 10 Mejores LLM sin Censura
Los analistas clasifican estos modelos basándose en el número de parámetros, la velocidad de inferencia, el soporte de la comunidad y las puntuaciones de referencia de fuentes como las tablas de clasificación de Hugging Face. La versatilidad en diversas tareas —como codificación, juegos de rol y razonamiento— también influye, junto con la facilidad de implementación local. Además, las actualizaciones recientes de 2025 priorizan los modelos con ventanas de contexto extendidas y diseños de mezcla de expertos (MoE) para una mayor eficiencia.
1. Dolphin 3.0: Potencia sin Censura Impulsada por la Precisión
Cognitive Computations desarrolla Dolphin 3.0 sobre la base Llama 3.1 8B, ajustándolo para un razonamiento y una capacidad de dirección excepcionales a través de indicaciones del sistema. Este modelo sobresale en tareas intensivas en lógica, entregando salidas precisas y sin filtrar, sin relleno verboso. Los ingenieros aprecian sus 8 mil millones de parámetros, que equilibran el rendimiento y las necesidades de recursos, requiriendo aproximadamente 16 GB de VRAM para una inferencia óptima.

Las características clave incluyen una arquitectura híbrida que mejora la adherencia a las indicaciones, lo que lo hace ideal para asistentes de IA personalizados. Además, Dolphin 3.0 admite la llamada a funciones, lo que permite la integración con herramientas externas. Los pros incluyen un control inigualable sobre las personas y una rápida resolución de problemas en codificación o matemáticas, mientras que los contras implican su estilo de prosa directo, que se adapta a aplicaciones técnicas pero no narrativas.
Los desarrolladores ejecutan Dolphin 3.0 localmente usando Ollama: instalan la herramienta, extraen el modelo con ollama pull dolphin-llama3 y consultan a través de API o CLI. Los puntos de referencia muestran que supera a sus pares en razonamiento estructurado, con puntuaciones superiores al 80% en las pruebas MMLU. Además, su falta de censura proviene de la curación de conjuntos de datos que evita los sesgos de alineación, lo que permite la exploración de casos extremos en la investigación.
En escenarios de implementación, los equipos lo integran en pipelines para análisis automatizado, donde su eficiencia brilla. Sin embargo, los usuarios calibran las indicaciones cuidadosamente para evitar sesgos no intencionados.
2. Nous Hermes 3: Modelo sin Censura Centrado en la Creatividad
NousResearch crea Nous Hermes 3 sobre la base Llama 3.2 8B, enfatizando la escritura creativa y los juegos de rol con salidas coherentes de formato largo. Con 8 mil millones de parámetros, mantiene la consistencia del personaje en los diálogos, aprovechando ChatML para conversaciones estructuradas. Esto lo convierte en una opción principal para la generación narrativa sin restricciones.

Las características destacan su comprensión matizada de las indicaciones, soportando contextos extendidos de hasta 8k tokens. Los pros incluyen una elaboración superior de ficción e interacciones atractivas, mientras que los contras señalan una verbosidad ocasional en consultas concisas. Las actualizaciones impulsadas por la comunidad aseguran mejoras continuas.
Para implementar, los usuarios aprovechan Hugging Face: descargan el modelo, lo cargan con la biblioteca Transformers a través de from transformers import AutoModelForCausalLM; model = AutoModelForCausalLM.from_pretrained('NousResearch/Hermes-3-Llama-3.2-8B'), y generan texto. Los puntos de referencia indican altas puntuaciones en pruebas creativas, a menudo superando el 85% en evaluaciones de juegos de rol.
Además, su falta de censura surge del ajuste fino en conjuntos de datos diversos y sin filtrar, lo que permite exploraciones profundas en la narración. Los desarrolladores lo aplican en el diseño de juegos, donde la creatividad sin restricciones acelera la creación de prototipos.
3. LLaMA-3.2 Dark Champion Abliterado: Bestia sin Censura de Contexto Largo
DavidAU ajusta LLaMA-3.2 Dark Champion en una arquitectura MoE de 8x3B, ablatando las capas de seguridad para obtener salidas no alineadas. Con una ventana de contexto de 128k, procesa documentos extensos de manera eficiente, ideal para el análisis de datos.
El diseño MoE de este modelo activa subconjuntos de parámetros, reduciendo el cómputo mientras mantiene la potencia. Los pros incluyen inferencia rápida y razonamiento profundo, pero los contras incluyen posibles sesgos negativos y altas demandas de VRAM (alrededor de 40 GB).
La instalación implica descargas de Hugging Face, con inferencia a través de pipeline('text-generation', model='DavidAU/Llama-3.2-8X3B-MOE-Dark-Champion-Instruct-uncensored-abliterated-18.4B'). Obtiene altas puntuaciones en pruebas de contexto largo, superando el 90% de precisión en tareas de recuperación.
Además, la abliteración garantiza que no haya restricciones, lo que la hace adecuada para la investigación avanzada. Los equipos la utilizan para automatizar informes, donde su escala maneja conjuntos de datos complejos sin problemas.
4. Llama 2 sin Censura: LLM Versátil de Nivel Básico sin Censura
Llama 2 de Meta sirve como base para esta variante sin censura, ajustada por George Sung para eliminar filtros morales. Con 7-13 mil millones de parámetros, se ejecuta en hardware de consumo, soportando juegos de rol y tareas generales.
Las características incluyen múltiples opciones de cuantificación como GGUF para el equilibrio CPU/GPU. Pros: accesibilidad y plugins de la comunidad; contras: razonamiento más débil que Llama 3.
Ejecútalo a través de Ollama: ollama run llama2-uncensored. Popular con 234K descargas, funciona bien para uso ligero.
Además, su diseño fomenta la experimentación, lo que lo convierte en un elemento básico para los principiantes en IA sin censura.
5. WizardLM sin Censura: Todoterreno Confiable
TheBloke empaqueta WizardLM sin Censura en Llama 2 13B, eliminando alineaciones para amplias aplicaciones. Sobresale en chat y escritura, con capacidades equilibradas.

Aspectos clave: comunidad fuerte, fácil implementación. Pros: previsibilidad; contras: base desactualizada.
Implementa con ollama run wizardlm-uncensored. Acumula 23K descargas, adecuado para flujos de trabajo creativos.
6. Dolphin 2.7 Mixtral 8x7B: Modelo sin Censura Especializado en Codificación
Eric Hartford construye esto sobre el MoE de Mixtral, ajustado para codificación sin filtros. Los parámetros 8x7B aseguran la eficiencia en tareas especializadas.
Características: formatos de cuantificación, alto rendimiento en codificación. Pros: velocidad; contras: necesidades de hardware.
Usa Ollama: ollama run dolphin-mixtral:8x7b. Los puntos de referencia destacan su destreza en programación.
7. GPT-4All: Framework sin Censura Enfocado en Offline
GPT-4All optimiza para ejecuciones locales, basándose en la investigación de transformadores para chats sin censura. El soporte multiplataforma facilita la implementación.
Pros: gratuito, personalizable; contras: límites de contexto.
Instala a través del sitio oficial, ejecuta los ejecutables. Ideal para usuarios preocupados por la privacidad.
8. Falcon LLM: Alternativa sin Censura de Alto Rendimiento
Technology Innovation Institute desarrolla Falcon con una arquitectura innovadora para texto matizado. Optimizado para la velocidad.
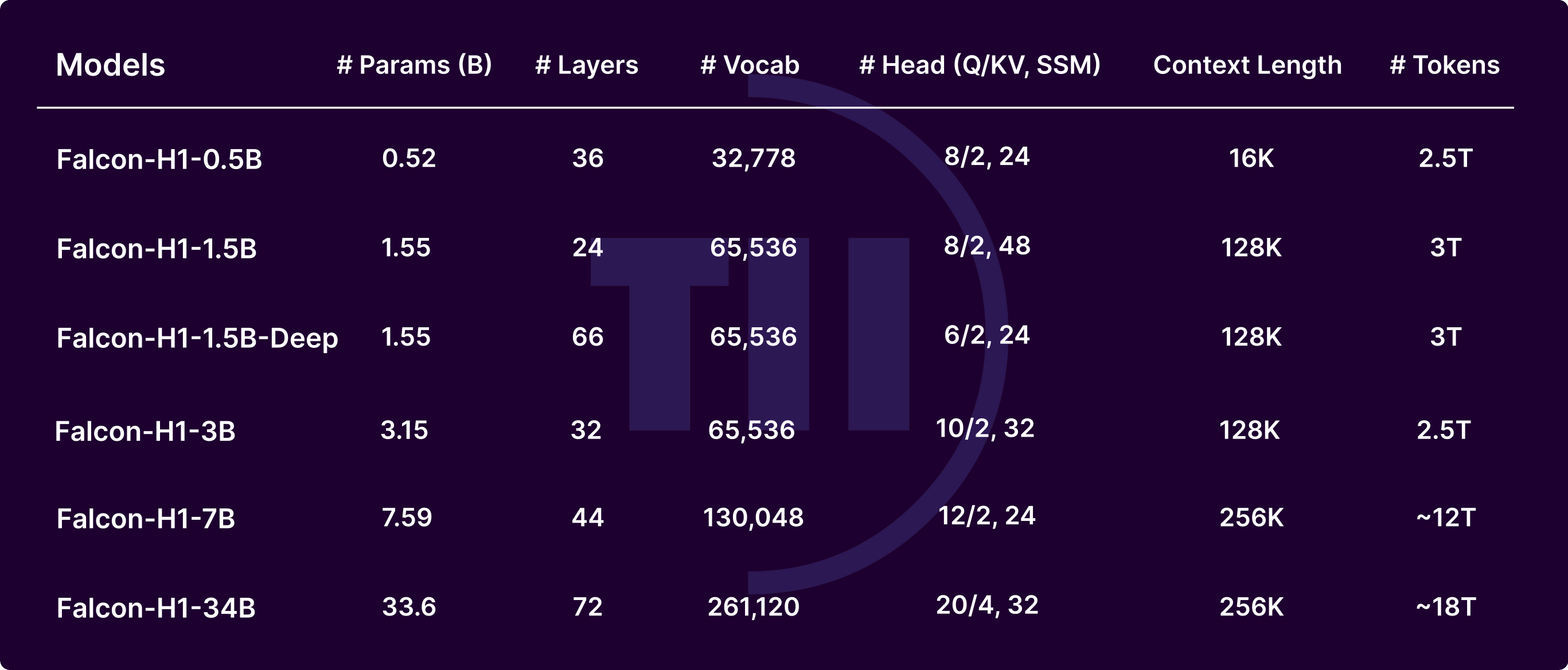
Características: diseño modular. Pros: calidad; contras: madurez del ecosistema.
Carga con la biblioteca Transformers. Adecuado para investigación.
9. MPT-7B Chat: LLM Conversacional sin Censura
MosaicML ajusta MPT-7B para chats, enfatizando la baja latencia. 7B parámetros se adaptan a configuraciones modestas.
Pros: tiempo real; contras: tareas complejas.
Implementa localmente con scripts. Ideal para bots.
10. Vicuna: Modelo sin Censura Optimizado para Diálogos
Vicuna se ajusta en datos conversacionales para interacciones naturales. Diseño ligero.
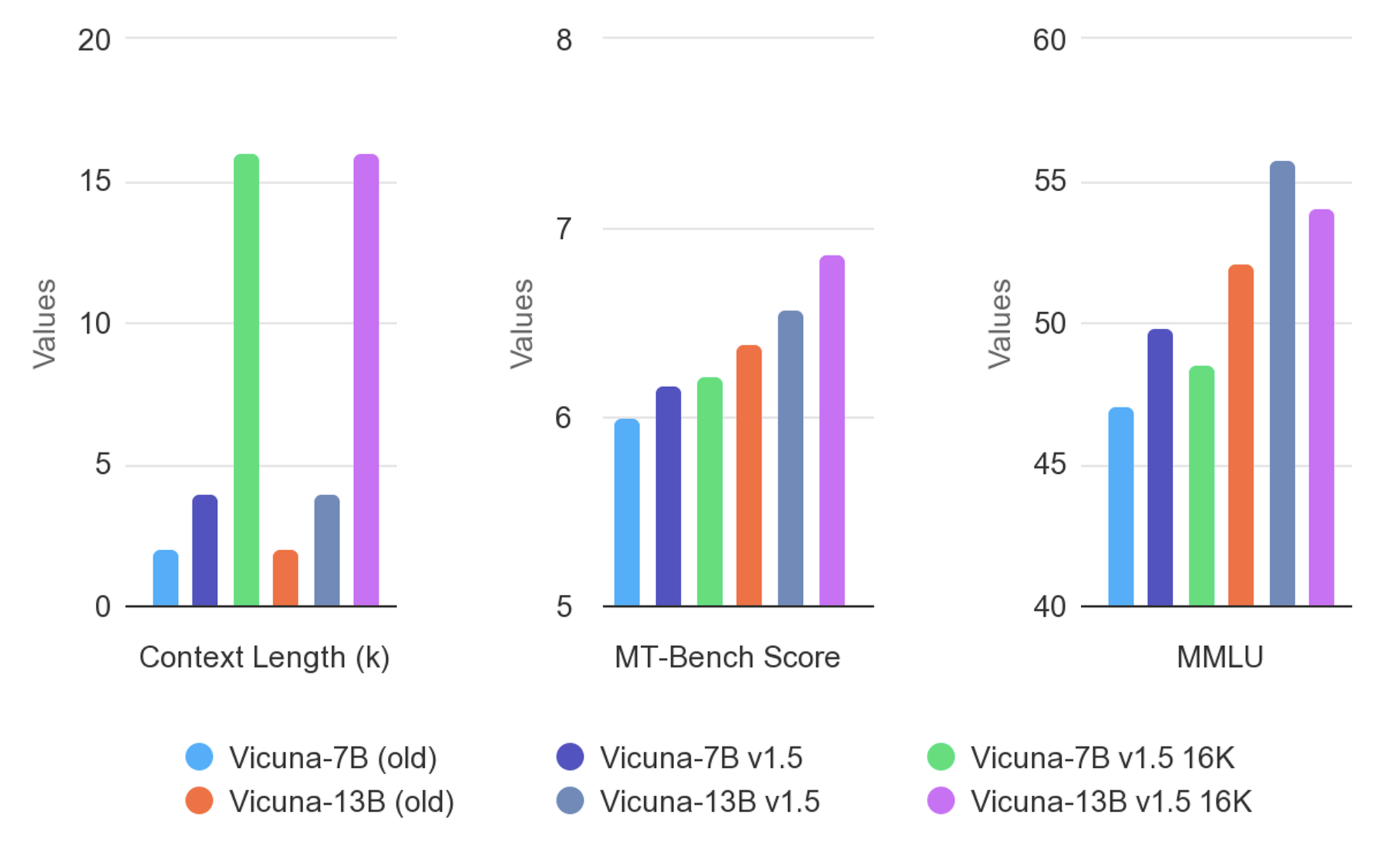
Pros: atractivo; contras: debilidades no conversacionales.
Ejecuta a través de herramientas de la comunidad. Mejora las aplicaciones interactivas.
Mejores Prácticas de Implementación para LLM sin Censura
Los ingenieros optimizan las implementaciones seleccionando niveles de cuantificación, como Q4 o Q8, para adaptarse al hardware. Herramientas como Ollama o LM Studio simplifican las ejecuciones, mientras que las API a través de Apidog permiten la escalabilidad.
Además, monitorea el uso de VRAM y ajusta para dominios específicos. Las medidas de seguridad incluyen el aislamiento de entornos.
Tendencias Futuras en LLM sin Censura
Los innovadores predicen modelos MoE más grandes y mejores técnicas de abliteración. La integración con capacidades multimodales amplía los usos.
Sin embargo, las presiones regulatorias pueden influir en el desarrollo, impulsando enfoques híbridos.
Conclusión
Esta exploración revela cómo los LLM sin restricciones revolucionan las aplicaciones de IA. Desde la precisión de Dolphin 3.0 hasta los diálogos de Vicuna, estos modelos ofrecen una libertad sin igual. Los desarrolladores los aprovechan de manera responsable, utilizando herramientas como Apidog para integraciones fluidas. A medida que avanza la tecnología, estos LLM sin censura continúan impulsando la innovación, transformando los paisajes de investigación y desarrollo.