
En el panorama en rápida evolución de los modelos de lenguaje grandes, Llama Nemotron Ultra 253B de NVIDIA destaca como una potencia para las empresas que buscan capacidades de razonamiento avanzadas. Esta guía completa examina los impresionantes puntos de referencia del modelo, lo compara con otros modelos de código abierto líderes y proporciona pasos claros para implementar su API en sus aplicaciones.
Benchmark de llama-3.1-nemotron-ultra-253b
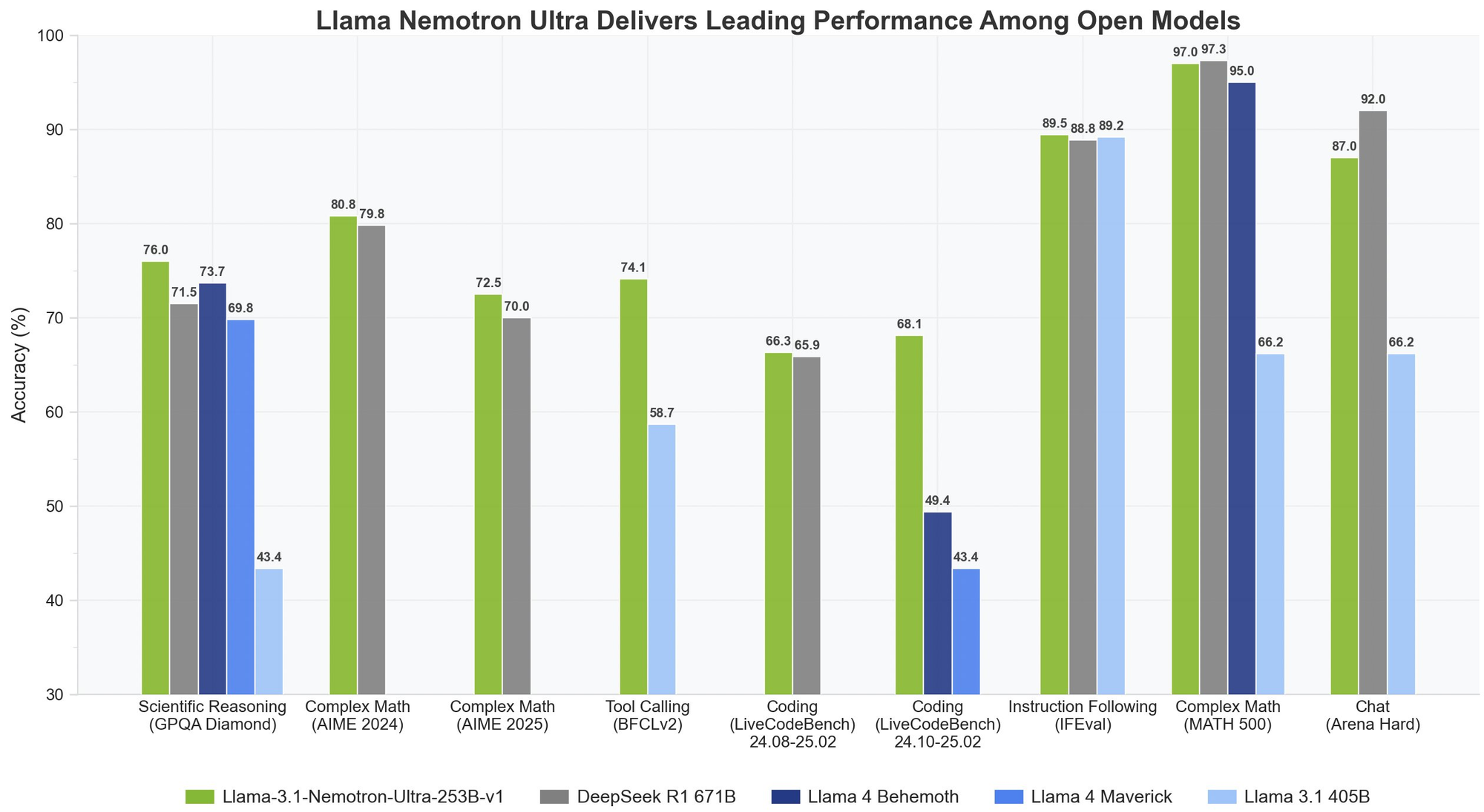
Llama Nemotron Ultra 253B ofrece resultados excepcionales en puntos de referencia críticos de razonamiento y agentic, con su capacidad única de "Razonamiento ON/OFF" que muestra diferencias de rendimiento dramáticas:
Razonamiento Matemático
Llama Nemotron Ultra 253B realmente brilla en tareas de razonamiento matemático:
- MATH500
- Razonamiento OFF: 80.4% pass@1
- Razonamiento ON: 97.0% pass@1
Con un 97% de precisión con Razonamiento ON, Llama Nemotron Ultra 253B casi perfecciona este desafiante benchmark matemático.
- AIME25 (Examen Americano de Invitación a las Matemáticas)
- Razonamiento OFF: 16.7% pass@1
- Razonamiento ON: 72.50% pass@1
Esta notable mejora de 56 puntos demuestra cómo las capacidades de razonamiento de Llama Nemotron Ultra 253B transforman su rendimiento en problemas matemáticos complejos.
Razonamiento Científico
- GPQA (Preguntas y Respuestas de Física de Nivel de Posgrado)
- Razonamiento OFF: 56.6% pass@1
- Razonamiento ON: 76.01% pass@1
La mejora significativa muestra cómo Llama Nemotron Ultra 253B puede abordar problemas de física de nivel de posgrado a través de un análisis metódico cuando se activa el razonamiento.
Programación y Uso de Herramientas
- LiveCodeBench (20240801-20250201)
- Razonamiento OFF: 29.03% pass@1
- Razonamiento ON: 66.31% pass@1
Llama Nemotron Ultra 253B más que duplica su rendimiento de codificación con el razonamiento activado.
- BFCL V2 Live (Llamada de Función)
- Razonamiento OFF: 73.62 score
- Razonamiento ON: 74.10 score
Este benchmark demuestra las sólidas capacidades de uso de herramientas del modelo en ambos modos, lo cual es fundamental para construir agentes de IA eficaces.
Seguimiento de Instrucciones
- IFEval (Evaluación del Seguimiento de Instrucciones)
- Razonamiento OFF: 88.85% de precisión estricta
- Razonamiento ON: 89.45% de precisión estricta
Ambos modos funcionan de manera excelente, lo que demuestra que Llama Nemotron Ultra 253B mantiene sólidas habilidades de seguimiento de instrucciones independientemente del modo de razonamiento.
Llama Nemotron Ultra 253B vs. DeepSeek-R1
DeepSeek-R1 ha sido el estándar de oro para los modelos de razonamiento de código abierto, pero Llama Nemotron Ultra 253B iguala o supera su rendimiento en benchmarks de razonamiento clave:
- En GPQA, Llama Nemotron Ultra 253B alcanza una precisión del 76.01%, compitiendo con el rendimiento de primer nivel de DeepSeek-R1
- Llama Nemotron Ultra 253B ofrece modos de razonamiento duales, a diferencia del enfoque de razonamiento fijo de DeepSeek-R1
- Llama Nemotron Ultra 253B proporciona capacidades superiores de llamada de función, lo que lo hace más versátil para aplicaciones agentic
Llama Nemotron Ultra 253B vs. Llama 4
En comparación con los próximos modelos Llama 4 Behemoth y Maverick:
- Llama Nemotron Ultra 253B demuestra un rendimiento superior en benchmarks de razonamiento matemático complejo y científico
- El interruptor de razonamiento explícito en Llama Nemotron Ultra 253B ofrece más flexibilidad que los modelos Llama 4 estándar
- Llama Nemotron Ultra 253B está específicamente optimizado para hardware NVIDIA, lo que proporciona una mejor eficiencia de inferencia
Probemos Llama Nemotron Ultra 253B a través de la API
La implementación de Llama Nemotron Ultra 253B en sus aplicaciones requiere seguir pasos específicos para garantizar un rendimiento óptimo:
Paso 1: Obtener Acceso a la API
Para acceder a Llama Nemotron Ultra 253B:
- Visite el portal de la API de NVIDIA en https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1
- Regístrese para obtener una clave de API si aún no tiene una
- Si se ejecuta dentro del entorno NGC de NVIDIA, la configuración de la clave de API puede simplificarse
Paso 2: Configure su Entorno de Desarrollo
Antes de realizar llamadas a la API:
- Instale el paquete de Python OpenAI usando
pip install openai - Importe la biblioteca necesaria:
from openai import OpenAI - Configure su entorno para almacenar de forma segura la clave de API
Paso 3: Configure el Cliente de la API
Inicialice el cliente OpenAI con los endpoints de NVIDIA:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "YOUR_API_KEY_HERE"
)

- A diferencia de Postman, Apidog ofrece una experiencia más integrada con documentación de API incorporada, pruebas automatizadas y servidores mock específicamente optimizados para endpoints de modelos de IA.
- La interfaz intuitiva de Apidog facilita la configuración de los conjuntos de parámetros complejos necesarios para las pruebas de API, y sus funciones de visualización de respuestas son particularmente útiles para analizar las salidas de transmisión del modelo.
- Si bien Postman sigue siendo una herramienta popular de prueba de API de propósito general, las funciones centradas en la IA y el flujo de trabajo optimizado de Apidog pueden acelerar significativamente su proceso de desarrollo.

Paso 4: Determine el Modo de Razonamiento Apropiado
Llama Nemotron Ultra 253B ofrece dos modos de operación distintos:
- Razonamiento ON: Mejor para problemas complejos que requieren un pensamiento paso a paso (matemáticas, física, codificación)
- Razonamiento OFF: Óptimo para el seguimiento de instrucciones directas y el chat general
Paso 5: Elabore sus Indicaciones de Sistema y Usuario
Para el modo Razonamiento ON:
- Establezca la indicación del sistema en
"detailed thinking on" - Coloque todas las instrucciones en el mensaje del usuario
- Considere usar plantillas específicas para tareas de benchmark (como problemas de matemáticas)
Para el modo Razonamiento OFF:
- Elimine la indicación del sistema de razonamiento
- Use instrucciones concisas y claras en el mensaje del usuario
Paso 6: Configure los Parámetros de Generación
Para obtener resultados óptimos:
- Razonamiento ON: Establezca temperature=0.6 y top_p=0.95 según lo recomendado por NVIDIA
- Razonamiento OFF: Use la decodificación greedy con temperature=0
- Establezca
max_tokensapropiados según la longitud de respuesta esperada - Considere habilitar la transmisión para respuestas en tiempo real
Paso 7: Realice la Solicitud de la API y Maneje las Respuestas
Cree su solicitud de finalización con todos los parámetros configurados:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "Your prompt here"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
Paso 8: Procese y Muestre la Respuesta
Si usa la transmisión:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Para respuestas sin transmisión, simplemente acceda a completion.choices[0].message.content.
Conclusión
Llama Nemotron Ultra 253B representa un avance significativo en los modelos de razonamiento de código abierto, ofreciendo un rendimiento de vanguardia en una amplia gama de benchmarks. Sus exclusivos modos de razonamiento dual, combinados con capacidades excepcionales de llamada de función y una ventana de contexto masiva, lo convierten en una opción ideal para aplicaciones de IA empresariales que requieren capacidades de razonamiento avanzadas.
Con la guía de implementación de la API paso a paso descrita en este artículo, los desarrolladores pueden aprovechar todo el potencial de Llama Nemotron Ultra 253B para construir sistemas de IA sofisticados que aborden problemas complejos con un razonamiento similar al humano. Ya sea que se construyan agentes de IA, se mejoren los sistemas RAG o se desarrollen aplicaciones especializadas, Llama Nemotron Ultra 253B proporciona una base poderosa para las capacidades de IA de próxima generación en un paquete de código abierto y comercialmente amigable.


