
El mundo de los modelos de lenguaje grandes (LLM) avanza a una velocidad vertiginosa, pero persisten los desafíos en eficiencia y adaptabilidad en tiempo real. El 10 de septiembre de 2025, Moonshot AI, la fuerza innovadora detrás de la serie Kimi, lanzó checkpoint-engine, un middleware de código abierto que redefine las actualizaciones de peso en los motores de inferencia de LLM. Diseñada para el aprendizaje por refuerzo (RL), esta herramienta ligera puede actualizar un gigante de 1 billón de parámetros como Kimi-K2 en miles de GPU en solo 20 segundos, reduciendo el tiempo de inactividad e impulsando la escalabilidad.
Este artículo profundiza en la mecánica de checkpoint-engine, desde su arquitectura hasta sus puntos de referencia, mientras destaca sus implicaciones para el RL y su encaje en el ecosistema más amplio. Al hacer de esta joya de código abierto, Moonshot AI empodera a la comunidad para llevar más allá los límites de los LLM. Desempaquemos esta innovación capa por capa.
Comprendiendo Checkpoint-Engine: Conceptos Centrales y Arquitectura
¿Qué es Checkpoint-Engine?
En esencia, checkpoint-engine es un middleware que facilita actualizaciones de peso en el lugar y sin interrupciones para los LLM durante la inferencia. Esto es fundamental en el RL, donde los modelos evolucionan a través de retroalimentación iterativa sin reentrenamientos completos. Los métodos tradicionales ralentizan los sistemas con recargas prolongadas; checkpoint-engine contrarresta esto con un enfoque simplificado y de baja sobrecarga.
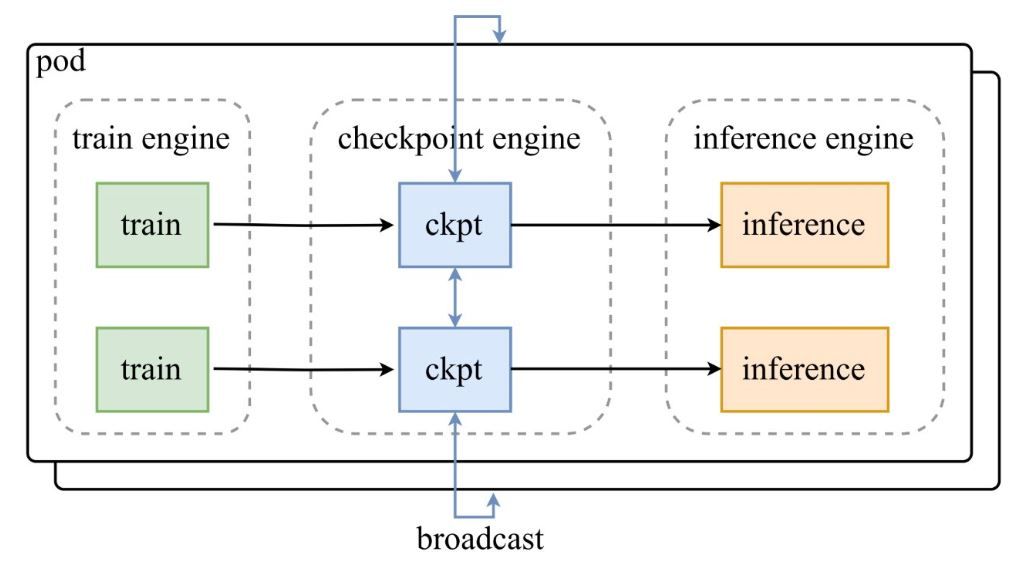
Como se muestra en el diagrama de arquitectura del anuncio de Moonshot AI en Twitter, un pod de motores de entrenamiento alimenta puntos de control al checkpoint-engine central, que luego transmite las actualizaciones a los motores de inferencia. El repositorio de GitHub profundiza en el código, destacando la clase ParameterServer como el orquestador de actualizaciones.
Componentes Arquitectónicos
- Motor de Entrenamiento: Produce nuevos pesos a partir del entrenamiento continuo de RL, capturando refinamientos de políticas en entornos dinámicos.
- Checkpoint Engine: El núcleo del middleware, ubicado junto a la inferencia para una latencia mínima. Maneja la recopilación de metadatos y ejecuta actualizaciones a través de los modos Broadcast o P2P.
- Motor de Inferencia: Integra actualizaciones sobre la marcha, manteniendo la continuidad del servicio en clústeres de GPU distribuidos.
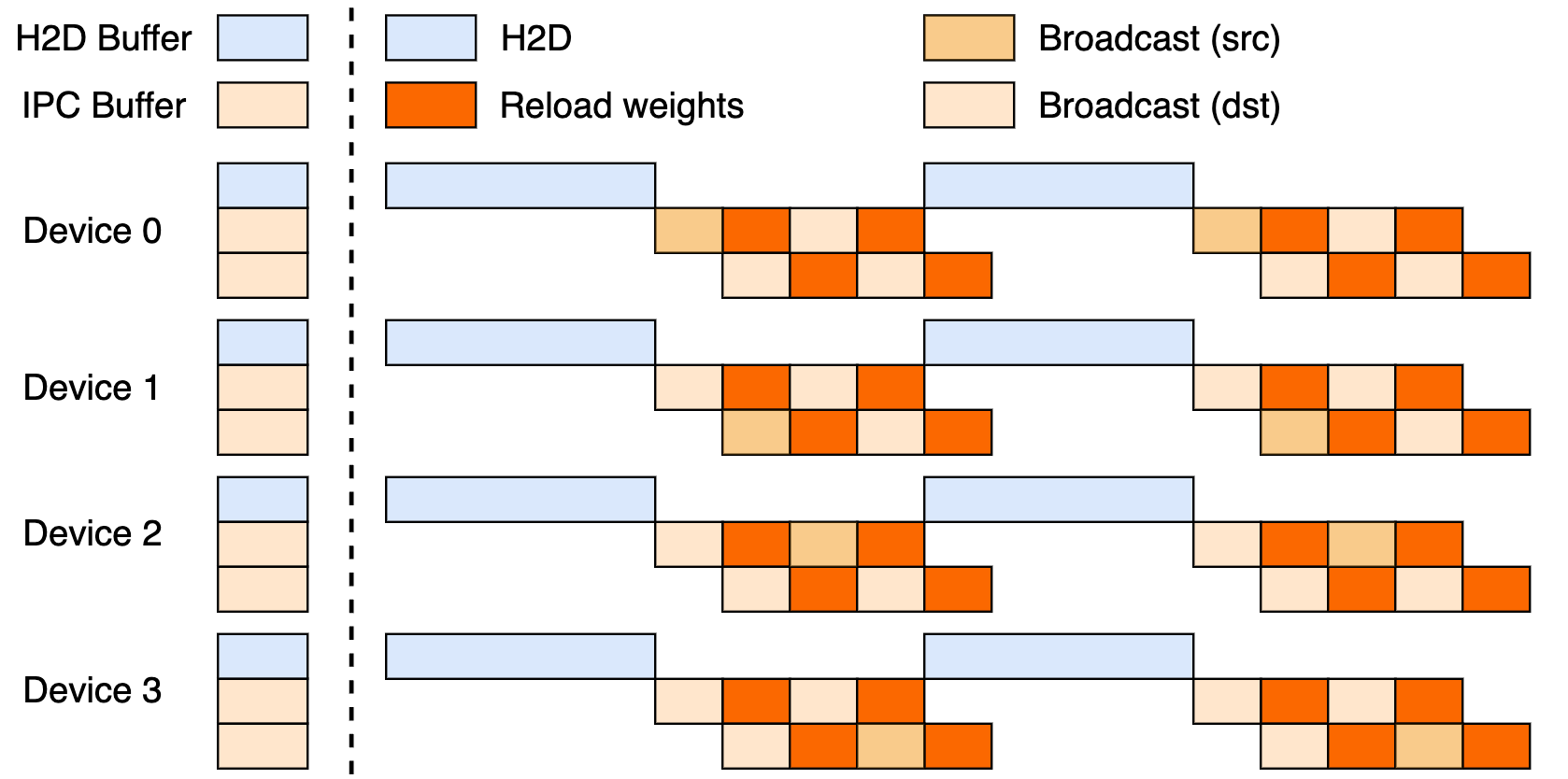
Esta configuración aprovecha una tubería de tres etapas: transferencias Host-a-Dispositivo (H2D), transmisiones entre trabajadores utilizando CUDA IPC y recargas dirigidas. Al superponer estas, maximiza la utilización de la GPU y frena los cuellos de botella de transferencia.
Actualizaciones Broadcast vs. P2P
Broadcast destaca en actualizaciones sincrónicas y a nivel de clúster, su modo predeterminado para máxima velocidad, agrupando datos para un flujo óptimo. P2P, mientras tanto, sobresale en escenarios elásticos, como escalar durante picos, utilizando RDMA a través de mooncake-transfer-engine para evitar interrupciones. Esta dualidad hace que checkpoint-engine sea versátil tanto para implementaciones estables como fluidas.
Puntos de Referencia de Rendimiento: ¿Qué tan Rápido es Suficientemente Rápido?
Actualizando un Modelo de un Billón de Parámetros en 20 Segundos
¿La característica principal de Checkpoint-engine? Actualizar los 1T parámetros de Kimi-K2 en miles de GPU en ~20 segundos. Esto se debe a una tubería inteligente: la planificación de metadatos establece tamaños de cubo eficientes, los sockets ZeroMQ coordinan las transferencias y las etapas H2D/broadcast superpuestas ocultan las latencias.
Contraste esto con las técnicas heredadas, que podrían mantener los sistemas inactivos durante minutos en medio de movimientos masivos de datos. El ethos en el lugar de Checkpoint-engine mantiene la inferencia funcionando, ideal para la necesidad de adaptaciones rápidas del RL.
Análisis de Puntos de Referencia
La tabla de puntos de referencia revela resultados estelares en modelos y configuraciones, probados con vLLM v0.10.2rc1:
| Modelo | Información del Dispositivo | RecopilarMetas | Actualizar (Broadcast) | Actualizar (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
Replique estos a través de examples/update.py del repositorio. Las ejecuciones FP8 necesitan parches de vLLM, lo que subraya la eficiencia a escala.
Implicaciones para el Aprendizaje por Refuerzo
El RL prospera con iteraciones rápidas; los ciclos de menos de 20 segundos de checkpoint-engine permiten bucles de aprendizaje continuos, superando los métodos por lotes. Esto desbloquea aplicaciones responsivas, desde agentes adaptativos hasta chatbots en evolución, donde cada segundo cuenta en el ajuste de políticas.
Implementación Técnica: Sumergiéndonos en la Base de Código
Accesibilidad de Código Abierto
El lanzamiento de GitHub de Moonshot AI democratiza las herramientas de RL de élite. El ParameterServer ancla las actualizaciones, ofreciendo Broadcast (compartición rápida de CUDA IPC) y P2P (RDMA para los recién llegados). Ejemplos como update.py y las pruebas (test_update.py) facilitan la incorporación.
La compatibilidad comienza con vLLM (a través de extensiones de trabajador), con planes para SGLang a continuación. La tubería parcial de tres etapas insinúa un potencial sin explotar.
Técnicas de Optimización
Las claves inteligentes incluyen:
- Superposiciones en Tubería: La comunicación y las copias se ejecutan concurrentemente, reduciendo el tiempo efectivo.
- Optimización de Cubos: El dimensionamiento basado en metadatos se ajusta a la fragmentación y las redes.
- Control ZeroMQ: Señalización de baja latencia a los motores de inferencia.
Estos abordan los obstáculos de los billones de parámetros, desde conflictos de PCIe hasta apreturas de memoria (recurriendo a serial si es necesario).
Limitaciones Actuales
El embudo de rango 0 de P2P puede ahogarse a escala, y la tubería completa espera pulido. El enfoque en vLLM limita el alcance, pero los parches cierran las brechas de FP8 para modelos como DeepSeek-V3.1. Esté atento al repositorio para evoluciones.
Integración con Marcos Existentes: vLLM y Más Allá
Colaboración con vLLM
Checkpoint-engine se empareja de forma nativa con PagedAttention de vLLM para una inferencia de RL fluida. Este dúo logra sincronizaciones de 20 segundos en modelos de 1T, como se insinuó en las actualizaciones de vLLM, un guiño a la colaboración abierta que amplifica el rendimiento.
Extensiones Potenciales a Claude y Apidog
La extensión a Claude de Anthropic podría infundir dinamismo de RL en sus chats centrados en la seguridad, permitiendo ajustes en vivo. Apidog encaja perfectamente para la simulación de puntos finales durante los ajustes de ZeroMQ: descargue Apidog gratis para prototipar estos puentes sin esfuerzo.
Impacto en el Ecosistema Más Amplio
La conexión a Ollama o LM Studio podría localizar el poder de los billones de parámetros, igualando el campo para los desarrolladores independientes. Este efecto dominó fomenta un panorama de IA más inclusivo.
Perspectivas Futuras: ¿Qué le Espera a Checkpoint-Engine?
Mejoras de Escalabilidad y Rendimiento
El despliegue completo de la tubería podría reducir aún más los segundos, mientras que la descentralización de P2P elimina los cuellos de botella para una verdadera elasticidad. Los ajustes de RDMA prometen una destreza nativa en la nube.
Contribuciones de la Comunidad
El código abierto invita a correcciones y puertos, piense en fusiones de SGLang o modos agnósticos de PCIe. Las primeras respuestas en el tweet zumban de emoción, impulsando el impulso.
Aplicaciones Industriales
Desde la traducción en tiempo real hasta el RL de conducción autónoma, checkpoint-engine se adapta a dominios con mucha fluctuación. Su velocidad mantiene los modelos frescos, superando a los rivales en agilidad.
¿Una Nueva Era para la Inferencia de LLM?
Checkpoint-engine anuncia futuros ágiles de LLM, abordando los problemas de peso con un toque de código abierto. Esa actualización de 1T en 20 segundos, respaldada por una arquitectura y puntos de referencia inteligentes, consolida su trono en el RL, a pesar de las limitaciones.
Combínelo con Apidog para flujos de desarrollo o Claude para inteligencias híbridas, y la innovación se dispara. ¡Siga GitHub, obtenga Apidog gratis y únase a la revolución que está remodelando la inferencia hoy!