
Los desarrolladores buscan constantemente formas eficientes de integrar modelos avanzados de IA en sus aplicaciones, y Qwen Next surge como una opción atractiva. Este modelo, parte de la serie Qwen de Alibaba, ofrece una arquitectura dispersa de Mezcla de Expertos (MoE) que activa solo una fracción de sus parámetros durante la inferencia. Como resultado, se logran tiempos de procesamiento más rápidos y menores costos sin sacrificar el rendimiento.
Comprendiendo la Arquitectura Central de Qwen Next y Por Qué es Importante para los Usuarios de API
La arquitectura híbrida de Qwen Next combina mecanismos de compuerta con normalización avanzada, optimizándola para tareas impulsadas por API. Su capa MoE enruta las entradas a 10 de 512 expertos especializados por token, más un experto compartido, activando solo 3 mil millones de parámetros. Esta dispersión reduce las demandas de recursos, permitiendo una inferencia más rápida para los usuarios de la API de Qwen.

Además, el modelo emplea atención de producto punto escalado con incrustaciones de posición rotatoria parcial (RoPE), preservando el contexto en secuencias de hasta 128K tokens. Las capas RMSNorm centradas en cero estabilizan los gradientes, asegurando salidas fiables durante las llamadas a la API de alto volumen. La ruta DeltaNet, con un factor de expansión de 3x, utiliza normalización L2, capas convolucionales y activaciones SiLU para soportar la decodificación especulativa, generando múltiples tokens simultáneamente.
Para los desarrolladores, esto significa que la Integración Siguiente en aplicaciones como herramientas de análisis de documentos es eficiente y escalable. La modularidad de la arquitectura permite un ajuste fino para dominios como las finanzas, haciéndola adaptable a través de la API de Qwen. A continuación, examinemos cómo estas características se traducen en un rendimiento medible.
Evaluando los Puntos de Referencia de Rendimiento para Qwen Next en Aplicaciones Impulsadas por API
Los desarrolladores que integran Qwen Next en flujos de trabajo impulsados por API priorizan modelos que equilibran alto rendimiento con eficiencia computacional. Qwen3-Next-80B-A3B, con su arquitectura dispersa de Mezcla de Expertos (MoE) que activa solo 3 mil millones de parámetros durante la inferencia, sobresale en este dominio. Esta sección evalúa los puntos de referencia clave, destacando cómo Qwen Next supera a sus contrapartes más densas como Qwen3-32B, al tiempo que ofrece velocidades de inferencia superiores, algo crítico para las respuestas de API en tiempo real. Al examinar las métricas en tareas de conocimiento general, codificación, razonamiento y contexto largo, se obtienen conocimientos sobre su idoneidad para aplicaciones escalables.
Eficiencia del Pre-entrenamiento y Rendimiento del Modelo Base
El pre-entrenamiento de Qwen Next demuestra una eficiencia notable. Entrenado en un subconjunto de 15 billones de tokens del corpus de 36 billones de tokens de Qwen3, el modelo base Qwen3-Next-80B-A3B consume menos del 80% de las horas de GPU requeridas por Qwen3-30B-A3B y solo el 9.3% del costo computacional de Qwen3-32B. A pesar de esto, activa solo una décima parte de los parámetros no incrustados utilizados por Qwen3-32B-Base, pero lo supera en la mayoría de los puntos de referencia estándar y rinde significativamente mejor que Qwen3-30B-A3B.
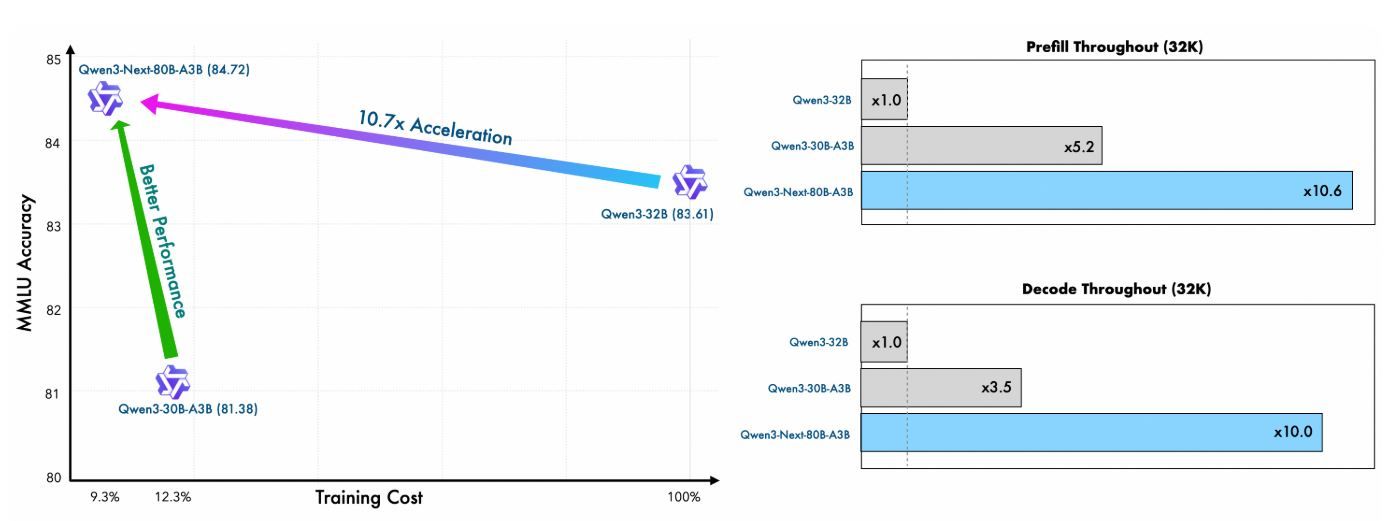
Esta eficiencia se debe a la arquitectura híbrida —que combina Gated DeltaNet (75% de las capas) con Gated Attention (25%)— la cual optimiza tanto la estabilidad del entrenamiento como el rendimiento de la inferencia. Para los usuarios de API, esto se traduce en menores costos de implementación y una prototipación más rápida, ya que el modelo logra una mejor perplejidad y reducción de pérdidas con menos recursos.
Métrica | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Qwen3-30B-A3B-Base |
|---|---|---|---|
Horas de GPU de Entrenamiento (% de Qwen3-32B) | 9.3% | 100% | ~125% |
Ratio de Parámetros Activos | 10% | 100% | 10% |
Superación en Benchmarks | Supera en la mayoría | Base | Significativamente mejor |
Estas cifras subrayan el valor de Qwen Next en entornos de API con recursos limitados, donde el entrenamiento de variantes personalizadas mediante el ajuste fino sigue siendo factible.
Velocidad de Inferencia: Etapas de Relleno y Decodificación para la Latencia de la API
La velocidad de inferencia impacta directamente los tiempos de respuesta de la API, particularmente en escenarios de alto rendimiento como servicios de chat o generación de contenido. Qwen Next destaca aquí, aprovechando su MoE ultra-disperso (512 expertos, enrutando 10 + 1 compartido) y la Predicción Multi-Token (MTP) para la decodificación especulativa.
En la etapa de relleno (procesamiento de prompts), Qwen Next logra un rendimiento casi 7 veces mayor que Qwen3-32B con longitudes de contexto de 4K. Más allá de los 32K tokens, esta ventaja supera las 10 veces, lo que lo hace ideal para APIs de análisis de documentos largos.
Para la etapa de decodificación (generación de tokens), el rendimiento alcanza casi 4 veces en contextos de 4K y más de 10 veces en longitudes mayores. El mecanismo MTP, optimizado para la consistencia multi-paso, aumenta las tasas de aceptación en la decodificación especulativa, acelerando aún más la inferencia en el mundo real.
Longitud del Contexto | Rendimiento de Relleno (vs. Qwen3-32B) | Rendimiento de Decodificación (vs. Qwen3-32B) |
|---|---|---|
4K Tokens | 7 veces más rápido | 4 veces más rápido |
>32K Tokens | >10 veces más rápido | >10 veces más rápido |
Los desarrolladores de API se benefician enormemente: la latencia reducida permite respuestas en menos de un segundo en producción, mientras que la eficiencia energética (al activar solo el 3.7% de los parámetros) reduce los costos de la nube. Frameworks como vLLM y SGLang amplifican estas ganancias, soportando hasta 256K contextos con paralelismo tensorial.
Realizando Tu Primera Llamada a la API con Qwen Next: Una Implementación Paso a Paso
Para aprovechar las capacidades de Qwen Next, sigue estos pasos claros y accionables para configurar y ejecutar llamadas a la API de Qwen a través de la plataforma DashScope de Alibaba. Esta guía asegura que puedas integrar el modelo de manera eficiente, ya sea para consultas simples o escenarios complejos de Integración Siguiente.
Paso 1: Crear una Cuenta de Alibaba Cloud y Acceder a Model Studio
Comienza registrándote para obtener una cuenta de Alibaba Cloud en alibabacloud.com. Después de verificar tu cuenta, navega a la consola de Model Studio dentro de la plataforma DashScope. Selecciona Qwen3-Next-80B-A3B de la lista de modelos, eligiendo la variante base, instruct o thinking según tu caso de uso, por ejemplo, instruct para tareas conversacionales o thinking para razonamiento complejo.
Paso 2: Generar y Proteger Tu Clave API
En el panel de DashScope, localiza la sección "API Keys" y genera una nueva clave. Esta clave autentica tus solicitudes a la API de Qwen. Ten en cuenta los límites de tasa: el nivel gratuito ofrece 1 millón de tokens mensuales, suficiente para las pruebas iniciales. Almacena la clave de forma segura en una variable de entorno para evitar su exposición:
bash
export DASHSCOPE_API_KEY='your_key_here'Esta práctica mantiene tu código portable y seguro.
Paso 3: Instalar el SDK de Python de DashScope
Instala el SDK de DashScope para simplificar las interacciones con la API de Qwen. Ejecuta el siguiente comando en tu terminal:
bash
pip install dashscopeEl SDK maneja la serialización, los reintentos y el análisis de errores, agilizando tu proceso de integración. Alternativamente, usa clientes HTTP como `requests` para configuraciones personalizadas, pero el SDK es recomendado por su facilidad.
Paso 4: Configurar el Punto Final de la API
Para clientes compatibles con OpenAI, establece la URL base en:
text
https://dashscope.aliyuncs.com/compatible-mode/v1Para llamadas nativas de DashScope, usa:
text
https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generationIncluye tu clave API en el encabezado de la solicitud como X-DashScope-API-Key. Esta configuración asegura un enrutamiento adecuado a Qwen Next.
Paso 5: Realizar Tu Primera Llamada a la API
Crea una solicitud de generación básica utilizando la variante `instruct`. A continuación, se muestra un script de Python para consultar Qwen Next:
python
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")Este script envía un prompt, limita la salida a 200 tokens y controla la creatividad con `temperature=0.7`. Un código de estado 200 indica éxito; de lo contrario, maneja errores como límites de cuota (código 10402).
Paso 6: Implementar Streaming para Respuestas en Tiempo Real
Para aplicaciones que requieren retroalimentación inmediata, usa streaming:
python
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
breakEsto entrega salida token por token, perfecto para interfaces de chat en vivo en Integración Siguiente.
Paso 7: Añadir Llamadas a Funciones para Flujos de Trabajo Agénticos
Extiende la funcionalidad con la integración de herramientas. Define un esquema JSON para una herramienta, como la recuperación del clima:
python
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)La API de Qwen analiza el prompt, activando la llamada a la herramienta. Ejecuta la función externamente y devuelve los resultados.
Paso 8: Probar y Validar con Apidog
Usa Apidog para probar tus llamadas a la API. Importa el esquema de DashScope a un nuevo proyecto de Apidog, añade el punto final e incluye tu clave API en el encabezado. Crea un cuerpo JSON con tu prompt, luego ejecuta casos de prueba para verificar las respuestas. Apidog genera métricas como la latencia y sugiere casos extremos, mejorando la fiabilidad.
Paso 9: Monitorear y Depurar Respuestas
Verifica los códigos de respuesta para detectar errores (por ejemplo, 429 para límites de tasa). Registra las salidas anonimizadas para auditoría. Usa los paneles de control de Apidog para rastrear el uso de tokens y los tiempos de respuesta, asegurando que tus llamadas a la API de Qwen se mantengan dentro de las cuotas.
Estos pasos proporcionan una base sólida para integrar Qwen Next. A continuación, optimiza tus pruebas con Apidog.
Aprovechando las Llamadas a Funciones en la API de Qwen Next para Flujos de Trabajo Agénticos
Las llamadas a funciones extienden la utilidad de Qwen Next más allá de la generación de texto. Define herramientas en un esquema JSON, especificando nombres, descripciones y parámetros. Para consultas meteorológicas, describe una función get_weather con un parámetro city.
En tu llamada a la API, incluye el array de herramientas y establece tool_choice en 'auto'. El modelo analiza el prompt, identificando intenciones y devolviendo llamadas a herramientas. Ejecuta la función externamente, alimentando los resultados de vuelta para las respuestas finales.
Este patrón crea sistemas agénticos, donde Qwen Next orquesta múltiples herramientas. Por ejemplo, combina datos meteorológicos con análisis de sentimientos para recomendaciones personalizadas. La API de Qwen maneja el análisis de manera eficiente, reduciendo la necesidad de código personalizado.
Optimiza validando estrictamente los esquemas. Asegúrate de que los parámetros coincidan con los tipos esperados para evitar errores en tiempo de ejecución. A medida que integres, prueba estas llamadas a fondo; herramientas como Apidog resultan invaluables aquí, simulando respuestas sin realizar llamadas a la API en vivo.
Integrando Apidog para una Prueba y Documentación Eficiente de la API de Qwen
Esta guía proporciona un flujo de trabajo completo para integrar Apidog con la API de Qwen (Qwen Next/3.0 de Alibaba Cloud) para pruebas, documentación y gestión del ciclo de vida de la API eficientes.
Fase 1: Configuración Inicial y de Cuenta
Paso 1: Configuración de la Cuenta
1.1 Crear Cuentas Requeridas
1. Cuenta de Alibaba Cloud
2. Visita: https://www.alibabacloud.com
3. Regístrate y completa la verificación
4. Habilita el servicio "Model Studio"
5. Cuenta de Apidog
6. Visita: https://apidog.com
7. Regístrate con correo electrónico/Google/GitHub
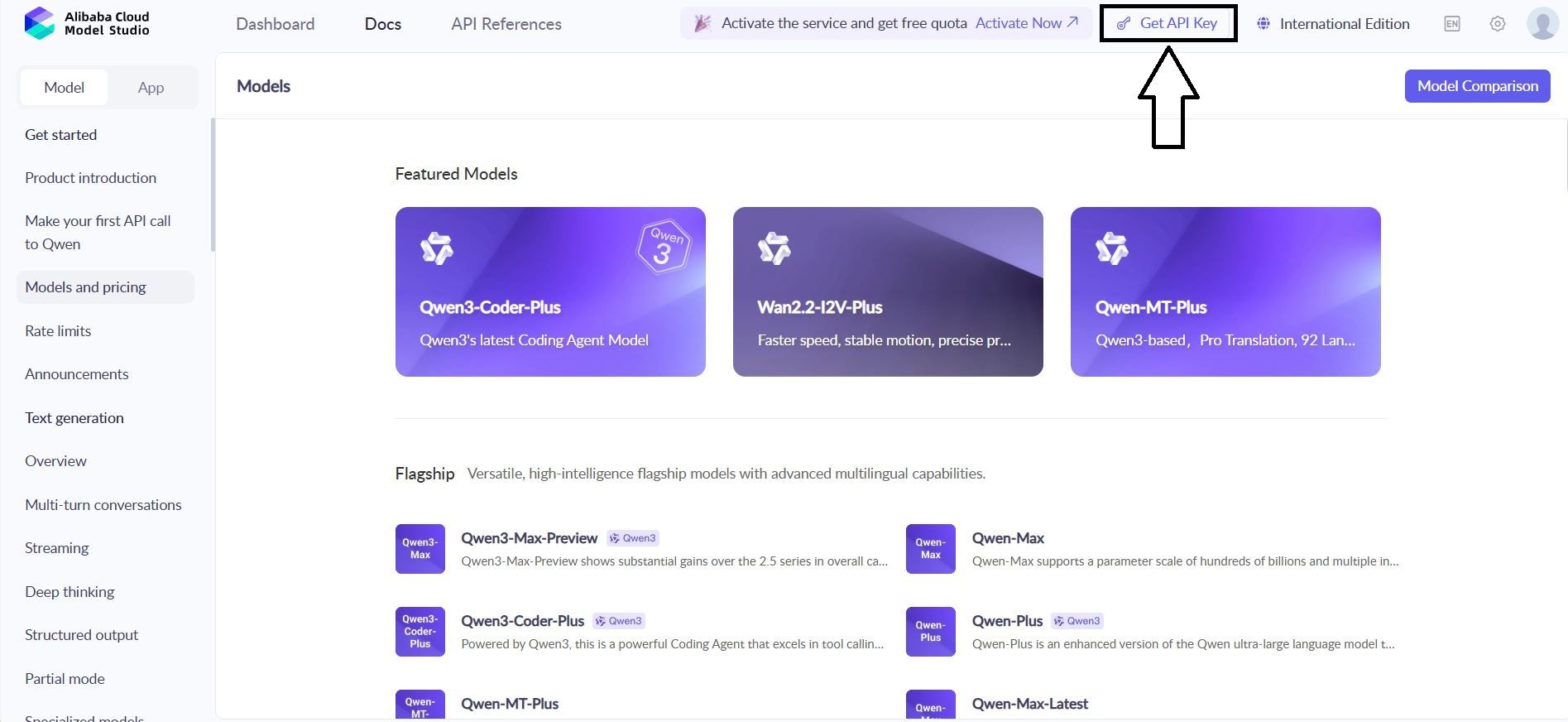
1.2 Obtener Credenciales de la API de Qwen
1. Navega a: Consola de Alibaba Cloud → Model Studio → API Keys
2. Crea una nueva clave: qwen-testing-key
3. Guarda tu clave: sk-[tu-clave-real-aquí]

1.3 Crear Proyecto Apidog
- Inicia sesión en Apidog → Haz clic en "Nuevo Proyecto"
2. Configurar Proyecto:
1. Nombre del Proyecto: Integración de la API de Qwen
2. Descripción: Pruebas y documentación de la API de Qwen Next
Fase 2: Importación y Configuración de la API
Paso 2: Importar Especificaciones de la API de Qwen
Método A: Creación Manual de la API
- Añadir Nueva API → "Crear API Manualmente"
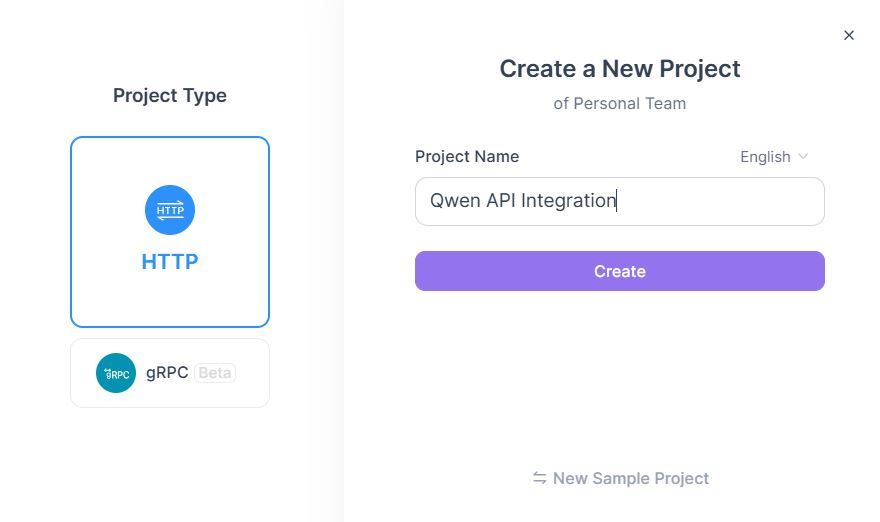
- Configurar el Punto Final de Chat de Qwen:

3. Establecer Configuración de Solicitud:
Método B: Importación de OpenAPI
- Descarga la especificación OpenAPI de Qwen (si está disponible)
- Ve a Proyecto → "Importar" → "OpenAPI/Swagger"
- Sube el archivo de especificación → "Importar"
Fase 3: Configuración del Entorno y Autenticación
Paso 3: Configurar Entornos
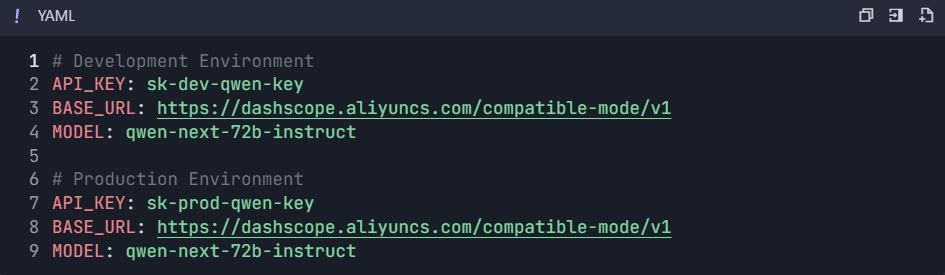
3.1 Crear Variables de Entorno
- Ve a Configuración del Proyecto → "Entornos"
- Crear entornos:
Fase 4: Suite de Pruebas Completa
Paso 4: Crear Escenarios de Prueba
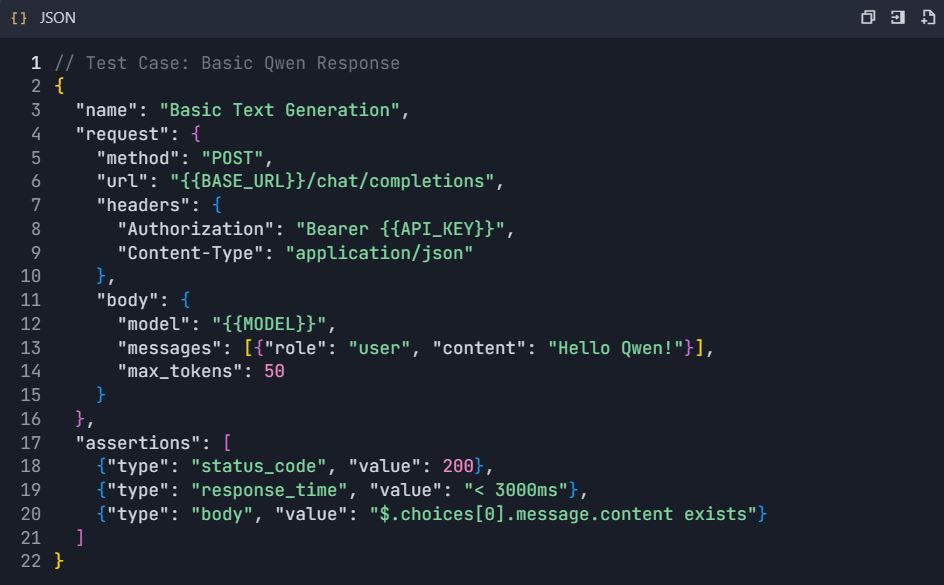
4.1 Prueba Básica de Generación de Texto
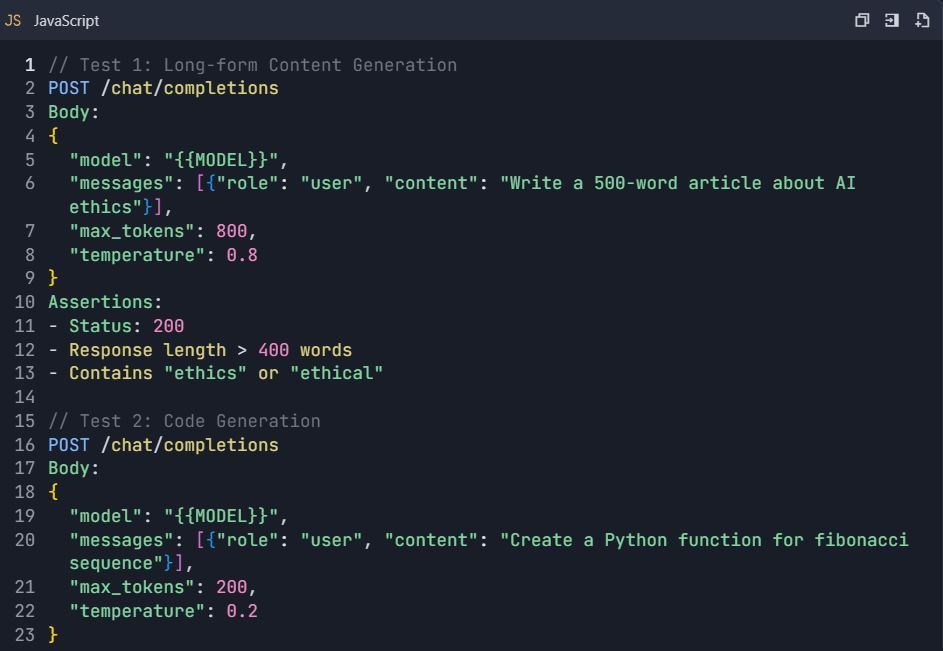
4.2 Escenarios de Prueba Avanzados
Suite de Pruebas: Pruebas Completas de la API de Qwen
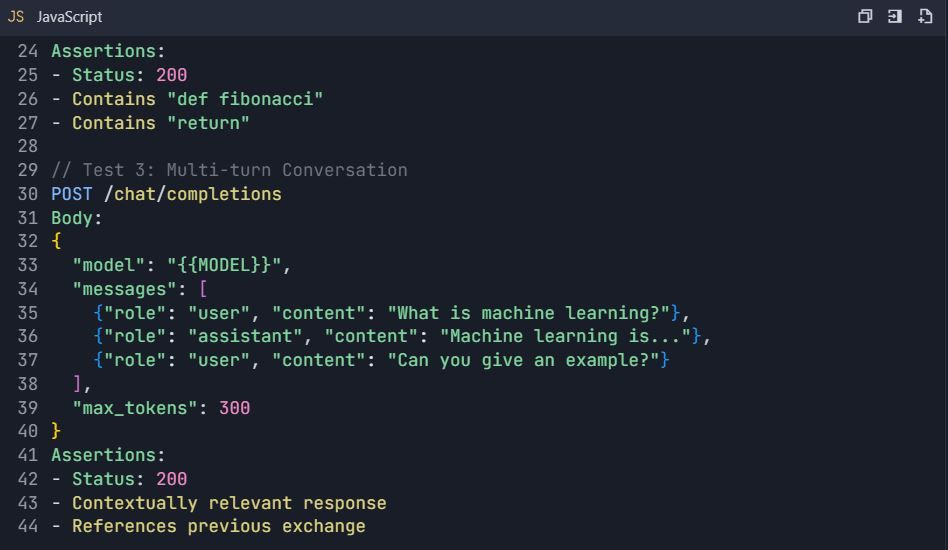
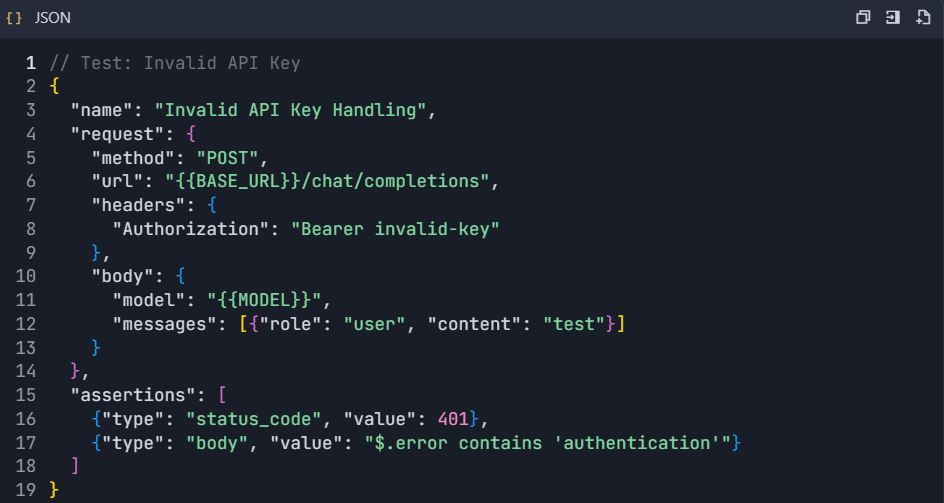
4.3 Pruebas de Manejo de Errores
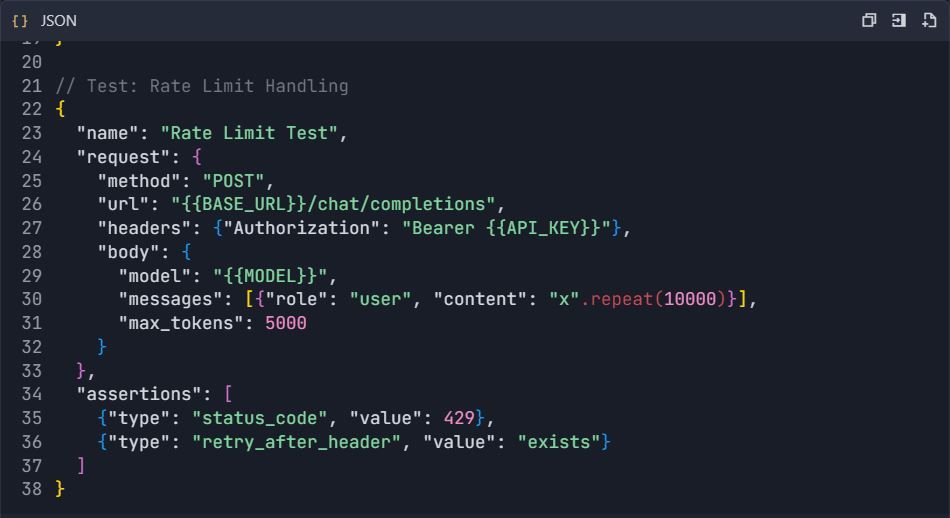
Fase 5: Generación de Documentación
Paso 5: Generar Automáticamente Documentación de API 5.1 Crear Estructura de Documentación
- Ve a Proyecto → "Documentación"
- Crear secciones:
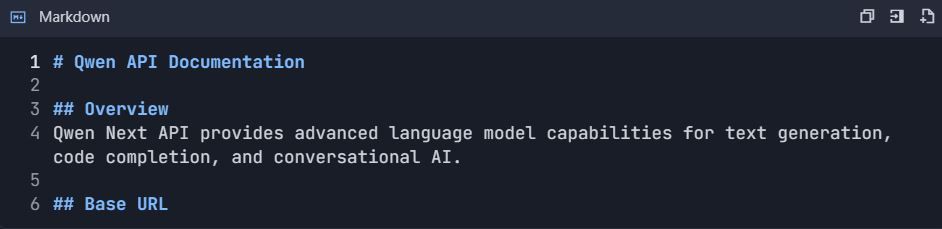
https://dashscope.aliyuncs.com/compatible-mode/v1

Autorización: Bearer sk-[tu-clave-api]

5.2 Explorador de API Interactivo
- Configurar ejemplos interactivos:
Fase 6: Funciones Avanzadas y Automatización
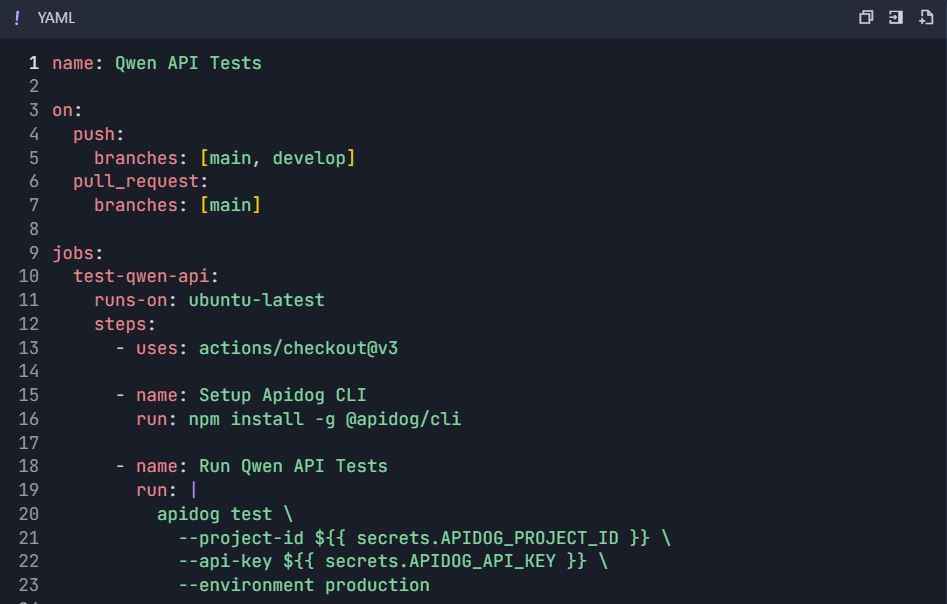
Paso 6: Flujos de Trabajo de Pruebas Automatizadas 6.1 Integración CI/CD
Flujo de Trabajo de GitHub Actions ( .github/workflows/qwen-tests.yml ):
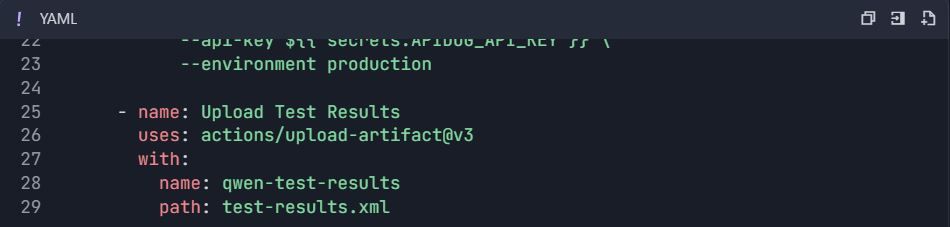
6.2 Pruebas de Rendimiento
- Crear suite de pruebas de rendimiento:

2. Monitorear métricas:
- Tiempo de respuesta (p50, p95, p99)
- Rendimiento (solicitudes/segundo)
- Tasa de error
- Eficiencia del uso de tokens
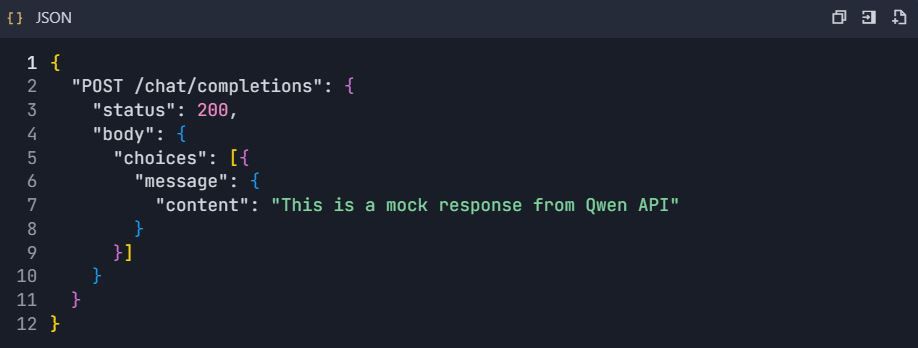
6.3 Configuración del Servidor Mock
- Habilitar servidor mock:

2. Configurar respuestas mock:
Fase 7: Monitoreo y Análisis
Paso 7: Panel de Análisis de Uso
7.1 Métricas Clave a Rastrear
- Estadísticas de Uso de la API:
- Conteo de solicitudes por punto final
- Consumo de tokens
- Tendencias del tiempo de respuesta
- Análisis de la tasa de error
2. Monitoreo de Costos:
- Uso diario de tokens
- Costo estimado por solicitud
- Alertas de presupuesto
7.2 Configuración de Panel Personalizado
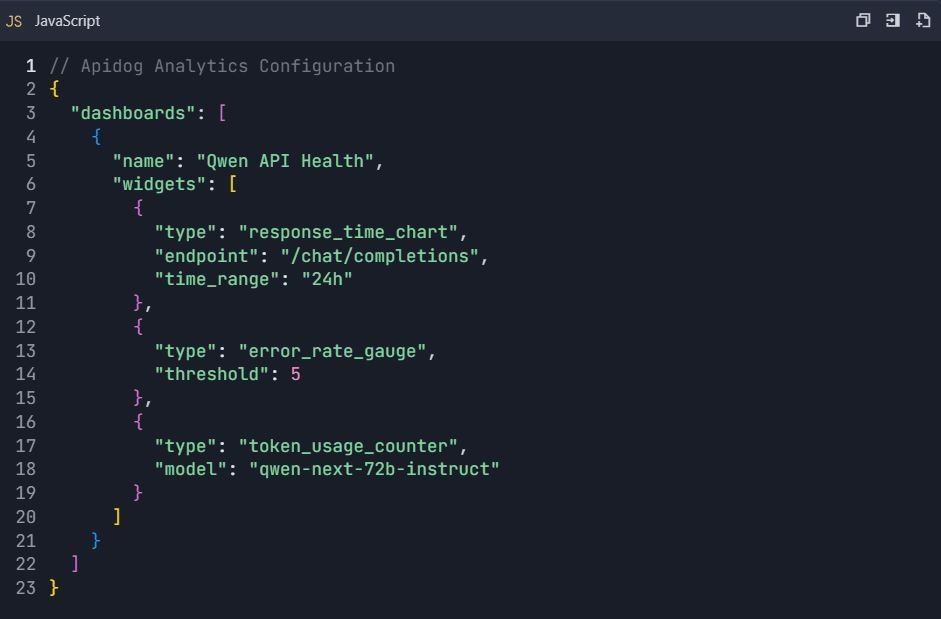
Fase 8: Colaboración en Equipo y Control de Versiones
Paso 8: Configuración del Flujo de Trabajo en Equipo
8.1 Configuración de Roles de Equipo

8.2 Integración de Control de Versiones
- Conectar a repositorio Git:

2. Estrategia de Ramificación:

Ejemplo Completo de Flujo de Trabajo de Pruebas
Escenario de Pruebas de Extremo a Extremo
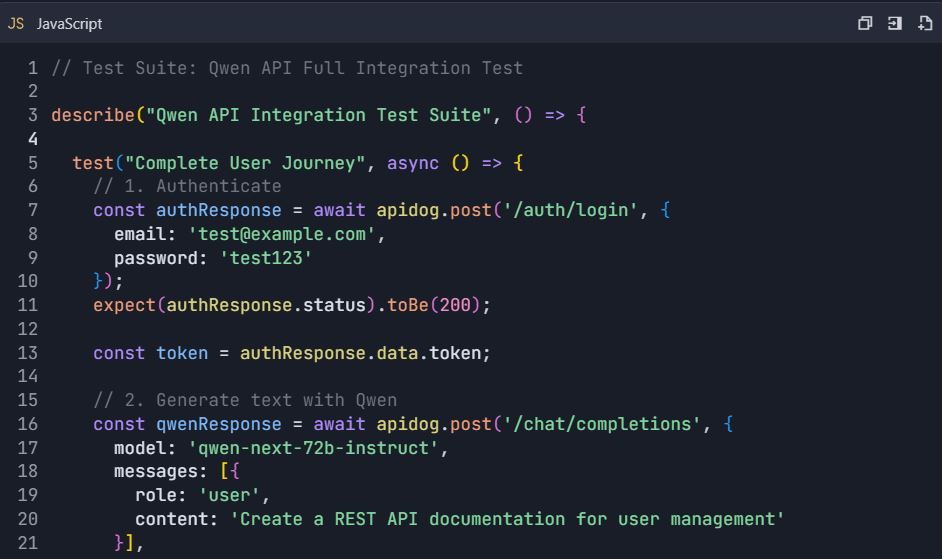
📋 Comandos de Prueba:
Esta guía de integración completa proporciona todo lo necesario para probar y documentar eficientemente la API de Qwen utilizando Apidog. La configuración permite pruebas automatizadas, monitoreo de rendimiento, colaboración en equipo e integración continua para un desarrollo robusto de API.
Técnicas Avanzadas de Optimización para la API de Qwen Next en Entornos de Producción
El procesamiento por lotes maximiza la eficiencia en escenarios de alto volumen. DashScope permite hasta 10 prompts por llamada, consolidando las solicitudes para minimizar la sobrecarga de latencia. Esto es adecuado para aplicaciones como la resumir en masa.
Monitorea de cerca el uso de tokens, ya que los cargos están ligados a los parámetros activos. Crea prompts concisos para ahorrar costos y usa `result_format='message'` para salidas analizables, omitiendo procesamiento adicional.
Implementa reintentos con retroceso exponencial para manejar transitorios. Una función que envuelve la llamada intenta varias veces, esperando progresivamente más tiempo entre intentos. Esto asegura la fiabilidad bajo carga.
Para la escalabilidad, distribuye en regiones como Singapur o EE. UU. Saneas las entradas para frustrar las inyecciones de prompts, validando contra listas blancas. Registra respuestas anonimizadas para cumplimiento.
En casos de contexto largo, divide los datos en fragmentos y encadena las llamadas. La variante `thinking` admite prompts estructurados para la coherencia en tokens extendidos. Estas estrategias aseguran implementaciones robustas.
Explorando la Siguiente Integración: Incrustando Qwen Next en Aplicaciones Web
La Siguiente Integración se refiere a la incorporación de Qwen Next en frameworks Next.js, aprovechando el renderizado del lado del servidor para las funciones de IA. Configura rutas de API en Next.js para proxyar las llamadas a Qwen, ocultando las claves a los clientes.
En tu manejador de API, usa el SDK de DashScope para procesar solicitudes, devolviendo respuestas en streaming si es necesario. Esta configuración permite contenido dinámico, como páginas personalizadas generadas sobre la marcha.
Maneja la autenticación del lado del servidor, utilizando la gestión de sesiones. Para actualizaciones en tiempo real, integra WebSockets con salidas de streaming. Prueba esto con Apidog, simulando solicitudes de cliente.
La optimización del rendimiento implica el almacenamiento en caché de consultas frecuentes. Usa Redis para almacenar respuestas, reduciendo las llamadas a la API. Esta combinación impulsa aplicaciones interactivas de manera eficiente.
Capacidades Multilingües y de Contexto Largo en la API de Qwen Next
Qwen Next soporta 119 idiomas, lo que lo hace versátil para aplicaciones globales. Especifica los idiomas en los prompts para traducciones o generaciones precisas. La API maneja los cambios sin problemas, manteniendo el contexto.
Para contextos largos, extiéndete hasta 128K tokens configurando `max_context_length`. Esto destaca en el análisis de documentos grandes. El prompting de cadena de pensamiento mejora el razonamiento sobre volúmenes.
Los benchmarks muestran una recuperación superior, ideal para motores de búsqueda. Intégralo con bases de datos para alimentar contextos dinámicamente.
Mejores Prácticas de Seguridad para Implementaciones de la API de Qwen
Protege las claves con bóvedas como AWS Secrets Manager. Monitorea el uso en busca de anomalías, configurando alertas ante picos. Cumple con las regulaciones anonimizando los datos.
La limitación de tasa del lado del cliente previene el abuso. Cifra las transmisiones con HTTPS.
Monitoreo y Escalado del Uso de la API de Qwen Next
Los paneles de DashScope rastrean métricas como el consumo de tokens. Establece presupuestos para evitar excesos. Escala actualizando los niveles para obtener límites más altos.
La infraestructura de autoescalado responde al tráfico. Herramientas como Kubernetes gestionan los contenedores que alojan la Siguiente Integración.
Casos de Estudio: Aplicaciones del Mundo Real de Qwen Next a Través de la API
En el comercio electrónico, Qwen Next impulsa motores de recomendación, analizando historiales de usuario para sugerencias. Las llamadas a la API generan descripciones dinámicamente.
Las aplicaciones de atención médica utilizan la variante `thinking` para ayudas diagnósticas, procesando informes con alta precisión.
Las plataformas de contenido emplean modelos `instruct` para la escritura automatizada, escalando la producción.
Perspectivas Futuras y Actualizaciones para Qwen Next
Alibaba continúa evolucionando la serie, con potencial para más expertos o un enrutamiento más fino. Mantente actualizado a través de canales oficiales como la cuenta QwenAI_Plus X.
Las mejoras de la API pueden incluir un mejor soporte de herramientas.
Aprovechando Qwen Next para Soluciones Innovadoras
Qwen Next a través de la API ofrece una eficiencia inigualable. Desde la configuración hasta las optimizaciones, ahora posees las herramientas para implementar de manera efectiva. Experimenta con integraciones, aprovechando Apidog para flujos de trabajo fluidos.