Los modelos Llama 4 de Meta, concretamente Llama 4 Maverick y Llama 4 Scout, representan un gran avance en la tecnología de IA multimodal. Lanzados el 5 de abril de 2025, estos modelos aprovechan una arquitectura Mixture-of-Experts (MoE), lo que permite un procesamiento eficiente de texto e imágenes con notables relaciones rendimiento-coste. Los desarrolladores pueden aprovechar estas capacidades a través de las API proporcionadas por varias plataformas, lo que hace que la integración en las aplicaciones sea fluida y potente.
Entendiendo Llama 4 Maverick y Llama 4 Scout
Antes de sumergirte en el uso de la API, comprende las especificaciones básicas de estos modelos. Llama 4 introduce la multimodalidad nativa, lo que significa que procesa texto e imágenes juntos desde el principio. Además, su diseño MoE activa solo un subconjunto de parámetros por tarea, lo que aumenta la eficiencia.
Llama 4 Scout: El caballo de batalla multimodal eficiente
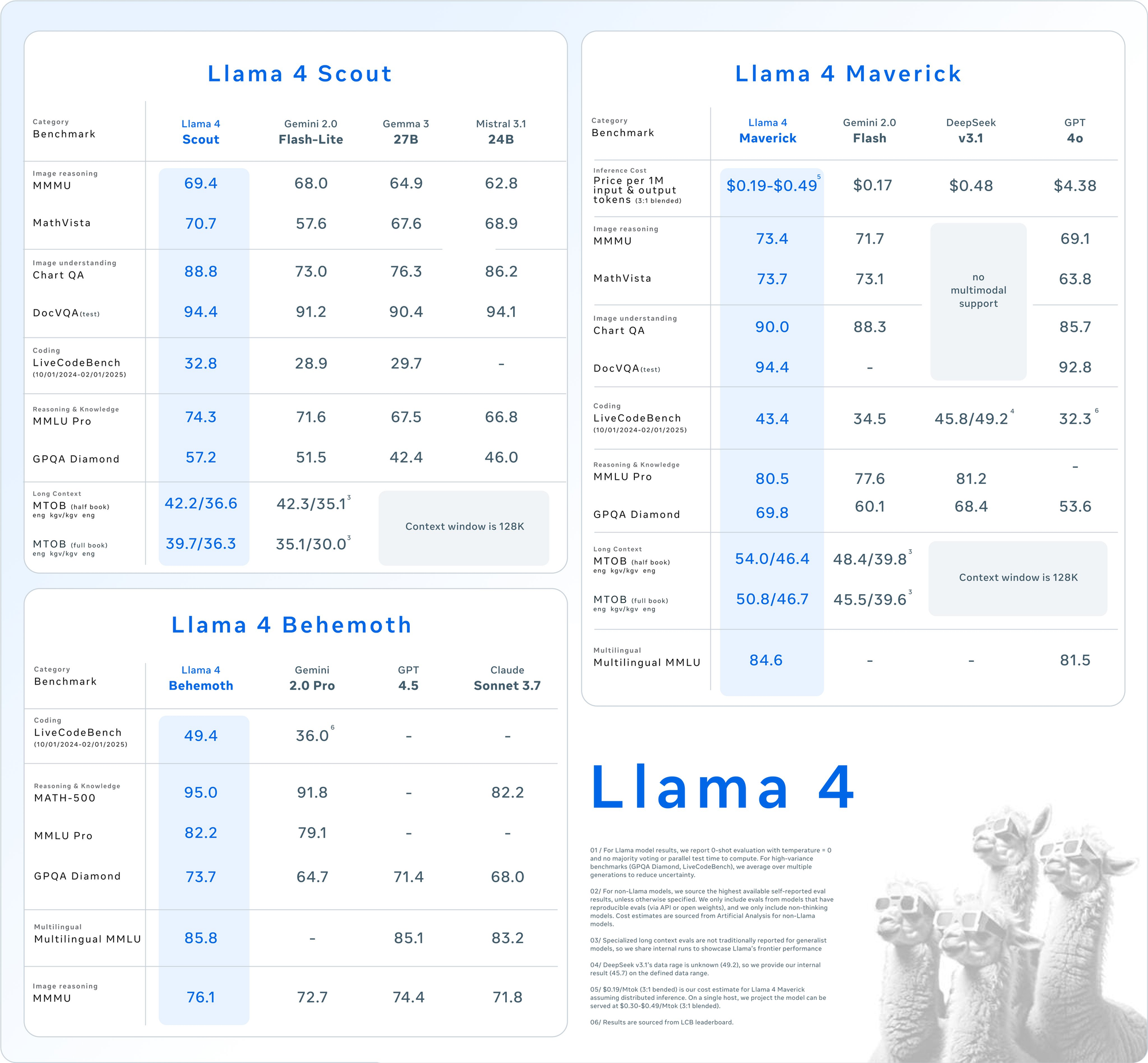
- Parámetros: 17 mil millones activos, 109 mil millones en total, 16 expertos.
- Ventana de contexto: Hasta 10 millones de tokens.
- Características clave: Destaca en tareas de contexto largo como el resumen de múltiples documentos y el razonamiento sobre grandes bases de código. Cabe en una sola GPU NVIDIA H100 con cuantificación INT4.
- Caso de uso: Ideal para desarrolladores que necesitan un procesamiento multimodal rápido y eficiente en recursos.
Llama 4 Maverick: La central eléctrica versátil
- Parámetros: 17 mil millones activos, 400 mil millones en total, 128 expertos.
- Ventana de contexto: Hasta 1 millón de tokens.
- Características clave: Ofrece texto e imágenes de alta calidad, compatible con 12 idiomas (por ejemplo, inglés, español, hindi). Está optimizado para el chat y la escritura creativa.
- Caso de uso: Adecuado para asistentes de nivel empresarial y aplicaciones multilingües.
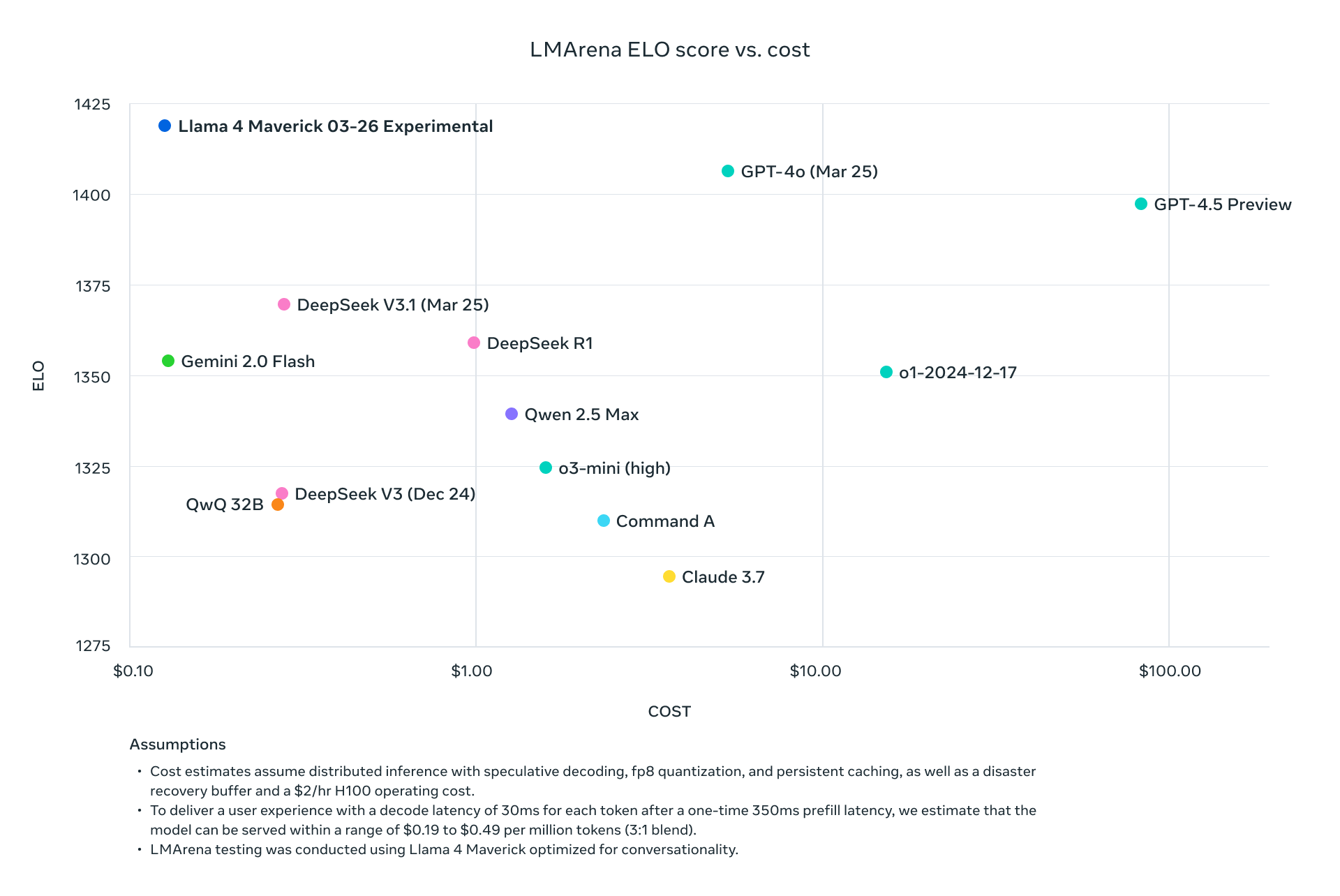
Ambos modelos superan a sus predecesores como Llama 3 y compiten con gigantes de la industria como GPT-4o, lo que los convierte en opciones convincentes para proyectos basados en API.
¿Por qué usar la API de Llama 4?
La integración de Llama 4 a través de la API elimina la necesidad de alojar estos modelos masivos localmente, lo que a menudo requiere hardware significativo (por ejemplo, NVIDIA H100 DGX para Maverick). En cambio, plataformas como Groq, Together AI y OpenRouter proporcionan API gestionadas, que ofrecen:
- Escalabilidad: Maneja cargas variables sin sobrecarga de infraestructura.
- Eficiencia de costes: Paga por token, con tarifas tan bajas como $0.11/M tokens de entrada (Scout en Groq).
- Facilidad de uso: Accede a funciones multimodales con simples solicitudes HTTP.
A continuación, configuremos tu entorno para llamar a estas API.
Configurando tu entorno para las llamadas a la API de Llama 4
Para interactuar con Llama 4 Maverick y Llama 4 Scout a través de la API, prepara tu entorno de desarrollo. Sigue estos pasos:
Paso 1: Elige un proveedor de API
Varias plataformas alojan las API de Llama 4. Aquí tienes opciones populares:
- Groq: Ofrece inferencia de bajo coste (Scout: $0.11/M de entrada, Maverick: $0.50/M de entrada).
- Together AI: Proporciona endpoints dedicados con escalado personalizado.
- OpenRouter: Nivel gratuito disponible, ideal para pruebas.
- Cloudflare Workers AI: Implementación sin servidor con soporte para Scout.
Para esta guía, usaremos Groq y Together AI como ejemplos debido a su sólida documentación y rendimiento.
Paso 2: Obtén las claves de la API
- Groq: Regístrate en groq.com, navega a la Consola de desarrollador y genera una clave de API.
- Together AI: Regístrate en together.ai, luego accede a tu clave de API desde el panel de control.
Guarda estas claves de forma segura (por ejemplo, en variables de entorno) para evitar codificarlas de forma rígida.
Paso 3: Instala las dependencias
Usa Python para simplificar. Instala las bibliotecas necesarias:
pip install requests
Para las pruebas, Apidog complementa esta configuración permitiéndote depurar visualmente los endpoints de la API.
Haciendo tu primera llamada a la API de Llama 4
Con tu entorno listo, envía una solicitud a la API de Llama 4. Comencemos con un ejemplo básico de generación de texto.
Ejemplo 1: Generación de texto con Llama 4 Scout (Groq)
import requests
import os
# Set API key
API_KEY = os.getenv("GROQ_API_KEY")
URL = "https://api.groq.com/v1/chat/completions"
# Define payload
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": "Write a short poem about AI."}
],
"max_tokens": 150,
"temperature": 0.7
}
# Set headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send request
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Salida: Un poema conciso generado por Scout, aprovechando su eficiente arquitectura MoE.
Ejemplo 2: Entrada multimodal con Llama 4 Maverick (Together AI)
Maverick brilla en tareas multimodales. Aquí te mostramos cómo describir una imagen:
import requests
import os
# Set API key
API_KEY = os.getenv("TOGETHER_API_KEY")
URL = "https://api.together.ai/v1/chat/completions"
# Define payload with image and text
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/sample.jpg"}
},
{
"type": "text",
"text": "Describe this image."
}
]
}
],
"max_tokens": 200
}
# Set headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send request
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Salida: Una descripción detallada de la imagen, que muestra la alineación imagen-texto de Maverick.
Optimizando las solicitudes de la API para el rendimiento
Para maximizar la eficiencia, ajusta tus llamadas a la API de Llama 4. Considera estas técnicas:
Ajusta la longitud del contexto
- Scout: Usa su ventana de 10 millones de tokens para documentos largos. Establece
max_model_len(si es compatible) para manejar entradas grandes. - Maverick: Limita a 1 millón de tokens para aplicaciones de chat para equilibrar la velocidad y la calidad.
Ajusta los parámetros
- Temperatura: Más baja (por ejemplo, 0.5) para respuestas objetivas, más alta (por ejemplo, 1.0) para la creatividad.
- Tokens máximos: Limita la longitud de la salida para evitar cálculos innecesarios.
Procesamiento por lotes
Envía múltiples prompts en una sola solicitud (si la API lo admite) para reducir la latencia. Consulta la documentación del proveedor para obtener endpoints por lotes.
Casos de uso avanzados con la API de Llama 4
Ahora, explora integraciones avanzadas para desbloquear todo el potencial de Llama 4.
Caso de uso 1: Chatbot multilingüe
Maverick admite 12 idiomas. Crea un bot de atención al cliente:
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Salida: Una respuesta en español, aprovechando la fluidez multilingüe de Maverick.
Caso de uso 2: Resumen de documentos con Scout
La ventana de 10 millones de tokens de Scout destaca en el resumen de textos grandes:
long_text = "..." # Insert a lengthy document here
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": f"Summarize this: {long_text}"}
],
"max_tokens": 300
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Salida: Un resumen conciso, procesado eficientemente por Scout.
Depuración y pruebas con Apidog
Probar las API puede ser complicado, especialmente con entradas multimodales. Aquí es donde Apidog brilla:
- Interfaz visual: Crea y envía solicitudes sin codificar.
- Seguimiento de errores: Identifica problemas como límites de velocidad o cargas útiles mal formadas.
- Respuestas simuladas: Simula las salidas de Llama 4 para el desarrollo frontend.
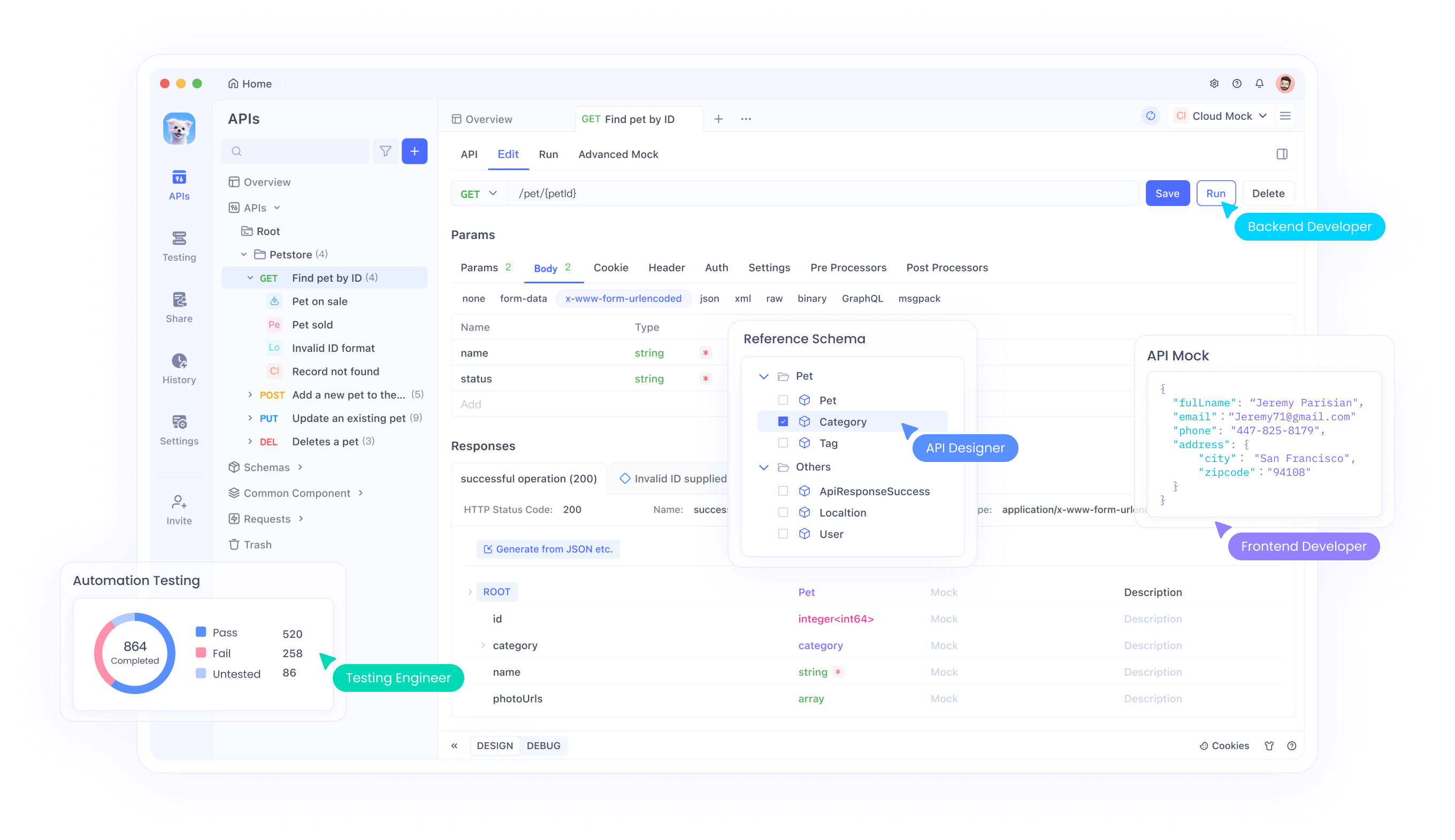
Para probar los ejemplos anteriores en Apidog:
- Abre Apidog y crea una nueva solicitud.
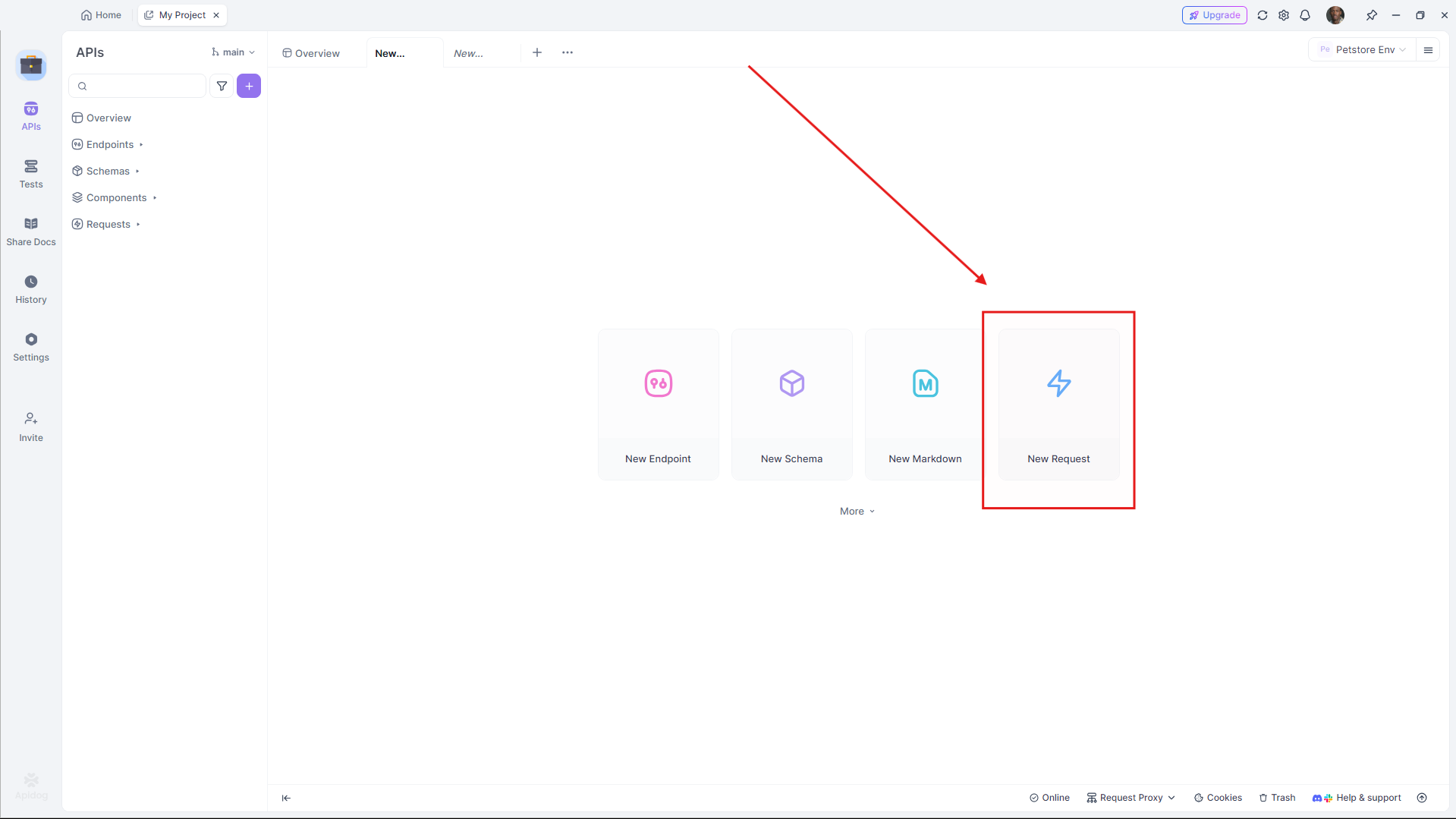
- Establece la URL (por ejemplo,
https://api.groq.com/v1/chat/completions).

- Añade encabezados (
Authorization,Content-Type).
- Pega la carga útil JSON.

- Envía y revisa la respuesta.

Este flujo de trabajo garantiza que tu integración de la API de Llama 4 se ejecute sin problemas.
Comparando proveedores de API para Llama 4
Elegir el proveedor adecuado afecta al coste y al rendimiento. Aquí tienes un desglose:
| Proveedor | Soporte del modelo | Precios (Entrada/Salida por M) | Límite de contexto | Notas |
|---|---|---|---|---|
| Groq | Scout, Maverick | $0.11/$0.34 (Scout), $0.50/$0.77 (Maverick) | 128K (extensible) | El coste más bajo, alta velocidad |
| Together AI | Scout, Maverick | Personalizado (endpoints dedicados) | 1M (Maverick) | Escalable, centrado en la empresa |
| OpenRouter | Ambos | Nivel gratuito disponible | 128K | Ideal para pruebas |
| Cloudflare | Scout | Basado en el uso | 131K | Simplicidad sin servidor |
Selecciona en función de la escala y el presupuesto de tu proyecto. Para la creación de prototipos, comienza con el nivel gratuito de OpenRouter, luego escala con Groq o Together AI.
Mejores prácticas para la integración de la API de Llama 4
Para garantizar una integración sólida, sigue estas pautas:
- Limitación de velocidad: Respeta los límites del proveedor (por ejemplo, 100 solicitudes/minuto de Groq). Implementa una retirada exponencial para los reintentos.
- Manejo de errores: Captura los errores HTTP (por ejemplo, 429 Demasiadas solicitudes) y regístralos.
- Seguridad: Cifra las claves de la API y usa endpoints HTTPS.
- Monitorización: Realiza un seguimiento del uso de tokens para gestionar los costes, especialmente con las tarifas más altas de Maverick.
Solución de problemas comunes de la API
¿Encuentras problemas? Abórdalos rápidamente:
- 401 No autorizado: Verifica tu clave de API.
- 429 Límite de velocidad excedido: Reduce la frecuencia de las solicitudes o actualiza tu plan.
- Errores de carga útil: Asegúrate de que el formato JSON coincida con las especificaciones del proveedor (por ejemplo, la matriz
messages).
Apidog ayuda a diagnosticar estos problemas visualmente, ahorrando tiempo.
Conclusión
La integración de Llama 4 Maverick y Llama 4 Scout a través de la API permite a los desarrolladores crear aplicaciones de vanguardia con una sobrecarga mínima. Ya sea que necesites la eficiencia de contexto largo de Scout o la destreza multilingüe de Maverick, estos modelos ofrecen un rendimiento de primer nivel a través de endpoints accesibles. Siguiendo esta guía, puedes configurar, optimizar y solucionar problemas de tus llamadas a la API de manera efectiva.
¿Listo para profundizar? Experimenta con proveedores como Groq y Together AI, y aprovecha Apidog para refinar tu flujo de trabajo. El futuro de la IA multimodal está aquí: ¡comienza a construir hoy mismo!