
¿Quieres chatear con más de 100 modelos de lenguaje grandes (LLMs) como si todos fueran la API de OpenAI? Ya sea que estés construyendo un chatbot, automatizando tareas o simplemente explorando, **LiteLLM** es tu pase para llamar a LLMs de OpenAI, Anthropic, Ollama y más, todo usando el mismo formato estilo OpenAI. Me sumergí en **LiteLLM** para simplificar mis llamadas a la API, y déjame decirte, es un salvavidas para mantener el código limpio y flexible. En esta guía para principiantes, te mostraré cómo configurar **LiteLLM**, llamar a un modelo local de Ollama y a GPT-4o de OpenAI, e incluso transmitir respuestas, todo basado en la documentación oficial. ¿Listo para hacer que tus proyectos de IA sean más fluidos que una tarde soleada? ¡Empecemos!
¿Qué es LiteLLM? Tu superpoder para la API de LLM
**LiteLLM** es una librería de Python de código abierto y un servidor proxy que te permite llamar a más de 100 APIs de LLM —como OpenAI, Anthropic, Azure, Hugging Face y modelos locales a través de Ollama— usando el formato OpenAI Chat Completions. Estandariza entradas y salidas, gestiona claves de API y añade extras como streaming, fallbacks y seguimiento de costos, para que no necesites reescribir código para cada proveedor. Con más de 22.7K estrellas en GitHub y adopción por empresas como Adobe y Lemonade, **LiteLLM** es uno de los favoritos entre los desarrolladores. Ya sea que estés documentando APIs (como con MkDocs) o construyendo aplicaciones de IA, **LiteLLM** simplifica tu flujo de trabajo. ¡Vamos a configurarlo y verlo en acción!
Configurando Tu Entorno para LiteLLM
Antes de llamar a LLMs con **LiteLLM**, preparemos tu sistema. Esta guía es apta para principiantes, con cada paso explicado para mantenerte encaminado.
1. Verificar Requisitos Previos: Necesitarás estas herramientas:
- Python: Versión 3.8 o superior. Ejecuta
python --versionen tu terminal. Si falta o es demasiado antigua, consíguela en python.org. Python ejecuta los scripts de **LiteLLM**. - pip: El gestor de paquetes de Python, incluido con Python 3.4+. Verifica con
pip --version. Si no está presente, descargaget-pip.pyy ejecutapython get-pip.py. - Ollama: Para modelos locales. Descárgalo desde ollama.com y verifica con
ollama --version(por ejemplo, 0.1.44). Lo usaremos para una prueba de LLM local.
¿Falta algo? Instálalo ahora para que todo funcione sin problemas.
2. Crear una Carpeta de Proyecto: Mantengámonos organizados:
mkdir litellm-api-test
cd litellm-api-test
Esta carpeta contendrá tu proyecto de **LiteLLM**, y cd te prepara.
3. Configurar un Entorno Virtual: Evita conflictos de paquetes con un entorno virtual de Python:
python -m venv venv
Actívalo:
- Mac/Linux:
source venv/bin/activate - Windows:
venv\Scripts\activate
Ver (venv) en tu terminal significa que estás en un entorno limpio, aislando las dependencias de **LiteLLM**.
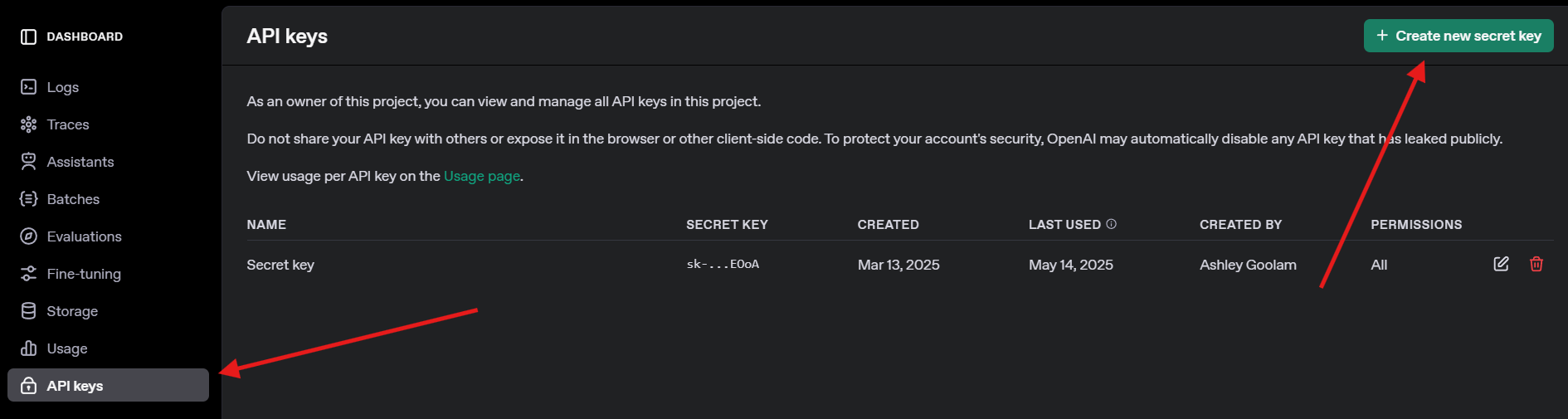
4. Obtener una Clave de API de OpenAI: Para la prueba de GPT-4o, regístrate en openai.com, navega a claves de API y crea una clave. Guárdala de forma segura, la necesitarás más tarde.
Instalando LiteLLM y Ollama
Ahora, instalemos **LiteLLM** y configuremos Ollama para modelos locales. Esto es rápido y prepara el escenario para nuestras llamadas a la API.
1. Instalar LiteLLM: En tu entorno virtual activado, ejecuta:
pip install litellm openai
Esto instala **LiteLLM** y el SDK de OpenAI (necesario para la compatibilidad). Descarga dependencias como pydantic y httpx.
2. Verificar LiteLLM: Verifica la instalación:
python -c "import litellm; print(litellm.__version__)"
Espera una versión como 1.40.14 o más reciente. Si falla, actualiza pip (`pip install --upgrade pip`).
3. Configurar Ollama: Asegúrate de que Ollama esté ejecutándose y descarga un modelo ligero como Llama 3 (8B):
ollama pull llama3
Esto descarga ~4.7GB, así que toma un refrigerio si tu conexión es lenta. Verifica con ollama list para ver llama3:latest. Ollama aloja modelos locales para que **LiteLLM** los llame.
Llamando a LLMs con LiteLLM: Ejemplos con OpenAI y Ollama
¡Lleguemos a la parte divertida: llamar a los LLMs! Crearemos un script de Python para llamar a GPT-4o de OpenAI y a un modelo local de Llama 3 a través de Ollama, ambos usando el formato compatible con OpenAI de **LiteLLM**. También probaremos el streaming para respuestas en tiempo real.
1. Crear un Script de Prueba: En tu carpeta litellm-api-test, crea test_llm.py con este código:
from litellm import completion
import os
# Set environment variables
os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Replace with your key
os.environ["OLLAMA_API_BASE"] = "http://localhost:11434" # Default Ollama endpoint
# Messages for the LLM
messages = [{"content": "Write a short poem about the moon", "role": "user"}]
# Call OpenAI GPT-4o
print("Calling GPT-4o...")
gpt_response = completion(
model="openai/gpt-4o",
messages=messages,
max_tokens=50
)
print("GPT-4o Response:", gpt_response.choices[0].message.content)
# Call Ollama Llama 3
print("\nCalling Ollama Llama 3...")
ollama_response = completion(
model="ollama/llama3",
messages=messages,
max_tokens=50,
api_base="http://localhost:11434"
)
print("Llama 3 Response:", ollama_response.choices[0].message.content)
# Stream Ollama Llama 3 response
print("\nStreaming Ollama Llama 3...")
stream_response = completion(
model="ollama/llama3",
messages=messages,
stream=True,
api_base="http://localhost:11434"
)
print("Streamed Llama 3 Response:")
for chunk in stream_response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Newline after streaming
Este script:
- Configura las claves de API y el endpoint de Ollama.
- Define un prompt (“Escribe un poema corto sobre la luna”).
- Llama a GPT-4o y Llama 3 con la función
completionde **LiteLLM**. - Transmite la respuesta de Llama 3 para una salida en tiempo real.
2. Reemplazar la Clave de API: Actualiza os.environ["OPENAI_API_KEY"] con tu clave de OpenAI real. Si no tienes una, omite la llamada a GPT-4o y enfócate en Ollama.
3. Asegurarse de que Ollama esté Ejecutándose: Inicia Ollama en una terminal separada:
ollama serve
Esto ejecuta Ollama en http://localhost:11434. Mantenlo abierto para las llamadas a Llama 3.
4. Ejecutar el Script: En tu entorno virtual, ejecuta:
python test_llm.py
- Cuando ejecuté esto, GPT-4o devolvió un poema pulido como:
>> The moon’s soft glow, a silver dream, lights paths where quiet shadows gleam.
- Llama 3 dio una versión más simple pero encantadora, como:
>> Moon so bright in the night sky, glowing soft as clouds float by.
La respuesta transmitida se imprimió palabra por palabra, sintiéndose como si el LLM estuviera escribiendo en vivo. Si falla, verifica que Ollama esté funcionando, que tu clave de OpenAI sea válida o que el puerto 11434 esté abierto. Los logs de depuración están en ~/.litellm/logs.
Añadiendo Observabilidad con Callbacks de LiteLLM
¿Quieres rastrear tus llamadas a LLM como un profesional? **LiteLLM** soporta callbacks para registrar entradas, salidas y costos en herramientas como Langfuse o MLflow. Añadamos un callback simple para registrar los costos.
Actualizar el Script: Modifica test_llm.py para incluir un callback de seguimiento de costos:
from litellm import completion
import os
# Callback function to track cost
def track_cost_callback(kwargs, completion_response, start_time, end_time):
cost = kwargs.get("response_cost", 0)
print(f"Response cost: ${cost:.4f}")
# Set callback
import litellm
litellm.success_callback = [track_cost_callback]
# Rest of the script (same as above)
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
os.environ["OLLAMA_API_BASE"] = "http://localhost:11434"
messages = [{"role": "user", "content": "Write a short poem about the moon"}]
print("Calling GPT-4o...")
gpt_response = completion(model="openai/gpt-4o", messages=messages, max_tokens=50)
print("GPT-4o Response:", gpt_response.choices[0].message.content)
# ... (Ollama and streaming calls unchanged)
Esto registra el costo de cada llamada (por ejemplo, “Costo de respuesta: $0.0025” para GPT-4o). Las llamadas a Ollama son gratuitas, por lo que su costo es $0.
Ejecutar de Nuevo: Ejecuta python test_llm.py. Verás los registros de costos junto a las respuestas, lo que te ayudará a monitorear los gastos de los LLMs basados en la nube.
Documentando Tus APIs con APIdog
Dado que estás trabajando con APIs de LLM, es probable que quieras documentarlas claramente para tu equipo o usuarios. Te recomiendo encarecidamente que eches un vistazo a **APIdog**. ¡La Documentación de APIdog es una herramienta fantástica para esto! Ofrece una plataforma elegante e interactiva para diseñar, probar y documentar APIs, con características como API playgrounds y opciones de autoalojamiento. Combinar las llamadas a la API de **LiteLLM** con la documentación pulida de APIdog puede llevar tu proyecto al siguiente nivel. ¡Pruébalo!
Mis Opiniones sobre LiteLLM
Después de jugar con **LiteLLM**, esto es lo que me encanta:
- Formato Unificado: Una estructura de código para OpenAI, Ollama y más allá, adiós a los dolores de cabeza específicos de cada API.
- Poder Local: La integración con Ollama te permite ejecutar modelos sin conexión, perfecto para la privacidad o proyectos de bajo presupuesto.
- Diversión con Streaming: Las respuestas en tiempo real hacen que las aplicaciones se sientan vivas, como chatear con un amigo.
- Comunidad Activa: Con más de 18K estrellas en GitHub, **LiteLLM** es uno de los favoritos entre los desarrolladores.
¿Desafíos? La configuración puede ser un poco complicada si Ollama o las claves de API no están bien configuradas, pero la documentación es sólida.
Consejos Pro para el Éxito con LiteLLM
- Depuración: Habilita el registro detallado con
litellm.set_verbose = Truepara ver las solicitudes y respuestas crudas. - Más Modelos: Prueba Claude de Anthropic o Azure OpenAI añadiendo sus claves de API y modelos (por ejemplo,
anthropic/claude-3-sonnet-20240229). - Llamadas Asíncronas: Usa
litellm.acompletionpara llamadas no bloqueantes en aplicaciones FastAPI. - Servidor Proxy: Ejecuta **LiteLLM** como un proxy (`litellm --model gpt-3.5-turbo`) para que múltiples aplicaciones compartan un único endpoint.
- Comunidad: Únete al Discord de **LiteLLM** o a las Discusiones de GitHub para obtener consejos y actualizaciones.
Conclusión: Tu Viaje con LiteLLM Comienza Aquí
¡Acabas de desbloquear el poder de **LiteLLM** para llamar a LLMs como un profesional, desde GPT-4o de OpenAI hasta Llama 3 local, todo en un formato limpio! Ya sea que estés construyendo aplicaciones de IA o experimentando como un programador curioso, **LiteLLM** facilita cambiar modelos, transmitir respuestas y rastrear costos. Prueba nuevos prompts, añade más proveedores o configura un servidor proxy para proyectos más grandes. Comparte tus logros con **LiteLLM** en el GitHub de **LiteLLM**. ¡Estoy emocionado de ver lo que creas! Y no olvides echar un vistazo a APIdog para documentar tus APIs. ¡Feliz programación!