
Los modelos de lenguaje visual (VLMs) han revolucionado la capacidad de la IA para comprender y razonar sobre el contenido visual. Entre estas innovaciones, el modelo Kimi VL Thinking de Moonshot AI destaca como particularmente impresionante, combinando capacidades de razonamiento avanzadas con una eficiencia notable. Este tutorial te guiará a través de la comprensión de las capacidades de Kimi VL Thinking y cómo usarlo gratis a través de la plataforma de OpenRouter.
Kimi VL Thinking Benchmarks
Kimi VL Thinking (oficialmente llamado Kimi-VL-A3B-Thinking) es un modelo de lenguaje visual avanzado desarrollado por Moonshot AI. Lo que hace que este modelo sea especial es su arquitectura Mixture-of-Experts (MoE) que activa solo 2.8 mil millones de parámetros por paso de inferencia, mientras que contiene aproximadamente 16 mil millones de parámetros en total. Esto le permite ofrecer un razonamiento sofisticado con una computación relativamente eficiente.
Kimi VL Thinking está diseñado específicamente para tareas de razonamiento avanzadas, particularmente aquellas que requieren un pensamiento paso a paso y un análisis matemático de las entradas visuales. Fue creado ajustando el modelo base Kimi VL con técnicas de aprendizaje supervisado de cadena de pensamiento (CoT) y aprendizaje por refuerzo.
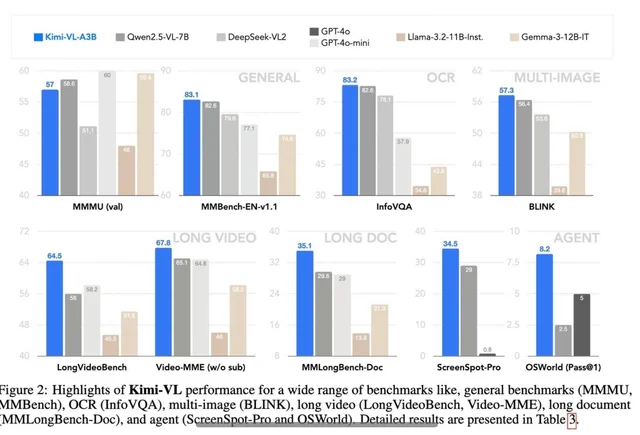
Aspectos destacados del modelo Kimi VL Thinking
- Ventana de contexto larga: admite hasta 128K tokens, lo que permite conversaciones extensas de varios turnos y el procesamiento de documentos largos.
- Visión de resolución nativa: utiliza el codificador MoonViT para procesar entradas visuales de alta resolución con un excelente reconocimiento de detalles.
- Razonamiento avanzado: especialmente fuerte en el razonamiento visual matemático y la resolución de problemas paso a paso.
- Computación eficiente: a pesar de sus poderosas capacidades, el modelo activa solo 2.8B parámetros, lo que lo hace más accesible que las alternativas más grandes.
- Código abierto: disponible bajo la licencia MIT, lo que permite amplias aplicaciones académicas y comerciales.
Rendimiento de Kimi VL Thinking Benchmark
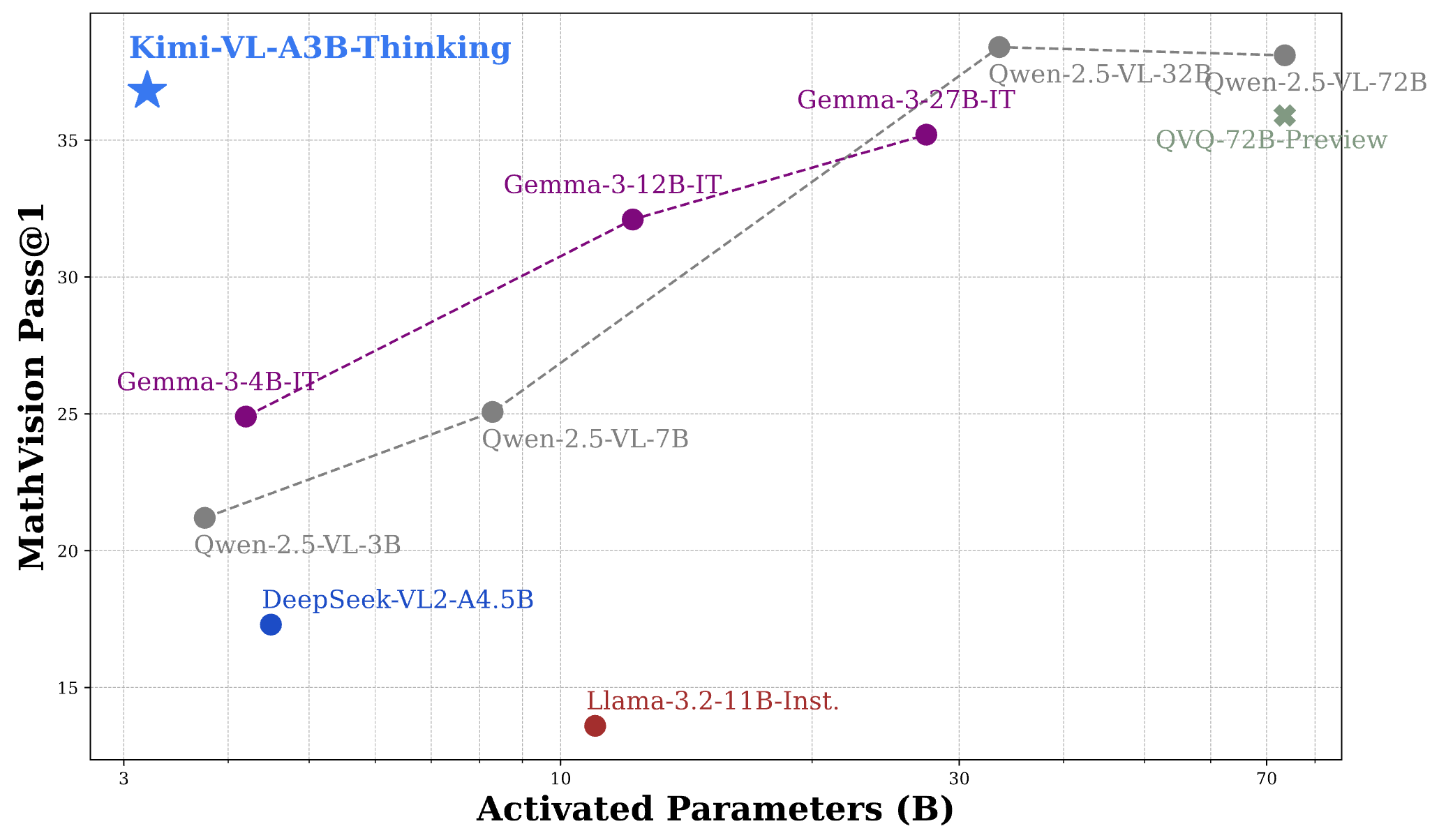
Kimi VL Thinking demuestra un rendimiento impresionante en varios benchmarks desafiantes, a menudo rivalizando o superando a modelos mucho más grandes:
- MathVision: alcanza una puntuación de 36.8 (Pass@1), comparable a modelos como Gemma-3-27B (35.5) y acercándose a Qwen2.5-VL-72B (38.1).
- MathVista: obtiene una puntuación de 71.3 en el mini benchmark, superando a modelos como GPT-4o-mini (56.7) y Gemma-3-12B (56.4).
- MMMU (Multimodal Massive Multitask Understanding): alcanza 61.7 en el conjunto de validación, lo que demuestra sólidas capacidades en tareas multimodales complejas.
Para poner estos resultados en perspectiva, el rendimiento de Kimi VL Thinking es notable considerando que activa solo 2.8B parámetros, mientras que compite contra modelos que usan 7B, 12B o incluso más de 70B parámetros. Esto lo posiciona como uno de los VLMs con capacidad de razonamiento más eficientes disponibles.
Cómo usar Kimi VL Thinking gratis a través de OpenRouter
OpenRouter proporciona una forma conveniente de acceder a Kimi VL Thinking sin necesidad de implementar el modelo usted mismo. Su nivel gratuito le permite experimentar con el modelo sin ningún costo. Aquí le mostramos cómo comenzar:
Paso 1: Crear una cuenta de OpenRouter
- Visite el sitio web de OpenRouter y regístrese para obtener una cuenta si aún no tiene una.
- Después del registro, navegue a la configuración de su cuenta para generar una clave API.
- Guarde esta clave API de forma segura, ya que la necesitará para todas las llamadas API.
Paso 2: Comprender la estructura de la API de OpenRouter
La API de OpenRouter está diseñada para ser compatible con el formato de la API de OpenAI, lo que facilita la integración si ya está familiarizado con los servicios de OpenAI. Las diferencias clave son:
- La URL base:
https://openrouter.ai/api/v1 - El nombre del modelo:
moonshotai/kimi-vl-a3b-thinking:free - Encabezados opcionales adicionales para análisis
Paso 3: Hacer su primera llamada API
Para los usuarios de Python, configure su entorno con estas dependencias:
pip install openai requests pillow
Comencemos con un ejemplo básico usando el SDK de OpenAI, que es el enfoque más sencillo:
from openai import OpenAI
from base64 import b64encode
from PIL import Image
import io
# Initialize the client with OpenRouter's base URL
client = OpenAI(
base_url="<https://openrouter.ai/api/v1>",
api_key="your_openrouter_api_key_here",
)
# Function to encode images
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# Load and encode your image
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# Create the API request
completion = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "your_site_url", # Optional for analytics
"X-Title": "your_app_name", # Optional for analytics
},
model="moonshotai/kimi-vl-a3b-thinking:free",
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Please examine this mathematical problem and solve it step by step."
}
]
}
],
max_tokens=1024
)
print(completion.choices[0].message.content)
Si prefiere usar llamadas API directas sin el SDK:
import requests
import json
from base64 import b64encode
# Function to encode images
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# Load and encode your image
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# Create the API request
response = requests.post(
url="<https://openrouter.ai/api/v1/chat/completions>",
headers={
"Authorization": "Bearer your_openrouter_api_key_here",
"Content-Type": "application/json",
"HTTP-Referer": "your_site_url", # Optional for analytics
"X-Title": "your_app_name", # Optional for analytics
},
data=json.dumps({
"model": "moonshotai/kimi-vl-a3b-thinking:free",
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Please examine this mathematical problem and solve it step by step."
}
]
}
],
"max_tokens": 1024
})
)
print(response.json()["choices"][0]["message"]["content"])
Para respuestas largas o una mejor experiencia de usuario, es posible que desee transmitir la salida del modelo:
from openai import OpenAI
from base64 import b64encode
client = OpenAI(
base_url="<https://openrouter.ai/api/v1>",
api_key="your_openrouter_api_key_here",
)
# Function to encode images
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# Load and encode your image
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# Create a streaming request
stream = client.chat.completions.create(
model="moonshotai/kimi-vl-a3b-thinking:free",
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Please examine this mathematical problem and solve it step by step."
}
]
}
],
stream=True,
max_tokens=1024
)
# Process the streaming response
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Probar la API de Kimi VL Thinking con Apidog
Apidog es una herramienta integral de prueba de API que simplifica el proceso de interacción con API como Kimi VL Thinking. Sus características, como la gestión del entorno y la simulación de escenarios, lo hacen ideal para los desarrolladores. Veamos cómo usar Apidog para probar la API de Kimi VL Thinking.
Configurar Apidog
Primero, descargue e instale Apidog desde apidog.com. Una vez instalado, cree un nuevo proyecto y agregue el punto final de la API de Kimi VL Thinking: https://openrouter.ai/api/v1/chat/completions.
Configurar su entorno
A continuación, configure diferentes entornos (por ejemplo, desarrollo y producción) en Apidog. Defina variables como su clave API y URL base para cambiar fácilmente entre configuraciones. En Apidog, vaya a la pestaña "Entornos" y agregue:
api_key: su clave API de OpenRouterbase_url:https://openrouter.ai/api/v1
Crear una solicitud de prueba
Ahora, cree una nueva solicitud POST en Apidog.
Establezca la URL en {{base_url}}/chat/completions, agregue sus encabezados e ingrese el cuerpo JSON:
{
"model": "quasar-alpha",
"messages": [
{"role": "user", "content": "Explain the difference between let and const in JavaScript."}
],
"max_tokens": 300
}
En la sección de encabezados, agregue:
Authorization:Bearer {{api_key}}Content-Type:application/json
Ejecutar y analizar la prueba
Finalmente, envíe la solicitud y analice la respuesta en la interfaz visual de Apidog. Apidog proporciona informes detallados, incluido el tiempo de respuesta, el código de estado y el uso de tokens. También puede guardar esta solicitud como un escenario reutilizable para futuras pruebas.

La capacidad de Apidog para simular escenarios del mundo real y generar informes exportables lo convierte en una herramienta poderosa para depurar y optimizar sus interacciones con la API de Kimi VL Thinking. Terminemos con algunas prácticas recomendadas.
Optimización de prompts para Kimi VL Thinking
Kimi VL Thinking sobresale en el razonamiento paso a paso, así que estructure sus prompts para aprovechar esta capacidad:
- Sea explícito sobre el razonamiento: pídale al modelo que "piense paso a paso" o que "razone este problema cuidadosamente".
- Una tarea a la vez: para problemas complejos, divídalos en pasos manejables en lugar de pedir todo a la vez.
- Proporcione contexto: cuando sea relevante, proporcione información de fondo que pueda ayudar al modelo a comprender mejor el problema.
- Use instrucciones claras: especifique exactamente lo que quiere que el modelo analice en la imagen.
Conclusión
Kimi VL Thinking representa un logro impresionante en modelos de lenguaje visual eficientes pero potentes. Su capacidad para realizar un razonamiento avanzado mientras activa solo 2.8B parámetros lo hace accesible a una gama más amplia de usuarios que los modelos grandes tradicionales.
Al aprovechar el nivel gratuito de OpenRouter, puede experimentar con esta tecnología de vanguardia sin barreras de costos. Ya sea que esté trabajando en aplicaciones educativas, análisis de datos o documentación técnica, Kimi VL Thinking ofrece una herramienta poderosa para comprender y razonar sobre el contenido visual.
A medida que se sienta más cómodo con el modelo, puede explorar casos de uso más complejos y potencialmente integrarlo en aplicaciones de producción. Recuerde que el nivel gratuito es perfecto para la experimentación, pero para casos de uso de producción con altos volúmenes, podría considerar actualizar a un nivel pago para obtener una mejor confiabilidad y garantías de rendimiento.
¡Comience a explorar Kimi VL Thinking hoy y descubra cómo las capacidades avanzadas de razonamiento visual pueden mejorar sus proyectos!


