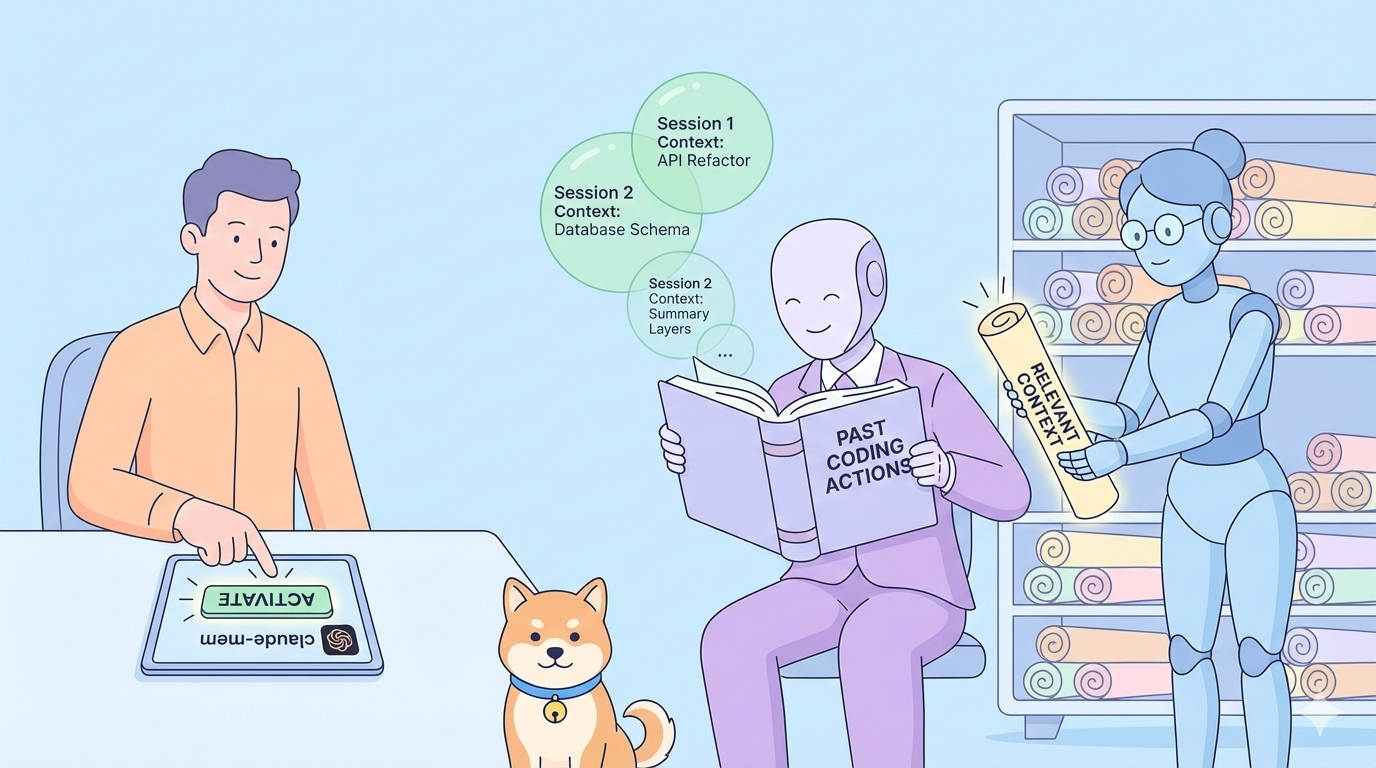
¿Qué pasaría si tu asistente de IA recordara cada decisión arquitectónica, corrección de errores y sesión de refactorización a lo largo de semanas de desarrollo? Claude-mem elimina la fricción de la pérdida de contexto al capturar automáticamente las observaciones de uso de herramientas, comprimirlas en resúmenes semánticos e inyectar historial relevante en cada nueva sesión de Claude Code.
El problema: Amnesia de contexto en el desarrollo asistido por IA
Cada sesión de Claude Code comienza como una pizarra en blanco. Cuando cierras tu terminal o te desconectas de una sesión, Claude olvida todo: la estructura de tu proyecto, las decisiones recientes de refactorización, los descubrimientos de depuración y los patrones arquitectónicos. Esto te obliga a explicar repetidamente tu base de código, quemando tokens en contexto redundante y rompiendo la continuidad del flujo de trabajo.
Actualmente, los desarrolladores resuelven esto manteniendo manualmente archivos CLAUDE.md, tomando notas en documentos separados o reexplicando el contexto del proyecto al inicio de cada sesión. Estos enfoques son frágiles, requieren mucho tiempo y nunca capturan toda la riqueza de tu historial de desarrollo. Claude-mem resuelve esto observando automáticamente cada invocación de herramienta, comprimiendo la salida en memorias semánticas buscables y recuperando de forma inteligente el contexto relevante cuando lo necesitas.
¿Quieres una plataforma integrada, todo en uno, para que tu equipo de desarrolladores trabaje junto con máxima productividad?
¡Apidog cumple todas tus demandas y reemplaza a Postman a un precio mucho más asequible!
Comprendiendo la Arquitectura de Claude-mem
Claude-mem funciona como un sistema de compresión de memoria persistente que se integra en el ciclo de vida de Claude Code. Captura las salidas de las herramientas (típicamente de 1,000 a 10,000 tokens) y las comprime en observaciones semánticas de aproximadamente 500 tokens utilizando el SDK de Agente de Claude. Estas observaciones se categorizan por tipo (decisión, corrección de errores, característica, refactorización, descubrimiento, cambio) y se etiquetan con conceptos relevantes y referencias de archivos, para luego almacenarse en una base de datos SQLite local con capacidades de búsqueda de texto completo.
El sistema utiliza cinco hooks de ciclo de vida para capturar el contexto:
- SessionStart: Inyecta contexto de sesiones anteriores cuando empiezas
- UserPromptSubmit: Captura tus consultas para el reconocimiento de patrones
- PostToolUse: Observa cada ejecución de herramienta y su salida
- Stop: Genera resúmenes de sesión cuando Claude termina de responder
- SessionEnd: Finaliza el almacenamiento de la sesión y la limpieza
Esta arquitectura permite la divulgación progresiva, un sistema de recuperación de memoria en capas que equilibra la cobertura con la eficiencia de los tokens. En lugar de volcar todo tu historial en el contexto, Claude-mem recupera las observaciones en capas, ahorrando aproximadamente 2,250 tokens por sesión en comparación con la gestión manual del contexto.
Instalación y Requisitos del Sistema
Claude-mem requiere Node.js 18.0.0 o superior, la última versión de Claude Code con soporte para plugins, y Bun como entorno de ejecución de JavaScript y gestor de procesos (auto-instalado si falta). SQLite 3 se incluye para el almacenamiento persistente. El plugin funciona de forma multiplataforma en Windows, macOS y Linux.
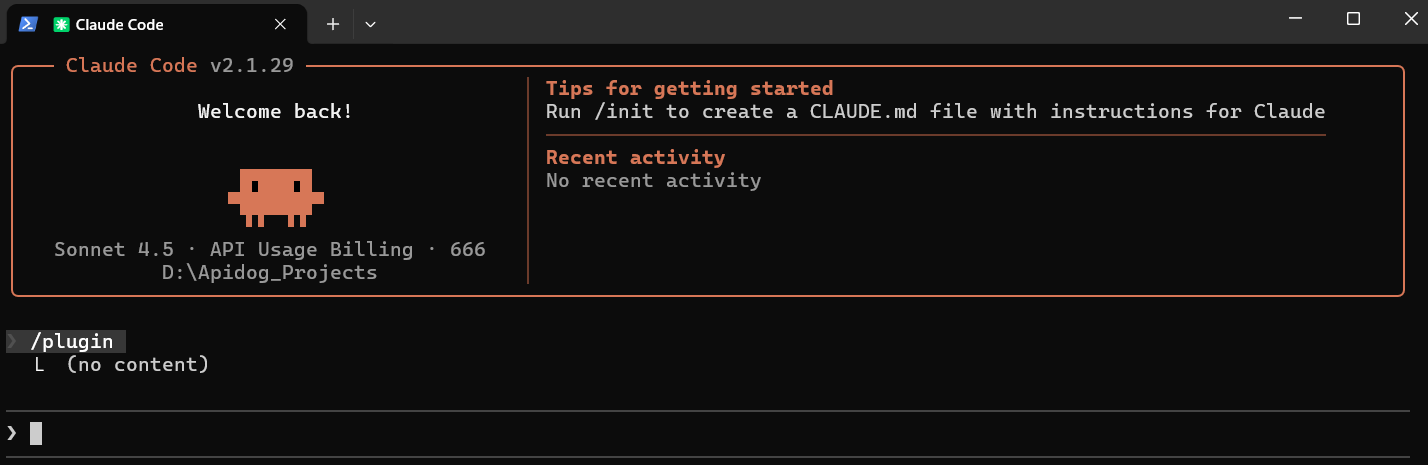
Instalación Rápida
Instala Claude-mem directamente desde el marketplace de plugins con dos comandos:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
Reinicia Claude Code después de la instalación. El plugin descarga automáticamente binarios precompilados, instala dependencias incluyendo Bun y SQLite, configura hooks para la gestión del ciclo de vida de la sesión y auto-inicia el servicio de worker en tu primera sesión.
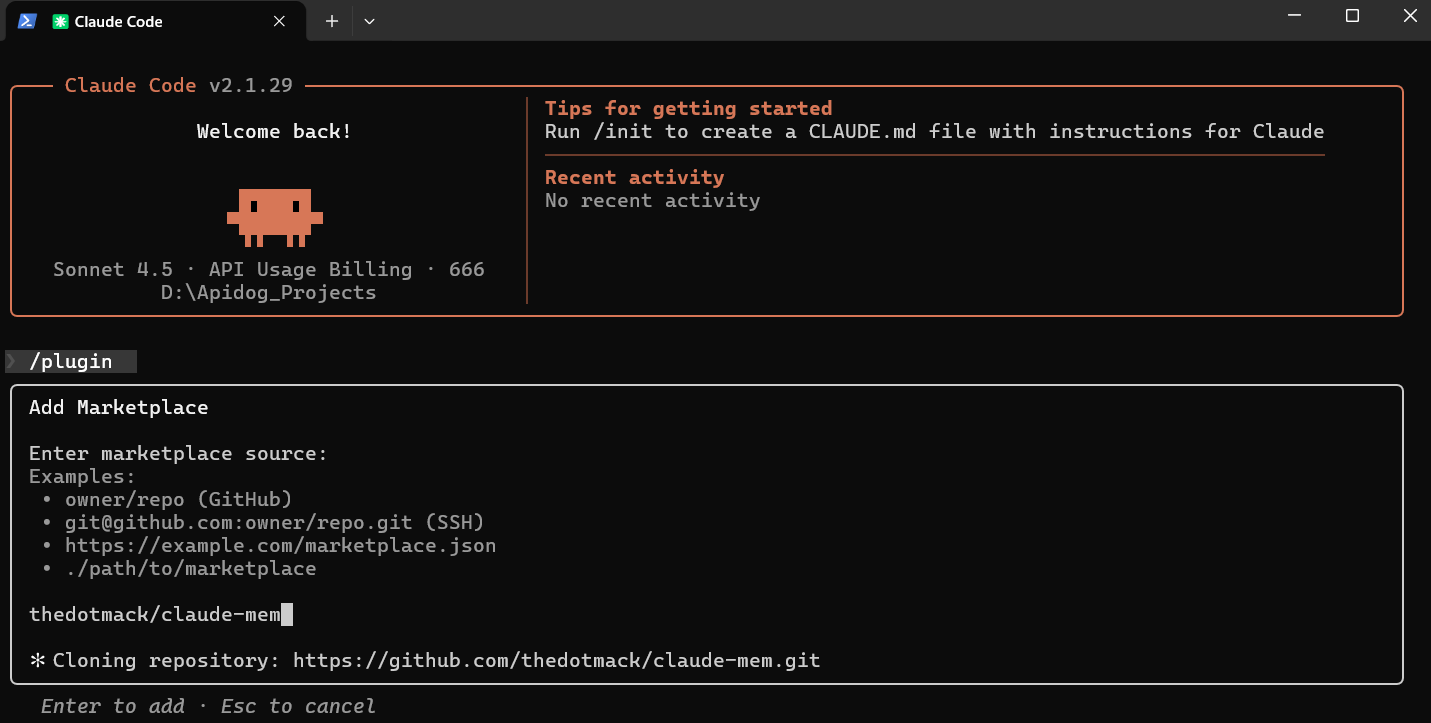
Instalación Avanzada desde el Código Fuente
Para desarrollo o pruebas, clona y compila desde la fuente en github:
git clone https://github.com/thedotmack/claude-mem.git
cd claude-mem
npm install
npm run build
npm run worker:start
Este enfoque es útil si necesitas modificar el plugin o ejecutar características beta como el Modo Infinito.

Verificación Post-Instalación
Después de la instalación, verifica que todo funcione:
- Verificar la instalación del plugin:
cat plugin/hooks/hooks.json
- Verificar que el servicio de worker esté en ejecución:
curl http://localhost:37777/api/health
- Ver los registros recientes del worker:
npm run worker:logs
Prueba la recuperación de contexto iniciando una nueva sesión de Claude Code. Deberías ver el contexto de sesiones anteriores cargado automáticamente en el prompt inicial.
Almacenamiento y Configuración de Datos
Claude-mem almacena todos los datos localmente en ~/.claude-mem/:
- Base de datos:
~/.claude-mem/claude-mem.db(SQLite con búsqueda FTS5) - Archivo PID:
~/.claude-mem/.worker.pid - Archivo de puerto:
~/.claude-mem/.worker.port - Registros:
~/.claude-mem/logs/worker-YYYY-MM-DD.log - Configuración:
~/.claude-mem/settings.json
Anula el directorio de datos predeterminado con una variable de entorno:
export CLAUDE_MEM_DATA_DIR=/custom/path
Opciones de Configuración
La configuración se gestiona en ~/.claude-mem/settings.json (creado automáticamente en la primera ejecución). Las configuraciones clave incluyen:
CLAUDE_MEM_CONTEXT_OBSERVATIONS: Número de observaciones inyectadas al inicio de la sesión (predeterminado: 50)CLAUDE_MEM_FOLDER_INDEX_ENABLED: Habilitar/deshabilitar archivos CLAUDE.md generados automáticamente en carpetas- Selección de modelo para compresión asistida por IA
- Configuración del puerto y host del worker
- Configuración del nivel de registro
Cómo Claude-mem Captura y Procesa el Contexto
Cuando usas Claude Code con claude-mem habilitado, el sistema captura automáticamente cada invocación de herramienta. Ya sea que Claude lea un archivo, ejecute un comando bash, busque con patrones glob o edite código, claude-mem observa la entrada y la salida.
El servicio de worker procesa estas observaciones y extrae:
- Título: Descripción breve de lo que sucedió
- Subtítulo: Contexto adicional
- Narrativa: Explicación detallada de la actividad
- Hechos: Aprendizajes clave como puntos clave
- Conceptos: Etiquetas y categorías relevantes para la búsqueda
- Tipo: Clasificación (decisión, corrección de errores, característica, refactorización, descubrimiento, cambio)
- Archivos: Qué archivos fueron leídos o modificados
Esta compresión ocurre automáticamente sin intervención manual. La salida de la herramienta sin procesar podría ser de 5,000 tokens, pero la observación semántica almacenada en la base de datos es de aproximadamente 500 tokens, preservando el significado y eliminando el ruido.
Resúmenes de Sesión
Cuando Claude termina de responder (activando el hook de Stop), claude-mem genera automáticamente un resumen de sesión que contiene:
- Solicitud: Lo que pediste
- Investigado: Lo que Claude exploró para responder
- Aprendido: Descubrimientos e ideas clave
- Completado: Lo que se logró
- Próximos pasos: Acciones de seguimiento recomendadas
Estos resúmenes se inyectan en sesiones futuras junto con observaciones individuales, proporcionando tanto detalles granulares como un contexto narrativo de alto nivel.
Uso de las Herramientas de Búsqueda MCP para Consultar tu Memoria
Claude-mem expone cuatro herramientas MCP que siguen un patrón de flujo de trabajo de 3 capas eficiente en tokens. Este diseño recupera el contexto progresivamente, minimizando el uso de tokens y maximizando la relevancia.
El Flujo de Trabajo de 3 Capas
search: Obtén un índice compacto con IDs (aproximadamente 50-100 tokens por resultado)timeline: Obtén contexto cronológico alrededor de resultados interesantesget_observations: Recupera detalles completos SÓLO para IDs filtrados (aproximadamente 500-1,000 tokens por resultado)
Este enfoque logra aproximadamente un ahorro de 10 veces en tokens al filtrar antes de recuperar los detalles completos.
Herramientas MCP Disponibles
search: Busca en el índice de memoria con consultas de texto completo. Filtra por tipo, fecha o proyecto.timeline: Obtén contexto cronológico alrededor de una observación o consulta específica. Útil para entender qué llevó a una decisión o corrección de errores en particular.get_observations: Recupera los detalles completos de las observaciones por IDs. Agrupa siempre múltiples IDs en una sola llamada para minimizar la sobrecarga.__IMPORTANT: Documentación del flujo de trabajo que siempre es visible para Claude, explicando cómo usar el sistema de memoria de manera efectiva.
Patrones de Uso de Ejemplo
Encuentra una corrección de error específica:
// Step 1: Search for the bug
search(query="authentication bug", type="bugfix", limit=10)
// Step 2: Review index, identify relevant IDs (e.g., #123, #456)
// Step 3: Fetch full details for relevant observations
get_observations(ids=[123, 456])
Explora decisiones arquitectónicas recientes:
search(query="database schema", type="decision", limit=5)
Encuentra todo lo relacionado con un archivo específico:
search(query="worker-service.ts", limit=20)
Consultas en Lenguaje Natural
Puedes preguntarle a Claude de forma natural sobre el historial de tu proyecto:
- "¿Qué decidimos sobre el manejo de errores?"
- "¿Cómo implementamos la autenticación?"
- "¿Qué errores corregimos en la capa de la API?"
- "Muéstrame los cambios en el esquema de la base de datos"
Claude invoca automáticamente las herramientas MCP adecuadas para recuperar el contexto relevante, presentando los hallazgos con citaciones URI claude-mem:// que hacen referencia a observaciones específicas.
Archivos de Contexto de Carpeta y Auto-Generación de CLAUDE.md
Claude-mem genera automáticamente archivos CLAUDE.md en las carpetas del proyecto, creando líneas de tiempo de actividad que complementan la base de datos de memoria global.
Cómo Funciona el Contexto de Carpeta
Cuando trabajas con archivos en una carpeta, claude-mem:
- Identifica rutas de carpeta únicas a partir de los archivos modificados
- Consulta observaciones recientes relevantes para cada carpeta
- Genera una línea de tiempo de actividad formateada
- Lo escribe en CLAUDE.md en esa carpeta (dentro de las etiquetas
<claude-mem-context>)
El archivo CLAUDE.md de cada carpeta contiene una sección de Actividad Reciente que muestra los IDs de observación, marcas de tiempo, indicadores de tipo (correcciones de errores, características, descubrimientos), títulos breves y recuentos estimados de tokens.
Preservación del Contenido del Usuario
El contenido autogenerado se envuelve en etiquetas <claude-mem-context>. Cualquier contenido que escribas fuera de estas etiquetas se conserva cuando el archivo se regenera. Esto te permite:
- Añadir tu propia documentación encima o debajo de la sección generada
- Escribir instrucciones específicas de la carpeta para Claude
- Incluir notas o convenciones arquitectónicas
Estructura de ejemplo de CLAUDE.md:
# Authentication Module
This folder contains all authentication-related code.
Follow the established patterns for new auth providers.
<claude-mem-context>
# Recent Activity
| ID | Time | Type | Title | Tokens |
|----|------|------|-------|--------|
| #1234 | 4:30 PM | 🔵 | Implemented user authentication | ~250 |
| #1235 | 4:45 PM | 🔴 | Fixed login redirect bug | ~180 |
</claude-mem-context>
## Manual Notes
- OAuth providers go in /providers/
- Session handling uses Redis
Controles de Privacidad y Seguridad
Claude-mem proporciona controles de privacidad granulares para evitar que datos sensibles entren en el sistema de memoria.
Etiquetas de Contenido Privado
Envuelve el contenido sensible en etiquetas <private> para excluirlo del almacenamiento:
<private>
API_KEY=sk-live-abc123xyz789
DATABASE_PASSWORD=supersecret456
</private>
El procesamiento en el borde asegura que el contenido privado nunca llegue a la base de datos. Esto es crítico para claves de API, credenciales y lógica propietaria.
Sistema de Privacidad de Doble Etiqueta
Claude-mem utiliza un enfoque de doble etiqueta:
<private>: Privacidad controlada por el usuario para contenido sensible<claude-mem-context>: Etiquetas a nivel de sistema que evitan el almacenamiento recursivo de observaciones
Interfaz de Usuario del Visor Web y Monitoreo en Tiempo Real
Claude-mem ejecuta un visor web en http://localhost:37777 para la visualización en tiempo real del flujo de memoria. La interfaz muestra:
- Flujo de observación en vivo con indicadores de emoji para la importancia
- Línea de tiempo de la sesión con marcadores cronológicos
- Interfaz de búsqueda para consultar recuerdos
- Panel de configuración para ajustes
- Cambio de versión entre canales estables y beta
Esta interfaz de usuario es opcional para el uso básico, pero invaluable para comprender lo que claude-mem captura y cómo organiza tu historial de desarrollo.
Características Beta: Modo Infinito
El canal beta ofrece el Modo Infinito, una arquitectura de memoria biomimética para sesiones extendidas. En lugar de alcanzar los límites de contexto después de 50 usos de herramientas, el Modo Infinito promete aproximadamente 1,000 usos, un aumento de 20 veces. Esto lo logra comprimiendo las salidas de las herramientas en tiempo real, reduciendo los tokens en aproximadamente un 95% y cambiando la escalabilidad de O(N²) cuadrática a O(N) lineal.
Compensación: La generación de observaciones añade entre 60 y 90 segundos por invocación de herramienta. Para sesiones de codificación profundas y reflexivas que abarcan días o semanas, esta latencia podría ser aceptable. Para un uso rápido de herramientas, podría ser prohibitiva.
Habilita las características beta desde la interfaz de usuario del visor web en http://localhost:37777 → Configuración → Canal de Versión.
Resolución de Problemas Comunes
El Servicio de Worker No Se Inicia
Si el worker no se inicia en el puerto 37777:
- Verifica si el puerto ya está ocupado:
lsof -i :37777
- Configura un puerto alternativo:
export CLAUDE_MEM_WORKER_PORT=8080
- Inicia manualmente el worker:
bun plugin/scripts/worker-service.cjs
La Memoria No Se Guarda
Si Claude no recuerda sesiones anteriores:
- Verifica que el worker esté en ejecución:
npm run worker:status
- Verifica que el archivo de la base de datos exista:
ls -la ~/.claude-mem/claude-mem.db
- Revisa los registros del worker en busca de errores:
npm run worker:logs
Problemas de Inyección de Contexto
Si aparece demasiado o muy poco contexto al inicio de la sesión:
Ajusta el límite de observación:
export CLAUDE_MEM_CONTEXT_OBSERVATIONS=10 # Reduce
export CLAUDE_MEM_CONTEXT_OBSERVATIONS=100 # Increase
Archivos CLAUDE.md Vacíos
Si claude-mem crea archivos CLAUDE.md vacíos en tu proyecto, es un problema conocido en la versión 9.0.5. Las soluciones temporales actuales incluyen eliminar manualmente los directorios creados, añadir patrones a .gitignore o esperar la corrección en una versión posterior.
Integración con Claude Desktop
Claude-mem funciona con Claude Desktop a través de la configuración del servidor MCP. Añade el servidor mcp-search a tu configuración de Claude Desktop, apunta al script del servidor MCP en la instalación de claude-mem y reinicia Claude Desktop.
Una vez configurado, pregunta de forma natural sobre trabajos anteriores:
- "¿Qué hicimos la última sesión?"
- "¿Corregimos este error antes?"
- "¿Cómo implementamos la autenticación?"
Usa el visor web en localhost:37777 para verificar que las memorias se están capturando y revisa los registros de Claude Desktop si la conexión falla.
Comandos Manuales de Gestión de Workers
Desde el directorio de claude-mem, puedes gestionar el servicio de worker:
npm run worker:start # Iniciar servicio de worker
npm run worker:stop # Detener servicio de worker
npm run worker:restart # Reiniciar servicio de worker
npm run worker:logs # Ver registros del worker
npm run worker:status # Verificar estado del worker
Conclusión
Claude-mem transforma Claude Code de un asistente sin estado a un socio de desarrollo persistente que acumula conocimiento sobre tu base de código con el tiempo. Al capturar automáticamente el uso de herramientas, comprimir observaciones en memorias buscables y recuperar de forma inteligente el contexto relevante, elimina la repetitiva construcción de contexto que ralentiza el desarrollo asistido por IA.
La arquitectura de divulgación progresiva del sistema —recuperación en capas con herramientas MCP, archivos CLAUDE.md basados en carpetas y controles de privacidad— proporciona aproximadamente 10 veces la eficiencia de tokens en comparación con la gestión manual del contexto, manteniendo al mismo tiempo la localidad y seguridad completas de los datos.
Al construir APIs o trabajar con servicios externos en tu flujo de trabajo mejorado con Claude-mem, agiliza tus pruebas con Apidog. Ofrece pruebas de API visuales, generación automática de documentación y depuración colaborativa que complementa tu configuración de memoria persistente.