
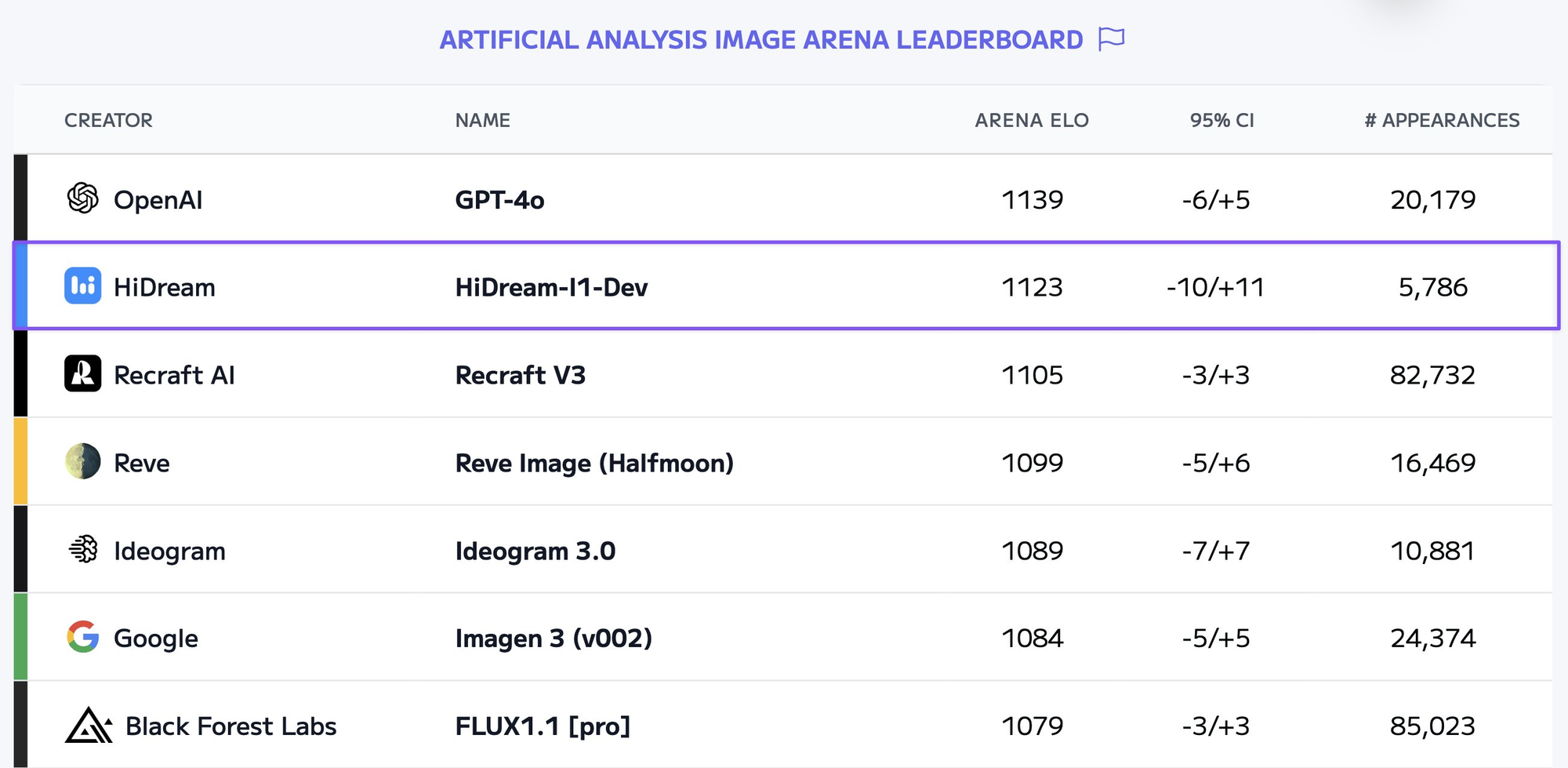
Parece que cada semana recibimos nuevos modelos de generación de imágenes con IA capaces de crear visuales impresionantes. Uno de esos modelos poderosos es HiDream-I1-Full. Aunque ejecutar estos modelos de forma local puede ser intensivo en recursos, aprovechar las API proporciona una forma conveniente y escalable de integrar esta tecnología en sus aplicaciones o flujos de trabajo.
Este tutorial te guiará a través de:
- Comprender HiDream-I1-Full: Qué es y sus capacidades.
- Opciones de API: Explorando dos plataformas populares que ofrecen HiDream-I1-Full a través de API: Replicate y Fal.ai.
- Pruebas con Apidog: Una guía paso a paso sobre cómo interactuar y probar estas API utilizando la herramienta Apidog.
¿Quieres una plataforma integrada, todo en uno, para que tu equipo de desarrolladores trabaje junto con máxima productividad?
¡Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!
Público objetivo: Desarrolladores, diseñadores, entusiastas de la IA y cualquier persona interesada en utilizar generación de imágenes de IA avanzada sin configuraciones locales complejas.
Requisitos previos:
- Comprensión básica de APIs (solicitudes HTTP, JSON).
- Una cuenta en Replicate y/o Fal.ai para obtener claves de API.
- Apidog instalado (o acceso a su versión web).
¿Qué es HiDream-I1-Full?

HiDream-I1-Full es un modelo avanzado de difusión de texto a imagen desarrollado por HiDream AI. Pertenece a la familia de modelos diseñados para generar imágenes de alta calidad, coherentes y estéticamente agradables basadas en descripciones textuales (prompts).

Detalles del modelo: Puedes encontrar la tarjeta oficial del modelo y más información técnica en Hugging Face: https://huggingface.co/HiDream-ai/HiDream-I1-Full
Capacidades clave (típicas para modelos de esta clase):
- Generación de Texto a Imagen: Crea imágenes a partir de prompts de texto detallados.
- Alta Resolución: Capaz de generar imágenes a resoluciones razonablemente altas adecuadas para diversas aplicaciones.
- Adherencia al Estilo: A menudo puede interpretar pistas estilísticas dentro del prompt (por ejemplo, "al estilo de Van Gogh", "fotorrealista", "anime").
- Composición de Escenas Complejas: Capacidad para generar imágenes con múltiples sujetos, interacciones y fondos detallados según la complejidad del prompt.
- Parámetros de Control: A menudo permite ajustes finos a través de parámetros como prompts negativos (cosas a evitar), semillas (para reproducibilidad), escala de guía (qué tan fuerte seguir el prompt) y, potencialmente, variaciones de imagen a imagen o entradas de control (dependiendo de la implementación específica de la API).
¿Por qué usar una API?
Ejecutar grandes modelos de IA como HiDream-I1-Full de forma local requiere recursos computacionales significativos (GPUs potentes, RAM abundante y almacenamiento) y configuración técnica (gestionar dependencias, pesos de modelo, configuraciones de entorno). Usar una API ofrece varias ventajas:
- Sin Requisitos de Hardware: Descarga el cálculo a una potente infraestructura en la nube.
- Escalabilidad: Maneja fácilmente cargas variables sin gestionar infraestructura.
- Facilidad de Integración: Integra capacidades de generación de imágenes en sitios web, aplicaciones o scripts usando solicitudes HTTP estándar.
- Sin Mantenimiento: El proveedor de la API maneja actualizaciones de modelos, mantenimiento y gestión del backend.
- Pago por Uso: A menudo, solo pagas por el tiempo de computación que utilizas.
Cómo usar HiDream-I1-Full a través de API
Varias plataformas alojan modelos de IA y proporcionan acceso a API. Nos centraremos en dos opciones populares para HiDream-I1-Full:
Opción 1: Usar la API HiDream de Replicate
Replicate es una plataforma que facilita ejecutar modelos de aprendizaje automático a través de una API sencilla, sin necesidad de gestionar infraestructura. Alojan una vasta biblioteca de modelos publicados por la comunidad.
- Página de Replicate para HiDream-I1-Full: https://replicate.com/prunaai/hidream-l1-full (Nota: La URL menciona
l1-full, pero es el enlace relevante proporcionado en el prompt para el modelo HiDream en Replicate. Supón que corresponde al modelo destinado para este tutorial).
Cómo funciona Replicate:
- Autenticación: Necesitas un token de API de Replicate, que puedes encontrar en la configuración de tu cuenta. Este token se pasa en el encabezado
Authorization. - Iniciar una Predicción: Envías una solicitud POST al endpoint de API de Replicate para predicciones. El cuerpo de la solicitud contiene la versión del modelo y los parámetros de entrada (como
prompt,negative_prompt,seed, etc.). - Operación Asincrónica: Replicate normalmente opera de forma asincrónica. La solicitud POST inicial devuelve inmediatamente un ID de predicción y URLs para comprobar el estado.
- Obtener Resultados: Necesitas consultar la URL de estado (proporcionada en la respuesta inicial) usando solicitudes GET hasta que el estado sea
succeeded(ofailed). La respuesta final exitosa contendrá la(s) URL(s) de la(s) imagen(es) generada(s).
Ejemplo Conceptual en Python (usando requests):
import requests
import time
import os
REPLICATE_API_TOKEN = "TU_TOKEN_API_REPLICATE" # Usa variables de entorno en producción
MODEL_VERSION = "VERSION_DEL_MODELO_OBJETIVO_DE_LA_PAGINA_REPLICATE" # por ejemplo, "9a0b4534..."
# 1. Iniciar Predicción
headers = {
"Authorization": f"Token {REPLICATE_API_TOKEN}",
"Content-Type": "application/json"
}
payload = {
"version": MODEL_VERSION,
"input": {
"prompt": "Un paisaje urbano ciberpunk majestuoso al atardecer, luces de neón reflejándose en calles mojadas, ilustración detallada",
"negative_prompt": "feo, deformado, borroso, baja calidad, texto, marca de agua",
"width": 1024,
"height": 1024,
"seed": 12345
# Agrega otros parámetros según sea necesario basándote en la página del modelo de Replicate
}
}
start_response = requests.post("<https://api.replicate.com/v1/predictions>", json=payload, headers=headers)
start_response_json = start_response.json()
if start_response.status_code != 201:
print(f"Error al iniciar la predicción: {start_response_json.get('detail')}")
exit()
prediction_id = start_response_json.get('id')
status_url = start_response_json.get('urls', {}).get('get')
print(f"Predicción iniciada con ID: {prediction_id}")
print(f"URL de estado: {status_url}")
# 2. Consultar Resultados
output_image_url = None
while True:
print("Comprobando estado...")
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status')
if status == 'succeeded':
output_image_url = status_response_json.get('output') # Generalmente una lista de URLs
print("¡Predicción exitosa!")
print(f"Salida: {output_image_url}")
break
elif status == 'failed' or status == 'canceled':
print(f"La predicción falló o fue cancelada: {status_response_json.get('error')}")
break
elif status in ['starting', 'processing']:
# Espera antes de consultar nuevamente
time.sleep(5) # Ajusta el intervalo de consulta según sea necesario
else:
print(f"Estado desconocido: {status}")
print(status_response_json)
break
# Ahora puedes usar output_image_url
Precios: Replicate cobra según el tiempo de ejecución del modelo en su hardware. Consulta su página de precios para más detalles.
Opción 2: Fal.ai
Fal.ai es otra plataforma centrada en proporcionar inferencias rápidas, escalables y rentables para modelos de IA a través de API. A menudo enfatizan el rendimiento en tiempo real.
Cómo Funciona Fal.ai:
- Autenticación: Necesitas credenciales de API de Fal (ID de clave y clave secreta, a menudo combinadas como
KeyID:KeySecret). Esto se pasa en el encabezadoAuthorization, típicamente comoKey TuKeyID:TuKeySecret. - Endpoint de API: Fal.ai proporciona una URL de endpoint directa para la función específica del modelo.
- Formato de Solicitud: Envías una solicitud POST a la URL del endpoint del modelo. El cuerpo de la solicitud es típicamente JSON que contiene los parámetros de entrada requeridos por el modelo (similar a Replicate:
prompt, etc.). - Síncrono vs. Asincrónico: Fal.ai puede ofrecer ambos. Para tareas que pueden tardar mucho tiempo, como la generación de imágenes, pueden usar:
- Funciones sin servidor: Un ciclo de solicitud/respuesta estándar, posiblemente con tiempos de espera más largos.
- Colas: Un patrón asincrónico similar a Replicate, donde envías un trabajo y consultas resultados usando un ID de solicitud. La página específica de la API vinculada detallará el patrón de interacción esperado.
Ejemplo Conceptual en Python (usando requests - asumiendo cola asincrónica):
import requests
import time
import os
FAL_API_KEY = "TU_FAL_KEY_ID:TU_FAL_KEY_SECRET" # Usa variables de entorno
MODEL_ENDPOINT_URL = "<https://fal.run/fal-ai/hidream-i1-full>" # Consulta la URL exacta en Fal.ai
# 1. Enviar Solicitud a la Cola (Ejemplo - consulta la documentación de Fal para la estructura exacta)
headers = {
"Authorization": f"Key {FAL_API_KEY}",
"Content-Type": "application/json"
}
payload = {
# Los parámetros suelen estar directamente en el payload para funciones sin servidor de Fal.ai
# o dentro de un objeto 'input' dependiendo de la configuración. ¡Consulta la documentación!
"prompt": "Un retrato hiperrealista de un astronauta flotando en el espacio, reflejando la Tierra en la visera del casco",
"negative_prompt": "dibujo, ilustración, boceto, texto, letras",
"seed": 98765
# Agrega otros parámetros admitidos por la implementación de Fal.ai
}
# Fal.ai podría requerir agregar '/queue' o parámetros de consulta específicos para asincrónico
# Ejemplo: POST <https://fal.run/fal-ai/hidream-i1-full/queue>
# ¡Consulta su documentación! Suponiendo un endpoint que devuelve una URL de estado:
submit_response = requests.post(f"{MODEL_ENDPOINT_URL}", json=payload, headers=headers, params={"fal_webhook": "URL_WEBHOOK_OPCIONAL"}) # Consulta la documentación para parámetros de consulta como webhook
if submit_response.status_code >= 300:
print(f"Error al enviar la solicitud: {submit_response.status_code}")
print(submit_response.text)
exit()
submit_response_json = submit_response.json()
# La respuesta asincrónica de Fal.ai podría diferir - podría devolver un request_id o una URL de estado directa
# Suponiendo que devuelve una URL de estado similar a Replicate para este ejemplo conceptual
status_url = submit_response_json.get('status_url') # O construir desde request_id, consulta la documentación
request_id = submit_response_json.get('request_id') # Identificador alternativo
if not status_url and request_id:
# Puede que necesites construir la URL de estado, por ejemplo, <https://fal.run/fal-ai/hidream-i1-full/requests/{request_id}/status>
# O consultar un endpoint de estado genérico: <https://fal.run/requests/{request_id}/status>
print("Necesitas construir la URL de estado o usar request_id, consulta la documentación de Fal.ai.")
exit() # Necesita implementación específica según la documentación de Fal
print(f"Solicitud enviada. URL de estado: {status_url}")
# 2. Consultar Resultados (si es asincrónico)
output_data = None
while status_url: # Solo consulta si tenemos una URL de estado
print("Comprobando estado...")
# La consulta podría requerir autenticación también
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status') # Consulta la documentación de Fal.ai para claves de estado ('COMPLETED', 'FAILED', etc.)
if status == 'COMPLETED': # Estado de ejemplo
output_data = status_response_json.get('response') # O 'result', 'output', consulta la documentación
print("¡Solicitud completada!")
print(f"Salida: {output_data}") # La estructura de salida depende del modelo en Fal.ai
break
elif status == 'FAILED': # Estado de ejemplo
print(f"La solicitud falló: {status_response_json.get('error')}") # Consulta el campo de error
break
elif status in ['IN_PROGRESS', 'IN_QUEUE']: # Estados de ejemplo
# Espera antes de consultar nuevamente
time.sleep(3) # Ajusta el intervalo de consulta
else:
print(f"Estado desconocido: {status}")
print(status_response_json)
break
# Usa output_data (que podría contener URLs de imágenes u otra información)
Precios: Fal.ai típicamente cobra según el tiempo de ejecución, a menudo con facturación por segundo. Consulta sus detalles de precios para el modelo específico y los recursos de computación.
Prueba la API HiDream con Apidog
Apidog es una poderosa herramienta de diseño, desarrollo y pruebas de API. Proporciona una interfaz fácil de usar para enviar solicitudes HTTP, inspeccionar respuestas y gestionar detalles de la API, lo que la hace ideal para probar las APIs de Replicate y Fal.ai antes de integrarlas en el código.
Pasos para probar la API HiDream-I1-Full usando Apidog:
Paso 1. Instalar y abrir Apidog: Descarga e instala Apidog o usa su versión web. Crea una cuenta si es necesario.

Paso 2. Crear una nueva solicitud:
- En Apidog, crea un nuevo proyecto o abre uno existente.
- Haz clic en el botón "+" para agregar una nueva solicitud HTTP.
Paso 3. Establecer el método HTTP y la URL:
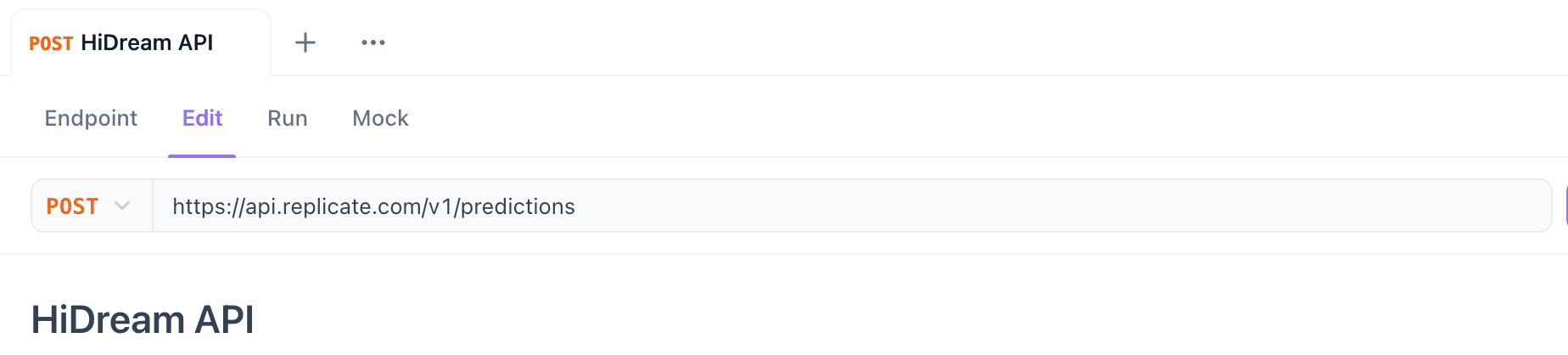
- Método: Selecciona
POST. - URL: Ingresa la URL del endpoint de API.
- Para Replicate (Iniciar Predicción):
https://api.replicate.com/v1/predictions - Para Fal.ai (Enviar Solicitud): Usa la URL de endpoint del modelo específico proporcionada en su página (por ejemplo,
https://fal.run/fal-ai/hidream-i1-full- verifica si necesita/queueo parámetros de consulta para asincrónico).
Paso 4. Configurar Encabezados:
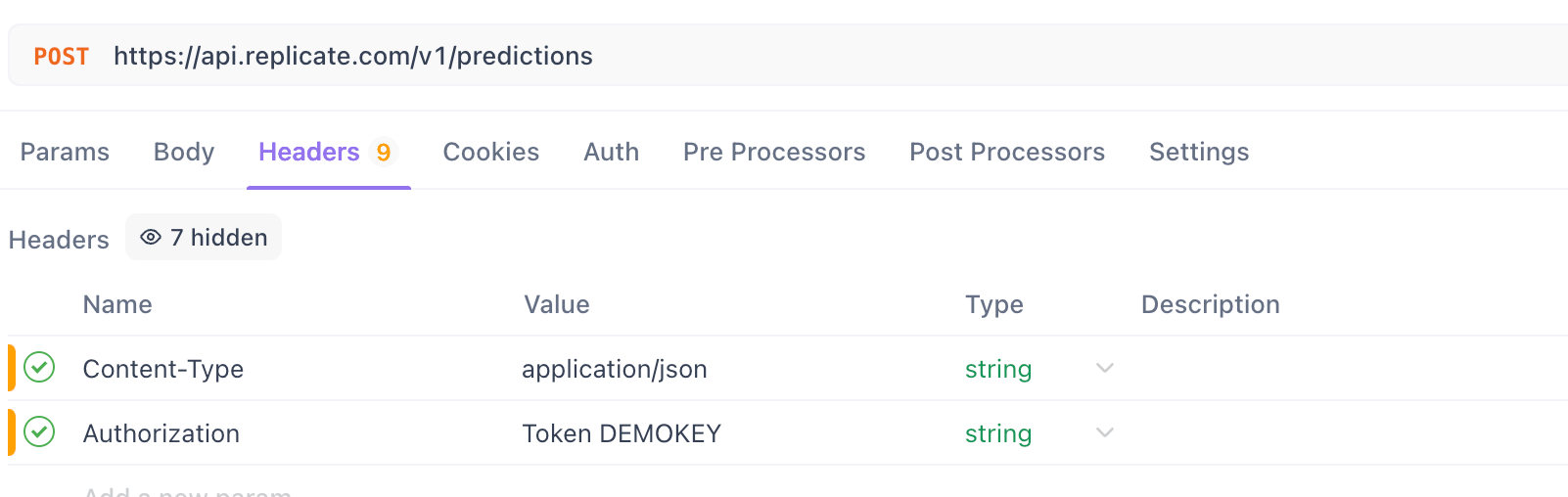
- Ve a la pestaña
Headers.
Agregar el encabezado Content-Type:
- Clave:
Content-Type - Valor:
application/json
Agregar el encabezado Authorization:
Para Replicate:
- Clave:
Authorization - Valor:
Token TU_TOKEN_API_REPLICATE(Reemplaza con tu token real)
Para Fal.ai:
- Clave:
Authorization - Valor:
Key TU_FAL_KEY_ID:TU_FAL_KEY_SECRET(Reemplaza con tus credenciales reales) - Consejo Profesional: Usa las variables de entorno de Apidog para almacenar tus claves de API de forma segura en lugar de codificarlas directamente en la solicitud. Crea un entorno (por ejemplo, "Replicate Dev", "Fal Dev") y define variables como
REPLICATE_TOKENoFAL_API_KEY. Luego, en el valor del encabezado, usaToken {{REPLICATE_TOKEN}}oKey {{FAL_API_KEY}}.
Paso 5. Configurar el cuerpo de la solicitud:
Ve a la pestaña Body.
Selecciona el formato raw y elige JSON del menú desplegable.
Pega el payload JSON según los requisitos de la plataforma.
Ejemplo de cuerpo JSON para Replicate:
{
"version": "PEGA_LA_VERSION_DEL_MODELO_DE_LA_PAGINA_REPLICATE_AQUI",
"input": {
"prompt": "Una pintura en acuarela de un acogedor rincón de biblioteca con un gato durmiendo",
"negative_prompt": "fotorrealista, renderizado 3d, arte malo, deformado",
"width": 1024,
"height": 1024,
"seed": 55555
}
}
Ejemplo de cuerpo JSON para Fal.ai
{
"prompt": "Una pintura en acuarela de un acogedor rincón de biblioteca con un gato durmiendo",
"negative_prompt": "fotorrealista, renderizado 3d, arte malo, deformado",
"width": 1024,
"height": 1024,
"seed": 55555
// Otros parámetros como 'model_name' pueden ser necesarios dependiendo de la configuración de Fal.ai
}
Importante: Consulta la documentación específica en las páginas de Replicate o Fal.ai para los parámetros exactos requeridos y opcionales para la versión del modelo HiDream-I1-Full que estás utilizando. Parámetros como guidance_scale, num_inference_steps, etc., pueden estar disponibles.
Paso 6. Enviar la solicitud:
- Haz clic en el botón "Enviar".
- Apidog mostrará el código de estado de la respuesta, los encabezados y el cuerpo.
- Para Replicate: Deberías obtener un estado
201 Creado. El cuerpo de la respuesta contendrá elidde la predicción y una URLurls.get. Copia esta URLget. - Para Fal.ai (Asincrónico): Podrías obtener un
200 OKo202 Aceptado. El cuerpo de la respuesta podría contener unrequest_id, unastatus_urldirecta u otros detalles según su implementación. Copia la URL o ID relevante necesario para la consulta. Si es síncrono, podrías obtener el resultado directamente después del procesamiento (menos probable para la generación de imágenes).
Consultar Resultados (para APIs Asincrónicas):
- Crea otra nueva solicitud en Apidog.
- Método: Selecciona
GET. - URL: Pega la
URL de estadoque copiaste de la respuesta inicial (por ejemplo, laurls.getde Replicate o la URL de estado de Fal.ai). Si Fal.ai te dio unrequest_id, construye la URL de estado de acuerdo a su documentación (por ejemplo,https://fal.run/requests/{request_id}/status). - Configurar Encabezados: Agrega el mismo encabezado
Authorizationque en la solicitud POST. (Content-Type generalmente no es necesario para GET). - Enviar la Solicitud: Haz clic en "Enviar".
- Inspeccionar Respuesta: Verifica el campo
statusen la respuesta JSON. - Si
processing,starting,IN_PROGRESS,IN_QUEUE, etc., espera unos segundos y haz clic en "Enviar" nuevamente. - Si
succeededoCOMPLETED, busca el campooutput(Replicate) o el camporesponse/result(Fal.ai) que debería contener la(s) URL(s) de tu(s) imagen(es) generada(s). - Si
failedoFAILED, consulta el campoerrorpara más detalles.
Ver la Imagen: Copia la URL de la imagen de la respuesta final exitosa y pégala en tu navegador web para ver la imagen generada.
¿Quieres una plataforma integrada, todo en uno, para que tu equipo de desarrolladores trabaje junto con máxima productividad?
¡Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!

Conclusión
HiDream-I1-Full ofrece potentes capacidades de generación de imágenes, y usar APIs de plataformas como Replicate o Fal.ai hace que esta tecnología sea accesible sin gestionar infraestructura compleja. Al comprender el flujo de trabajo de la API (solicitud, posible consulta, respuesta) y utilizar herramientas como Apidog para pruebas, puedes experimentar e integrar fácilmente la generación de imágenes de IA de vanguardia en tus proyectos.
Recuerda siempre consultar la documentación específica en Replicate y Fal.ai para obtener las URL de endpoint más actualizadas, los parámetros requeridos, los métodos de autenticación y los detalles de precios, ya que estos pueden cambiar con el tiempo. ¡Feliz generación!