
Elegir la estrategia de gestión de datos adecuada es esencial para lograr el éxito en tus proyectos. La eficacia de tus aplicaciones a menudo depende de lo bien que puedas gestionar y recuperar los datos.
En este artículo, profundizaremos en las diferencias clave y los beneficios de GraphQL y SQL, dos enfoques potentes que satisfacen diferentes necesidades de datos. Al comprender sus características únicas, puedes tomar decisiones informadas que se ajusten a los requisitos de tu aplicación y mejoren su rendimiento. ¡Únete a nosotros mientras desentrañamos las complejidades de cada método, allanando el camino para una gestión de datos más inteligente y eficiente!
Haz clic en el botón Download y transforma tu conectividad de SQL Server hoy mismo. 🚀🌟
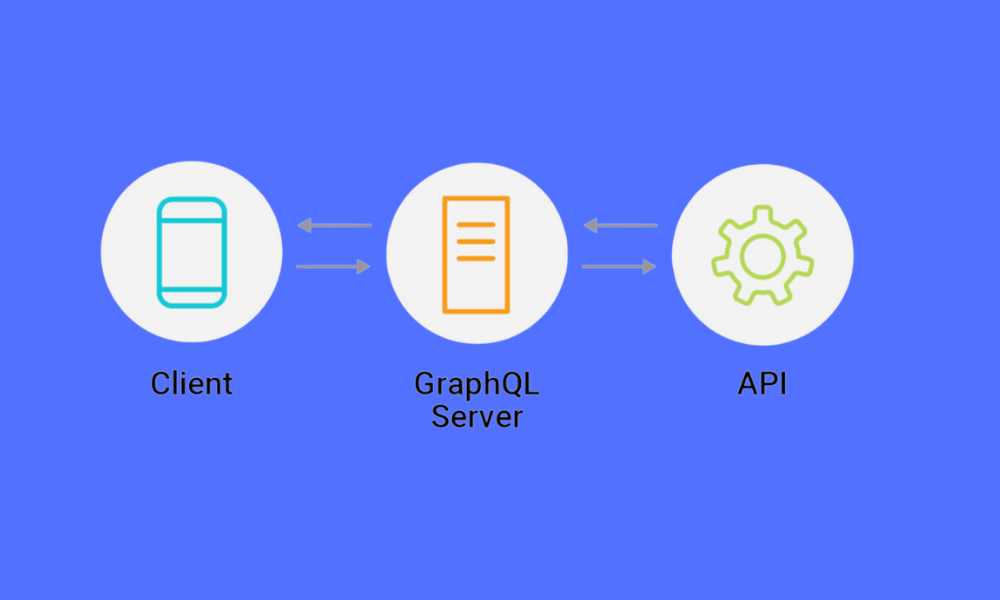
¿Qué es GraphQL?
GraphQL es un lenguaje de consulta desarrollado por Facebook para las API, así como un tiempo de ejecución para ejecutar esas consultas mediante un sistema de tipos definido para tus datos. No es una tecnología de base de datos, sino una forma de interactuar con los datos a través de las API.
type Query {
user(id: ID!): User
}
type User {
id: ID!
name: String
email: String
}
# Query
{
user(id: "123") {
name
email
}
}
Características clave de GraphQL
- Consultas específicas del cliente: Permite a los clientes solicitar exactamente los datos que necesitan, incluso con estructuras profundamente anidadas.
- Punto de conexión único: Utiliza un único punto de conexión de API y aprovecha las consultas para obtener diversas formas de datos.
- Datos en tiempo real con suscripciones: Admite actualizaciones de datos en tiempo real a través de suscripciones.
- Disminución del exceso de búsqueda: Reduce la transferencia innecesaria de datos al permitir que los clientes especifiquen exactamente lo que necesitan.
¿Por qué usar GraphQL en tu aplicación?
Usar GraphQL en una aplicación puede proporcionar una serie de beneficios, especialmente para las aplicaciones basadas en datos que dependen de una búsqueda de datos eficiente y flexible. Usemos un ejemplo de una plataforma de blogs para ilustrar los beneficios de GraphQL.
Escenario: Creación de una API de blog
Imagina que estás desarrollando una aplicación de blog con las siguientes entidades:
- Usuario: Autor de las publicaciones del blog.
- Publicación: La publicación del blog, incluido el título, el contenido y la fecha de publicación.
- Comentarios: Comentarios sobre cada publicación de los lectores.
En una API REST, podrías tener los siguientes puntos de conexión:
/users/{id}para obtener los detalles del usuario./posts/{id}para obtener los detalles de la publicación./posts/{id}/commentspara obtener los comentarios de una publicación.
Para crear una página de publicación de blog detallada, querrías mostrar:
- El contenido de la publicación.
- El nombre y el perfil del autor.
- Todos los comentarios, junto con el nombre de cada comentarista.
Enfoque REST
- Primera solicitud:
/posts/123– Obtiene el contenido y los metadatos de la publicación. - Segunda solicitud:
/users/45– Obtiene los detalles del autor (suponiendo que el ID del autor es 45). - Tercera solicitud:
/posts/123/comments– Obtiene todos los comentarios de la publicación. - Solicitudes adicionales: Es posible que necesites más solicitudes si cada comentario requiere datos de diferentes usuarios, obteniendo el perfil de cada comentarista por separado.
Con REST, esto puede llevar a un exceso de búsqueda (recuperar más información de la necesaria, como campos adicionales en cada punto de conexión) y a una búsqueda insuficiente (no recuperar relaciones anidadas como comentarios y detalles del usuario en una sola consulta).
Enfoque GraphQL
Con GraphQL, puedes estructurar una sola consulta para obtener todos los datos necesarios:
query {
post(id: "123") {
title
content
publishedDate
author {
name
profilePicture
}
comments {
text
commenter {
name
}
}
}
}
En esta única consulta:
- Datos de la publicación: Obtienes el
title, elcontenty lapublishedDatede la publicación. - Datos del autor: Anidados bajo el campo
author, por lo que solo obtienes elnamey laprofilePictureque necesitas. - Comentarios: Cada comentario incluye solo el
texty elnamedel comentarista.
Beneficios clave en este ejemplo
- Reducción de las solicitudes de red: En lugar de múltiples solicitudes a diferentes puntos de conexión, estás obteniendo todos los datos necesarios con una sola solicitud. Esto reduce la carga de la red y acelera el tiempo de respuesta.
- Evita el exceso/insuficiencia de búsqueda: Recibes solo los campos específicos que solicitaste, sin datos excesivos ni campos faltantes. Esto hace que la recuperación de datos sea más eficiente, especialmente en redes móviles o de bajo ancho de banda.
- Única fuente de verdad: El esquema GraphQL define la estructura de los datos, lo que deja claro tanto a los equipos de frontend como de backend qué datos están disponibles y cómo se pueden consultar.
- Versiones simplificadas: Dado que cada cliente especifica los datos que necesita, los equipos de backend pueden evolucionar de forma segura el esquema sin romper la funcionalidad existente.
De esta manera, la flexibilidad de consulta de GraphQL te permite optimizar la búsqueda de datos y hace que tu aplicación sea más rápida y eficiente, especialmente cuando se trata de datos complejos o profundamente anidados.
¿Qué es SQL?
SQL (Structured Query Language) es un lenguaje específico del dominio que se utiliza en la programación y está diseñado para gestionar los datos contenidos en los sistemas de gestión de bases de datos relacionales (RDBMS). Es particularmente eficaz para manejar datos estructurados donde las relaciones entre diferentes entidades están claramente definidas.

SELECT name, email FROM users WHERE id = 123;
Características clave de SQL
- Lenguaje de consulta estandarizado: Un estándar ampliamente aceptado para consultar y manipular datos en bases de datos relacionales.
- Representación de datos tabulares: Los datos se organizan en tablas y las relaciones se pueden formar utilizando claves primarias y externas.
- Consultas complejas: Admite consultas complejas con operaciones JOIN, agregaciones y subconsultas.
- Control transaccional: Proporciona un control transaccional robusto para garantizar la integridad de los datos.
¿Por qué usar SQL en tu aplicación?
Usar SQL (Structured Query Language) en tu aplicación tiene varias ventajas, especialmente cuando se trata de datos estructurados y requisitos de consulta complejos. Las bases de datos SQL, también conocidas como bases de datos relacionales, se utilizan ampliamente en aplicaciones de muchas industrias debido a su fiabilidad, robusta integridad de datos y facilidad de uso. Usemos un ejemplo de una aplicación de comercio electrónico para ilustrar los beneficios de SQL.
Escenario: Creación de una aplicación de comercio electrónico con SQL
Imagina que estás desarrollando una tienda en línea con las siguientes características:
- Usuarios: Clientes que pueden crear cuentas, realizar pedidos y escribir reseñas.
- Productos: Artículos a la venta, cada uno con detalles específicos (nombre, precio, cantidad en stock).
- Pedidos: Transacciones que incluyen uno o más productos comprados por un usuario.
- Reseñas: Comentarios dejados por los usuarios sobre diferentes productos.
En SQL, estas características se pueden representar mediante tablas relacionadas:
- Tabla de usuarios: Almacena la información del usuario (ID de usuario, nombre, correo electrónico).
- Tabla de productos: Almacena la información del producto (ID de producto, nombre, precio, stock).
- Tabla de pedidos: Almacena los metadatos de cada pedido (ID de pedido, ID de usuario, fecha del pedido).
- Tabla de artículos del pedido: Almacena los detalles de cada artículo en un pedido (ID del artículo del pedido, ID del pedido, ID del producto, cantidad).
- Tabla de reseñas: Almacena las reseñas de los usuarios (ID de la reseña, ID del usuario, ID del producto, calificación, comentario).
Cómo SQL hace que esto sea eficiente
Integridad de los datos con claves externas
- La tabla
OrderItemscontiene unproduct_idque enlaza con la tablaProducts, lo que garantiza que cada artículo del pedido haga referencia a un producto válido. Del mismo modo, la tablaOrdersincluye un campouser_idque enlaza con la tablaUsers, lo que garantiza que cada pedido esté vinculado a un usuario existente. - Esta configuración impone la integridad de los datos, evitando que los pedidos incluyan productos o usuarios que no existen.
Consultas complejas para informes
- Supongamos que quieres un informe de las ventas totales de cada producto. En SQL, puedes usar una consulta con joins y funciones de agregación para obtener estos datos de manera eficiente:
SELECT
Products.name,
SUM(OrderItems.quantity) AS total_quantity_sold,
SUM(OrderItems.quantity * Products.price) AS total_revenue
FROM
OrderItems
JOIN
Products ON OrderItems.product_id = Products.product_id
GROUP BY
Products.name;
Esta consulta calcula tanto la cantidad como los ingresos de cada producto, lo que de otro modo requeriría varios pasos en bases de datos menos estructuradas.Garantizar la coherencia transaccional
- Cuando un usuario realiza un pedido, la aplicación necesita actualizar varias tablas:
- Añadir una entrada a la tabla
Orderspara la transacción. - Añadir entradas a la tabla
OrderItemspara cada artículo comprado. - Reducir la cantidad en stock en la tabla
Products. - Usando las transacciones SQL, estas acciones se agrupan. Si algún paso falla (por ejemplo, un producto se agota), se puede revertir toda la transacción, lo que garantiza que la base de datos permanezca en un estado coherente. Así es como podría verse esta transacción en SQL:
BEGIN TRANSACTION;
-- Add a new order
INSERT INTO Orders (user_id, order_date)
VALUES (1, CURRENT_DATE);
-- Add order items
INSERT INTO OrderItems (order_id, product_id, quantity)
VALUES (LAST_INSERT_ID(), 2, 3);
-- Deduct stock
UPDATE Products
SET stock = stock - 3
WHERE product_id = 2;
COMMIT;
Si la actualización del stock falla debido a una cantidad insuficiente, SQL revertirá la transacción para garantizar que el pedido y los artículos del pedido no se guarden parcialmente, manteniendo la precisión de los datos.Análisis de datos e información del cliente
- Con SQL, puedes generar información sobre el comportamiento del cliente y el rendimiento del producto. Por ejemplo, es posible que quieras encontrar los productos que se compran con más frecuencia:
SELECT
product_id, COUNT(*) AS purchase_count
FROM
OrderItems
GROUP BY
product_id
ORDER BY
purchase_count DESC
LIMIT 5;
- Esta consulta encuentra los cinco productos principales por recuento de compras, una métrica valiosa para comprender los productos populares y planificar el inventario.
Resumen de las ventajas de SQL en este ejemplo
- Datos estructurados y relaciones: Las tablas y las claves externas ayudan a imponer datos relacionales estructurados, lo que es ideal para aplicaciones organizadas como el comercio electrónico.
- Integridad de los datos y cumplimiento de ACID: Las transacciones SQL garantizan que las operaciones se completen por completo o no se completen en absoluto, lo que es crucial para la gestión de pedidos.
- Potentes capacidades de consulta: Los joins, las agregaciones y las agrupaciones de SQL permiten un análisis de datos e informes eficientes, lo que simplifica la información sobre las ventas y el comportamiento del cliente. Por lo tanto, SQL es muy adecuado para esta aplicación de comercio electrónico porque permite una organización eficiente de los datos, una integridad de los datos fiable y una consulta potente, lo que facilita la gestión y el análisis de los datos en tiempo real.
Diferencias clave entre GraphQL y SQL
GraphQL y SQL ofrecen distintos beneficios para la gestión y la recuperación de datos. Las flexibles funciones de consulta, las funcionalidades en tiempo real y la eficiente búsqueda de datos de GraphQL lo hacen ideal para las aplicaciones contemporáneas con variados requisitos de datos.
En cambio, SQL es excepcional en la gestión de datos estructurados, la navegación por relaciones complejas y el mantenimiento de la integridad transaccional. Los detalles son los siguientes:
Propósito y alcance:
- GraphQL es un lenguaje de consulta diseñado específicamente para las interacciones cliente-servidor, utilizado principalmente para las API web.
- SQL es un lenguaje para gestionar y manipular datos en una base de datos relacional.
Recuperación de datos:
- GraphQL permite a los clientes especificar exactamente los datos que necesitan en una sola solicitud.
- Las consultas SQL se centran más en la recuperación de datos de una base de datos a través de consultas SELECT, joins y otras operaciones.
Datos en tiempo real:
- GraphQL puede manejar datos en tiempo real con suscripciones.
- SQL no admite de forma nativa las actualizaciones de datos en tiempo real de la misma manera.
Flexibilidad en la consulta:
- GraphQL ofrece una gran flexibilidad, lo que permite realizar consultas personalizadas adaptadas a los requisitos del cliente.
- SQL sigue un enfoque más estructurado, con esquemas predefinidos y formatos de consulta rígidos.
Manejo del exceso de búsqueda:
- GraphQL reduce eficazmente el exceso de búsqueda al permitir consultas específicas.
- SQL podría resultar en un exceso de búsqueda si la consulta no está bien estructurada o es demasiado amplia.
Complejidad y curva de aprendizaje:
- GraphQL podría tener una curva de aprendizaje más pronunciada debido a su enfoque único para la recuperación de datos.
- SQL se enseña y se usa ampliamente, con una gran cantidad de recursos y un enfoque estandarizado.
Diferencias entre GraphQL y SQL
| Aspecto | GraphQL | SQL |
|---|---|---|
| Definición básica | Un lenguaje de consulta para las API, que permite a los clientes solicitar datos específicos. | Un lenguaje para gestionar y consultar datos en bases de datos relacionales. |
| Enfoque de recuperación de datos | Permite a los clientes solicitar exactamente lo que necesitan, reduciendo el exceso de búsqueda. | Utiliza consultas predefinidas para recuperar datos, lo que puede llevar a un exceso de búsqueda. |
| Soporte de datos en tiempo real | Admite actualizaciones en tiempo real con suscripciones. | Generalmente no admite actualizaciones en tiempo real de forma nativa. |
| Tipo de comunicación | Normalmente opera sobre HTTP/HTTPS con un único punto de conexión. | Opera sobre conexiones de bases de datos, utilizando varios protocolos basados en el sistema de bases de datos. |
| Flexibilidad de la consulta | Altamente flexible; los clientes pueden adaptar las solicitudes a sus necesidades exactas. | Más estructurado; se basa en esquemas predefinidos y formatos de consulta. |
| Estructura de datos | Funciona bien con estructuras de datos jerárquicas y anidadas. | Más adecuado para datos tabulares en formas normalizadas. |
| Casos de uso | Ideal para API complejas y en evolución y aplicaciones con diversas necesidades de datos. | Adecuado para aplicaciones que requieren transacciones complejas e integridad de datos en bases de datos. |
| Complejidad | Puede ser complejo de configurar y optimizar para el rendimiento. | Ampliamente utilizado con muchos recursos educativos, pero las consultas complejas pueden ser un desafío. |
| Control transaccional | No gestiona las transacciones; se centra en la búsqueda de datos. | Proporciona un control transaccional robusto para la integridad de los datos. |
| Comunidad y ecosistema | Creciendo rápidamente, especialmente popular en el desarrollo de aplicaciones web y móviles. | Maduro, con amplias herramientas, recursos y una vasta comunidad de usuarios. |
| Entorno de uso típico | Comúnmente utilizado en aplicaciones web y móviles para la recuperación flexible de datos. | Utilizado en sistemas donde la integridad de los datos, las consultas complejas y la generación de informes son cruciales. |
Cómo conectarse a SQL Server en Apidog
Conectarse a un SQL Server en Apidog es un proceso similar a conectarse a una base de datos Oracle, pero con algunas diferencias específicas que se adaptan a SQL Server. Aquí tienes una guía concisa para ayudarte a configurar esta conexión:
Paso 1: Instalar Apidog
- Descargar Apidog: Visita el sitio web oficial de Apidog y descarga la aplicación. Asegúrate de que sea compatible con tu sistema operativo (Windows o Linux).
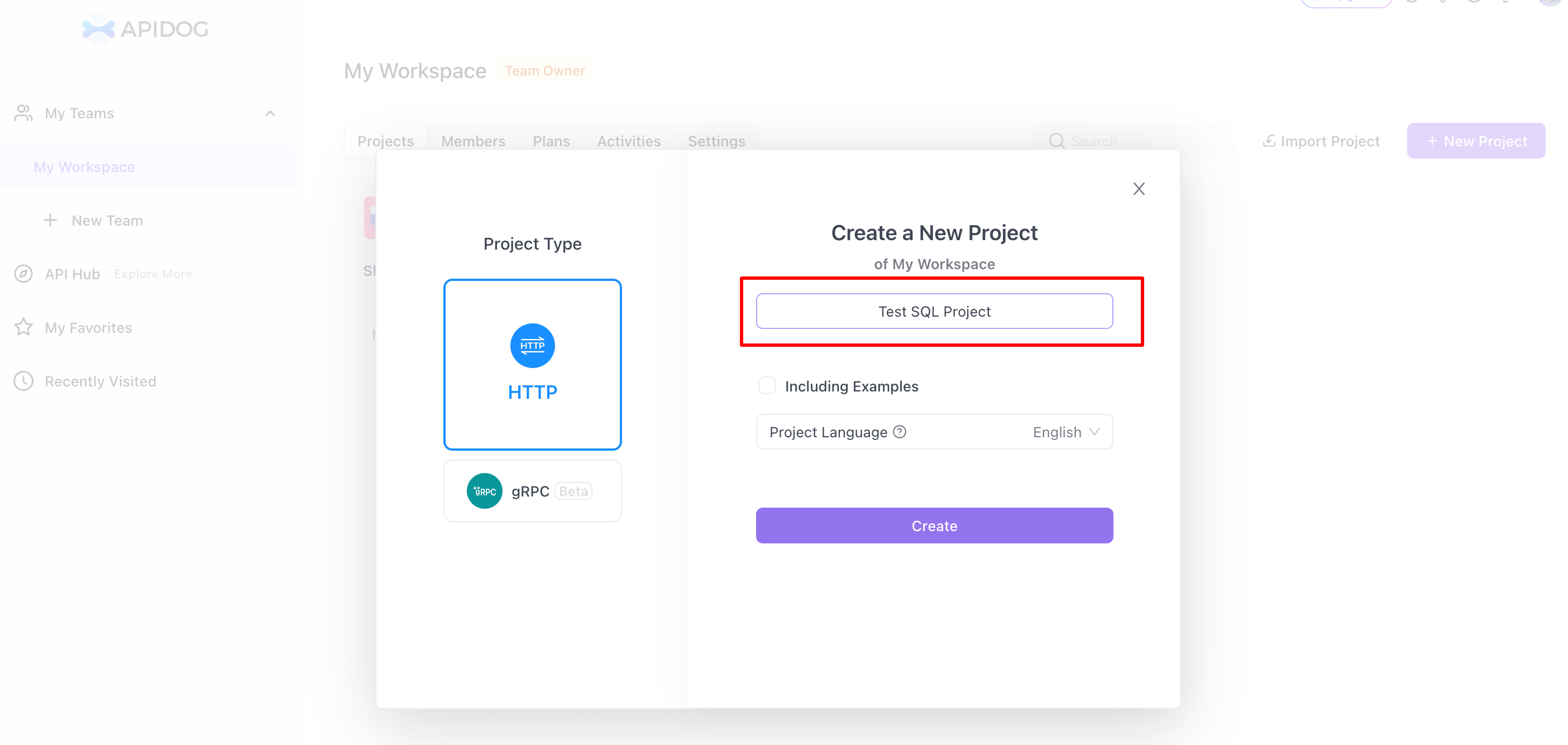
Paso 2: Crear un nuevo proyecto
- Nuevo proyecto: En Apidog, ve a la sección "Mi espacio de trabajo", selecciona "Nuevo proyecto" y elige "HTTP" como tipo. Introduce un nombre para tu proyecto.
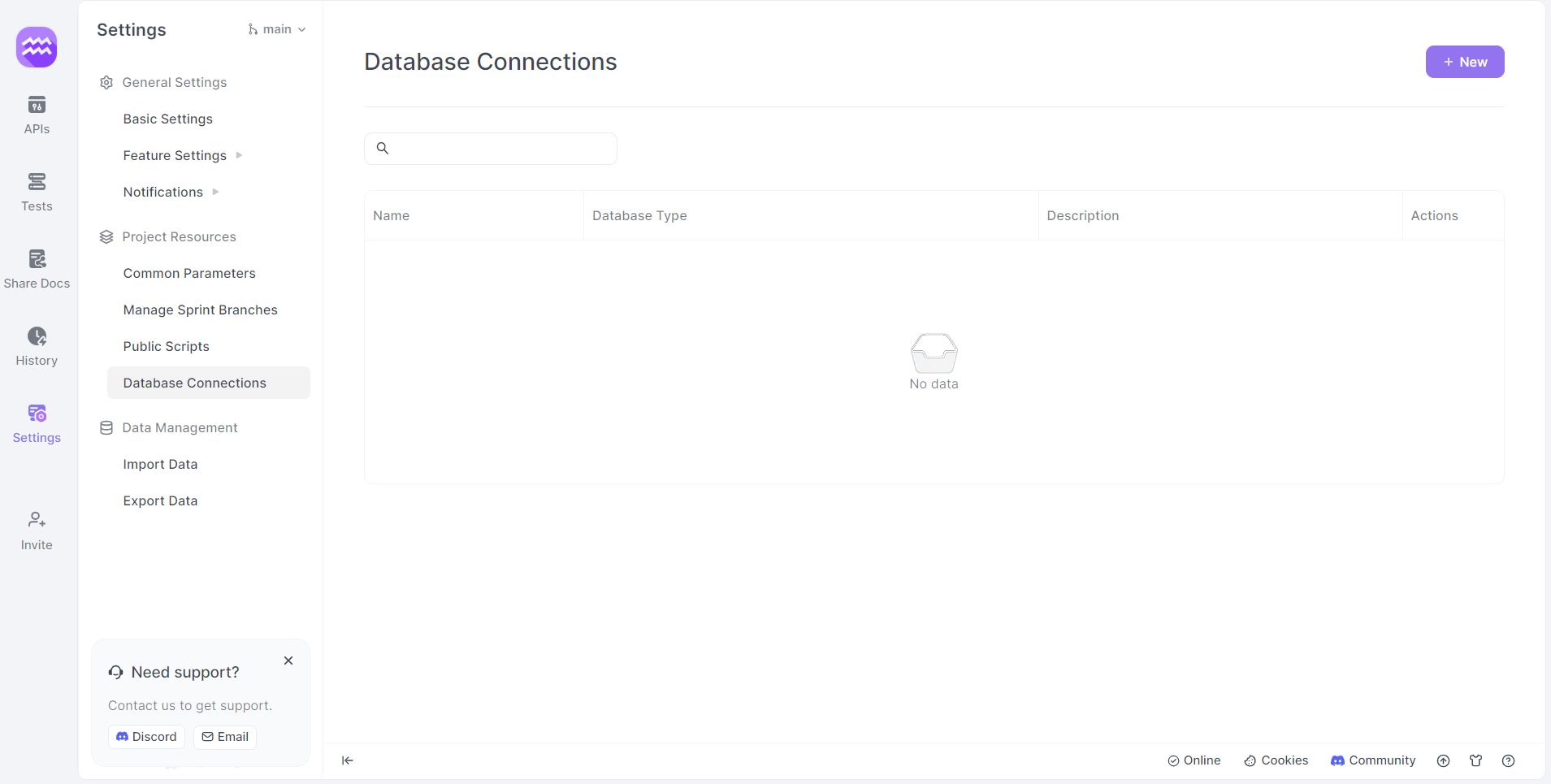
Paso 3: Acceder a las conexiones de la base de datos
- Ajustes: Haz clic en la opción de ajustes en el menú lateral.
- Conexiones de la base de datos: Navega hasta el menú "Conexiones de la base de datos".
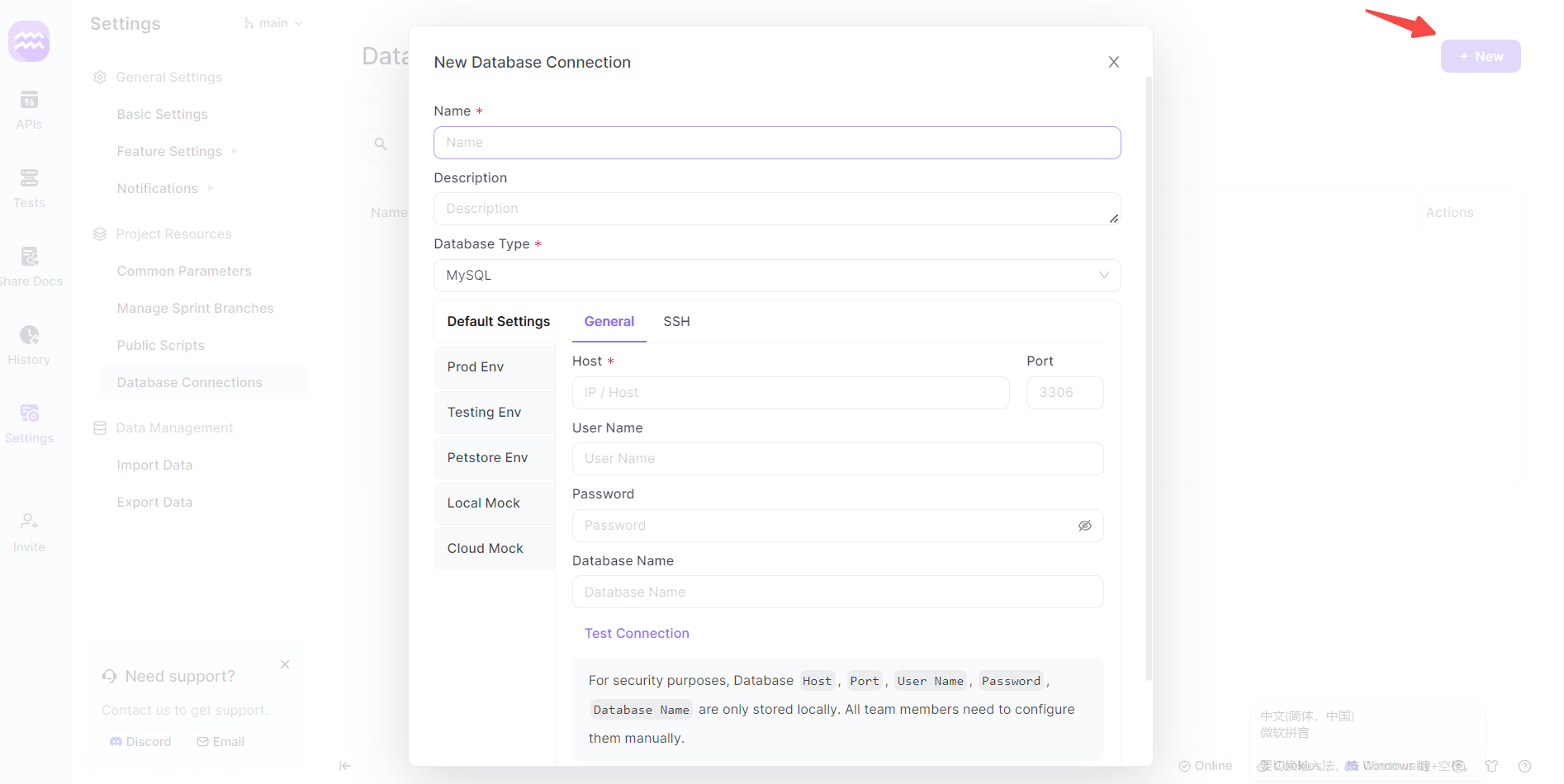
Paso 4: Configurar una nueva conexión
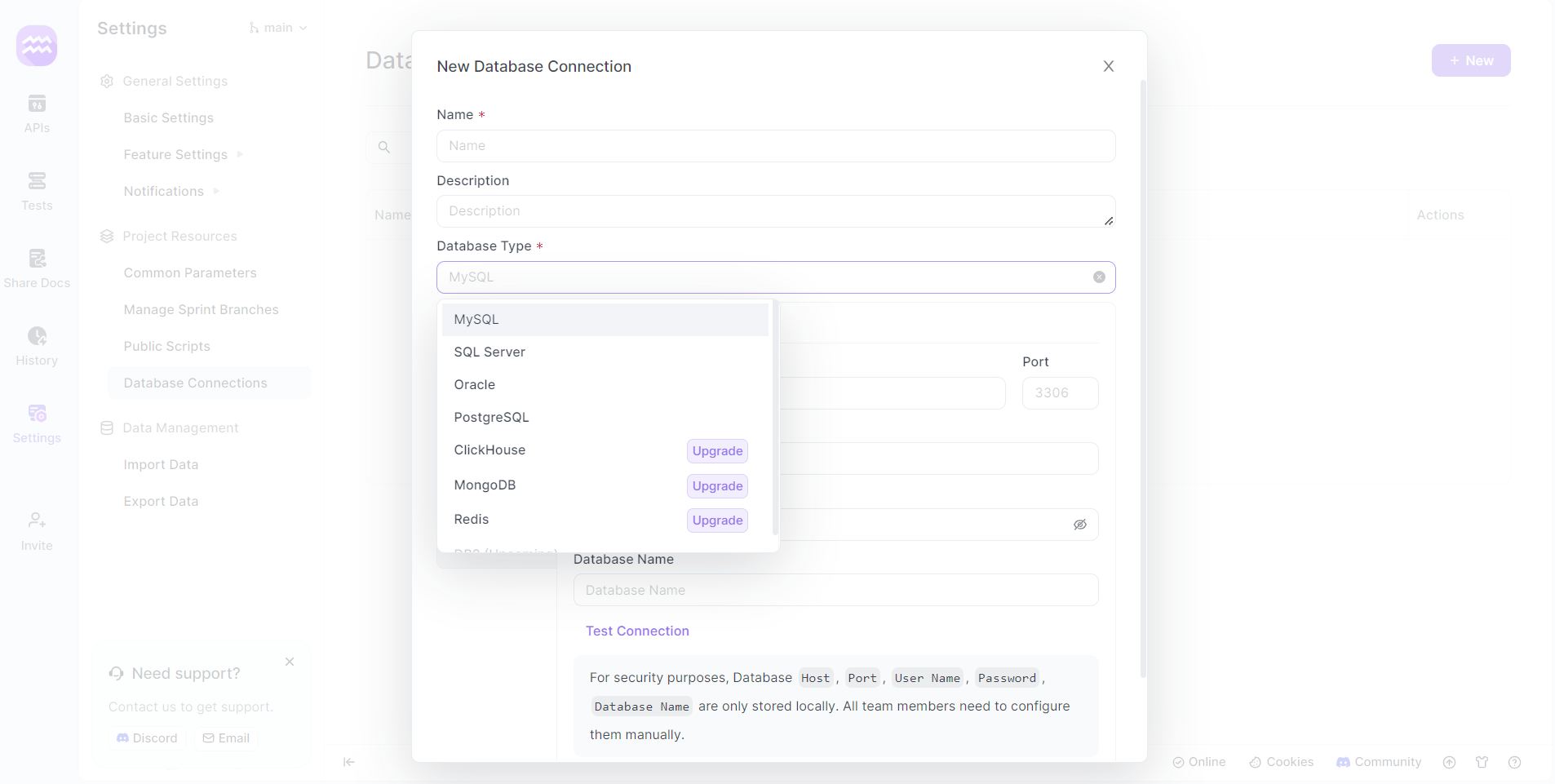
- Añadir conexión: Haz clic en "+ Nuevo" para crear una nueva conexión de base de datos. Aparecerá una nueva ventana para la configuración.
Paso 5: Configurar la conexión de SQL Server
- Detalles de la conexión: Proporciona un nombre para tu conexión de base de datos y selecciona "SQL Server" como tipo de base de datos.
- Detalles del servidor: Introduce el host, el puerto y otros detalles relevantes específicos de tu instancia de SQL Server.
- Autenticación: Utiliza el nombre de usuario y la contraseña de SQL Server adecuados. Normalmente, podría ser una cuenta de administrador como "sa" o una cuenta específica del usuario.
- Probar conexión: Haz clic en el botón "Probar conexión" para verificar si la configuración se ha realizado correctamente.
Paso 6: Definir los puntos de conexión de la API
- Establecer puntos de conexión: Especifica las URL para las operaciones de envío/recepción de datos de tu aplicación, marcando el tipo de operación (GET, POST, PUT, DELETE).
- Configurar procesadores: Define cualquier preprocesador o postprocesador para diferentes operaciones de la base de datos.
Paso 7: Probar y validar
- Pruebas de API: Utiliza las herramientas de Apidog para probar cada punto de conexión. El editor resaltará cualquier error.
- Depurar y volver a probar: Investiga cualquier problema, realiza correcciones y vuelve a probar hasta que las API funcionen como se espera.
Conclusión
En conclusión, GraphQL y SQL se adaptan a diferentes aspectos de la gestión y la recuperación de datos. GraphQL destaca en escenarios que requieren consultas flexibles y específicas del cliente y datos en tiempo real, lo que lo convierte en una opción popular para las API web modernas.
SQL, por otro lado, sigue siendo la piedra angular para la manipulación de datos estructurados en bases de datos relacionales, destacando en la consulta de datos complejos y la integridad transaccional. Comprender sus distintas características ayuda a elegir la tecnología adecuada en función de los requisitos específicos de un proyecto.


