
¿Quieres potenciar tu flujo de trabajo de codificación con GPT-OSS, el modelo de peso abierto de Open AI, directamente dentro de Claude Code? ¡Estás de enhorabuena! Lanzado en agosto de 2025, GPT-OSS (variantes 20B o 120B) es una potencia para la codificación y el razonamiento, y puedes emparejarlo con la elegante interfaz CLI de Claude Code para configuraciones gratuitas o de bajo coste. En esta guía conversacional, te guiaremos a través de tres rutas para integrar GPT-OSS con Claude Code usando Hugging Face, OpenRouter o LiteLLM. ¡Vamos a sumergirnos y poner en marcha a tu compañero de codificación con IA!
¿Quieres una plataforma integrada y todo en uno para que tu equipo de desarrolladores trabaje en conjunto con máxima productividad?
¡Apidog cumple con todas tus demandas y reemplaza a Postman a un precio mucho más asequible!
¿Qué es GPT-OSS y por qué usarlo con Claude Code?
GPT-OSS es la familia de modelos de peso abierto de Open AI, con las variantes 20B y 120B que ofrecen un rendimiento estelar para tareas de codificación, razonamiento y agenciales. Con una ventana de contexto de 128K tokens y licencia Apache 2.0, es perfecto para desarrolladores que desean flexibilidad y control. Claude Code, la herramienta CLI de Anthropic (versión 0.5.3+), es la favorita de los desarrolladores por sus capacidades de codificación conversacional. Al enrutar Claude Code a GPT-OSS a través de APIs compatibles con OpenAI, puedes disfrutar de la interfaz familiar de Claude mientras aprovechas el poder de código abierto de GPT-OSS, sin los costes de suscripción de Anthropic. ¿Listo para hacerlo realidad? ¡Exploremos las opciones de configuración!

Requisitos previos para usar GPT-OSS con Claude Code
Antes de empezar, asegúrate de tener:
- Claude Code ≥ 0.5.3: Comprueba con
claude --version. Instala a través depip install claude-codeo actualiza conpip install --upgrade claude-code. - Cuenta de Hugging Face: Regístrate en huggingface.co y crea un token de lectura/escritura (Configuración > Tokens de acceso).
- Clave API de OpenRouter: Opcional, para la Ruta B. Consigue una en openrouter.ai.
- Python 3.10+ y Docker: Para configuraciones locales o LiteLLM (Ruta C).
- Conocimientos básicos de CLI: La familiaridad con las variables de entorno y los comandos de terminal ayuda.
Ruta A: Autoalojar GPT-OSS en Hugging Face
¿Quieres control total? Aloja GPT-OSS en los puntos finales de inferencia de Hugging Face para una configuración privada y escalable. Así es como:
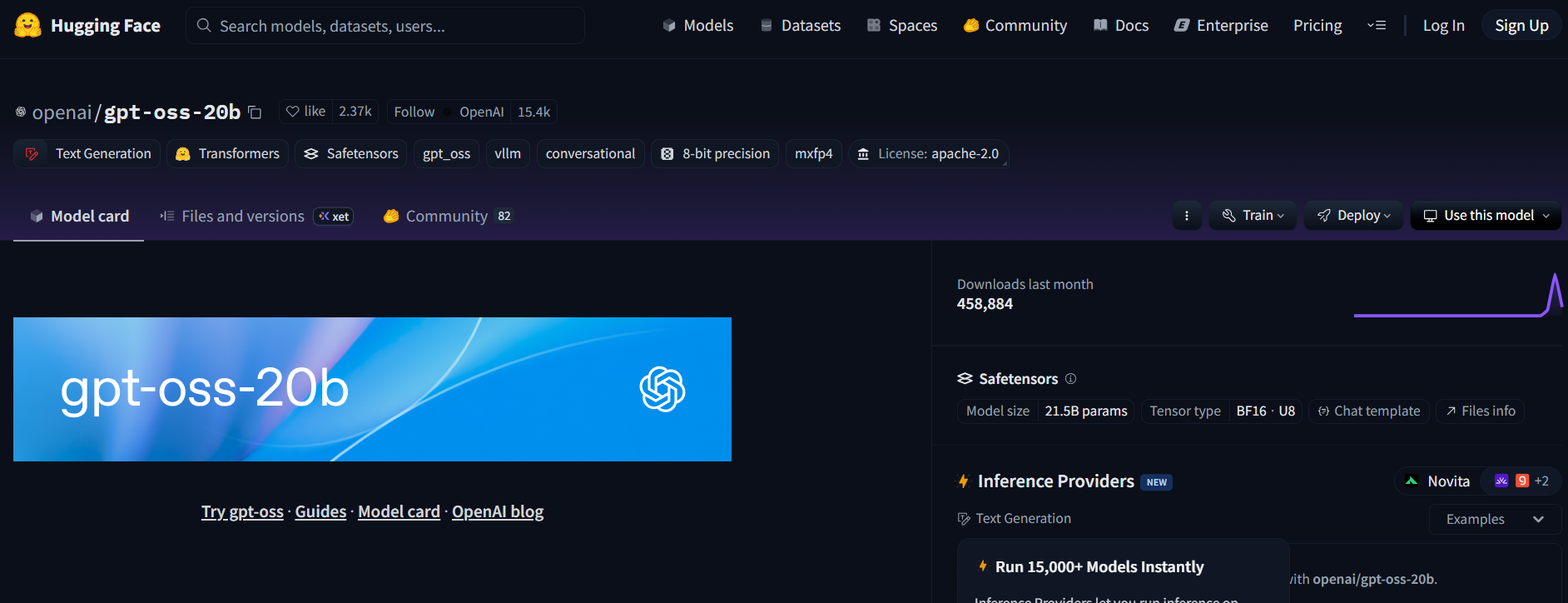
Paso 1: Obtén el modelo
- Visita el repositorio de GPT-OSS en Hugging Face (openai/gpt-oss-20b o openai/gpt-oss-120b).
- Acepta la licencia Apache 2.0 para acceder al modelo.
- Alternativamente, prueba Qwen3-Coder-480B-A35B-Instruct (Qwen/Qwen3-Coder-480B-A35B-Instruct) para un modelo enfocado en la codificación (usa una versión GGUF para hardware más ligero).
Paso 2: Despliega un punto final de inferencia de generación de texto
- En la página del modelo, haz clic en Deploy > Inference Endpoint.
- Selecciona la plantilla Text Generation Inference (TGI) (≥ v1.4.0).
- Habilita la compatibilidad con OpenAI marcando Enable OpenAI compatibility o añadiendo
--enable-openaien la configuración avanzada. - Elige el hardware: A10G o CPU para 20B, A100 para 120B. Crea el punto final.
Paso 3: Recopila las credenciales
- Una vez que el estado del punto final sea Running, copia:
- ENDPOINT_URL: Se ve como
https://<tu-punto-final>.us-east-1.aws.endpoints.huggingface.cloud. - HF_API_TOKEN: Tu token de Hugging Face de Configuración > Tokens de acceso.
2. Anota el ID del modelo (por ejemplo, gpt-oss-20b o gpt-oss-120b).
Paso 4: Configura Claude Code
- Establece las variables de entorno en tu terminal:
export ANTHROPIC_BASE_URL="https://<tu-punto-final>.us-east-1.aws.endpoints.huggingface.cloud"
export ANTHROPIC_AUTH_TOKEN="hf_xxxxxxxxxxxxxxxxx"
export ANTHROPIC_MODEL="gpt-oss-20b" # o gpt-oss-120b
Reemplaza <tu-punto-final> y hf_xxxxxxxxxxxxxxxxx con tus valores.
2. Prueba la configuración:
claude --model gpt-oss-20b
Claude Code se enruta a tu punto final de GPT-OSS, transmitiendo respuestas a través de la API /v1/chat/completions de TGI, imitando el esquema de OpenAI.
Paso 5: Notas sobre costes y escalado
- Costes de Hugging Face: Los puntos finales de inferencia se autoescalan, así que monitoriza el uso para evitar el consumo de créditos. A10G cuesta ~$0.60/hora, A100 ~$3/hora.
- Opción local: Para costes de nube cero, ejecuta TGI localmente con Docker:
docker run --name tgi -p 8080:80 -e HF_TOKEN=hf_xxxxxxxxxxxxxxxxx ghcr.io/huggingface/text-generation-inference:latest --model-id openai/gpt-oss-20b --enable-openai
Luego, establece ANTHROPIC_BASE_URL="http://localhost:8080".
Ruta B: Proxy de GPT-OSS a través de OpenRouter
¿No tienes DevOps? ¡No hay problema! Usa OpenRouter para acceder a GPT-OSS con una configuración mínima. Es rápido y gestiona la facturación por ti.
Paso 1: Regístrate y elige un modelo
- Regístrate en openrouter.ai y copia tu clave API de la sección Keys.
- Elige un slug de modelo:
openai/gpt-oss-20bopenai/gpt-oss-120bqwen/qwen3-coder-480b(para el modelo de codificador de Qwen)
Paso 2: Configura Claude Code
- Establece las variables de entorno:
export ANTHROPIC_BASE_URL="https://openrouter.ai/api/v1"
export ANTHROPIC_AUTH_TOKEN="or_xxxxxxxxx"
export ANTHROPIC_MODEL="openai/gpt-oss-20b"
Reemplaza or_xxxxxxxxx con tu clave API de OpenRouter.
2. Pruébalo:
claude --model openai/gpt-oss-20b
Claude Code se conecta a GPT-OSS a través de la API unificada de OpenRouter, con soporte de streaming y fallback.
Paso 3: Notas de coste
- Precios de OpenRouter: ~$0.50/M tokens de entrada, ~$2.00/M tokens de salida para GPT-OSS-120B, significativamente más barato que modelos propietarios como GPT-4 (~$20.00/M).
- Facturación: OpenRouter gestiona el uso, por lo que solo pagas por lo que usas.
Ruta C: Usa LiteLLM para flotas de modelos mixtos
¿Quieres manejar GPT-OSS, Qwen y modelos de Anthropic en un solo flujo de trabajo? LiteLLM actúa como un proxy para intercambiar modelos sin problemas.
Paso 1: Instala y configura LiteLLM
- Instala LiteLLM:
pip install litellm
2. Crea un archivo de configuración (litellm.yaml):
model_list:
- model_name: gpt-oss-20b
litellm_params:
model: openai/gpt-oss-20b
api_key: or_xxxxxxxxx # Clave de OpenRouter
api_base: https://openrouter.ai/api/v1
- model_name: qwen3-coder
litellm_params:
model: openrouter/qwen/qwen3-coder
api_key: or_xxxxxxxxx
api_base: https://openrouter.ai/api/v1
Reemplaza or_xxxxxxxxx con tu clave de OpenRouter.
3. Inicia el proxy:
litellm --config litellm.yaml
Paso 2: Apunta Claude Code a LiteLLM
- Establece las variables de entorno:
export ANTHROPIC_BASE_URL="http://localhost:4000"
export ANTHROPIC_AUTH_TOKEN="litellm_master"
export ANTHROPIC_MODEL="gpt-oss-20b"
2. Pruébalo:
claude --model gpt-oss-20b
LiteLLM enruta las solicitudes a GPT-OSS a través de OpenRouter, con registro de costes y enrutamiento simple-shuffle para mayor fiabilidad.
Paso 3: Notas
- Evitar el enrutamiento por latencia: Usa el modo simple-shuffle en LiteLLM para evitar problemas con los modelos de Anthropic.
- Seguimiento de costes: LiteLLM registra el uso para mayor transparencia.
Probando GPT-OSS con Claude Code
¡Asegurémonos de que GPT-OSS funciona! Abre Claude Code y prueba estos comandos:
Generación de código:
claude --model gpt-oss-20b "Escribe una API REST en Python con Flask"
Espera una respuesta como:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api', methods=['GET'])
def get_data():
return jsonify({"message": "¡Hola desde GPT-OSS!"})
if __name__ == '__main__':
app.run(debug=True)
Análisis de base de código:
claude --model gpt-oss-20b "Resume src/server.js"
GPT-OSS aprovecha su ventana de contexto de 128K para analizar tu archivo JavaScript y devolver un resumen.
Depuración:
claude --model gpt-oss-20b "Depura este código Python con errores: [pega el código]"
Con una tasa de aprobación de HumanEval del 87.3%, GPT-OSS debería detectar y corregir problemas con precisión.
Consejos para la resolución de problemas
- ¿404 en /v1/chat/completions? Asegúrate de que
--enable-openaiesté activo en TGI (Ruta A) o verifica la disponibilidad del modelo de OpenRouter (Ruta B). - ¿Respuestas vacías? Verifica que
ANTHROPIC_MODELcoincida con el slug (por ejemplo,gpt-oss-20b). - ¿Error 400 después de cambiar el modelo? Usa el enrutamiento simple-shuffle en LiteLLM (Ruta C).
- ¿Primer token lento? Calienta los puntos finales de Hugging Face con una pequeña instrucción después de escalar a cero.
- ¿Claude Code se bloquea? Actualiza a ≥ 0.5.3 y asegúrate de que las variables de entorno estén configuradas correctamente.
¿Por qué usar GPT-OSS con Claude Code?
Emparejar GPT-OSS con Claude Code es el sueño de todo desarrollador. Obtienes:
- Ahorro de costes: Los $0.50/M tokens de entrada de OpenRouter superan a los modelos propietarios, y las configuraciones locales de TGI son gratuitas después de los costes de hardware.
- Poder de código abierto: La licencia Apache 2.0 de GPT-OSS te permite personalizar o desplegar de forma privada.
- Flujo de trabajo sin interrupciones: La CLI de Claude Code se siente como chatear con un compañero de codificación, mientras que GPT-OSS se encarga del trabajo pesado con puntuaciones de 94.2% MMLU y 96.6% AIME.
- Flexibilidad: Intercambia entre modelos GPT-OSS, Qwen o Anthropic con LiteLLM u OpenRouter.
Los usuarios están entusiasmados con la destreza de codificación de GPT-OSS, llamándolo "una bestia económica para proyectos de múltiples archivos". Ya sea que lo autoalojes o lo proxies a través de OpenRouter, esta configuración mantiene los costes bajos y la productividad alta.
Conclusión
¡Ahora estás listo para usar GPT-OSS con Claude Code! Ya sea que te autoalojes en Hugging Face, uses un proxy a través de OpenRouter o utilices LiteLLM para la gestión de modelos, tienes una configuración de codificación potente y rentable. Desde la generación de API REST hasta la depuración de código, GPT-OSS cumple, y Claude Code lo hace sentir sin esfuerzo. ¡Pruébalo, comparte tus instrucciones favoritas en los comentarios y disfrutemos de la codificación con IA!
¿Quieres una plataforma integrada y todo en uno para que tu equipo de desarrolladores trabaje en conjunto con máxima productividad?
¡Apidog cumple con todas tus demandas y reemplaza a Postman a un precio mucho más asequible!