
Los desarrolladores que construyen aplicaciones inteligentes a menudo se enfrentan al desafío de integrar modelos de vanguardia como GPT-5.2 en sus flujos de trabajo. Lanzado por OpenAI como la última frontera en capacidades de IA, GPT-5.2 amplía los límites en la generación de código, la percepción de imágenes y el razonamiento multi-paso. Lo integras no solo para experimentar, sino para implementar soluciones robustas y escalables que manejen tareas profesionales complejas. Sin embargo, la profundidad de la API —desde la selección de variantes hasta el ajuste de parámetros— exige un enfoque estructurado. Ahí es donde entran herramientas como Apidog, simplificando el diseño, las pruebas y la documentación de la API para que te concentres en la innovación en lugar de en el trabajo repetitivo.
Comprendiendo GPT-5.2: Capacidades Clave y Por Qué Es Importante para los Desarrolladores
Seleccionas GPT-5.2 porque supera a sus predecesores en precisión y eficiencia. OpenAI lo posiciona como una suite optimizada para el trabajo de conocimiento, donde logra resultados de vanguardia en diversos benchmarks. Por ejemplo, obtiene un 80.0% en SWE-Bench Verified para tareas de codificación, lo que significa que generas soluciones de software más precisas con menos iteraciones. Además, sus capacidades de visión reducen a la mitad las tasas de error en el razonamiento de gráficos, lo que permite aplicaciones como herramientas de visualización de datos automatizadas.
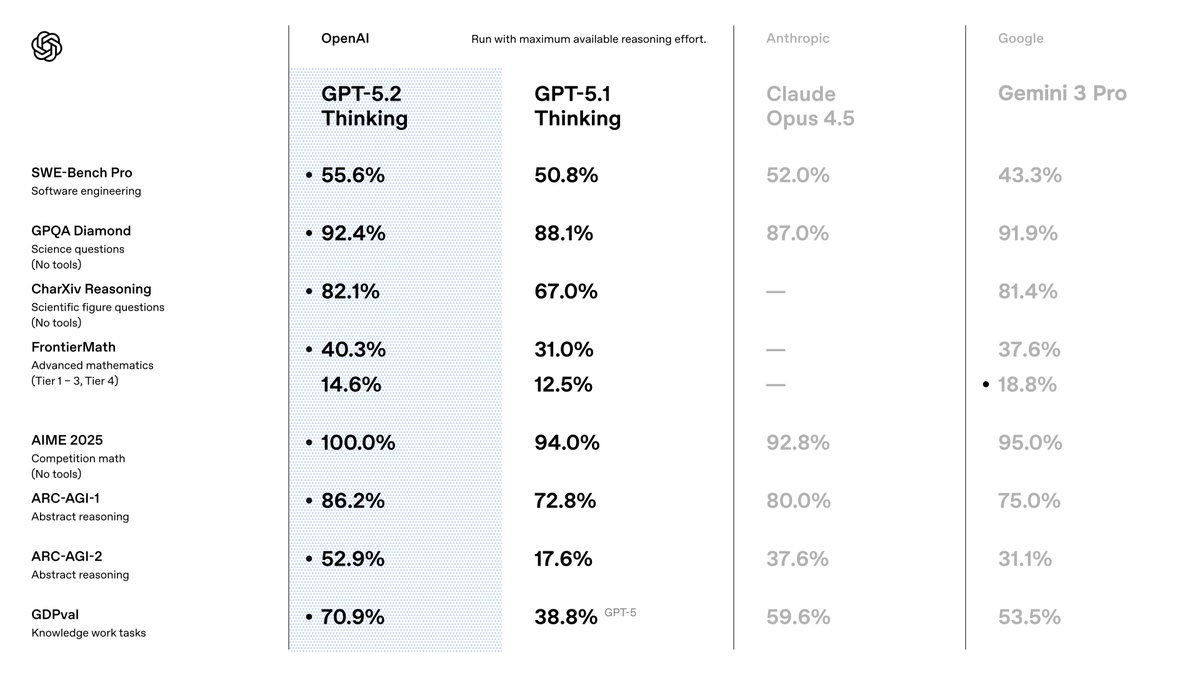
Al pasar de GPT-5.1, notarás mejoras en la factualidad —30% menos de alucinaciones en consultas habilitadas para búsqueda— y en el manejo de contextos largos, con una precisión casi perfecta de hasta 256k tokens. Estas características son importantes porque reducen las necesidades de post-procesamiento en tus pipelines. También te beneficias de una mejor llamada a herramientas, obteniendo un 98.7% en benchmarks de múltiples turnos, lo que agiliza los sistemas agénticos.
Para los usuarios de la API, GPT-5.2 se integra sin problemas en los ecosistemas existentes de OpenAI. Accedes a él a través de la API de Chat Completions o Responses, admitiendo parámetros como la temperatura para el control de la creatividad. Sin embargo, el éxito depende de elegir la variante correcta. A continuación, exploraremos esas.
Explorando las Variantes de GPT-5.2: Adapta el Rendimiento a Tus Necesidades
GPT-5.2 ofrece variantes que equilibran velocidad, profundidad y costo, permitiéndote ajustar el comportamiento del modelo a las demandas de la tarea. A diferencia de los modelos monolíticos, estas opciones —Instant, Thinking y Pro— brindan flexibilidad. Las activas a través de identificadores de modelo específicos en tus solicitudes de API.
Comienza con GPT-5.2 Instant (gpt-5.2-chat-latest). Esta variante prioriza la baja latencia para interacciones cotidianas, como la búsqueda rápida de información o la redacción técnica. Los desarrolladores la prefieren para chatbots o asistentes en tiempo real, donde los tiempos de respuesta inferiores a 200 ms son esenciales. Maneja traducciones y guías con una precisión refinada, lo que la hace ideal para aplicaciones orientadas al consumidor.
A continuación, considera GPT-5.2 Thinking (gpt-5.2). Lo implementas para análisis más profundos, como la síntesis de documentos largos o la planificación lógica. Su motor de razonamiento destaca en matemáticas y toma de decisiones, resolviendo el 40.3% de los problemas de FrontierMath. Utiliza el parámetro reasoning aquí —establecido en 'high' o 'xhigh'— para amplificar la calidad de la salida en consultas complejas. Por ejemplo, en herramientas de gestión de proyectos, orquesta flujos de trabajo de múltiples pasos con errores mínimos.
Finalmente, **GPT-5.2 Pro** (gpt-5.2-pro) apunta a un rendimiento de élite en dominios desafiantes. Se jacta de un 93.2% en GPQA Diamond para preguntas de ciencia y destaca en programación con menos fallos en casos extremos. Lo reservas para prototipos de I+D o entornos de alto riesgo, como la modelización financiera, donde la precisión supera a la velocidad.
La imagen que compartiste destaca los conmutadores para estos, incluyendo los modos "Max", "Mini", "High", "Low" y "Fast". Estos se alinean con los esfuerzos de razonamiento: 'none' para respuestas instantáneas, 'low' para tareas básicas, hasta 'xhigh' para análisis exhaustivos. Los activas a través de parámetros de la API, asegurando que el modelo se adapte dinámicamente. Por ejemplo, cambia a "Max High Fast" para sesiones de codificación equilibradas que priorizan la velocidad sin sacrificar la profundidad.
Al seleccionar las variantes cuidadosamente, optimizas el uso de los recursos. Ahora, configuras el acceso para realizar estas llamadas.
Configurando el Acceso a la API de GPT-5.2: Autenticación y Preparación del Entorno
Comienzas la integración asegurando las credenciales de la API. OpenAI requiere una clave API, que generas desde el panel de control de la plataforma. Navega a platform.openai.com, crea una cuenta si es necesario y emite una clave bajo "API Keys".
A continuación, instala el SDK de Python de OpenAI. Ejecuta pip install openai en tu terminal. Esta biblioteca maneja solicitudes HTTP, reintentos y streaming de forma nativa. Para usuarios de Node.js, npm install openai proporciona una funcionalidad similar. Lo importas de la siguiente manera:
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Prueba la conectividad con una simple finalización:
response = client.chat.completions.create(
model="gpt-5.2-chat-latest",
messages=[{"role": "user", "content": "Explica brevemente el entrelazamiento cuántico."}]
)
print(response.choices[0].message.content)
Esta llamada verifica la configuración. Si surgen errores, verifica los límites de velocidad (3,500 RPM predeterminados para el Nivel 1) o la validez de la clave. También configuras la URL base para endpoints personalizados, como /compact para contextos extendidos: client = OpenAI(base_url="https://api.openai.com/v1", api_key=...).
Con lo básico establecido, exploras la creación de solicitudes.
Elaborando Solicitudes Efectivas a la API de GPT-5.2: Parámetros y Mejores Prácticas
Construyes solicitudes usando el endpoint de Chat Completions (/v1/chat/completions). El payload incluye model, messages, y parámetros opcionales como temperature (0-2 para determinismo) y max_tokens (hasta 4096 de salida).
Para las especificidades de GPT-5.2, incorpora reasoning_effort para controlar la profundidad:
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Escribe una función Python para la secuencia de Fibonacci."}],
reasoning_effort="high", # Se alinea con el conmutador "Max High"
temperature=0.7,
max_tokens=500
)
Esto genera código con razonamiento paso a paso, reduciendo errores. Encadenas mensajes para conversaciones, preservando el contexto a través de los turnos. Para tareas de visión, sube imágenes a través de content con tipo "image_url":
messages = [
{"role": "user", "content": [
{"type": "text", "text": "Describe las tendencias de este gráfico."},
{"type": "image_url", "image_url": {"url": "https://example.com/chart.png"}}
]}
]
Las mejores prácticas incluyen agrupar solicitudes para ahorrar costos y usar streaming (stream=True) para interfaces de usuario en tiempo real. Monitorea el uso de tokens con usage en las respuestas para refinar las prompts. Además, habilita herramientas para la llamada a funciones —define esquemas para APIs externas, y GPT-5.2 las ejecuta de forma autónoma.
Para probar esto de manera eficiente, integra Apidog. Simula los endpoints de OpenAI, permitiéndote simular variantes sin consumir cuotas en vivo.
Integrando GPT-5.2 con Apidog: Simplifica las Pruebas y la Documentación
Apidog transforma la forma en que gestionas los flujos de trabajo de la API de GPT-5.2. Como plataforma todo en uno, soporta importaciones de especificaciones OpenAPI, construcción de solicitudes y pruebas automatizadas. Importas el esquema de OpenAI a Apidog, luego diseñas colecciones para las llamadas a GPT-5.2.
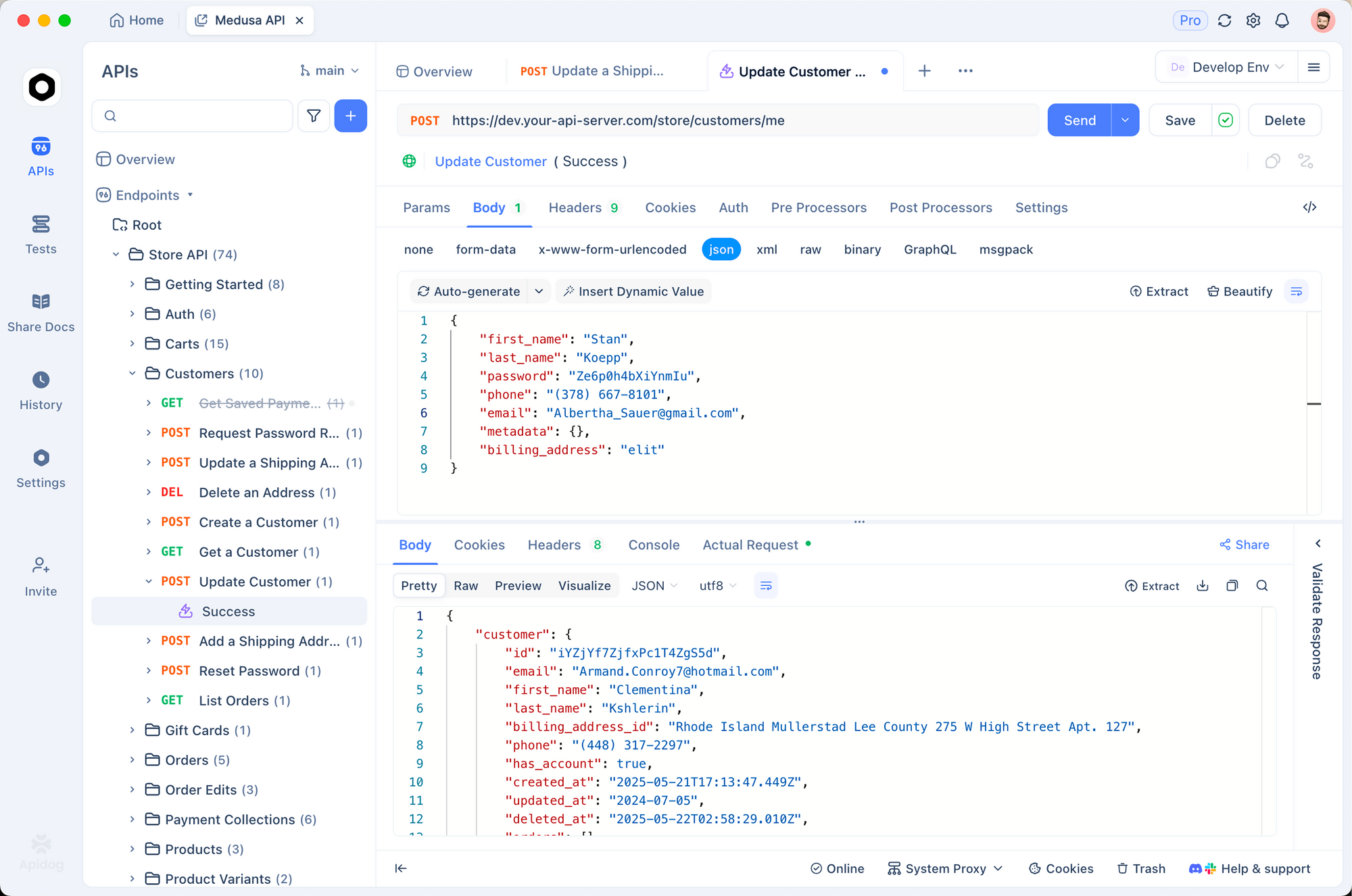
Comienza creando un nuevo proyecto en Apidog. Agrega una solicitud HTTP a https://api.openai.com/v1/chat/completions, establece los encabezados (Authorization: Bearer YOUR_KEY, Content-Type: application/json), y pega un cuerpo de ejemplo. Alterna variables para modelos como "gpt-5.2-pro" para comparar las salidas una al lado de la otra.
La fortaleza de Apidog reside en su servidor de mocking. Generas respuestas falsas que imitan la estructura JSON de GPT-5.2, ideal para el desarrollo offline. Por ejemplo, simula una respuesta "Max Extra High" con rastros de razonamiento detallados. Ejecuta pruebas con aserciones sobre el recuento de tokens o las tasas de alucinación.

Además, documenta tu API con el editor integrado de Apidog. Genera documentación interactiva que tus colegas puedan usar para explorar los endpoints. Exporta a Postman o HAR para portabilidad. En producción, Apidog monitorea las llamadas, alertando sobre anomalías como alta latencia en los modos "Low Fast".
Al integrar Apidog en tu proceso, aceleras la iteración. Descárgalo gratis e importa tu primera solicitud de GPT-5.2 —experimenta la diferencia en minutos.
Precios de la API de GPT-5.2: Equilibra Estratégicamente Costo y Capacidad
No puedes ignorar los precios al escalar aplicaciones GPT-5.2. OpenAI estructura los costos por millón de tokens, con niveles que reflejan el volumen de uso. Para GPT-5.2 Instant (gpt-5.2-chat-latest), espera $1.75 por 1M de tokens de entrada y $14 por 1M de tokens de salida. Las entradas en caché bajan a $0.175 —un ahorro del 90%— fomentando contextos repetidos.
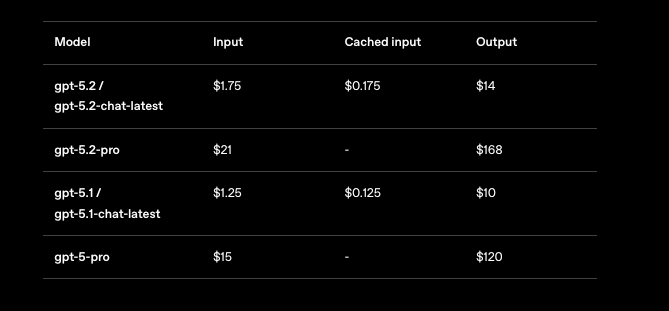
GPT-5.2 Thinking (gpt-5.2) refleja estas tarifas, lo que lo hace rentable para tareas equilibradas. Sin embargo, GPT-5.2 Pro (gpt-5.2-pro) exige más: $21 por 1M de entrada y $168 por 1M de salida. Este costo premium refleja su precisión superior en consultas de nivel profesional, pero debes evaluar el ROI con cuidado.
En general, GPT-5.2 demuestra ser eficiente en el uso de tokens, a menudo reduciendo el gasto total en comparación con GPT-5.1 para obtener resultados de calidad. Lo rastreas a través del analizador de uso del dashboard. Para empresas, negocia niveles personalizados. Herramientas como Apidog ayudan a pronosticar costos registrando flujos de tokens simulados.
Comprendiendo estas cifras, procedes a ejemplos prácticos.
Ejemplos Prácticos: Generación de Código y Tareas de Visión con GPT-5.2
Aplicas GPT-5.2 en escenarios tangibles. Considera la generación de código: Solicita un componente React con gestión de estado.
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Crea una lista de tareas de React con useReducer."}],
reasoning_effort="medium"
)
La salida produce código limpio y comentado —80% alineado con el benchmark. Lo refinas iterando: Continúa con "Optimiza para el rendimiento."
Para visión, analiza capturas de pantalla. Sube una maqueta de UI y consulta: "Sugiere mejoras de accesibilidad." GPT-5.2 identifica problemas como el contraste de color, aprovechando su tasa de error reducida a la mitad.
En agentes multi-herramienta, define funciones para consultas a bases de datos. GPT-5.2 orquesta llamadas, reduciendo la latencia en mega-agentes con más de 20 herramientas.
Estos ejemplos demuestran versatilidad. Sin embargo, ocurren errores —manéjalos con reintentos y mecanismos de respaldo.
Manejo de Errores y Casos Límite en las Llamadas a la API de GPT-5.2
Encuentras límites de tasa o parámetros inválidos. Envuelve las llamadas en try-except:
try:
response = client.chat.completions.create(...)
except openai.RateLimitError:
time.sleep(60) # Retroceso
response = client.chat.completions.create(...)
Para alucinaciones, verifica con herramientas de búsqueda. En contextos largos, usa /compact para comprimir historiales. Monitorea el sesgo en aplicaciones sensibles, aplicando filtros.
Apidog ayuda aquí: Scripts de pruebas para escenarios de error, asegurando la resiliencia.
Optimizaciones Avanzadas: Escalando GPT-5.2 para Producción
Escalas ajustando las prompts y usando la API de Assistants para hilos persistentes. Implementa el almacenamiento en caché para entradas repetidas. Para aplicaciones globales, enruta a través de servidores edge.
Integra con frameworks como LangChain: Encadena GPT-5.2 con almacenes de vectores para sistemas RAG.
Finalmente, mantente actualizado —OpenAI itera rápidamente.
Conclusión: Domina la API de GPT-5.2 y Construye el Futuro
Ahora posees las herramientas para manejar GPT-5.2 de manera efectiva. Desde la selección de variantes hasta las pruebas mejoradas con Apidog, aplica estos pasos para elevar tus proyectos. Los precios siguen siendo accesibles para un uso reflexivo, desbloqueando capacidades que antes estaban reservadas para laboratorios.
Experimenta hoy: Prototipa un agente GPT-5.2 y mide las ganancias. Comparte tus creaciones en los comentarios —¿qué desafíos enfrentas? Para inmersiones más profundas, explora la documentación de OpenAI. ¡Construye con audacia!