Los desarrolladores buscan constantemente modelos de lenguaje potentes que ofrezcan un rendimiento robusto en diversas aplicaciones. Zhipu AI presenta GLM-4.6, una iteración avanzada de la serie GLM que amplía los límites de las capacidades de la inteligencia artificial. Este modelo se basa en versiones anteriores al incorporar mejoras significativas en el manejo del contexto, el razonamiento y la utilidad práctica. Los ingenieros integran GLM-4.6 en sus flujos de trabajo para abordar tareas complejas, desde la generación de código hasta la creación de contenido, con mayor eficiencia y precisión.
Zhipu AI diseña GLM-4.6 como parte del GLM Coding Plan, un servicio de suscripción que comienza a un precio asequible. Los usuarios acceden a este modelo a través de herramientas integradas como Claude Code, Cline, OpenCode y otras, lo que permite un desarrollo asistido por IA sin interrupciones. El modelo sobresale en escenarios del mundo real, donde procesa contextos extensos y genera resultados de alta calidad. Además, GLM-4.6 demuestra un rendimiento superior en los benchmarks, rivalizando con líderes internacionales como Claude Sonnet 4. Esto lo posiciona como una opción principal para los desarrolladores en China y más allá que requieren un soporte de IA confiable.
Pasando de comprender la base del modelo, examinemos sus características principales y cómo benefician las implementaciones técnicas.
¿Qué es GLM-4.6?
Zhipu AI desarrolla GLM-4.6 como un modelo de lenguaje grande optimizado para una amplia gama de tareas técnicas y creativas. El modelo presenta una arquitectura de Mezcla de Expertos (MoE) de 355B parámetros, que permite una computación eficiente manteniendo un alto rendimiento. Los usuarios aprecian su ventana de contexto expandida de 200K tokens, una mejora notable con respecto al límite de 128K en versiones anteriores. Esta expansión permite al modelo gestionar interacciones complejas y de formato largo sin perder coherencia.
Además, GLM-4.6 admite modalidades de entrada y salida de texto, lo que lo hace versátil para aplicaciones que exigen un procesamiento preciso del lenguaje. El límite máximo de tokens de salida alcanza los 128K, proporcionando un amplio espacio para respuestas detalladas. Los desarrolladores aprovechan estas especificaciones para construir sistemas que manejan datos extensos, como el análisis de documentos o cadenas de razonamiento de varios pasos.
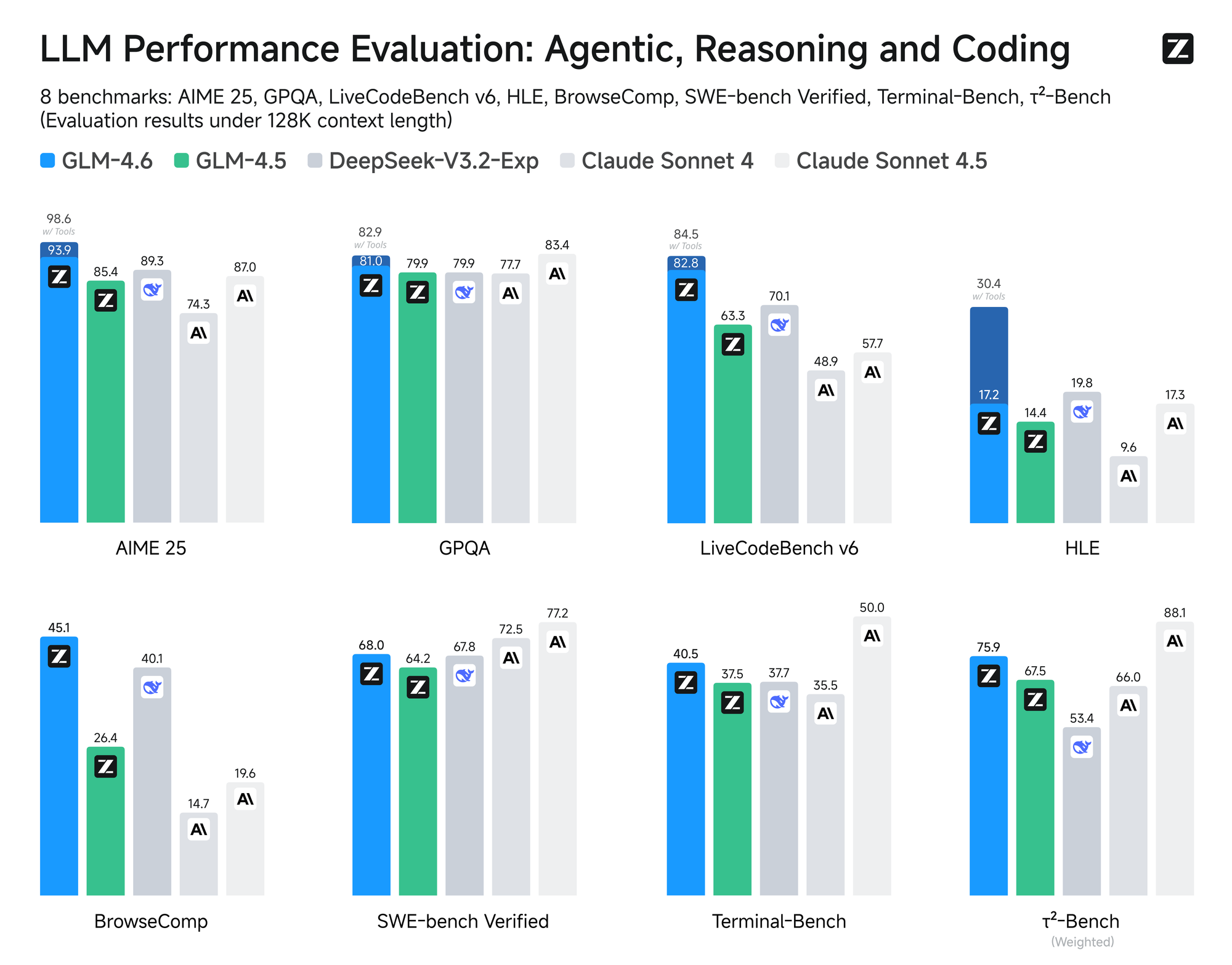
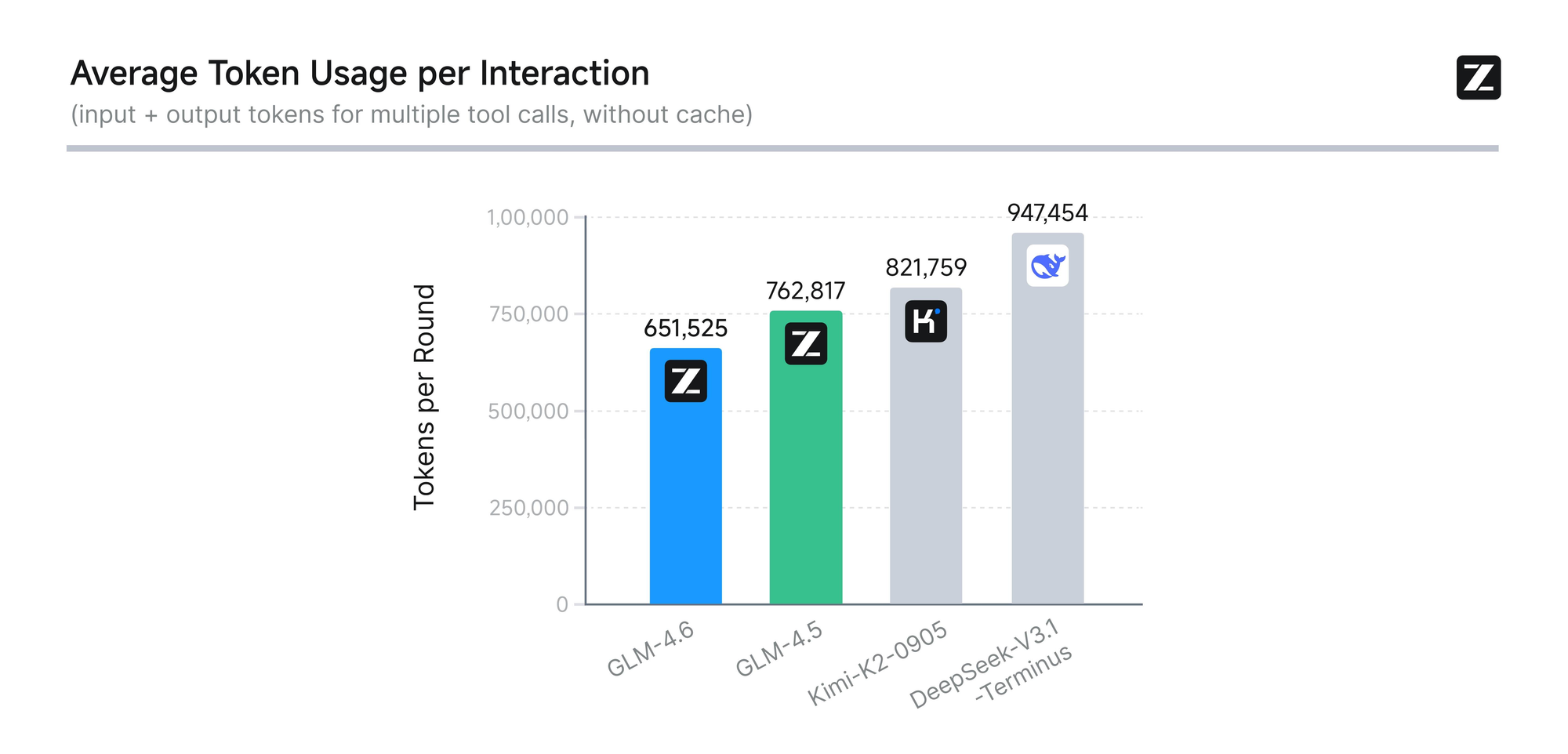
El modelo se somete a una evaluación rigurosa en ocho benchmarks autorizados, incluidos AIME 25, GPQA, LCB v6, HLE y SWE-Bench Verified. Los resultados muestran que GLM-4.6 tiene un rendimiento a la par de modelos líderes como Claude Sonnet 4 y 4.6. Por ejemplo, en pruebas de codificación del mundo real realizadas dentro del entorno Claude Code, GLM-4.6 supera a sus competidores en 74 escenarios prácticos. Logra esto con una eficiencia más del 30% mayor en el consumo de tokens, reduciendo los costos operativos para usuarios de alto volumen.
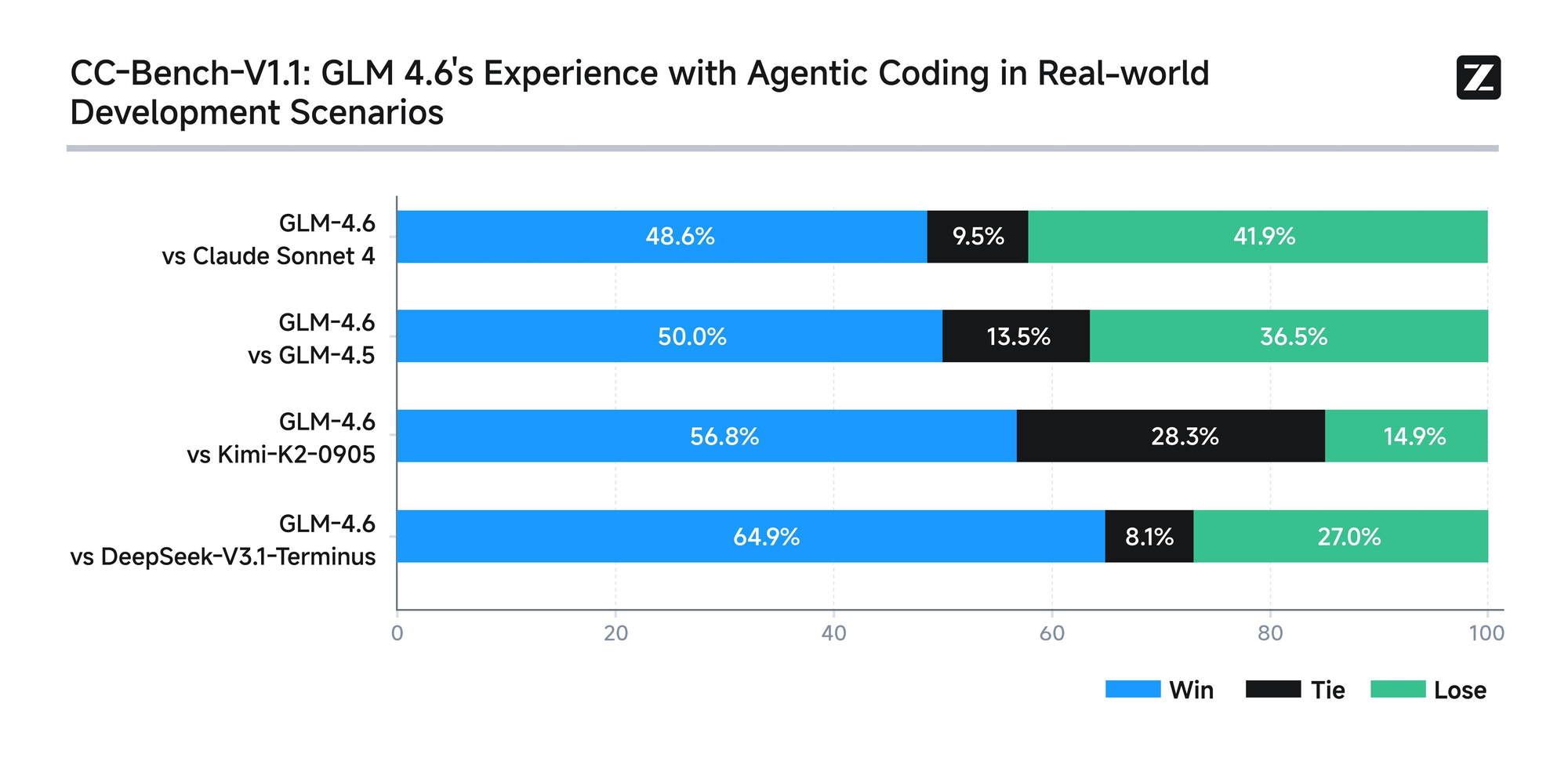
Además, Zhipu AI se compromete con la transparencia al publicar todas las preguntas de prueba y las trayectorias de los agentes. Esta práctica permite a los desarrolladores verificar las afirmaciones y reproducir los resultados, fomentando la confianza en la tecnología. GLM-4.6 también integra capacidades de razonamiento avanzadas, lo que permite el uso de herramientas durante la inferencia. Esta característica mejora su utilidad en marcos de agentes, donde el modelo planifica y ejecuta tareas de forma autónoma.
Más allá de la codificación, GLM-4.6 destaca en otros dominios. Refina la escritura para alinearse estrechamente con las preferencias humanas, mejorando el estilo, la legibilidad y la autenticidad en la interpretación de roles. En tareas de traducción, el modelo se optimiza para idiomas minoritarios como el francés, ruso, japonés y coreano, asegurando la coherencia semántica en contextos informales. Los creadores de contenido lo utilizan para novelas, guiones y redacción publicitaria, beneficiándose de la expansión contextual y el matiz emocional.
El desarrollo de personajes virtuales representa otra fortaleza, ya que GLM-4.6 mantiene un tono consistente en conversaciones de múltiples turnos. Esto lo hace ideal para la IA social y la personificación de marcas. En la búsqueda inteligente y la investigación profunda, el modelo mejora la comprensión de la intención y la síntesis de resultados, ofreciendo resultados perspicaces.
En general, GLM-4.6 empodera a los desarrolladores para crear aplicaciones más inteligentes. Su combinación de procesamiento de contexto largo, uso eficiente de tokens y amplia aplicabilidad lo distingue en el panorama de la IA. Ahora que comprendemos la esencia del modelo, pasamos a acceder a su API para una implementación práctica.
Cómo acceder a la API de GLM-4.6
Zhipu AI proporciona acceso directo a la API de GLM-4.6 a través de su plataforma abierta. Los desarrolladores comienzan registrándose para obtener una cuenta en el sitio web de Zhipu AI, específicamente en open.bigmodel.cn o z.ai. El proceso requiere verificar un correo electrónico o número de teléfono para garantizar un registro seguro.
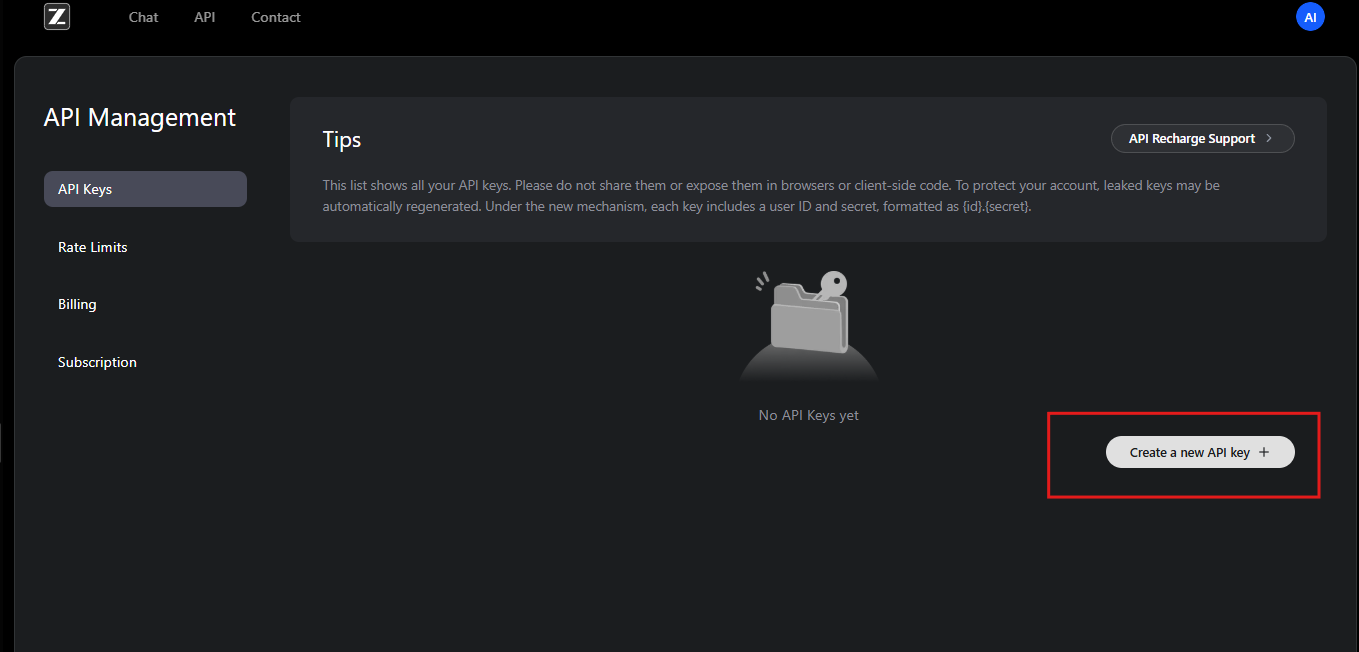
Una vez registrados, los usuarios se suscriben al GLM Coding Plan. Este plan desbloquea GLM-4.6 y modelos relacionados. Los suscriptores obtienen acceso al panel de control de la API, donde generan claves de API. Estas claves sirven como credenciales para autenticar las solicitudes.
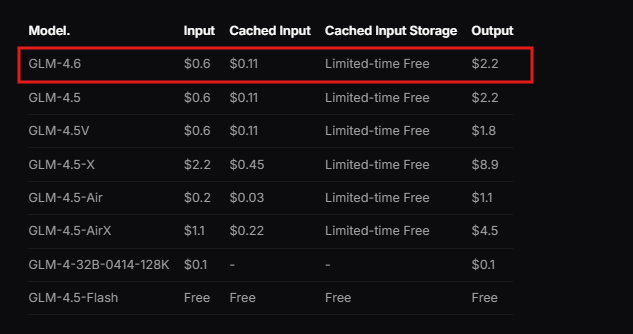
Además, Zhipu AI ofrece documentación que detalla los pasos de integración. Los desarrolladores revisan este recurso para comprender los requisitos previos, como los entornos de programación compatibles. La API sigue un diseño RESTful, compatible con clientes HTTP estándar.
Para comenzar, los usuarios navegan a la sección de gestión de API en su cuenta. Aquí, crean una nueva clave de API y anotan su valor de forma segura. Zhipu AI recomienda rotar las claves periódicamente por seguridad. Además, la plataforma proporciona cuotas de uso basadas en los niveles de suscripción, lo que evita el uso excesivo.
Si los desarrolladores encuentran problemas, el equipo de soporte de Zhipu AI ayuda por correo electrónico o foros. También ofrecen recursos comunitarios para solucionar problemas de acceso comunes. Con el acceso asegurado, el siguiente paso implica configurar la autenticación para interactuar con la API de GLM-4.6 de manera efectiva.
Autenticación y configuración para la API de GLM-4.6
La autenticación constituye la columna vertebral de las interacciones seguras con la API. Zhipu AI emplea la autenticación de token Bearer para la API de GLM-4.6. Los desarrolladores incluyen la clave de API en el encabezado de Autorización de cada solicitud.
Para la configuración, instala las bibliotecas necesarias en tu entorno de desarrollo. Los usuarios de Python, por ejemplo, utilizan la biblioteca `requests`. La importas y configuras los encabezados de la siguiente manera:
import requests
api_key = "your-api-key"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
Este código prepara el entorno para enviar solicitudes. De manera similar, en JavaScript con Node.js, los desarrolladores usan la API `fetch` o la biblioteca `axios`. Establecen los encabezados en el objeto `options`.
Además, asegúrate de que tu sistema cumpla con los requisitos de red. El endpoint de la API de GLM-4.6 reside en https://api.z.ai/api/paas/v4/chat/completions. Prueba la conectividad haciendo ping al dominio o enviando una solicitud simple.
Durante la configuración, los desarrolladores configuran variables de entorno para almacenar la clave de API de forma segura. Esta práctica evita codificar información sensible en los scripts. Herramientas como `dotenv` en Python o `process.env` en Node.js facilitan esto.
Si utilizas un proxy o VPN, verifica que permita el tráfico a los servidores de Zhipu AI. Los fallos de autenticación a menudo se deben a un formato de clave incorrecto o a suscripciones caducadas. Zhipu AI registra los errores en las respuestas, lo que ayuda a diagnosticar problemas.
Una vez autenticados, los desarrolladores proceden a explorar los endpoints. Esta configuración garantiza un acceso fiable y seguro a las capacidades de GLM-4.6.
Explorando los Endpoints de la API de GLM-4.6
La API de GLM-4.6 se centra en un endpoint principal para las finalizaciones de chat. Los desarrolladores envían solicitudes POST a https://api.z.ai/api/paas/v4/chat/completions para generar respuestas.
Este endpoint maneja tanto el modo básico como el modo de streaming. En el modo básico, el servidor procesa toda la solicitud y devuelve una respuesta completa. El modo de streaming, sin embargo, entrega la salida de forma incremental, ideal para aplicaciones en tiempo real.
Para invocar el endpoint, construye un payload JSON con los parámetros requeridos. El campo `model` especifica "glm-4.6". El array `messages` contiene pares `role-content`, simulando conversaciones.
Por ejemplo, una solicitud `curl` básica se ve así:
curl -X POST "https://api.z.ai/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-4.6",
"messages": [
{"role": "user", "content": "Generate a Python function for sorting a list."}
]
}'
El servidor responde con JSON que contiene el contenido generado. Los desarrolladores analizan esto para extraer los mensajes del asistente.
Además, el endpoint admite funciones avanzadas como los pasos de pensamiento. Establece el objeto `thinking` para habilitar el razonamiento detallado en las salidas.
Comprender este endpoint permite a los desarrolladores construir sistemas de IA interactivos. A continuación, desglosaremos los parámetros de la solicitud en detalle.
Explicación detallada de los parámetros de solicitud de la API de GLM-4.6
Los parámetros de solicitud controlan el comportamiento de la API de GLM-4.6. El parámetro `model` exige "glm-4.6" para seleccionar esta versión específica.
El array `messages` impulsa la conversación. Cada objeto incluye un `role` – "user" para las entradas, "assistant" para las respuestas anteriores – y `content` como cadenas de texto. Los desarrolladores estructuran diálogos de múltiples turnos alternando los roles.
Además, `max_tokens` limita la longitud de la respuesta, evitando una salida excesiva. Establécelo en 4096 para obtener resultados equilibrados. `Temperature` ajusta la aleatoriedad; valores más bajos como 0.6 producen salidas deterministas, mientras que los más altos fomentan la creatividad.
Para el streaming, incluye `"stream": true`. Esto cambia el formato de la respuesta a datos en fragmentos.
El parámetro `thinking` habilita el razonamiento paso a paso. Establece `"thinking": {"type": "enabled"}` para incluir pensamientos intermedios en las respuestas.
Otros parámetros opcionales incluyen `top_p` para el muestreo de núcleo y `presence_penalty` para desalentar la repetición. Los desarrolladores ajustan estos según los casos de uso.
Los parámetros inválidos desencadenan respuestas de error con códigos como 400 para solicitudes incorrectas. Valida siempre los payloads antes de enviarlos.
Al dominar estos parámetros, los desarrolladores personalizan las llamadas a la API de GLM-4.6 para un rendimiento óptimo.
Manejo de respuestas de la API de GLM-4.6
Las respuestas de la API de GLM-4.6 llegan en formato JSON. Los desarrolladores analizan el array `choices` para acceder al contenido generado.
En modo básico, la respuesta incluye:
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1694123456,
"model": "glm-4.6",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Your generated text here."
},
"finish_reason": "stop"
}
]
}
Extrae el campo `content` para usarlo en las aplicaciones.
En modo streaming, las respuestas se transmiten como Eventos Enviados por el Servidor (SSE). Cada fragmento sigue:
data: {"id":"chatcmpl-...","choices":[{"delta":{"content":" partial text"}}]}
Los desarrolladores acumulan los `deltas` para construir la salida completa.
El manejo de errores implica verificar los códigos de estado. Un 401 indica un fallo de autenticación, mientras que un 429 señala límites de tasa.
Registra las respuestas para depuración. Este enfoque garantiza una integración robusta con la API de GLM-4.6.
Ejemplos de código para integrar la API de GLM-4.6
Los desarrolladores implementan la API de GLM-4.6 en varios lenguajes. En Python, usa `requests` para una llamada básica:
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
payload = {
"model": "glm-4.6",
"messages": [{"role": "user", "content": "Explain quantum computing."}],
"max_tokens": 500,
"temperature": 0.7
}
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Este código envía una consulta e imprime la respuesta.
En JavaScript con Node.js:
const fetch = require('node-fetch');
const url = 'https://api.z.ai/api/paas/v4/chat/completions';
const payload = {
model: 'glm-4.6',
messages: [{ role: 'user', content: 'Write a haiku about AI.' }],
max_tokens: 100
};
const headers = {
'Authorization': 'Bearer your-api-key',
'Content-Type': 'application/json'
};
fetch(url, {
method: 'POST',
body: JSON.stringify(payload),
headers
})
.then(res => res.json())
.then(data => console.log(data.choices[0].message.content));
Para el streaming en Python, usa bibliotecas de análisis SSE como `sseclient`.
Estos ejemplos demuestran una integración práctica, lo que permite a los desarrolladores prototipar rápidamente.
Uso de Apidog para probar la API de GLM-4.6
Apidog sirve como una excelente herramienta para probar la API de GLM-4.6. Esta plataforma todo en uno permite a los desarrolladores diseñar, depurar, simular y automatizar las interacciones con la API.
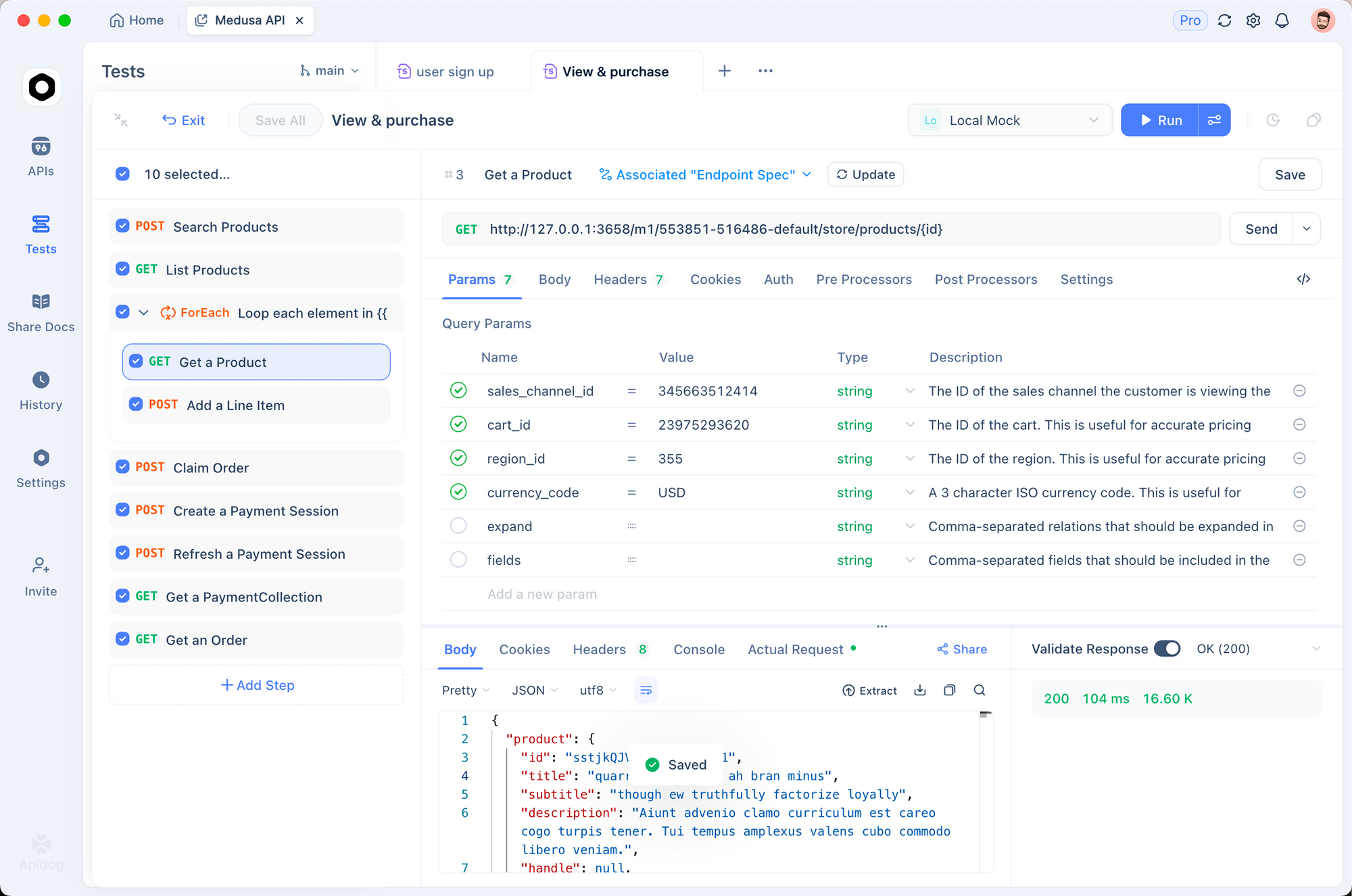
Comienza descargando Apidog desde apidog.com y creando un proyecto. Importa el endpoint de la API de GLM-4.6 añadiendo una nueva API con la URL https://api.z.ai/api/paas/v4/chat/completions.
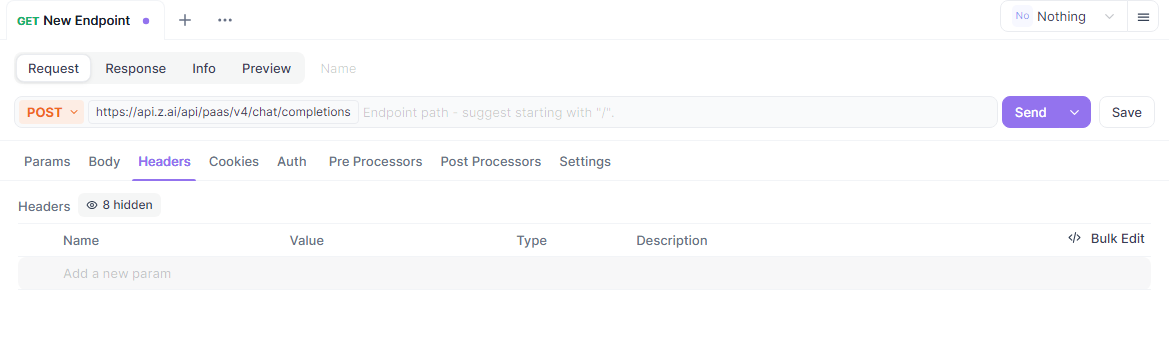
Establece la autenticación en la sección de encabezados de Apidog, añadiendo "Authorization: Bearer your-api-key". Configura el cuerpo de la solicitud con parámetros JSON como `model` y `messages`.
Apidog permite enviar solicitudes y ver las respuestas en una interfaz fácil de usar. Los desarrolladores prueban variaciones duplicando solicitudes y ajustando parámetros.
Además, automatiza las pruebas creando escenarios en Apidog. Define aserciones para validar el contenido de la respuesta, asegurando que la API de GLM-4.6 se comporte como se espera.
Los servidores simulados en Apidog simulan respuestas para el desarrollo offline. Esta característica acelera la creación de prototipos sin llamadas a la API en vivo.

Al incorporar Apidog, los desarrolladores optimizan los flujos de trabajo de la API de GLM-4.6, reduciendo errores y acelerando la implementación.
Mejores prácticas y límites de tasa para la API de GLM-4.6
Adherirse a las mejores prácticas maximiza el potencial de la API de GLM-4.6. Los desarrolladores monitorean el uso para mantenerse dentro de los límites de tasa, típicamente definidos por tokens por minuto o solicitudes por día según la suscripción.
Implementa la retroceso exponencial para reintentos en errores como 429. Esto evita sobrecargar el servidor.
Optimiza los prompts para mayor claridad para mejorar la calidad de la respuesta. Utiliza mensajes del sistema para establecer el contexto, guiando al modelo de manera efectiva.
Protege las claves de API en entornos de producción. Evita exponerlas en el código del lado del cliente.
Registra las interacciones para auditoría y análisis de rendimiento. Estos datos informan las mejoras.
Maneja casos extremos, como respuestas vacías o tiempos de espera, con mecanismos de respaldo.
Zhipu AI actualiza los límites de tasa en la documentación; revísalos regularmente.
Seguir estas prácticas garantiza un uso eficiente y fiable de la API de GLM-4.6.
Uso avanzado de la API de GLM-4.6
Los usuarios avanzados exploran el streaming para aplicaciones interactivas. Establece `"stream": true` y procesa los fragmentos en tiempo real.
Incorpora herramientas incluyendo llamadas a funciones en los mensajes. GLM-4.6 admite la invocación de herramientas, lo que permite a los agentes ejecutar acciones externas.
Por ejemplo, define herramientas en el payload:
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {...}
}
}
]
El modelo responde con llamadas a herramientas si es necesario.
Ajusta la temperatura para tareas específicas; baja para consultas fácticas, alta para las creativas.
Combínalo con contextos largos para el resumen de documentos. Introduce textos grandes en los mensajes.
Intégralo en frameworks de agentes como LangChain para flujos de trabajo complejos.
Estas técnicas desbloquean todo el potencial de GLM-4.6 en sistemas sofisticados.
Conclusión
La API de GLM-4.6 ofrece a los desarrolladores una potente herramienta para la innovación en IA. Siguiendo esta guía, la integrarás sin problemas en tus proyectos. Experimenta con las funciones, pruébala con Apidog y aplica las mejores prácticas para el éxito. Zhipu AI continúa evolucionando GLM-4.6, prometiendo capacidades aún mayores en el futuro.