
El panorama de la IA de código abierto acaba de presenciar otro cambio sísmico. Z.ai, la empresa china de IA antes conocida como Zhipu, ha lanzado GLM-4.5 y GLM-4.5 Air, prometiendo superar a DeepSeek y establecer nuevos estándares para el rendimiento y la accesibilidad de la IA. Estos modelos representan más que mejoras incrementales; encarnan un replanteamiento fundamental de cómo deberían funcionar el razonamiento híbrido y las capacidades de agente en entornos de producción.
El lanzamiento llega en un momento crucial en el que los desarrolladores demandan cada vez más alternativas rentables a los modelos propietarios sin sacrificar la capacidad. Tanto GLM-4.5 como GLM-4.5 Air cumplen esta promesa a través de sofisticadas innovaciones arquitectónicas que maximizan la eficiencia manteniendo un rendimiento de vanguardia en tareas de razonamiento, codificación y multimodales.
Comprendiendo la Revolución Arquitectónica de GLM-4.5
La serie GLM-4.5 representa una desviación significativa de las arquitecturas de transformadores tradicionales. Construido sobre una arquitectura completamente auto-desarrollada, GLM-4.5 logra un rendimiento SOTA en modelos de código abierto a través de varias innovaciones clave que lo distinguen de sus competidores.
GLM-4.5 cuenta con 355 mil millones de parámetros totales con 32 mil millones de parámetros activos, mientras que GLM-4.5-Air adopta un diseño más compacto con 106 mil millones de parámetros totales y 12 mil millones de parámetros activos. Esta configuración de parámetros refleja un cuidadoso equilibrio entre la eficiencia computacional y la capacidad del modelo, lo que permite que ambos modelos ofrezcan un rendimiento impresionante manteniendo costos de inferencia razonables.
Los modelos utilizan una sofisticada arquitectura de Mezcla de Expertos (MoE) que activa solo un subconjunto de parámetros durante la inferencia. Ambos aprovechan el diseño de Mezcla de Expertos para una eficiencia óptima, permitiendo que GLM-4.5 procese tareas complejas utilizando solo 32 mil millones de sus 355 mil millones de parámetros. Mientras tanto, GLM-4.5 Air mantiene capacidades de razonamiento comparables con solo 12 mil millones de parámetros activos de su grupo total de 106 mil millones de parámetros.
Este enfoque arquitectónico aborda directamente uno de los desafíos más apremiantes en la implementación de modelos de lenguaje grandes: la sobrecarga computacional de la inferencia. Los modelos densos tradicionales requieren activar todos los parámetros para cada operación de inferencia, creando una carga computacional innecesaria para tareas más simples. La serie GLM-4.5 resuelve esto mediante un enrutamiento inteligente de parámetros que adapta la complejidad computacional a los requisitos de la tarea.
Además, los modelos admiten ventanas de contexto de hasta 128k de entrada y 96k de salida, lo que proporciona capacidades sustanciales de manejo de contexto que permiten un razonamiento sofisticado de formato largo y un análisis documental exhaustivo. Esta ventana de contexto extendida resulta particularmente valiosa para aplicaciones de agente donde los modelos deben mantener la conciencia de interacciones complejas de varios pasos.
Características de Rendimiento Optimizadas de GLM-4.5 Air
GLM-4.5 Air emerge como el campeón de eficiencia de la serie, diseñado específicamente para escenarios donde los recursos computacionales requieren una gestión cuidadosa. GLM-4.5-Air es un modelo fundamental diseñado específicamente para aplicaciones de agente de IA, construido sobre una arquitectura de Mezcla de Expertos (MoE) que prioriza la velocidad y la optimización de recursos sin comprometer las capacidades centrales.
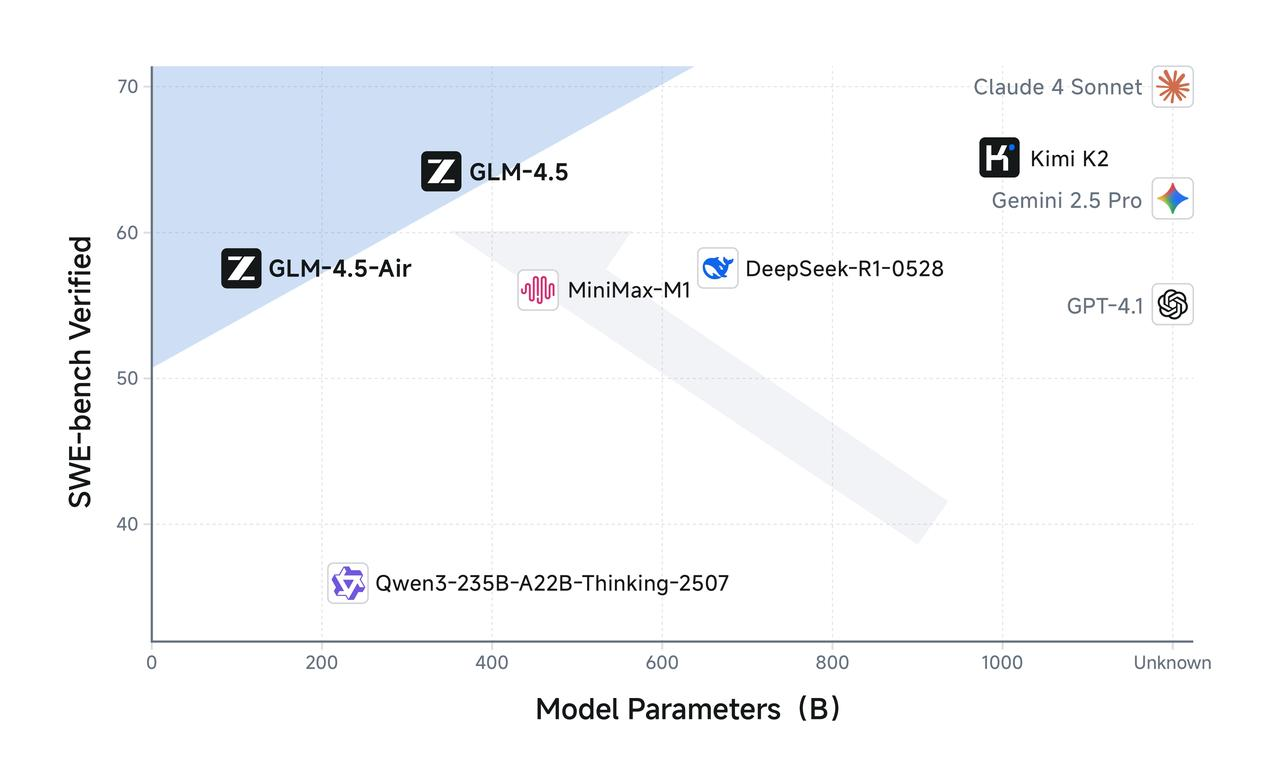
La variante Air demuestra cómo una reducción de parámetros bien pensada puede mantener la calidad del modelo al tiempo que mejora drásticamente la viabilidad de la implementación. Con 106 mil millones de parámetros totales y 12 mil millones de parámetros activos, GLM-4.5 Air logra notables ganancias de eficiencia que se traducen directamente en costos de inferencia reducidos y tiempos de respuesta más rápidos.
Los requisitos de memoria representan otra área donde GLM-4.5 Air sobresale. GLM-4.5-Air requiere 16 GB de memoria GPU (cuantificada a INT4 en ~12 GB), lo que lo hace accesible para organizaciones con limitaciones de hardware moderadas. Este factor de accesibilidad resulta crucial para una adopción generalizada, ya que muchos equipos de desarrollo no pueden justificar los costos de infraestructura asociados con modelos más grandes.
La optimización se extiende más allá de la eficiencia de parámetros pura para abarcar la capacitación especializada para tareas orientadas a agentes. Se ha optimizado ampliamente para el uso de herramientas, la navegación web, el desarrollo de software y el desarrollo de front-end, lo que permite una integración perfecta con agentes de codificación. Esta especialización significa que GLM-4.5 Air ofrece un rendimiento superior en tareas de desarrollo prácticas en comparación con modelos de propósito general de tamaño similar.
La latencia de respuesta se vuelve particularmente importante en aplicaciones interactivas donde los usuarios esperan una retroalimentación casi instantánea. El recuento de parámetros reducido de GLM-4.5 Air y la tubería de inferencia optimizada permiten tiempos de respuesta de menos de un segundo para la mayoría de las consultas, lo que lo hace adecuado para aplicaciones en tiempo real como la finalización de código, la depuración interactiva y la generación de documentación en vivo.
Implementación y Beneficios del Razonamiento Híbrido
La característica definitoria de ambos modelos GLM-4.5 radica en sus capacidades de razonamiento híbrido. Tanto GLM-4.5 como GLM-4.5-Air son modelos de razonamiento híbrido que proporcionan dos modos: modo de pensamiento para razonamiento complejo y uso de herramientas, y modo sin pensamiento para respuestas inmediatas. Esta arquitectura de doble modo representa una innovación fundamental en cómo los modelos de IA manejan diferentes tipos de tareas cognitivas.
El modo de pensamiento se activa cuando los modelos encuentran problemas complejos que requieren razonamiento de varios pasos, uso de herramientas o análisis extendido. Durante el modo de pensamiento, los modelos generan pasos de razonamiento intermedios que permanecen visibles para los desarrolladores pero ocultos para los usuarios finales. Esta transparencia permite la depuración y optimización de los procesos de razonamiento mientras se mantienen interfaces de usuario limpias.
Por el contrario, el modo sin pensamiento maneja consultas sencillas que se benefician de respuestas inmediatas sin una sobrecarga de razonamiento extendida. El modelo determina automáticamente qué modo emplear en función de la complejidad y el contexto de la consulta, lo que garantiza una utilización óptima de los recursos en diversos casos de uso.
Este enfoque híbrido resuelve un desafío persistente en los sistemas de IA de producción: equilibrar la velocidad de respuesta con la calidad del razonamiento. Los modelos tradicionales sacrifican la velocidad por un razonamiento exhaustivo o proporcionan respuestas rápidas pero potencialmente superficiales. El sistema híbrido de GLM-4.5 elimina esta compensación al adaptar la complejidad del razonamiento a los requisitos de la tarea.
Ambos proporcionan un modo de pensamiento para tareas complejas y un modo sin pensamiento para respuestas inmediatas, creando una experiencia de usuario fluida que se adapta a las diferentes demandas cognitivas. Los desarrolladores pueden configurar los parámetros de selección de modo para ajustar el equilibrio entre la velocidad y la profundidad del razonamiento en función de los requisitos específicos de la aplicación.
El modo de pensamiento resulta particularmente valioso para aplicaciones de agente donde los modelos deben planificar acciones de varios pasos, evaluar opciones de uso de herramientas y mantener un razonamiento coherente a lo largo de interacciones extendidas. Mientras tanto, el modo sin pensamiento garantiza un rendimiento receptivo para consultas simples como búsquedas de hechos o tareas sencillas de finalización de código.
Especificaciones Técnicas y Detalles de Entrenamiento
La base técnica que subyace a las impresionantes capacidades de GLM-4.5 refleja un extenso esfuerzo de ingeniería y metodologías de entrenamiento innovadoras. Entrenados con 15 billones de tokens, con soporte para ventanas de contexto de hasta 128k de entrada y 96k de salida, los modelos demuestran la escala y sofisticación requeridas para un rendimiento de vanguardia.
La curación de datos de entrenamiento representa un factor crítico en la calidad del modelo, particularmente para aplicaciones especializadas como la generación de código y el razonamiento de agentes. El corpus de entrenamiento de 15 billones de tokens incorpora diversas fuentes, incluidos repositorios de código, documentación técnica, ejemplos de razonamiento y contenido multimodal que permite una comprensión integral en todos los dominios.
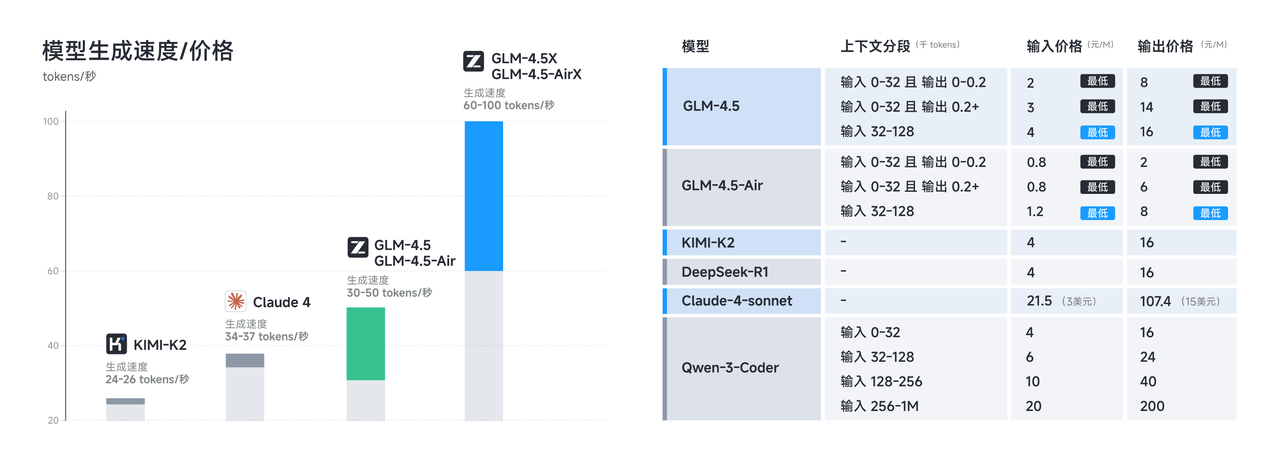
Las capacidades de la ventana de contexto distinguen a GLM-4.5 de muchos modelos de la competencia. GLM-4.5 proporciona una longitud de contexto de 128k y capacidad de llamada a funciones nativa, lo que permite un análisis sofisticado de formato largo y conversaciones de múltiples turnos sin truncamiento de contexto. La ventana de contexto de salida de 96k garantiza que los modelos puedan generar respuestas completas sin limitaciones de longitud artificiales.
La llamada a funciones nativa representa otra ventaja arquitectónica que elimina la necesidad de capas de orquestación externas. Los modelos pueden invocar directamente herramientas y API externas como parte de su proceso de razonamiento, creando flujos de trabajo de agente más eficientes y confiables. Esta capacidad resulta esencial para aplicaciones de producción donde los modelos deben interactuar con bases de datos, servicios externos y herramientas de desarrollo.
El proceso de entrenamiento incorpora una optimización especializada para tareas de agente, asegurando que los modelos desarrollen fuertes capacidades en el uso de herramientas, razonamiento de varios pasos y mantenimiento de contexto. La arquitectura unificada para flujos de trabajo de razonamiento, codificación y percepción-acción multimodal permite transiciones fluidas entre diferentes tipos de tareas dentro de interacciones individuales.
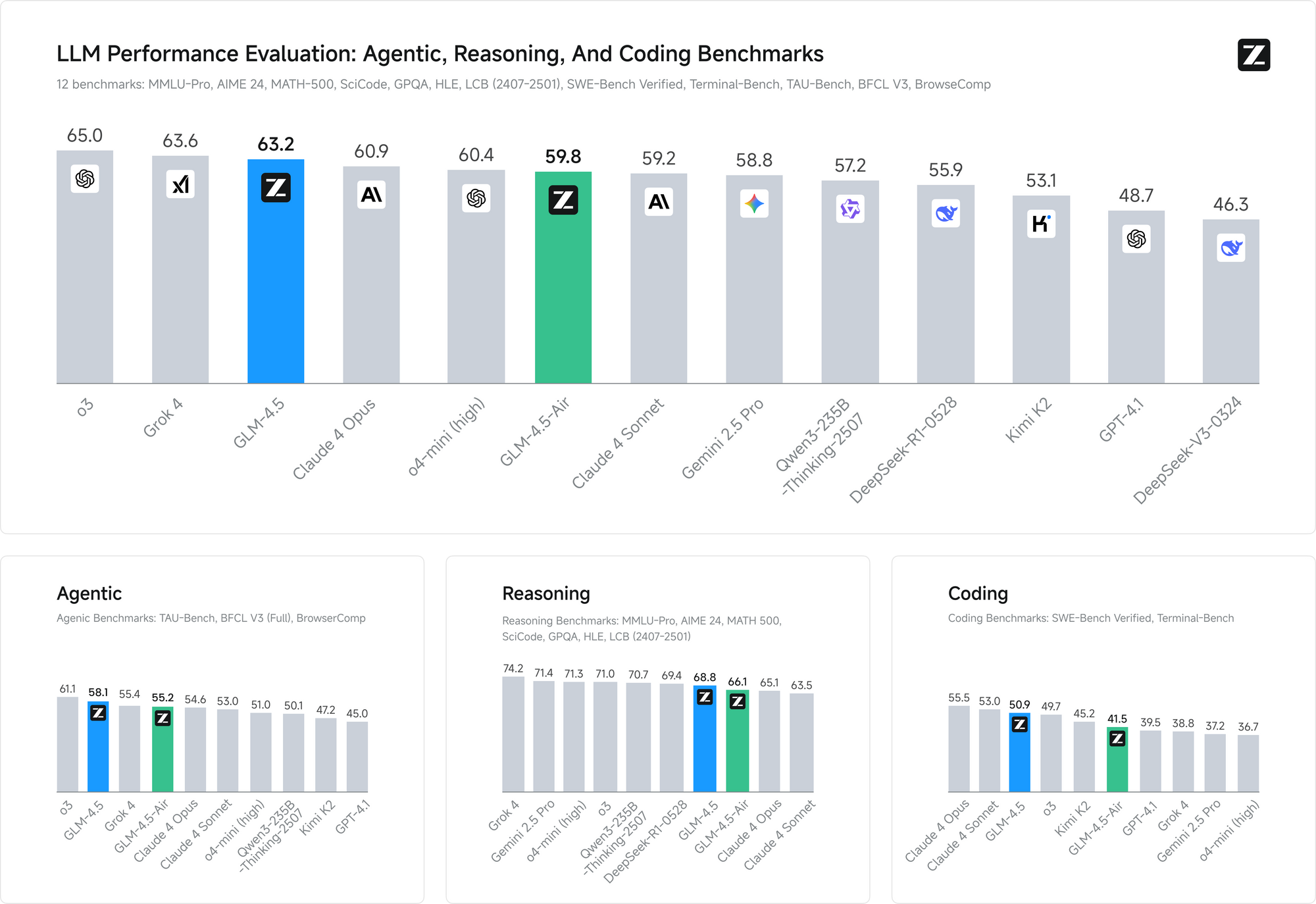
Los puntos de referencia de rendimiento validan la efectividad de estos enfoques de entrenamiento. En ambos puntos de referencia, GLM-4.5 iguala el rendimiento de Claude en las evaluaciones de capacidad de agente, demostrando una capacidad competitiva frente a los principales modelos propietarios mientras mantiene la accesibilidad de código abierto.
Ventajas de Licenciamiento e Implementación Comercial
El licenciamiento de código abierto representa una de las ventajas competitivas más significativas de GLM-4.5 en el panorama actual de la IA. Los modelos base, los modelos híbridos (de pensamiento/no pensamiento) y las versiones FP8 se lanzan para uso comercial sin restricciones y desarrollo secundario bajo la licencia MIT, lo que proporciona una libertad sin precedentes para la implementación comercial.
Este enfoque de licenciamiento elimina muchas restricciones que limitan otros modelos de código abierto. Las organizaciones pueden modificar, redistribuir y comercializar implementaciones de GLM-4.5 sin tarifas de licencia ni restricciones de uso. La licencia MIT aborda específicamente las preocupaciones comerciales que a menudo complican las implementaciones de IA empresarial.
Múltiples Métodos de Acceso e Integración de Plataformas
GLM-4.5 y GLM-4.5 Air ofrecen a los desarrolladores múltiples vías de acceso, cada una optimizada para diferentes casos de uso y requisitos técnicos. Comprender estas opciones de implementación permite a los equipos seleccionar el método de integración más apropiado para sus aplicaciones específicas.
Sitio Web Oficial y Acceso Directo a la API
El método de acceso principal implica el uso de la plataforma oficial de Z.ai en chat.z.ai, que proporciona una interfaz fácil de usar para la interacción inmediata con el modelo. Esta interfaz basada en web permite la creación rápida de prototipos y pruebas sin requerir trabajo de integración técnica. Los desarrolladores pueden evaluar las capacidades del modelo, probar estrategias de ingeniería de prompts y validar casos de uso antes de comprometerse con las implementaciones de API.
El acceso directo a la API a través de los puntos finales oficiales de Z.ai proporciona capacidades de integración de nivel de producción con documentación y soporte completos. La API oficial ofrece un control granular sobre los parámetros del modelo, incluida la selección del modo de razonamiento híbrido, la utilización de la ventana de contexto y las opciones de formato de respuesta.
Integración de OpenRouter para un Acceso Simplificado
OpenRouter proporciona acceso simplificado a los modelos GLM-4.5 a través de su plataforma API unificada en openrouter.ai/z-ai. Este método de integración resulta particularmente valioso para los desarrolladores que ya utilizan la infraestructura multimodo de OpenRouter, ya que elimina la necesidad de una gestión de claves API y patrones de integración separados.
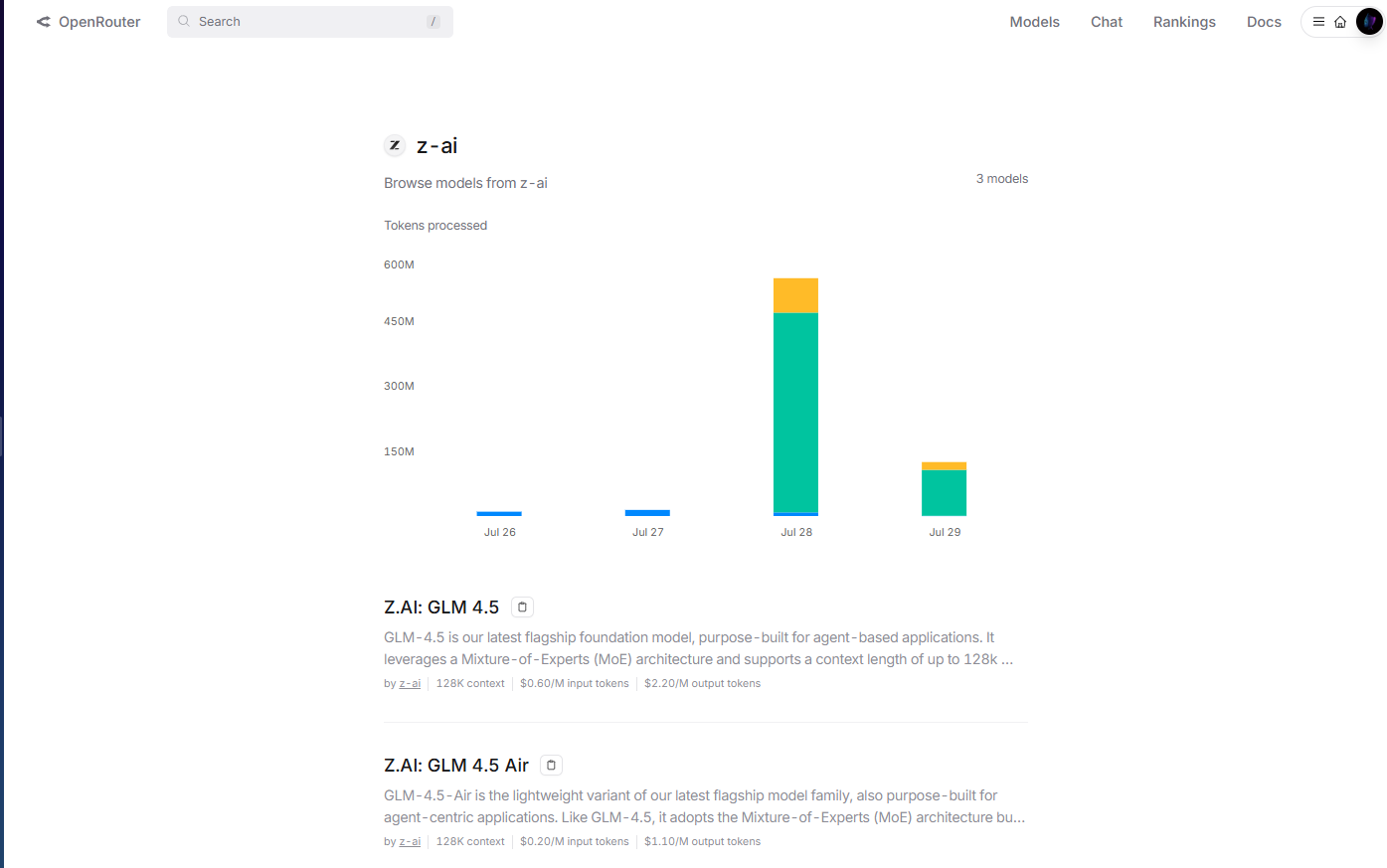
La implementación de OpenRouter maneja la autenticación, la limitación de velocidad y el manejo de errores automáticamente, reduciendo la complejidad de la integración para los equipos de desarrollo. Además, el formato API estandarizado de OpenRouter permite un fácil cambio de modelo y pruebas A/B entre GLM-4.5 y otros modelos disponibles sin modificaciones de código.
La gestión de costos se vuelve más transparente a través del sistema de facturación unificado de OpenRouter, que proporciona análisis de uso detallados y controles de gasto en múltiples proveedores de modelos. Este enfoque centralizado simplifica la gestión del presupuesto para las organizaciones que utilizan múltiples modelos de IA en sus aplicaciones.
Hugging Face Hub para Implementación de Código Abierto
Hugging Face Hub aloja los modelos GLM-4.5, proporcionando tarjetas de modelo completas, documentación técnica y ejemplos de uso impulsados por la comunidad. Esta plataforma resulta esencial para los desarrolladores que prefieren patrones de implementación de código abierto o requieren una amplia personalización del modelo.
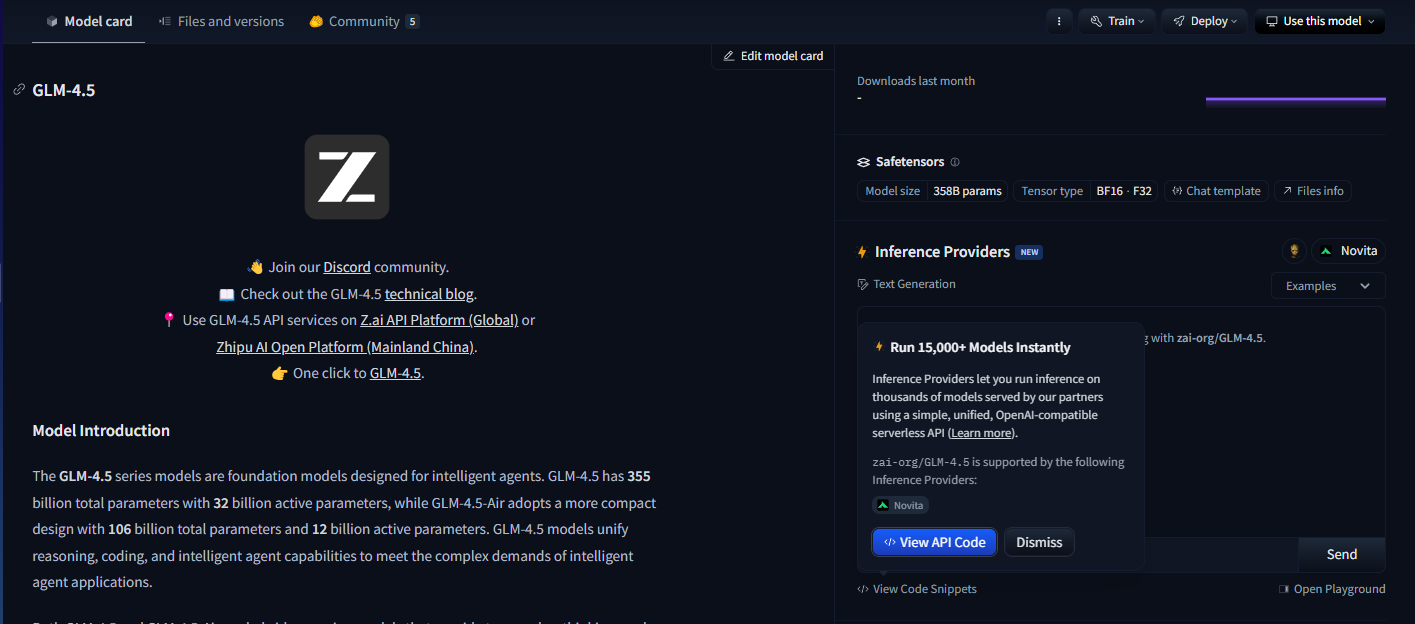
La integración de Hugging Face permite la implementación local utilizando la biblioteca Transformers, lo que brinda a las organizaciones control total sobre el alojamiento del modelo y la privacidad de los datos. Los desarrolladores pueden descargar los pesos del modelo directamente, implementar tuberías de inferencia personalizadas y optimizar las configuraciones de implementación para entornos de hardware específicos.
Opciones de Implementación Autoalojada
Las organizaciones con requisitos estrictos de privacidad de datos o necesidades de infraestructura especializadas pueden implementar modelos GLM-4.5 utilizando configuraciones autoalojadas. La licencia MIT permite la implementación sin restricciones en entornos de nube privada, infraestructura local o arquitecturas híbridas.
La implementación autoalojada proporciona el máximo control sobre el comportamiento del modelo, las configuraciones de seguridad y los patrones de integración. Las organizaciones pueden implementar sistemas de autenticación personalizados, infraestructura de monitoreo especializada y optimizaciones específicas del dominio sin dependencias externas.
La implementación basada en contenedores utilizando Docker o Kubernetes permite implementaciones autoalojadas escalables que pueden adaptarse a las diferentes demandas de carga de trabajo. Estos patrones de implementación resultan particularmente valiosos para organizaciones con experiencia existente en orquestación de contenedores.
Integración con Flujos de Trabajo de Desarrollo Usando Apidog
El desarrollo moderno de IA requiere herramientas sofisticadas para gestionar la integración de modelos, las pruebas y los flujos de trabajo de implementación de manera efectiva en estos diversos métodos de acceso. Apidog proporciona capacidades completas de gestión de API que simplifican la integración de GLM-4.5, independientemente del enfoque de implementación elegido.
Al implementar modelos GLM-4.5 en diferentes plataformas, ya sea a través de OpenRouter, acceso directo a la API, implementaciones de Hugging Face o configuraciones autoalojadas, los desarrolladores deben validar el rendimiento en diversos casos de uso, probar diferentes configuraciones de parámetros y garantizar un manejo de errores confiable. El marco de pruebas de API de Apidog permite una evaluación sistemática de las respuestas del modelo, las características de latencia y los patrones de utilización de recursos en todos estos métodos de implementación.
Las capacidades de generación de documentación de la plataforma resultan particularmente valiosas al implementar GLM-4.5 a través de múltiples métodos de acceso simultáneamente. Los desarrolladores pueden generar automáticamente documentación de API completa que incluye opciones de configuración del modelo, esquemas de entrada/salida y ejemplos de uso específicos de las capacidades de razonamiento híbrido de GLM-4.5 en OpenRouter, API directa e implementaciones autoalojadas.
Las características colaborativas dentro de Apidog facilitan el intercambio de conocimientos entre los equipos de desarrollo que trabajan con implementaciones de GLM-4.5. Los miembros del equipo pueden compartir configuraciones de prueba, documentar las mejores prácticas y colaborar en patrones de integración que maximicen la efectividad del modelo.
Las capacidades de gestión de entornos garantizan implementaciones consistentes de GLM-4.5 en entornos de desarrollo, staging y producción, independientemente de si los equipos utilizan el servicio gestionado de OpenRouter, la integración directa de API o implementaciones autoalojadas. Los desarrolladores pueden mantener configuraciones separadas para diferentes entornos mientras garantizan patrones de implementación reproducibles.
Estrategias de Implementación y Mejores Prácticas
La implementación exitosa de los modelos GLM-4.5 requiere una cuidadosa consideración de los requisitos de infraestructura, las técnicas de optimización del rendimiento y los patrones de integración que maximizan la efectividad del modelo. Las organizaciones deben evaluar sus casos de uso específicos en función de las capacidades del modelo para determinar las configuraciones de implementación óptimas.
Los requisitos de hardware varían significativamente entre GLM-4.5 y GLM-4.5 Air, lo que permite a las organizaciones seleccionar variantes que se ajusten a sus limitaciones de infraestructura. Los equipos con una infraestructura de GPU robusta pueden aprovechar el modelo GLM-4.5 completo para obtener la máxima capacidad, mientras que los entornos con recursos limitados pueden encontrar que GLM-4.5 Air proporciona un rendimiento suficiente con costos de infraestructura reducidos.
El ajuste fino del modelo representa otra consideración crítica para las organizaciones con requisitos especializados. La licencia MIT permite una personalización completa del modelo, lo que permite a los equipos adaptar GLM-4.5 para aplicaciones específicas del dominio. Sin embargo, el ajuste fino requiere una cuidadosa curación del conjunto de datos y experiencia en entrenamiento para lograr resultados óptimos.
La configuración del modo híbrido requiere un ajuste cuidadoso de los parámetros para equilibrar la velocidad de respuesta con la calidad del razonamiento. Las aplicaciones con requisitos estrictos de latencia pueden preferir valores predeterminados más agresivos en el modo sin pensamiento, mientras que las aplicaciones que priorizan la calidad del razonamiento pueden beneficiarse de umbrales de modo de pensamiento más bajos.
Los patrones de integración de API deben aprovechar las capacidades de llamada a funciones nativas de GLM-4.5 para crear flujos de trabajo de agente eficientes. En lugar de implementar capas de orquestación externas, los desarrolladores pueden confiar en las capacidades de uso de herramientas integradas del modelo para reducir la complejidad del sistema y mejorar la confiabilidad.
Consideraciones de Seguridad y Gestión de Riesgos
La implementación de modelos de código abierto como GLM-4.5 introduce consideraciones de seguridad que las organizaciones deben abordar a través de estrategias integrales de gestión de riesgos. La disponibilidad de los pesos del modelo permite una auditoría de seguridad exhaustiva, pero también requiere un manejo cuidadoso para evitar el acceso no autorizado o el uso indebido.
La seguridad de la inferencia del modelo requiere protección contra entradas adversas que podrían comprometer el comportamiento del modelo o extraer información sensible de los datos de entrenamiento. Las organizaciones deben implementar validación de entrada, filtrado de salida y sistemas de detección de anomalías para identificar interacciones potencialmente problemáticas.
La seguridad de la infraestructura de implementación se vuelve crítica al alojar modelos GLM-4.5 en entornos de producción. Las prácticas de seguridad estándar, incluida la segregación de redes, los controles de acceso y el cifrado, se aplican a las implementaciones de modelos de IA al igual que a las aplicaciones tradicionales.
Las consideraciones de privacidad de datos requieren una atención cuidadosa a los flujos de información entre las aplicaciones y los modelos GLM-4.5. Las organizaciones deben asegurarse de que las entradas de datos sensibles reciban la protección adecuada y que las salidas del modelo no expongan inadvertidamente información confidencial.
La seguridad de la cadena de suministro se extiende a la procedencia del modelo y la verificación de la integridad. Las organizaciones deben validar las sumas de verificación del modelo, verificar las fuentes de descarga e implementar controles que garanticen que los modelos implementados coincidan con las configuraciones previstas.
La naturaleza de código abierto de GLM-4.5 permite una auditoría de seguridad integral que proporciona ventajas sobre los modelos propietarios donde las propiedades de seguridad permanecen opacas. Las organizaciones pueden analizar la arquitectura del modelo, las características de los datos de entrenamiento y las posibles vulnerabilidades mediante un examen directo en lugar de depender de las afirmaciones de seguridad del proveedor.
Conclusión
GLM-4.5 y GLM-4.5 Air representan avances significativos en las capacidades de IA de código abierto, ofreciendo un rendimiento competitivo mientras mantienen la accesibilidad y flexibilidad que definen los proyectos de código abierto exitosos. Z.ai ha lanzado su modelo base de próxima generación, GLM-4.5, logrando un rendimiento SOTA en modelos de código abierto a través de innovaciones arquitectónicas que abordan los desafíos de implementación del mundo real.
La arquitectura de razonamiento híbrido demuestra cómo un diseño cuidadoso puede eliminar las compensaciones tradicionales entre la velocidad de respuesta y la calidad del razonamiento. Esta innovación proporciona una plantilla para el desarrollo futuro de modelos que prioriza la utilidad práctica sobre el rendimiento puro de los puntos de referencia.
Las ventajas de eficiencia de costos hacen que GLM-4.5 sea accesible para organizaciones que anteriormente encontraban las capacidades avanzadas de IA prohibitivamente caras. La combinación de costos de inferencia reducidos y licencias permisivas crea oportunidades para la implementación de IA en diversas industrias y tamaños de organización.