
Flux es un modelo de texto a imagen de última generación desarrollado por Black Forest Labs, que ofrece capacidades avanzadas de generación de imágenes. ComfyUI, por otro lado, es una interfaz de modelo de difusión potente y modular con un sistema de flujo de trabajo basado en nodos. Cuando se combinan, crean una solución robusta para la generación de imágenes de alta calidad a la que se puede acceder mediante programación.
Combinar el poder de los modelos Flux con la versatilidad de ComfyUI puede mejorar significativamente su flujo de trabajo de generación de imágenes con IA. Este tutorial le guiará a través del proceso de ejecución de Flux en ComfyUI como una API, abriendo posibilidades para la automatización y la integración con otros sistemas.
Apidog ofrece un ecosistema de desarrollo de API integral con funciones como pruebas automatizadas, servidores simulados y generación de documentación detallada, todo en una plataforma unificada.

A diferencia de Postman, Apidog proporciona una gestión del ciclo de vida de la API sin problemas con herramientas de depuración integradas específicamente optimizadas para flujos de trabajo complejos como los de ComfyUI. Su interfaz intuitiva hace que probar sus puntos finales de Flux ComfyUI sea significativamente más eficiente, con funciones de colaboración que permiten a los miembros del equipo compartir y perfeccionar las configuraciones de la API juntos.
Si se toma en serio el desarrollo y las pruebas de API, la solución todo en uno de Apidog agilizará considerablemente su flujo de trabajo.
Configuración de su entorno Flux ComfyUI
Antes de sumergirnos en la implementación de la API, necesitamos configurar el entorno necesario. Utilizaremos Modal, una plataforma en la nube que facilita la ejecución de aplicaciones sin servidor con acceso a GPU.
Requisitos previos para Flux ComfyUI
- Una cuenta de Modal (cree una en modal.com)
- Python 3.11 o posterior
- Git instalado en su máquina local
- Conocimientos básicos de Python y conceptos de API
Creación de la imagen de contenedor Flux ComfyUI
Nuestro primer paso es crear una imagen de contenedor que incluya todos los componentes necesarios para ejecutar Flux en ComfyUI. Desglosemos el proceso:
import json
import subprocess
import uuid
from pathlib import Path
from typing import Dict
import modal
# Create a base image with necessary dependencies
image = (
modal.Image.debian_slim(python_version="3.11")
.apt_install("git") # Install git for cloning ComfyUI
.pip_install("fastapi[standard]==0.115.4") # Web dependencies
.pip_install("comfy-cli==1.3.5") # ComfyUI CLI tool
.run_commands(
"comfy --skip-prompt install --nvidia --version 0.3.10" # Install ComfyUI
)
)
Este código crea una imagen Modal basada en Debian Slim con Python 3.11, luego instala Git, FastAPI y comfy-cli. La herramienta comfy-cli se utiliza luego para instalar el propio ComfyUI.
Mejora de su Flux ComfyUI con nodos personalizados
Para desbloquear funcionalidad adicional, agregaremos nodos personalizados a nuestra instalación de ComfyUI:
image = (
image.run_commands(
"comfy node install was-node-suite-comfyui@1.0.2" # Install WAS Node Suite
)
# Add more custom nodes as needed
)
WAS Node Suite proporciona funcionalidad adicional para la generación y manipulación de imágenes, lo que puede ser particularmente útil cuando se trabaja con modelos Flux.
Configuración de la descarga del modelo Flux ComfyUI
La gestión eficiente de modelos es crucial para una experiencia fluida. Crearemos una función para descargar el modelo Flux y almacenarlo en un volumen persistente:
def hf_download():
from huggingface_hub import hf_hub_download
flux_model = hf_hub_download(
repo_id="Comfy-Org/flux1-schnell",
filename="flux1-schnell-fp8.safetensors",
cache_dir="/cache",
)
# Symlink the model to the ComfyUI directory
subprocess.run(
f"ln -s {flux_model} /root/comfy/ComfyUI/models/checkpoints/flux1-schnell-fp8.safetensors",
shell=True,
check=True,
)
# Create a persistent volume for model storage
vol = modal.Volume.from_name("hf-hub-cache", create_if_missing=True)
# Add the model download function to our image
image = (
image.pip_install("huggingface_hub[hf_transfer]==0.26.2")
.env({"HF_HUB_ENABLE_HF_TRANSFER": "1"})
.run_function(
hf_download,
volumes={"/cache": vol},
)
)
# Add our workflow JSON to the container
image = image.add_local_file(
Path(__file__).parent / "workflow_api.json", "/root/workflow_api.json"
)
Este código define una función para descargar el modelo Flux Schnell de Hugging Face y crear un enlace simbólico al directorio de modelos de ComfyUI. También creamos un volumen Modal para persistir los modelos descargados entre ejecuciones.
Desarrollo interactivo de Flux ComfyUI
Antes de implementar como una API, es útil probar interactivamente su flujo de trabajo de Flux ComfyUI:
app = modal.App(name="example-comfyui", image=image)
@app.function(
allow_concurrent_inputs=10, # Needed for UI startup
max_containers=1, # Limit to one container for interactive use
gpu="L40S", # Powerful GPU for Flux model inference
volumes={"/cache": vol}, # Mount our cached models
)
@modal.web_server(8000, startup_timeout=60)
def ui():
subprocess.Popen(
"comfy launch -- --listen 0.0.0.0 --port 8000",
shell=True
)
Puede ejecutar esto con modal serve your_file.py y acceder a la interfaz de usuario en su navegador para diseñar y probar sus flujos de trabajo antes de implementar la API.
Implementación de la API Flux ComfyUI
Ahora para el evento principal: convertir ComfyUI en un punto final de API para la inferencia del modelo Flux:
@app.cls(
allow_concurrent_inputs=10, # Allow multiple concurrent API calls
scaledown_window=300, # Keep containers alive for 5 minutes after use
gpu="L40S",
volumes={"/cache": vol},
)
class ComfyUI:
@modal.enter()
def launch_comfy_background(self):
# Start ComfyUI server in the background
cmd = "comfy launch --background"
subprocess.run(cmd, shell=True, check=True)
@modal.method()
def infer(self, workflow_path: str = "/root/workflow_api.json"):
# Check ComfyUI server health
self.poll_server_health()
# Run workflow with comfy-cli
cmd = f"comfy run --workflow {workflow_path} --wait --timeout 1200 --verbose"
subprocess.run(cmd, shell=True, check=True)
# Find output image
output_dir = "/root/comfy/ComfyUI/output"
workflow = json.loads(Path(workflow_path).read_text())
file_prefix = [
node.get("inputs")
for node in workflow.values()
if node.get("class_type") == "SaveImage"
][0]["filename_prefix"]
# Return image as bytes
for f in Path(output_dir).iterdir():
if f.name.startswith(file_prefix):
return f.read_bytes()
@modal.fastapi_endpoint(method="POST")
def api(self, item: Dict):
from fastapi import Response
# Load workflow template
workflow_data = json.loads(
(Path(__file__).parent / "workflow_api.json").read_text()
)
# Insert the prompt
workflow_data["6"]["inputs"]["text"] = item["prompt"]
# Generate unique ID for this request
client_id = uuid.uuid4().hex
workflow_data["9"]["inputs"]["filename_prefix"] = client_id
# Save modified workflow
new_workflow_file = f"{client_id}.json"
json.dump(workflow_data, Path(new_workflow_file).open("w"))
# Run inference
img_bytes = self.infer.local(new_workflow_file)
return Response(img_bytes, media_type="image/jpeg")
def poll_server_health(self) -> Dict:
import socket
import urllib
try:
# Check if server is healthy
req = urllib.request.Request("<http://127.0.0.1:8188/system_stats>")
urllib.request.urlopen(req, timeout=5)
print("El servidor ComfyUI está en buen estado")
except (socket.timeout, urllib.error.URLError) as e:
# Stop container if server is unhealthy
print(f"La comprobación del estado del servidor falló: {str(e)}")
modal.experimental.stop_fetching_inputs()
raise Exception("El servidor ComfyUI no está en buen estado, deteniendo el contenedor")
Esta clase define la funcionalidad principal de la API:
launch_comfy_backgroundinicia el servidor ComfyUI cuando se inicia el contenedorinferejecuta un flujo de trabajo y devuelve la imagen generadaapies el punto final de FastAPI que acepta un mensaje, modifica el flujo de trabajo y devuelve la imagenpoll_server_healthasegura que el servidor ComfyUI responda
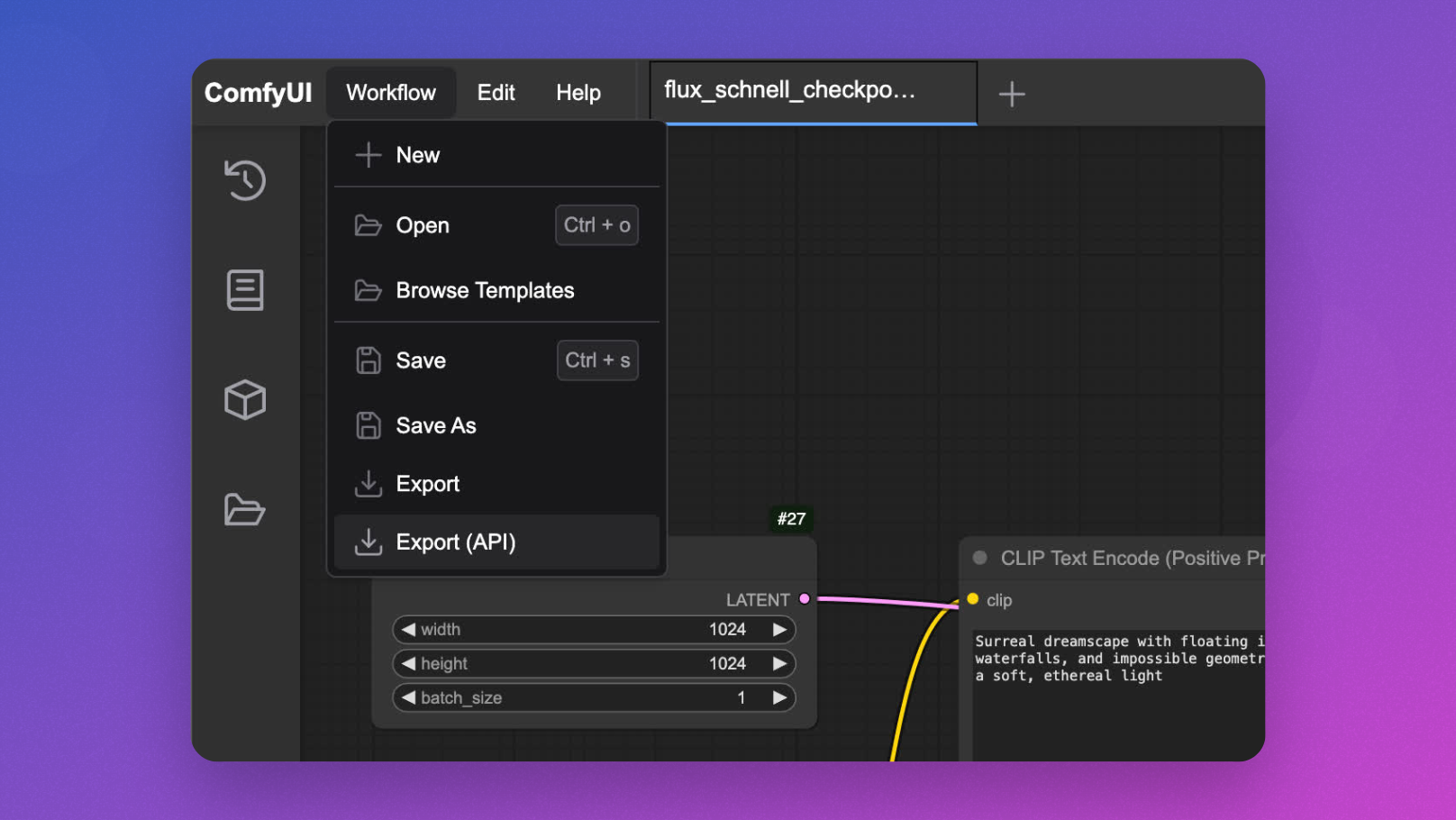
Prueba de su API Flux ComfyUI
Para probar su API, puede crear un script de cliente simple:
import requests
import base64
from PIL import Image
import io
import argparse
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--prompt", default="A surreal landscape with floating islands and ethereal light")
parser.add_argument("--endpoint", default="<https://your-modal-endpoint.modal.run>")
args = parser.parse_args()
# Send request to the API
response = requests.post(
f"{args.endpoint}/api",
json={"prompt": args.prompt}
)
# Handle the response
if response.status_code == 200:
# Save and display the image
image = Image.open(io.BytesIO(response.content))
image.save("flux_output.jpg")
print(f"Imagen generada y guardada como flux_output.jpg")
# Optional: display the image if in a suitable environment
try:
image.show()
except:
pass
else:
print(f"Error: {response.status_code}, {response.text}")
if __name__ == "__main__":
main()
Optimización del rendimiento de Flux ComfyUI
Para garantizar que su API siga respondiendo y sea rentable, considere implementar las siguientes optimizaciones:
1. Instantáneas de memoria para inicios en frío de Flux ComfyUI más rápidos
Los inicios en frío pueden ser un cuello de botella para las aplicaciones sin servidor. Modal ofrece instantáneas de memoria que pueden reducir significativamente los tiempos de inicio:
@app.cls(
allow_concurrent_inputs=10,
gpu="L40S",
volumes={"/cache": vol},
memory_snapshot=modal.MemorySnapshot(
snapshot_path="/root/comfy-snapshot",
boot_command="comfy launch --background",
),
)
class ComfyUI:
# Rest of the class implementation
2. Procesamiento por lotes de solicitudes para Flux ComfyUI
Para escenarios de alto rendimiento, la implementación del procesamiento por lotes de solicitudes puede mejorar la eficiencia:
@modal.method()
def batch_inference(self, prompts: list[str]):
results = []
for prompt in prompts:
# Create workflow for each prompt
client_id = uuid.uuid4().hex
workflow_data = json.loads(
(Path(__file__).parent / "workflow_api.json").read_text()
)
workflow_data["6"]["inputs"]["text"] = prompt
workflow_data["9"]["inputs"]["filename_prefix"] = client_id
# Save and process workflow
new_workflow_file = f"{client_id}.json"
json.dump(workflow_data, Path(new_workflow_file).open("w"))
img_bytes = self.infer.local(new_workflow_file)
results.append(img_bytes)
return results
Funciones avanzadas de la API Flux ComfyUI
Personalización de los parámetros del flujo de trabajo
Extienda su API para permitir parámetros adicionales más allá del mensaje:
@modal.fastapi_endpoint(method="POST")
def advanced_api(self, item: Dict):
from fastapi import Response
workflow_data = json.loads(
(Path(__file__).parent / "workflow_api.json").read_text()
)
# Insert the prompt
workflow_data["6"]["inputs"]["text"] = item["prompt"]
# Optional: Set additional parameters if provided
if "negative_prompt" in item:
workflow_data["7"]["inputs"]["text"] = item["negative_prompt"]
if "cfg_scale" in item:
workflow_data["3"]["inputs"]["cfg"] = item["cfg_scale"]
if "steps" in item:
workflow_data["3"]["inputs"]["steps"] = item["steps"]
# Generate unique ID
client_id = uuid.uuid4().hex
workflow_data["9"]["inputs"]["filename_prefix"] = client_id
# Save and process workflow
new_workflow_file = f"{client_id}.json"
json.dump(workflow_data, Path(new_workflow_file).open("w"))
img_bytes = self.infer.local(new_workflow_file)
return Response(img_bytes, media_type="image/jpeg")
Manejo de diferentes modelos Flux ComfyUI
Permitir el cambio entre diferentes modelos Flux:
@modal.fastapi_endpoint(method="POST")
def model_selection_api(self, item: Dict):
from fastapi import Response
workflow_data = json.loads(
(Path(__file__).parent / "workflow_api.json").read_text()
)
# Insert the prompt
workflow_data["6"]["inputs"]["text"] = item["prompt"]
# Select model if specified
if "model" in item:
if item["model"] == "flux-schnell":
workflow_data["2"]["inputs"]["ckpt_name"] = "flux1-schnell-fp8.safetensors"
elif item["model"] == "flux-turbo":
workflow_data["2"]["inputs"]["ckpt_name"] = "flux1-turbo-fp8.safetensors"
# Generate unique ID
client_id = uuid.uuid4().hex
workflow_data["9"]["inputs"]["filename_prefix"] = client_id
# Save and process workflow
new_workflow_file = f"{client_id}.json"
json.dump(workflow_data, Path(new_workflow_file).open("w"))
img_bytes = self.infer.local(new_workflow_file)
return Response(img_bytes, media_type="image/jpeg")
Supervisión de su API Flux ComfyUI
La implementación de una supervisión adecuada es esencial para las implementaciones de producción:
@app.cls(
# Other parameters
monitor_agent=modal.MonitorAgent(),
)
class ComfyUI:
# Existing implementation
def log_request(self, prompt, model, processing_time):
# Custom logging implementation
print(f"Imagen generada para el mensaje: '{prompt}' usando el modelo {model} en {processing_time:.2f}s")
Conclusión: Liberando el poder de Flux ComfyUI como API
Siguiendo este tutorial, ha aprendido a transformar ComfyUI con modelos Flux en un servicio de API escalable y listo para producción. Este enfoque ofrece varias ventajas:
- Escalabilidad: gestione varias solicitudes simultáneamente con el escalado automático de contenedores
- Flexibilidad: personalice los flujos de trabajo en función de los requisitos del usuario
- Integración: conecte sus capacidades de generación de imágenes con otras aplicaciones
- Rentabilidad: pague solo por el cálculo que utilice
La combinación de la infraestructura sin servidor de Modal, el potente sistema de flujo de trabajo de ComfyUI y la generación de imágenes de última generación de Flux crea una solución robusta para una amplia gama de aplicaciones creativas y empresariales.
Ya sea que esté construyendo una herramienta creativa, un sistema de visualización de comercio electrónico o una plataforma de generación de contenido, ejecutar Flux en ComfyUI como una API proporciona la base para experiencias visuales innovadoras impulsadas por IA.


