
Imagina tener la capacidad de extraer datos de cualquier sitio web y recopilar información a escala, todo con solo unas pocas líneas de código. Suena mágico, ¿verdad? Pues bien, Firecrawl hace esto posible.
En esta guía para principiantes, te guiaré por todo lo que necesitas saber sobre Firecrawl, desde la instalación hasta las técnicas avanzadas de extracción de datos. Tanto si eres desarrollador, analista de datos o simplemente sientes curiosidad por el web scraping, este tutorial te ayudará a empezar con Firecrawl e integrarlo en tus flujos de trabajo.

¿Qué es Firecrawl?
Firecrawl es un innovador motor de web scraping y rastreo que convierte el contenido de los sitios web en formatos como markdown, HTML y datos estructurados. Esto lo hace ideal para Large Language Models (LLMs) y aplicaciones de IA. Con Firecrawl, puedes recopilar eficientemente datos estructurados y no estructurados de sitios web, simplificando tu flujo de trabajo de análisis de datos.
Características principales de Firecrawl
Crawl: Rastreo web integral
El endpoint /crawl de Firecrawl te permite recorrer recursivamente un sitio web, extrayendo contenido de todas las subpáginas. Esta función es perfecta para descubrir y organizar grandes cantidades de datos web, convirtiéndolos en formatos listos para LLM.
Scrape: Extracción de datos específica
Utiliza la función Scrape para extraer datos específicos de una sola URL. Firecrawl puede entregar contenido en varios formatos, incluyendo markdown, datos estructurados, capturas de pantalla y HTML. Esto es particularmente útil para extraer información específica de URLs conocidas.
Map: Mapeo rápido de sitios
La función Map recupera rápidamente todas las URLs asociadas a un sitio web determinado, proporcionando una visión general completa de su estructura. Esto es invaluable para el descubrimiento y la organización de contenido.
Extract: Transformación de datos no estructurados en formato estructurado
El endpoint /extract es la función impulsada por IA de Firecrawl que simplifica el proceso de recopilación de datos estructurados de sitios web. Se encarga del trabajo pesado de rastrear, analizar y organizar los datos en un formato estructurado.
Empezando con Firecrawl
Paso 1: Regístrate y obtén tu clave API
Visita el sitio web oficial de Firecrawl y regístrate para obtener una cuenta. Una vez que hayas iniciado sesión, navega a tu panel de control para encontrar tu clave API.
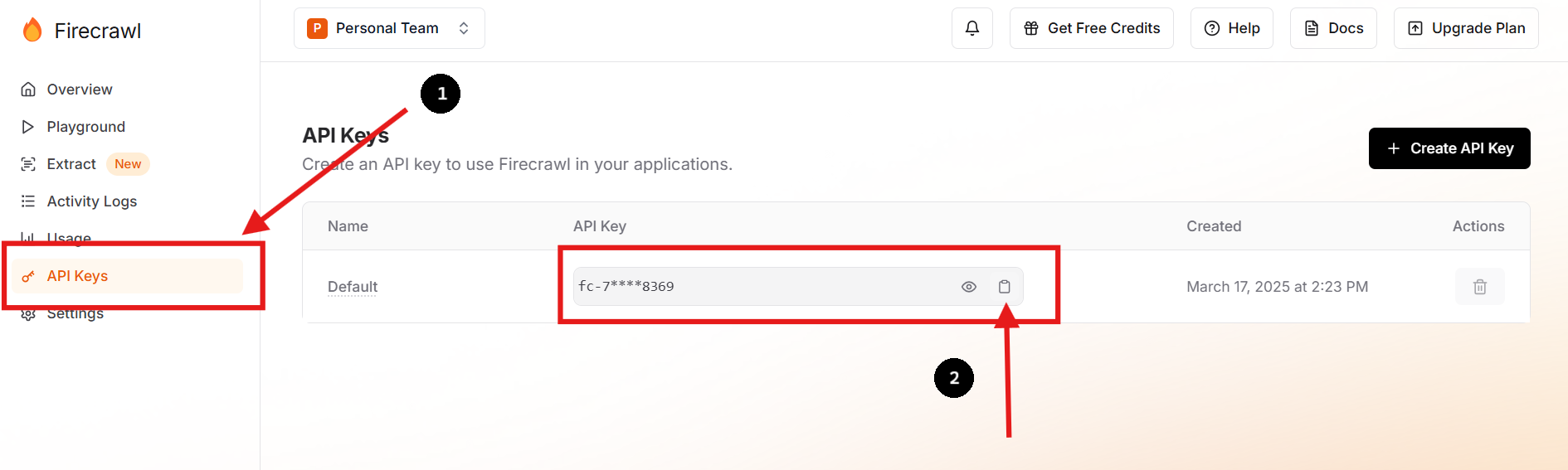
También puedes crear una nueva clave API y eliminar la anterior si lo prefieres o necesitas hacerlo.

Paso 2: Configura tu entorno
En el directorio de tu proyecto, crea un archivo .env para almacenar de forma segura tu clave API como una variable de entorno. Puedes hacer esto ejecutando los siguientes comandos en tu terminal:
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .envEste enfoque mantiene la información confidencial fuera de tu código base principal, mejorando la seguridad y simplificando la gestión de la configuración.
Paso 3: Instala el SDK de Firecrawl
Para los usuarios de Python, instala el SDK de Firecrawl usando pip:
pip install firecrawl Paso 4: Utiliza la función "Scrape" de Firecrawl
Aquí tienes un ejemplo sencillo de cómo hacer scraping de un sitio web utilizando el SDK de Python:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define the URL to scrape
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# Scrape the website
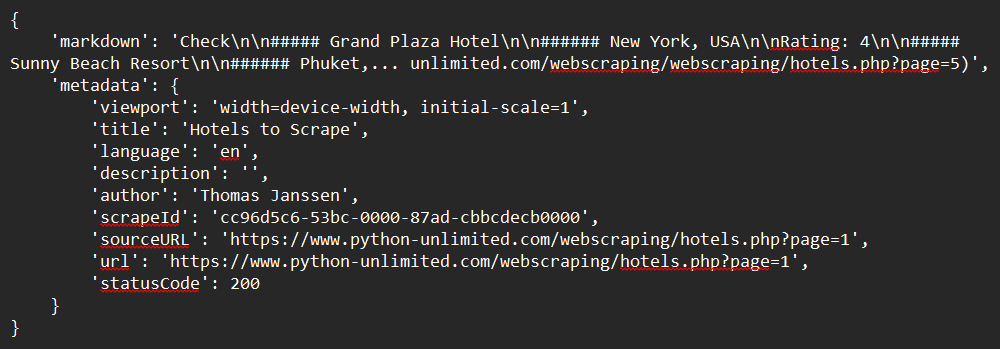
response = app.scrape_url(url)
# Print the response
print(response)Ejemplo de salida:
Paso 5: Utiliza la función "Crawl" de Firecrawl
Aquí veremos un ejemplo sencillo de cómo rastrear un sitio web utilizando el SDK de Python:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Crawl a website and capture the response:
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
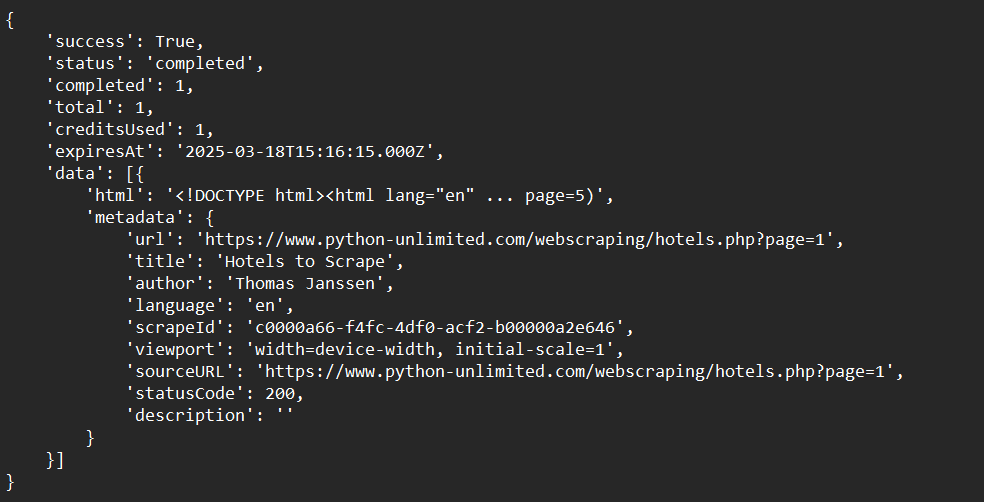
print(crawl_status)Ejemplo de salida:
Paso 6: Utiliza la función "Map" de Firecrawl
Aquí tienes un ejemplo sencillo de cómo mapear datos de un sitio web utilizando el SDK de Python:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Map a website:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)Ejemplo de salida:

Paso 7: Utiliza la función "Extract" de Firecrawl (Beta abierta)
A continuación, se muestra un ejemplo sencillo de cómo extraer datos de un sitio web utilizando el SDK de Python:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define schema to extract contents into
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
# Call the extract function and capture the response
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Extract the data provided in the schema.",
'schema': ExtractSchema.model_json_schema()
})
# Print the response
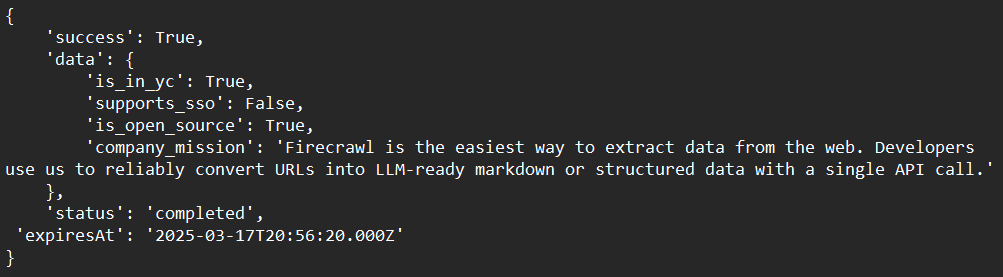
print(response)Ejemplo de salida:
Técnicas avanzadas con Firecrawl
Manejo de contenido dinámico
Firecrawl puede manejar contenido dinámico basado en JavaScript utilizando navegadores sin cabeza para renderizar las páginas antes de hacer scraping. Esto asegura que captures todo el contenido, incluso si se carga dinámicamente.
Evitar los bloqueadores de web scraping
Utiliza las funciones integradas de Firecrawl para evitar los bloqueadores comunes de web scraping, como los CAPTCHA o los límites de velocidad. Esto implica rotar los agentes de usuario y las direcciones IP para imitar el tráfico natural.
Integración con LLMs
Combina Firecrawl con LLMs como LangChain para construir potentes flujos de trabajo de IA. Por ejemplo, puedes utilizar Firecrawl para recopilar datos y luego introducirlos en un LLM para tareas de análisis o generación.
Solución de problemas comunes
Problema: "Clave API no reconocida"
Solución: Asegúrate de que tu clave API esté almacenada correctamente como una variable de entorno o en un archivo .env.
Problema: "Rastreo demasiado lento"
Solución: Utiliza el rastreo asíncrono para acelerar el proceso. Firecrawl admite solicitudes concurrentes para mejorar la eficiencia.
Problema: "Contenido no extraído correctamente"
Solución: Comprueba si el sitio web utiliza contenido dinámico. Si es así, asegúrate de que Firecrawl esté configurado para manejar la renderización de JavaScript.
Conclusión
¡Enhorabuena por completar esta completa guía para principiantes sobre Firecrawl! Hemos cubierto todo lo que necesitas para empezar, desde qué es Firecrawl, hasta instrucciones detalladas de instalación, ejemplos de uso y opciones avanzadas de personalización. A estas alturas, deberías tener una comprensión clara de cómo:
- Configurar e instalar Firecrawl en tu entorno de desarrollo.
- Configurar y ejecutar Firecrawl para hacer scraping, rastrear, mapear y extraer datos de forma eficiente.
- Solucionar problemas de tus procesos de rastreo para satisfacer tus necesidades específicas.
Firecrawl es una herramienta increíblemente potente que puede agilizar significativamente tus flujos de trabajo de extracción de datos. Su flexibilidad, eficiencia y facilidad de integración lo convierten en una opción ideal para los desafíos modernos del rastreo web.
Ahora es el momento de poner en práctica tus nuevas habilidades. Empieza a experimentar con diferentes sitios web, ajusta tus analizadores e intégralos con herramientas adicionales para crear una solución verdaderamente personalizada que satisfaga tus requisitos únicos.
¿Listo para multiplicar por 10 tu flujo de trabajo de web scraping? Descarga Apidog gratis hoy mismo y descubre cómo puede mejorar tu integración con Firecrawl.


