
El dominio de la inteligencia artificial continúa su rápida expansión, con los Modelos de Lenguaje Grandes (LLMs) demostrando cada vez más habilidades cognitivas sofisticadas. Entre ellos, FractalAIResearch/Fathom-R1-14B emerge como un modelo destacable, albergando aproximadamente 14.8 mil millones de parámetros. Este modelo ha sido diseñado específicamente por Fractal AI Research para destacar en tareas complejas de razonamiento matemático y general. Lo que distingue a Fathom-R1-14B es su capacidad para lograr este alto nivel de rendimiento con una notable rentabilidad y dentro de una ventana de contexto práctica de 16.384 (16K) tokens. Este artículo ofrece una visión general técnica de Fathom-R1-14B, detallando su desarrollo, arquitectura, procesos de entrenamiento, rendimiento evaluado y proporcionando una guía enfocada para su implementación práctica basada en métodos establecidos.
Fractal AI: Los Innovadores Detrás del Modelo

Fathom-R1-14B es un producto de Fractal AI Research, la división de investigación de Fractal, una firma distinguida de IA y análisis con sede en Mumbai, India. Fractal se ha ganado una reputación global por ofrecer soluciones de inteligencia artificial y análisis avanzados a empresas Fortune 500. La creación de Fathom-R1-14B se alinea estrechamente con las crecientes ambiciones de la India en el sector de la inteligencia artificial.
Las Aspiraciones de IA de la India
El desarrollo de este modelo es particularmente significativo dentro del contexto de la Misión IndiaAI. Srikanth Velamakanni, Co-fundador, Director Ejecutivo del Grupo y Vicepresidente de Fractal, indicó que Fathom-R1-14B es una demostración temprana de una iniciativa más amplia. Mencionó: "Propusimos construir el primer modelo de razonamiento grande (LRM) de la India como parte de la misión IndiaAI... Esto [Fathom-R1-14B] es solo una pequeña prueba de lo que es posible", aludiendo a planes para una serie de modelos, incluyendo una versión mucho más grande de 70 mil millones de parámetros. Esta dirección estratégica destaca un compromiso nacional con la autosuficiencia en IA y la creación de modelos fundacionales indígenas. Las contribuciones más amplias de Fractal a la IA incluyen otros proyectos impactantes, como Vaidya.ai, una plataforma de IA multimodal para asistencia sanitaria. La publicación de Fathom-R1-14B como una herramienta de código abierto, por lo tanto, no solo beneficia a la comunidad global de IA, sino que también significa un logro clave en el panorama de IA en evolución de la India.
Diseño Fundacional y Plano Arquitectónico de Fathom-R1-14B
Las impresionantes capacidades de Fathom-R1-14B se basan en una base cuidadosamente elegida y un diseño arquitectónico robusto, optimizado para tareas de razonamiento.
El camino de Fathom-R1-14B comenzó con la selección de Deepseek-R1-Distilled-Qwen-14B como su modelo base. La naturaleza "destilada" de este modelo significa que es un derivado más compacto y computacionalmente eficiente de un modelo padre más grande, diseñado específicamente para retener una porción significativa de las capacidades del original, particularmente las de la bien considerada familia Qwen. Esto proporcionó un sólido punto de partida, que Fractal AI Research luego mejoró meticulosamente a través de técnicas de post-entrenamiento especializadas. Para sus operaciones, el modelo típicamente utiliza precisión bfloat16 (Formato de Punto Flotante Cerebral), lo que logra un equilibrio efectivo entre la velocidad computacional y la precisión numérica requerida para cálculos complejos.
Fathom-R1-14B está construido sobre la arquitectura Qwen2, una potente iteración dentro de la familia de modelos Transformer. Los modelos Transformer son el estándar actual para LLMs de alto rendimiento, en gran parte debido a sus innovadores mecanismos de auto-atención. Estos mecanismos permiten que el modelo pondere dinámicamente la importancia de diferentes tokens —ya sean palabras, sub-palabras o símbolos matemáticos— dentro de una secuencia de entrada al generar su salida. Esta capacidad es crucial para comprender las intrincadas dependencias presentes en problemas matemáticos complejos y argumentos lógicos matizados.
La escala del modelo, caracterizada por aproximadamente 14.8 mil millones de parámetros, es un factor clave en su rendimiento. Estos parámetros, que son esencialmente los valores numéricos aprendidos dentro de las capas de la red neuronal, codifican el conocimiento y las capacidades de razonamiento del modelo. Un modelo de este tamaño ofrece una capacidad sustancial para capturar y representar patrones complejos de sus datos de entrenamiento.
La Importancia de la Ventana de Contexto de 16K
Una especificación arquitectónica crítica es su ventana de contexto de 16.384 tokens. Esto determina la longitud máxima de la combinación de la instrucción de entrada y la salida generada por el modelo que se puede procesar en una sola operación. Si bien algunos modelos presumen de ventanas de contexto mucho más grandes, la capacidad de 16K de Fathom-R1-14B es una elección de diseño deliberada y pragmática. Es lo suficientemente grande para acomodar enunciados de problemas detallados, extensas cadenas de razonamiento paso a paso (como a menudo se requieren en matemáticas de nivel de Olimpiada) y respuestas completas. Es importante destacar que esto se logra sin incurrir en la escalada cuadrática del costo computacional que puede estar asociada con los mecanismos de atención en secuencias extremadamente largas, haciendo que Fathom-R1-14B sea más ágil y menos intensivo en recursos durante la inferencia.
Fathom-R1-14B es Realmente, Realmente Rentable
Uno de los aspectos más llamativos de Fathom-R1-14B es la eficiencia de su proceso de post-entrenamiento. La versión principal del modelo fue ajustada con un costo reportado de aproximadamente $499 USD. Esta notable viabilidad económica se logró a través de una estrategia de entrenamiento sofisticada y multifacética, enfocada en maximizar las habilidades de razonamiento sin un gasto computacional excesivo.
Las técnicas centrales que sustentan esta especialización eficiente incluyeron:
- Ajuste Fino Supervisado (SFT): Esta fase fundamental implicó entrenar el modelo base en un conjunto de datos curado y de alta calidad de pares problema-solución específicamente adaptados al razonamiento matemático avanzado. A través del SFT, el modelo aprendió a emular vías correctas de resolución de problemas y deducción lógica.
- Aprendizaje Curricular Iterativo: En lugar de exponer el modelo a todo el espectro de dificultad de problemas a la vez, esta estrategia introduce desafíos de manera gradual. El modelo comienza con problemas matemáticos más simples y progresa hacia otros más complejos, como los de AIME y HMMT. Este enfoque estructurado facilita un aprendizaje más estable y efectivo, permitiendo que el modelo construya una base sólida antes de abordar tareas altamente desafiantes. Esta técnica fue central para el desarrollo de un modelo precursor clave,
Fathom-R1-14B-V0.6. - Fusión de Modelos: El modelo final Fathom-R1-14B es una amalgama de dos modelos predecesores específicamente ajustados:
Fathom-R1-14B-V0.6(que se sometió a SFT con Currículo Iterativo) yFathom-R1-14B-V0.4(que se centró en SFT con "Cadenas más Cortas", probablemente enfatizando la concisión en las soluciones). Al fusionar modelos entrenados con enfoques ligeramente diferentes, el modelo resultante hereda un conjunto más amplio de fortalezas.
El objetivo general de este meticuloso proceso de entrenamiento fue inculcar un "razonamiento matemático conciso pero preciso".
Fractal AI Research también exploró una vía de entrenamiento alternativa con una variante llamada Fathom-R1-14B-RS. Esta versión incorporó Aprendizaje por Refuerzo (RL), utilizando específicamente un algoritmo conocido como GRPO (Optimización Generalizada por Empuje de Recompensa), junto con SFT. Si bien este enfoque arrojó un alto rendimiento comparable, su costo de post-entrenamiento fue ligeramente mayor, en $967 USD. El desarrollo de ambas versiones subraya un compromiso con la exploración de diversas metodologías para lograr un rendimiento de razonamiento óptimo de manera eficiente. Como parte de su compromiso con la transparencia, Fractal AI Research ha publicado las recetas de entrenamiento y los conjuntos de datos como código abierto.
Puntos de Referencia de Rendimiento: Cuantificando la Excelencia en el Razonamiento
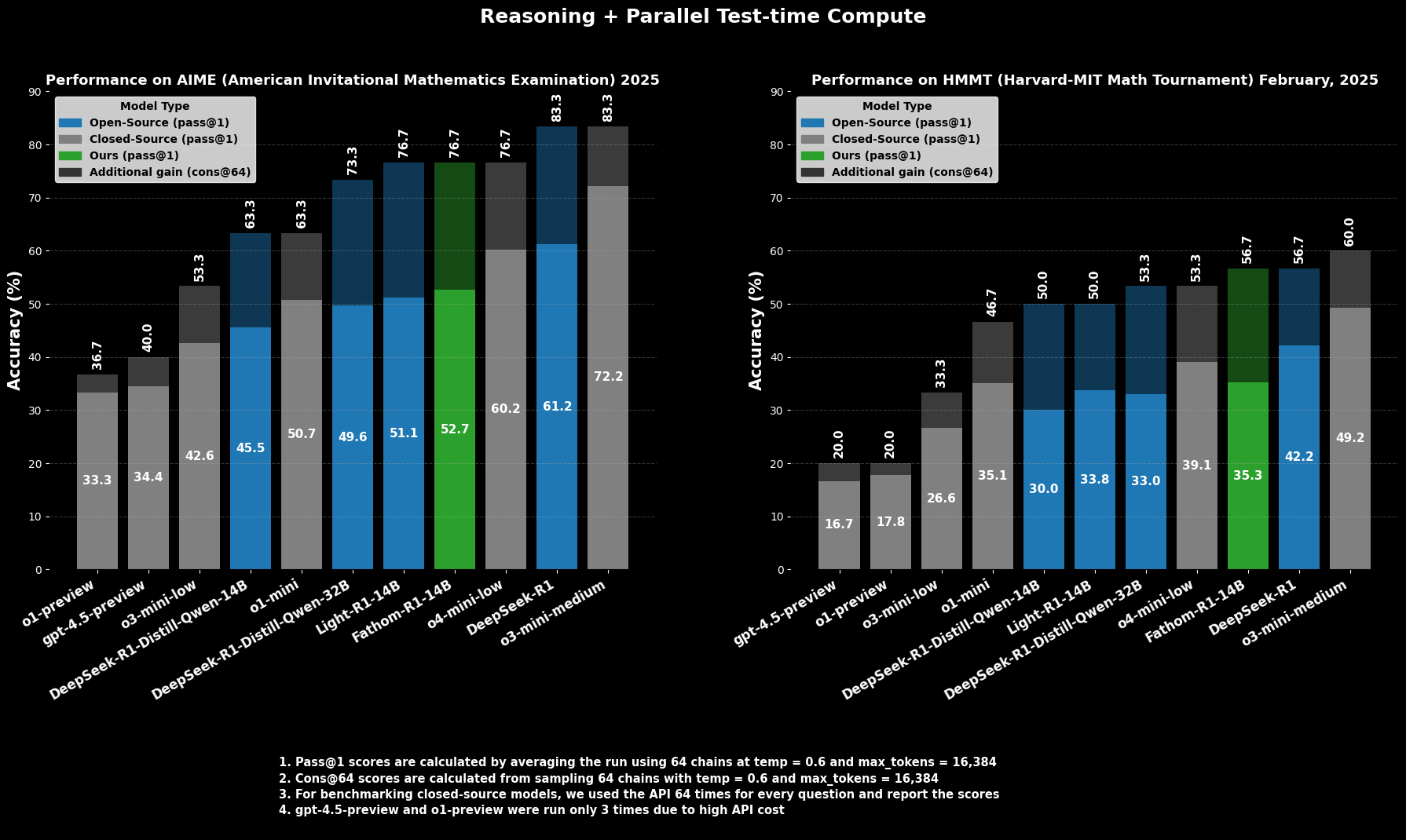
La competencia de Fathom-R1-14B no es meramente teórica; está respaldada por un rendimiento impresionante en puntos de referencia de razonamiento matemático rigurosos y reconocidos internacionalmente.
Éxito en AIME y HMMT
En el AIME2025 (American Invitational Mathematics Examination), una desafiante competición de matemáticas preuniversitarias, Fathom-R1-14B logra una precisión Pass@1 del 52.71%. La métrica Pass@1 indica el porcentaje de problemas para los cuales el modelo genera una solución correcta en un solo intento. Cuando se le permite un mayor presupuesto computacional en el momento de la prueba, evaluado usando cons@64 (consistencia entre 64 soluciones muestreadas), su precisión en AIME2025 asciende a un impresionante 76.7%.
De manera similar, en el HMMT25 (Harvard-MIT Mathematics Tournament), otra competición de alto nivel, el modelo obtiene un 35.26% Pass@1, que aumenta a 56.7% cons@64. Estas puntuaciones son particularmente destacables porque se logran dentro del presupuesto de salida de 16K tokens del modelo, reflejando consideraciones prácticas de despliegue.
Rendimiento Comparativo
En evaluaciones comparativas, Fathom-R1-14B supera significativamente a otros modelos de código abierto de tamaños similares o incluso mayores en estos puntos de referencia matemáticos específicos en Pass@1. Más sorprendentemente, su rendimiento, especialmente al considerar la métrica cons@64, lo posiciona como competitivo con algunos modelos de código cerrado capaces, de los cuales a menudo se presume que tienen acceso a recursos mucho mayores. Esto destaca la eficiencia de Fathom-R1-14B al traducir sus parámetros y entrenamiento en razonamiento de alta fidelidad.
Intentemos Ejecutar Fathom-R1-14B
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
Esta sección proporciona una guía enfocada sobre cómo ejecutar Fathom-R1-14B utilizando la biblioteca transformers de Hugging Face dentro de un entorno Python. Este enfoque es adecuado para usuarios con acceso a hardware de GPU capaz, ya sea localmente o a través de proveedores de la nube. Los pasos aquí descritos siguen de cerca las prácticas establecidas para desplegar tales modelos.
Configuración del Entorno
Configurar un entorno Python adecuado es crucial. Los siguientes pasos detallan una configuración común usando Conda en un sistema basado en Linux (o Subsistema de Windows para Linux):
Acceda a su Máquina: Si usa una instancia de GPU remota en la nube, conéctese a ella a través de SSH.Bash
# Example: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
Verifique el Reconocimiento de la GPU: Asegúrese de que el sistema reconozca la GPU NVIDIA y que los controladores estén correctamente instalados.Bash
nvidia-smi
Cree y Active un Entorno Conda: Es una buena práctica aislar las dependencias del proyecto.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
Instale las Bibliotecas Necesarias: Instale PyTorch (compatible con su versión de CUDA), Hugging Face transformers, accelerate (para carga y distribución eficiente del modelo), notebook (para Jupyter) e ipywidgets (para interactividad en notebooks).Bash
# Ensure you install a PyTorch version compatible with your GPU's CUDA toolkit
# Example for CUDA 11.8:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Or for CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Inferencia Basada en Python en un Jupyter Notebook
Con el entorno preparado, puede usar un Jupyter Notebook para cargar e interactuar con Fathom-R1-14B.
Inicie el Servidor Jupyter Notebook: Si está en un servidor remoto, inicie Jupyter Notebook permitiendo acceso remoto y especifique un puerto.Bash
jupyter notebook --no-browser --port=8888 --allow-root
Si se ejecuta de forma remota, probablemente necesitará configurar el reenvío de puertos SSH desde su máquina local para acceder a la interfaz de Jupyter:Bash
# Example: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
Luego, abra http://localhost:8889 (o el puerto local que haya elegido) en su navegador web.
Código Python para la Interacción con el Modelo: Cree un nuevo Jupyter Notebook y use el siguiente código Python:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Define the model ID from Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Loading tokenizer for {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Loading model {model_id} (this may take a while)...")
# Load the model with bfloat16 precision for efficiency and device_map for auto distribution
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it
device_map="auto", # Automatically distributes model layers across available hardware
trust_remote_code=True # Some models may require this
)
print("Model and tokenizer loaded successfully.")
# Define a sample mathematical prompt
prompt = """Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. In June, she sold 4 more clips than in May. How many clips did Natalia sell altogether in April, May, and June? Provide a step-by-step solution.
Solution:"""
print(f"\nPrompt:\n{prompt}")
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Ensure inputs are on the model's device
print("\nGenerating solution...")
# Generate the output from the model
# Adjust generation parameters as needed for different types of problems
outputs = model.generate(
**inputs,
max_new_tokens=768, # Maximum number of new tokens to generate for the solution
num_return_sequences=1, # Number of independent sequences to generate
temperature=0.1, # Lower temperature for more deterministic, factual outputs
top_p=0.7, # Use nucleus sampling with top_p
do_sample=True # Enable sampling for temperature and top_p to have an effect
)
# Decode the generated tokens into a string
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerated Solution:\n")
print(solution_text)
Conclusión: El Impacto de Fathom-R1-14B en la IA Accesible
FractalAIResearch/Fathom-R1-14B se erige como una demostración convincente de ingenio técnico en el ámbito de la IA contemporánea. Su diseño específico, con aproximadamente 14.8 mil millones de parámetros, la arquitectura Qwen2 y una ventana de contexto de 16K tokens, cuando se combina con un entrenamiento innovador y rentable (alrededor de $499 para la versión principal), ha resultado en un LLM que ofrece un rendimiento de vanguardia. Esto se evidencia por sus puntuaciones en rigurosos puntos de referencia de razonamiento matemático como AIME y HMMT.
Fathom-R1-14B ilustra de manera convincente que las fronteras del razonamiento de IA pueden ser avanzadas a través de un diseño inteligente y metodologías eficientes, fomentando un futuro donde la IA de alto rendimiento sea más democrática y ampliamente beneficiosa.
¿Quiere una plataforma integrada, Todo-en-Uno para que su Equipo de Desarrolladores trabaje junto con máxima productividad?
Apidog satisface todas sus demandas, ¡y reemplaza a Postman a un precio mucho más asequible!