
ElevenLabs convierte texto en voz natural y admite una amplia gama de voces, idiomas y estilos. La API facilita la integración de voz en aplicaciones, la automatización de flujos de narración o la creación de experiencias en tiempo real como agentes de voz. Si puedes enviar una solicitud HTTP, puedes generar audio en segundos.
¿Qué es la API de ElevenLabs?
La API de ElevenLabs proporciona acceso programático a modelos de IA que generan, transforman y analizan audio. La plataforma comenzó como un servicio de texto a voz, pero se ha expandido a una suite completa de IA de audio.
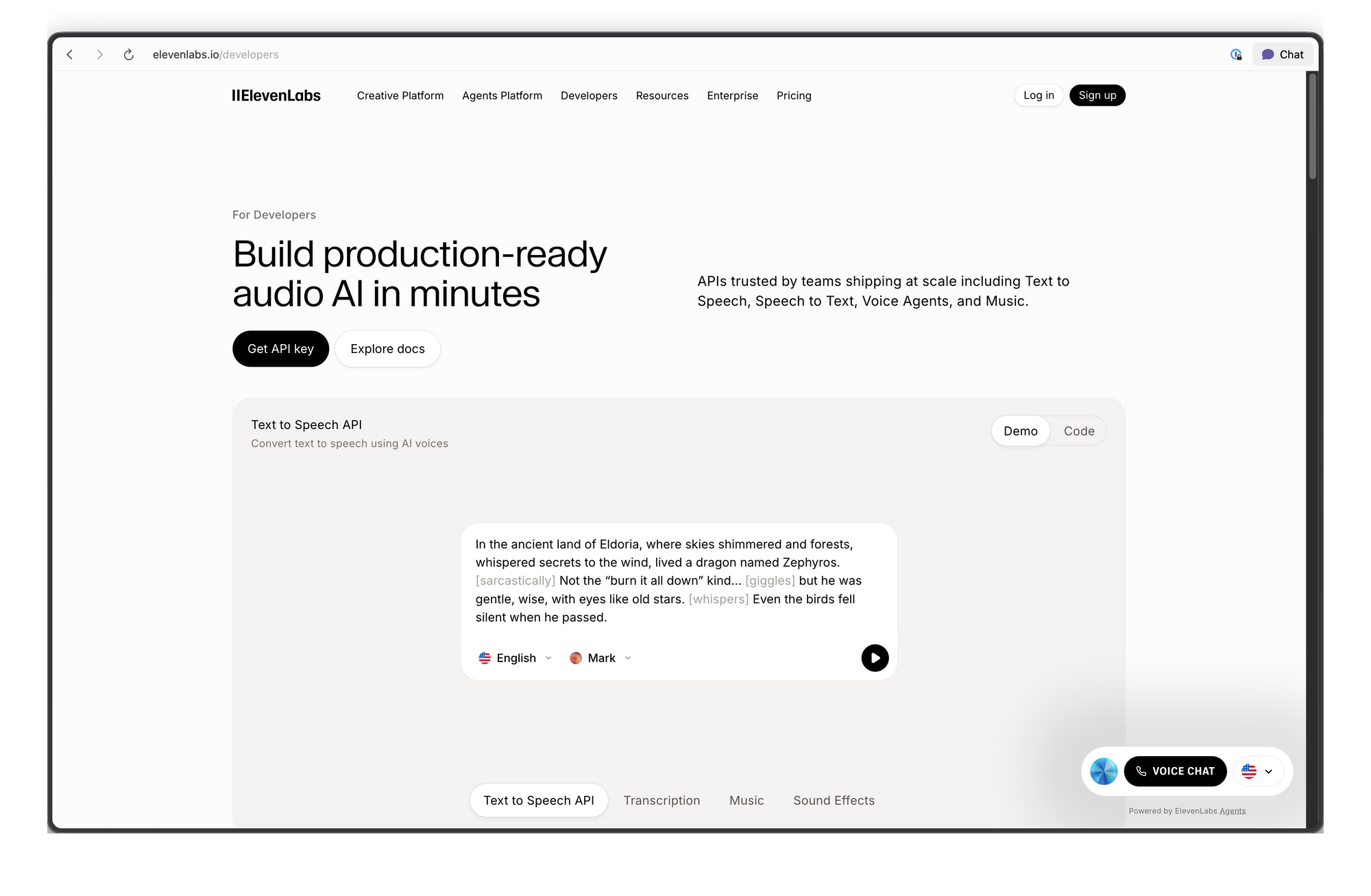
Capacidades principales:
- Texto a Voz (TTS): Convierte texto escrito en audio hablado con control sobre las características de la voz, la emoción y el ritmo.
- Voz a Voz (STS): Transforma una voz en otra mientras conserva la entonación y el ritmo originales.
- Clonación de Voz: Crea una réplica digital de cualquier voz a partir de tan solo 60 segundos de audio limpio.
- Doblaje por IA: Traduce y dobla contenido de audio/video a diferentes idiomas manteniendo las características de la voz del hablante.
- Efectos de Sonido: Genera efectos de sonido a partir de descripciones de texto.
- Voz a Texto: Transcribe audio a texto con alta precisión.
La API funciona a través de los protocolos estándar HTTP y WebSocket. Puedes llamarla desde cualquier lenguaje, pero existen SDKs oficiales para Python y JavaScript/TypeScript con seguridad de tipos y soporte de streaming incorporado.
Obteniendo la clave API de ElevenLabs
Antes de realizar cualquier llamada a la API, necesitas una clave API. Aquí te mostramos cómo obtener una:
Paso 1: Crea una cuenta gratuita. Incluso el plan gratuito incluye acceso a la API con 10,000 caracteres por mes.
Paso 2: Inicia sesión y navega a la sección Perfil + Clave API. Puedes encontrarla haciendo clic en el icono de tu perfil en la esquina inferior izquierda, o yendo directamente a la configuración de desarrollador.
Paso 3: Haz clic en Crear clave API. Copia la clave y guárdala de forma segura; no podrás ver la clave completa de nuevo.
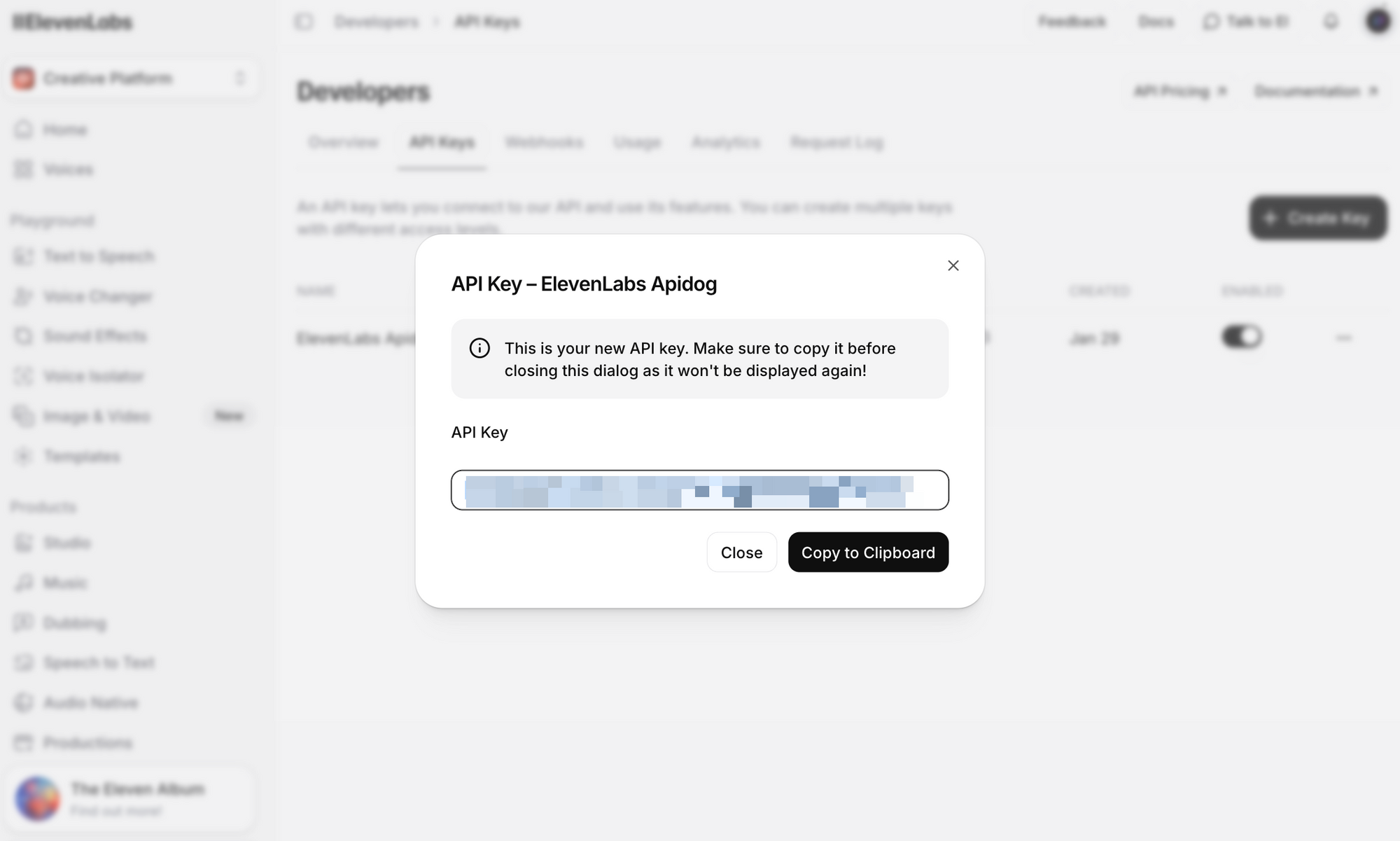
Notas de seguridad importantes:
- Nunca subas tu clave API al control de versiones.
- Usa variables de entorno o un gestor de secretos en producción.
- Las claves API pueden ser asignadas a espacios de trabajo específicos para entornos de equipo.
- Rota las claves regularmente y revoca las claves comprometidas de inmediato.
Establécela como una variable de entorno para los ejemplos de esta guía:
# Linux/macOS
export ELEVENLABS_API_KEY="tu_clave_api_aquí"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="tu_clave_api_aquí"
Descripción general de los puntos finales de la API de ElevenLabs
La API está organizada en varios grupos de recursos. Aquí están los puntos finales más comúnmente utilizados:
| Punto Final | Método | Descripción |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | Convierte texto en audio de voz |
/v1/text-to-speech/{voice_id}/stream | POST | Transmite audio a medida que se genera |
/v1/speech-to-speech/{voice_id} | POST | Convierte la voz de una a otra |
/v1/voices | GET | Lista todas las voces disponibles |
/v1/voices/{voice_id} | GET | Obtener detalles de una voz específica |
/v1/models | GET | Lista todos los modelos disponibles |
/v1/user | GET | Obtener información de la cuenta de usuario y uso |
/v1/voice-generation/generate-voice | POST | Genera una nueva voz aleatoria |
URL base: https://api.elevenlabs.io
Autenticación: Todas las solicitudes requieren el encabezado xi-api-key:
xi-api-key: tu_clave_api_aquí
Texto a voz con cURL
La forma más rápida de probar la API es con un comando cURL. Este ejemplo utiliza la voz Rachel (ID: 21m00Tcm4TlvDq8ikWAM), una de las voces predeterminadas disponibles en todos los planes:
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Bienvenido a nuestra aplicación. Este audio fue generado usando la API de ElevenLabs.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
Si tiene éxito, obtendrás un archivo speech.mp3 con el audio generado. Reprodúcelo con cualquier reproductor multimedia.
Desglose de la solicitud:
- voice_id (en la URL): El ID de la voz a usar. Cada voz en ElevenLabs tiene un ID único.
- text: El contenido a convertir a voz. El modelo Flash v2.5 soporta hasta 40,000 caracteres por solicitud.
- model_id: Qué modelo de IA usar.
eleven_flash_v2_5ofrece el mejor equilibrio entre velocidad y calidad. - voice_settings: Parámetros opcionales de ajuste fino (cubiertos en detalle a continuación).
La respuesta devuelve datos de audio sin procesar. El formato predeterminado es MP3, pero puedes solicitar otros formatos agregando el parámetro de consulta output_format:
# Obtener audio PCM en lugar de MP3
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Hola mundo", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
Uso del SDK de Python
El SDK oficial de Python simplifica la integración con sugerencias de tipos, reproducción de audio incorporada y soporte de streaming.
Instalación
pip install elevenlabs
Para reproducir audio directamente a través de tus altavoces, también puedes necesitar mpv o ffmpeg:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
Texto a voz básico
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="La API de ElevenLabs facilita la adición de salida de voz realista a cualquier aplicación.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # Voz de George
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
Guardar audio en archivo
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="tu_clave_api")
audio = client.text_to_speech.convert(
text="Este audio se guardará en un archivo.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("Audio guardado en output.mp3")
Listar voces disponibles
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="tu_clave_api")
response = client.voices.search()
for voice in response.voices:
print(f"Nombre: {voice.name}, ID: {voice.voice_id}, Categoría: {voice.category}")
Esto imprime todas las voces disponibles en tu cuenta, incluyendo voces preestablecidas, voces clonadas y voces de la comunidad que hayas añadido.
Soporte asíncrono
Para aplicaciones que utilizan asyncio, el SDK proporciona AsyncElevenLabs:
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="tu_clave_api")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="Esto fue generado asincrónicamente.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("Audio asíncrono guardado.")
asyncio.run(generate_speech())
Uso del SDK de JavaScript
El SDK oficial de Node.js (@elevenlabs/elevenlabs-js) proporciona soporte completo de TypeScript y funciona en entornos Node.js.
Instalación
npm install @elevenlabs/elevenlabs-js
Texto a voz básico
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // ID de voz de Rachel
{
text: "¡Hola desde el SDK de JavaScript de ElevenLabs!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
Guardar en archivo (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Este audio se escribirá en un archivo utilizando flujos de Node.js.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("Audio guardado en output.mp3");
Manejo de errores
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Probando el manejo de errores.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`Error de API: ${error.message}, Estado: ${error.statusCode}`);
} else {
console.error("Error inesperado:", error);
}
}
El SDK reintenta las solicitudes fallidas hasta 2 veces por defecto, con un tiempo de espera de 60 segundos. Ambos valores son configurables.
Transmisión de audio en tiempo real
Para chatbots, asistentes de voz o cualquier aplicación donde la latencia sea importante, la transmisión te permite comenzar a reproducir audio antes de que se genere la respuesta completa. Esto es crucial para la IA conversacional, donde los usuarios esperan respuestas casi instantáneas.
Transmisión en Python
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="tu_clave_api")
audio_stream = client.text_to_speech.stream(
text="La transmisión permite escuchar el audio casi al instante, sin esperar a que se complete toda la generación.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Reproducir audio transmitido a través de los altavoces en tiempo real
stream(audio_stream)
Transmisión en JavaScript
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "Este audio se transmite en tiempo real con una latencia mínima.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
Transmisión por WebSocket
Para la latencia más baja, usa conexiones WebSocket. Esto es ideal para agentes de voz en tiempo real donde el texto llega en fragmentos (por ejemplo, desde un LLM):
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Enviar configuración inicial
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "tu_clave_api",
}))
# Enviar fragmentos de texto a medida que llegan (por ejemplo, desde un LLM)
text_chunks = [
"¡Hola! ",
"Esto es transmisión ",
"vía WebSockets. ",
"Cada fragmento se envía por separado."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Señal de fin de entrada
await ws.send(json.dumps({"text": ""}))
# Recibir fragmentos de audio
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("Audio de WebSocket guardado.")
asyncio.run(stream_tts_websocket())
Selección y gestión de voces
ElevenLabs ofrece cientos de voces. Elegir la correcta es importante para la experiencia de usuario de tu aplicación.
Voces predeterminadas
Estas voces están disponibles en todos los planes, incluido el nivel gratuito:
| Nombre de la Voz | ID de Voz | Descripción |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | Femenina, joven, tranquila |
| Drew | 29vD33N1CtxCmqQRPOHJ | Masculina, equilibrada |
| Clyde | 2EiwWnXFnvU5JabPnv8n | Personaje veterano de guerra |
| Paul | 5Q0t7uMcjvnagumLfvZi | Reportero de campo |
| Domi | AZnzlk1XvdvUeBnXmlld | Femenina, fuerte, asertiva |
| Dave | CYw3kZ02Hs0563khs1Fj | Masculina británica conversacional |
| Fin | D38z5RcWu1voky8WS1ja | Masculina irlandesa |
| Sarah | EXAVITQu4vr4xnSDxMaL | Femenina, joven, suave |
Búsqueda de ID de voz
Usa la API para buscar todas las voces disponibles:
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
O filtra por categoría (preestablecidas, clonadas, generadas):
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="tu_clave_api")
# Listar solo voces preestablecidas
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
También puedes copiar un ID de voz directamente desde el sitio web de ElevenLabs: selecciona una voz, haz clic en el menú de tres puntos y elige Copiar ID de voz.
Eligiendo el modelo correcto
ElevenLabs ofrece múltiples modelos, cada uno optimizado para diferentes casos de uso:

# Listar todos los modelos disponibles con detalles
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="tu_clave_api")
models = client.models.list()
for model in models:
print(f"Modelo: {model.name}")
print(f" ID: {model.model_id}")
print(f" Idiomas: {len(model.languages)}")
print(f" Máx. caracteres: {model.max_characters_request_free_user}")
print()
Probando la API de ElevenLabs con Apidog
Antes de escribir código de integración, es útil probar los puntos finales de la API de forma interactiva. Apidog lo hace sencillo: puedes configurar solicitudes visualmente, inspeccionar respuestas (incluido audio) y generar código de cliente una vez que estés satisfecho.
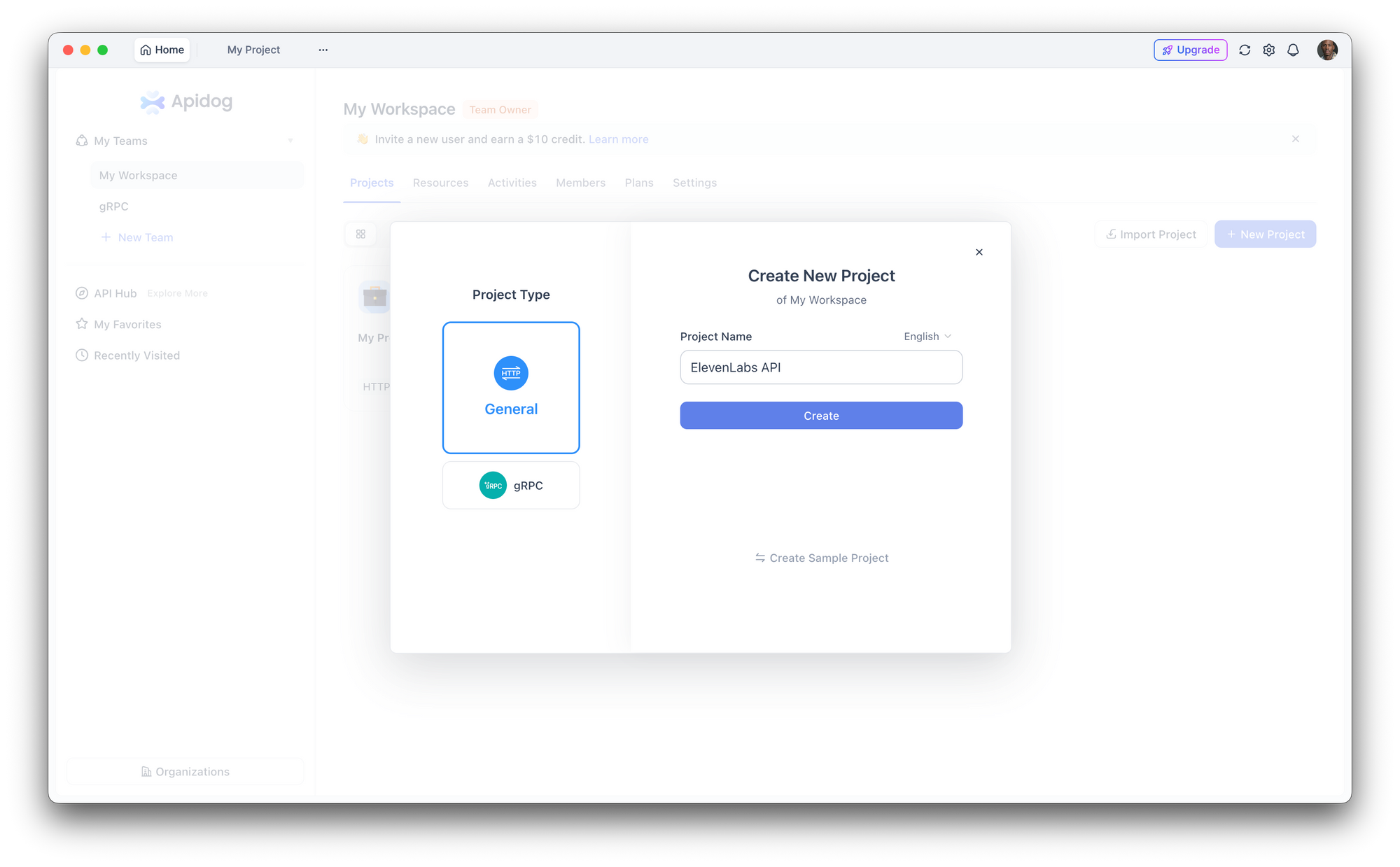
Paso 1: Configurar un nuevo proyecto
Abre Apidog y crea un nuevo proyecto. Nómbralo "API de ElevenLabs" o agrega los puntos finales a un proyecto existente.
Paso 2: Configurar la autenticación
Ve a Configuración del proyecto > Autenticación y configura un encabezado global:
- Nombre del encabezado:
xi-api-key - Valor del encabezado: tu clave API de ElevenLabs
Esto adjunta automáticamente la autenticación a cada solicitud en el proyecto.
Paso 3: Crear una solicitud de texto a voz
Crea una nueva solicitud POST:
- URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - Cuerpo (JSON):
{
"text": "Probando la API de ElevenLabs a través de Apidog. Esto facilita experimentar con diferentes voces y configuraciones.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
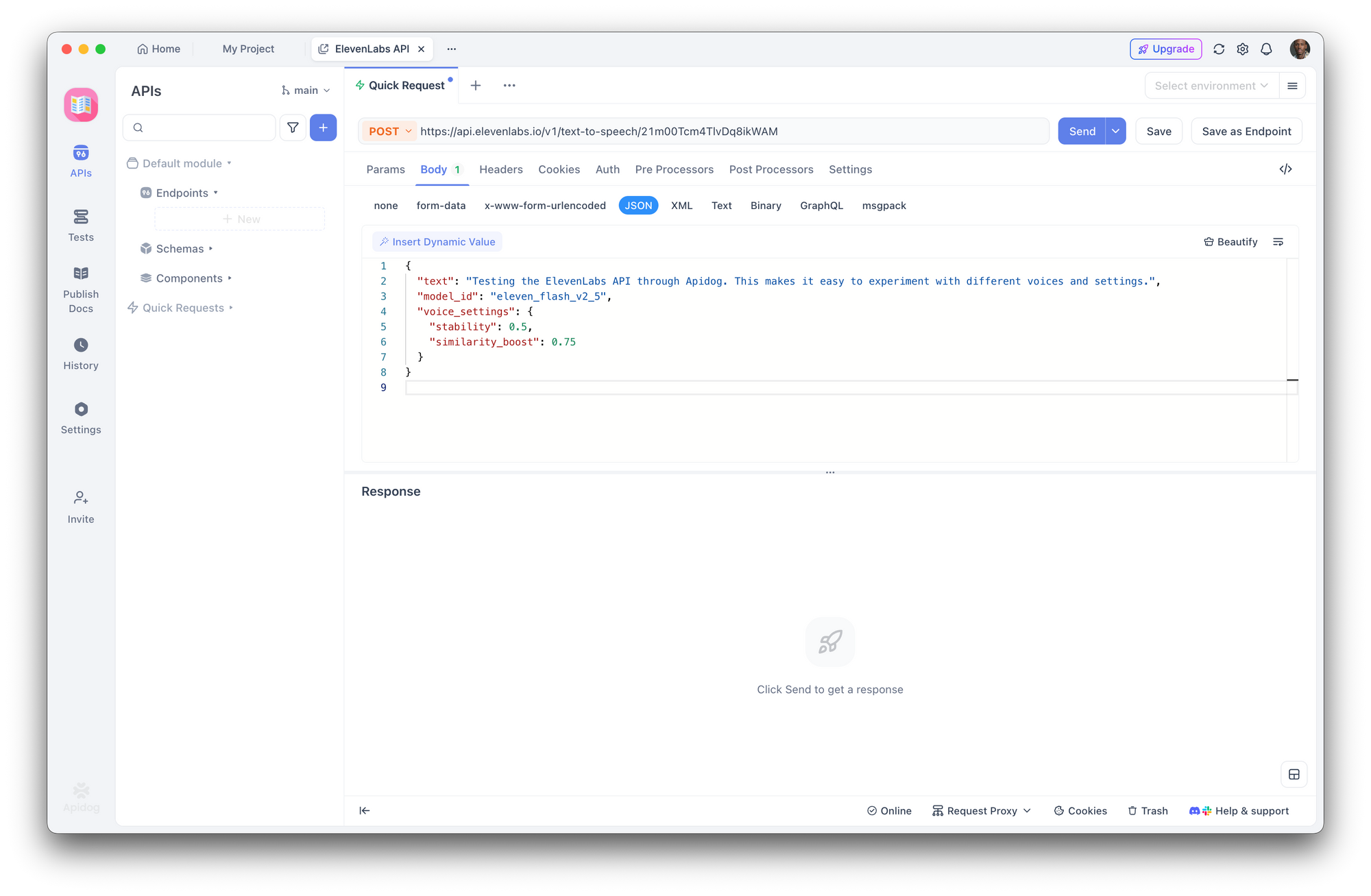
Haz clic en Enviar. Apidog muestra los encabezados de respuesta y te permite descargar o reproducir el audio directamente.
Paso 4: Experimentar con parámetros
Utiliza la interfaz de Apidog para intercambiar rápidamente ID de voz, cambiar modelos o ajustar la configuración de voz sin editar el JSON sin procesar. Guarda diferentes configuraciones como puntos finales separados en tu colección para una fácil comparación.
Paso 5: Generar código de cliente
Una vez que hayas confirmado que la solicitud funciona, haz clic en Generar código en Apidog para obtener código de cliente listo para usar en Python, JavaScript, cURL, Go, Java y más. Esto elimina la traducción manual de la documentación de la API a código funcional.
Pruébalo ahora:Descarga Apidog gratis
Configuración de voz y ajuste fino
La configuración de voz te permite ajustar cómo suena una voz. Estos parámetros se envían en el objeto voice_settings:
| Parámetro | Rango | Predeterminado | Efecto |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | Mayor = más consistente, menos expresiva. Menor = más variable, más emocional. |
similarity_boost | 0.0 - 1.0 | 0.75 | Mayor = más cercana a la voz original. Menor = más variación. |
style | 0.0 - 1.0 | 0.0 | Mayor = estilo más exagerado. Aumenta la latencia. Solo para Multilingual v2. |
use_speaker_boost | booleano | verdadero | Aumenta la similitud con el hablante original. Ligero aumento de la latencia. |
Ejemplos prácticos:
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="tu_clave_api")
# Voz de narración: consistente, estable
narration = client.text_to_speech.convert(
text="Capítulo Uno. Era un día brillante y frío de abril.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# Voz conversacional: expresiva, natural
conversational = client.text_to_speech.convert(
text="¡Oh, vaya, esa es una gran idea! Déjame pensar cómo podríamos hacer que funcione.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
Pautas:
- Para audiolibros y narración, usa una estabilidad más alta (0.7-0.9) para una entrega consistente.
- Para chatbots e IA conversacional, usa una estabilidad más baja (0.3-0.5) para una variación natural.
- Para voces de personajes, experimenta con un
similarity_boostmás bajo (0.4-0.6) para crear personalidades distintivas. - El parámetro
stylesolo funciona con Multilingual v2 y añade latencia; evítalo para aplicaciones en tiempo real.
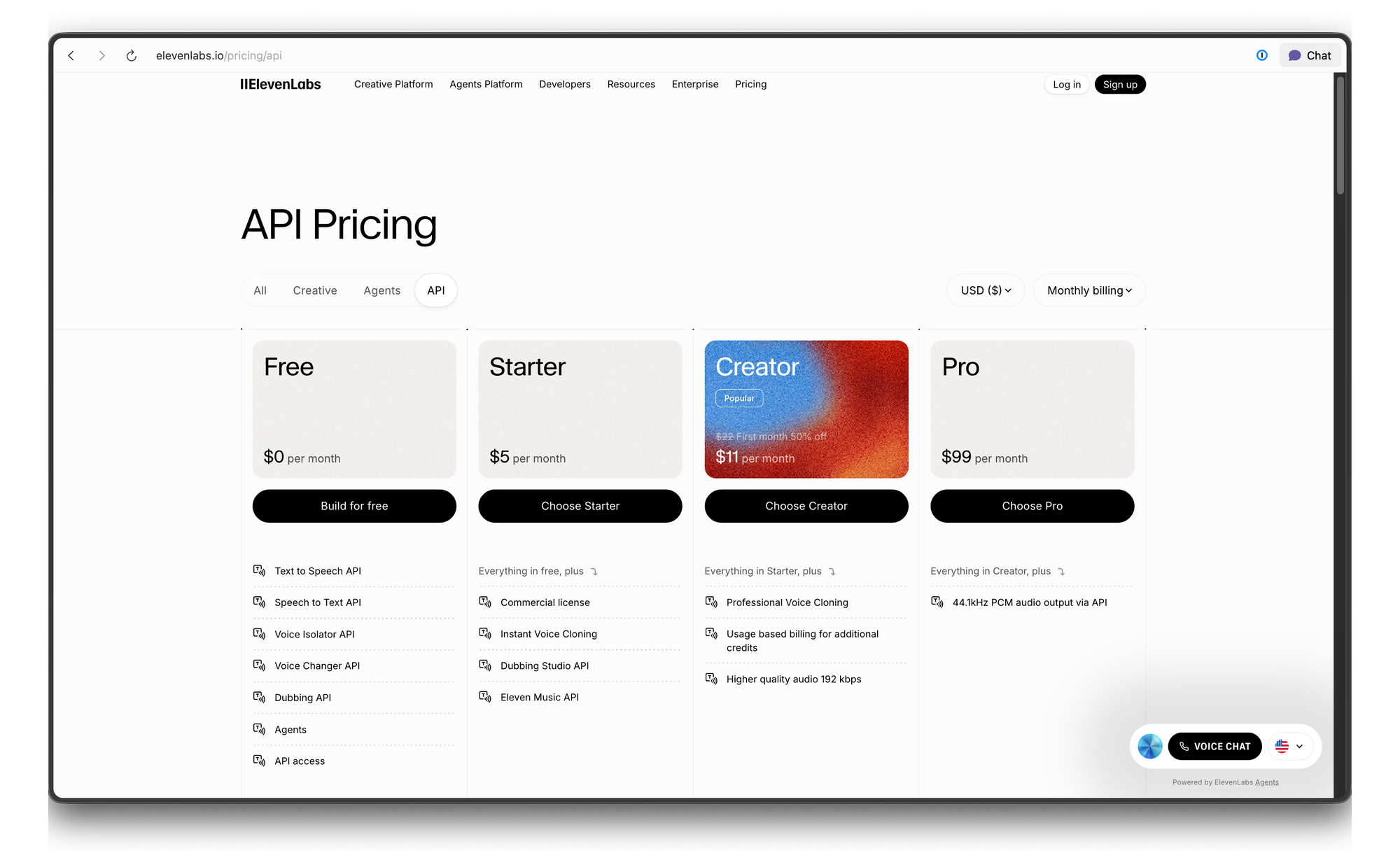
Precios y límites de tasa de la API de ElevenLabs
ElevenLabs utiliza un sistema de precios basado en créditos. Aquí tienes el desglose:
Solución de problemas
| Error | Causa | Solución |
|---|---|---|
| 401 No autorizado | Clave API inválida o ausente | Comprueba el valor de tu encabezado xi-api-key |
| 422 Entidad no procesable | Cuerpo de la solicitud inválido | Verifica que voice_id exista y que el texto no esté vacío |
| 429 Demasiadas solicitudes | Límite de tasa excedido | Añade un retroceso exponencial o actualiza tu plan |
| El audio suena robótico | Modelo o configuración incorrecta | Prueba Multilingual v2 con estabilidad en 0.5 |
| Errores de pronunciación | Problema de normalización de texto | Escribe los números/abreviaturas, o usa formato tipo SSML |
Conclusión
La API de ElevenLabs brinda a los desarrolladores acceso a una de las síntesis de voz más realistas disponibles hoy en día. Ya sea que necesites unas pocas líneas de narración o una pipeline de voz completa en tiempo real, la API escala desde simples llamadas cURL hasta transmisiones de WebSocket en producción.
¿Listo para añadir voz realista a tu aplicación? Descarga Apidog para probar los puntos finales de la API de ElevenLabs, experimentar con la configuración de voz y generar código de cliente, todo gratis y sin necesidad de tarjeta de crédito.