
Los ingenieros de DeepSeek lanzan DeepSeek-V3.1-Terminus como una mejora iterativa de su modelo V3.1, abordando problemas reportados por los usuarios y amplificando sus puntos fuertes. Esta versión se centra en mejoras prácticas que los desarrolladores valoran en aplicaciones del mundo real, como salidas de lenguaje consistentes y funcionalidades de agente robustas. A medida que los modelos de IA evolucionan, equipos como DeepSeek priorizan los refinamientos que aumentan la fiabilidad sin revisar la base. En consecuencia, DeepSeek-V3.1-Terminus surge como una herramienta pulida para tareas que van desde la generación de código hasta el razonamiento complejo.
Este lanzamiento subraya el compromiso de DeepSeek con la innovación de código abierto. El modelo ahora reside en Hugging Face, lo que permite un acceso inmediato para la experimentación. Los ingenieros se basan en la base V3.1, introduciendo ajustes que mejoran el rendimiento en todos los puntos de referencia. Como resultado, los usuarios experimentan menos frustraciones, como respuestas mezcladas en chino-inglés o caracteres erráticos, que antes dificultaban las interacciones fluidas.
Comprendiendo la Arquitectura de DeepSeek-V3.1-Terminus
Los arquitectos de DeepSeek diseñan DeepSeek-V3.1-Terminus con un marco híbrido de Mezcla de Expertos (MoE), reflejando la estructura de su predecesor, DeepSeek-V3. Este enfoque combina componentes densos y dispersos, permitiendo que el modelo active solo los expertos relevantes para tareas específicas. En consecuencia, logra una alta eficiencia, procesando consultas con una sobrecarga computacional reducida en comparación con los modelos completamente densos.

En su núcleo, el modelo cuenta con 685 mil millones de parámetros, distribuidos entre módulos expertos. Los ingenieros emplean tipos de tensor BF16, F8_E4M3 y F32 para estos parámetros, optimizando tanto la precisión como la velocidad. Sin embargo, un problema notado implica que la proyección de salida de autoatención no se adhiere completamente al formato de escala UE8M0 FP8, lo que DeepSeek planea resolver en próximas iteraciones. Este defecto menor no resta valor significativamente a la funcionalidad general, pero resalta la naturaleza iterativa del desarrollo de modelos.
Además, DeepSeek-V3.1-Terminus admite modos de pensamiento y no pensamiento. En el modo de pensamiento, el modelo se involucra en un razonamiento de múltiples pasos, basándose en la lógica interna para manejar problemas complejos. El modo de no pensamiento, por el contrario, prioriza las respuestas rápidas para consultas sencillas. Esta dualidad proviene del post-entrenamiento en un punto de control V3.1-Base extendido, que incorpora un método de extensión de contexto largo de dos fases. Los desarrolladores recopilan documentos largos adicionales para reforzar el conjunto de datos, extendiendo las fases de entrenamiento para un mejor manejo del contexto.
Mejoras Clave en DeepSeek-V3.1-Terminus Respecto a Versiones Anteriores
Los ingenieros de DeepSeek refinan DeepSeek-V3.1-Terminus abordando los comentarios de la versión V3.1, lo que resulta en mejoras tangibles. Principalmente, reducen las inconsistencias lingüísticas, eliminando las frecuentes mezclas de chino-inglés y los caracteres aleatorios que plagaban las salidas anteriores. Este cambio garantiza respuestas más limpias y profesionales, especialmente en entornos multilingües.
Además, las actualizaciones de los agentes destacan como un avance importante. Los Agentes de Código ahora manejan tareas de programación con mayor precisión, mientras que los Agentes de Búsqueda mejoran la eficiencia de recuperación. Estas mejoras provienen de datos de entrenamiento refinados y plantillas actualizadas, lo que permite que el modelo integre herramientas de manera más fluida.
Las comparaciones de puntos de referencia revelan estas ganancias cuantitativamente. Por ejemplo, en el modo de razonamiento sin uso de herramientas, las puntuaciones de MMLU-Pro aumentan de 84.8 a 85.0, y GPQA-Diamond mejora de 80.1 a 80.7. Humanity's Last Exam experimenta un salto sustancial de 15.9 a 21.7, lo que demuestra un rendimiento más sólido en evaluaciones desafiantes. LiveCodeBench se mantiene casi estable en 74.9, con fluctuaciones menores en Codeforces y Aider-Polyglot.
Pasando al uso de herramientas de agente, el modelo sobresale aún más. BrowseComp aumenta de 30.0 a 38.5, y SimpleQA sube de 93.4 a 96.8. SWE Verified avanza a 68.4 desde 66.0, SWE-bench Multilingual a 57.8 desde 54.5, y Terminal-bench a 36.7 desde 31.3. Aunque BrowseComp-zh disminuye ligeramente, las tendencias generales indican una fiabilidad superior.
Además, DeepSeek-V3.1-Terminus logra esto sin sacrificar la velocidad. Responde más rápido que algunos competidores manteniendo una calidad comparable a DeepSeek-R1 en puntos de referencia difíciles. Este equilibrio surge de un post-entrenamiento optimizado, que incorpora datos de contexto largo para una mejor generalización.
Puntos de Referencia de Rendimiento y Evaluaciones para DeepSeek-V3.1-Terminus
Los evaluadores valoran DeepSeek-V3.1-Terminus en diversos puntos de referencia, revelando sus fortalezas en razonamiento e integración de herramientas. En el razonamiento sin herramientas, el modelo obtiene una puntuación de 85.0 en MMLU-Pro, mostrando una amplia retención de conocimientos. GPQA-Diamond alcanza 80.7, lo que indica competencia en preguntas de nivel de posgrado.
Además, Humanity's Last Exam con 21.7 destaca una mejor gestión de temas esotéricos. Los puntos de referencia de codificación como LiveCodeBench (74.9) y Aider-Polyglot (76.1) demuestran utilidad práctica, aunque Codeforces baja a 2046, lo que sugiere áreas para un ajuste adicional.
Transitando a escenarios de agente, la puntuación de 38.5 de BrowseComp refleja capacidades mejoradas de navegación web. El casi perfecto 96.8 de SimpleQA subraya la precisión en la resolución de consultas. Las suites SWE-bench, incluyendo Verified (68.4) y Multilingual (57.8), afirman su destreza en ingeniería de software. Terminal-bench con 36.7 muestra competencia en interacciones de línea de comandos.
Comparativamente, DeepSeek-V3.1-Terminus supera a V3.1 en la mayoría de las métricas, logrando una ventaja de costo de 68x con mínimas compensaciones de rendimiento. Rivaliza con modelos de código cerrado en eficiencia, lo que lo hace ideal para aplicaciones empresariales.
Integrando DeepSeek-V3.1-Terminus con APIs y Herramientas como Apidog
Los desarrolladores integran DeepSeek-V3.1-Terminus a través de su API compatible con OpenAI, simplificando la adopción. Especifican 'deepseek-chat' para el modo de no pensamiento o 'deepseek-reasoner' para el modo de pensamiento.
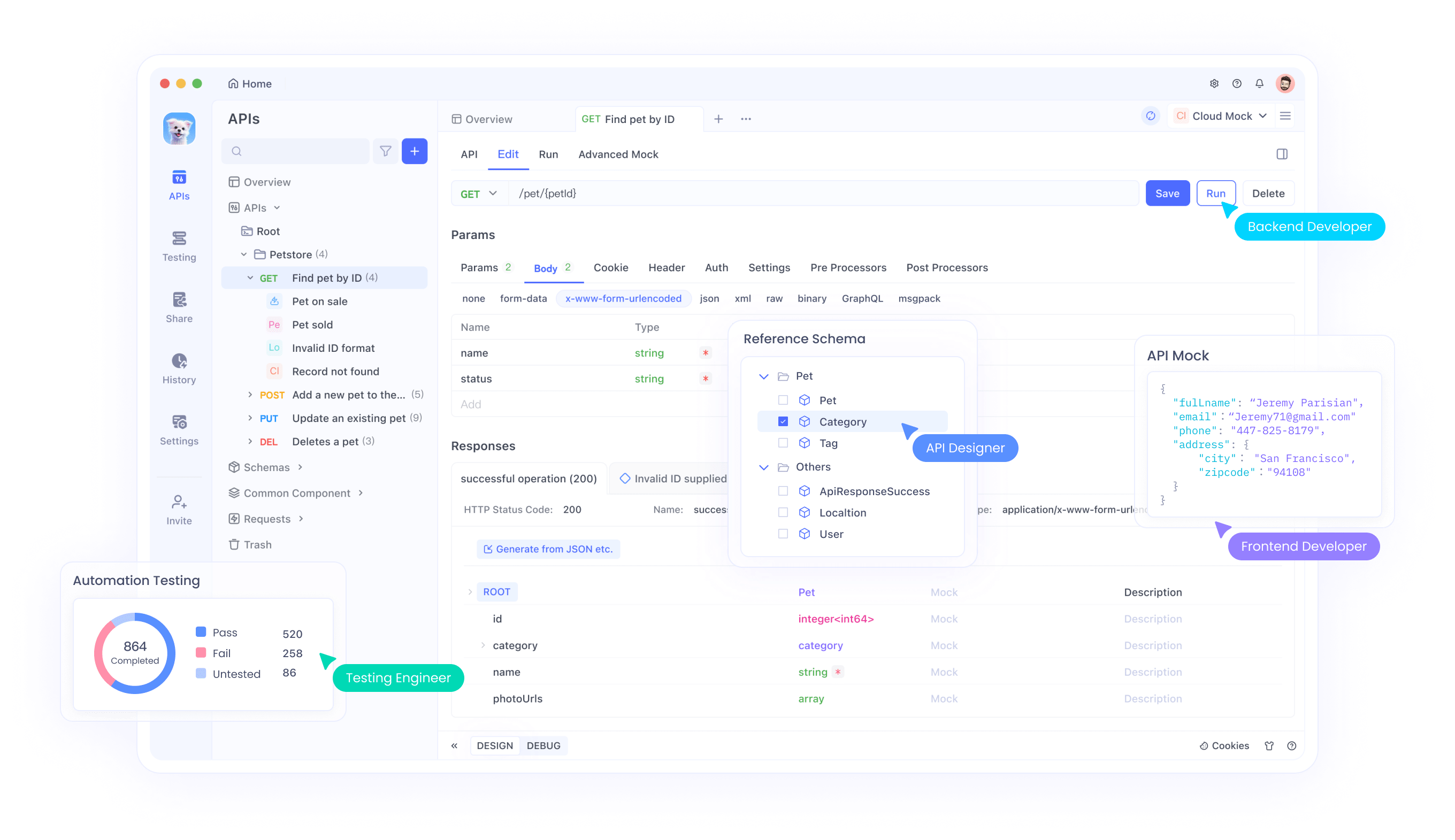
Para empezar, los usuarios generan una clave API en la plataforma DeepSeek. Con Apidog, configuran entornos introduciendo la URL base (https://api.deepseek.com) y almacenando la clave como una variable. Esta configuración facilita las pruebas de finalización de chat y llamadas a funciones.
Además, Apidog soporta la depuración, permitiendo a los desarrolladores verificar las respuestas de manera eficiente. Para la llamada a funciones, definen herramientas en las solicitudes, permitiendo que el modelo invoque funciones externas dinámicamente.
El precio sigue siendo competitivo a $1.68 por millón de tokens de salida, fomentando un uso generalizado. Las integraciones se extienden a frameworks como Geneplore AI o AI/ML API, soportando sistemas multiagente.
Comparaciones con Modelos de IA Competidores
DeepSeek-V3.1-Terminus compite eficazmente contra modelos como DeepSeek-R1, igualando la calidad en el razonamiento mientras responde más rápido. Supera a V3.1 en el uso de herramientas, con ganancias de BrowseComp de 8.5 puntos.
Frente a las opciones propietarias, ofrece accesibilidad de código abierto y eficiencia de costos. Por ejemplo, se acerca al rendimiento de nivel Sonnet en los puntos de referencia.
Además, sus modos híbridos proporcionan una versatilidad ausente en algunos competidores. Por lo tanto, atrae a desarrolladores conscientes del presupuesto que buscan características robustas.
Estrategias de Despliegue para DeepSeek-V3.1-Terminus
Los ingenieros despliegan el modelo localmente usando el repositorio DeepSeek-V3. Para la nube, plataformas como AWS Bedrock lo alojan.
El código de inferencia optimizado en el repositorio facilita la configuración. Por lo tanto, la escalabilidad se adapta a varios entornos.
Características Avanzadas: Llamada a Funciones e Integración de Herramientas
Los desarrolladores implementan la llamada a funciones definiendo esquemas en las solicitudes de API. Esto permite interacciones dinámicas, como consultar bases de datos.
Apidog ayuda a probar estas características, asegurando integraciones robustas.
Análisis de Costos y Consejos de Optimización
Con bajos costos por token, DeepSeek-V3.1-Terminus ofrece valor. Optimice seleccionando los modos sabiamente: no pensamiento para tareas simples.
Supervise el uso a través de Apidog para gestionar los gastos de manera efectiva.
Comentarios de Usuarios y Recepción de la Comunidad
Los usuarios celebran el lanzamiento, destacando las mejoras de estabilidad. Algunos anticipan la V4, lo que refleja altas expectativas.
Foros como Reddit están llenos de discusiones sobre sus fortalezas como agente.
Conclusión: Adoptando DeepSeek-V3.1-Terminus en el Desarrollo de IA
DeepSeek-V3.1-Terminus refina las capacidades de IA, ofreciendo a los desarrolladores una herramienta potente y eficiente. Sus mejoras en agentes y lenguaje allanan el camino para aplicaciones innovadoras. A medida que los equipos lo adoptan, el modelo continúa evolucionando, impulsado por la contribución de la comunidad.