
¿Estás buscando implementar Deepseek R1 —uno de los modelos de lenguaje grandes más potentes— en una plataforma en la nube? Ya sea que estés trabajando en AWS, Azure o Digital Ocean, esta guía te tiene cubierto. Al final de esta publicación, tendrás una hoja de ruta clara para poner en marcha tu modelo Deepseek R1 con facilidad. Además, te mostraremos cómo herramientas como Apidog pueden ayudar a optimizar las pruebas de API durante la implementación.
¿Por qué implementar Deepseek R1 en la nube?
Implementar Deepseek R1 en la nube no se trata solo de escalabilidad; se trata de aprovechar el poder de las GPU y la infraestructura sin servidor para manejar cargas de trabajo masivas de manera eficiente. Con sus 671B parámetros, Deepseek R1 exige hardware robusto y configuraciones optimizadas. La nube proporciona flexibilidad, rentabilidad y recursos de alto rendimiento que hacen que la implementación de tales modelos sea factible incluso para equipos más pequeños.
En esta guía, te guiaremos a través de la implementación de Deepseek R1 en tres plataformas populares: AWS, Azure y Digital Ocean. También compartiremos consejos para optimizar el rendimiento e integrar herramientas como Apidog para la gestión de API.
Preparando tu entorno
Antes de lanzarnos a la implementación, preparemos nuestro entorno. Esto implica configurar tokens de autenticación, garantizar la disponibilidad de la GPU y organizar tus archivos.
Tokens de autenticación
Cada proveedor de la nube requiere alguna forma de autenticación. Por ejemplo:
- En AWS , necesitarás un rol de IAM con permisos para acceder a los buckets de S3 y las instancias de EC2.
- En Azure , puedes usar experiencias de autenticación simplificadas proporcionadas por los SDK de Azure Machine Learning.
- En Digital Ocean , genera un token de API desde el panel de control de tu cuenta.
Estos tokens son cruciales porque permiten una comunicación segura entre tu máquina local y la plataforma en la nube.
Organización de archivos
Organiza tus archivos sistemáticamente. Si estás usando Docker (lo cual es altamente recomendado), crea un Dockerfile que contenga todas las dependencias. Herramientas como Tensorfuse proporcionan plantillas preconstruidas para implementar Deepseek R1. De manera similar, los usuarios de IBM Cloud deben cargar sus archivos de modelo a Object Storage antes de continuar.
Opción 1: Implementar Deepseek R1 en AWS usando Tensorfuse
Comencemos con Amazon Web Services (AWS), una de las plataformas en la nube más utilizadas. AWS es como una navaja suiza: tiene herramientas para cada tarea, desde almacenamiento hasta potencia de cómputo. En esta sección, nos centraremos en la implementación de Deepseek R1 usando Tensorfuse, lo cual simplifica el proceso significativamente.
¿Por qué construir con Deepseek-R1?
Antes de sumergirnos en los detalles técnicos, entendamos por qué Deepseek R1 destaca:
- Alto rendimiento en evaluaciones: Logra resultados sólidos en puntos de referencia estándar de la industria, obteniendo un 90.8% en MMLU y un 79.8% en AIME 2024.
- Razonamiento avanzado: Maneja tareas de razonamiento lógico de varios pasos con un contexto mínimo, sobresaliendo en puntos de referencia como LiveCodeBench (Pass@1-COT) con una puntuación de 65.9%.
- Soporte multilingüe: Preentrenado en datos lingüísticos diversos, lo que lo hace experto en la comprensión multilingüe.
- Modelos destilados escalables: Las variantes destiladas más pequeñas (2B, 7B y 70B) ofrecen opciones más económicas sin comprometer el costo.
Estas fortalezas hacen de Deepseek R1 una excelente opción para aplicaciones listas para producción, desde chatbots hasta análisis de datos a nivel empresarial.
Prerrequisitos
Antes de comenzar, asegúrate de haber configurado Tensorfuse en tu cuenta de AWS. Si aún no lo has hecho, sigue la guía de Introducción. Esta configuración es como preparar tu espacio de trabajo antes de comenzar un proyecto: asegura que todo esté en su lugar para un proceso sin problemas.
Paso 1: Establece tu token de autenticación de API
Genera una cadena aleatoria que se utilizará como tu token de autenticación de API. Guárdalo como un secreto en Tensorfuse usando el siguiente comando:
tensorkube secret create vllm-token VLLM_API_KEY=vllm-key --env default
Asegúrate de que en producción, uses un token generado aleatoriamente. Puedes generar uno rápidamente usando openssl rand -base64 32 y recuerda mantenerlo seguro ya que los secretos de Tensorfuse son opacos.
Paso 2: Prepara el Dockerfile
Usaremos la imagen oficial de vLLM OpenAI como nuestra imagen base. Esta imagen viene con todas las dependencias necesarias para ejecutar vLLM.
Aquí está la configuración del Dockerfile:
# Dockerfile for Deepseek-R1-671B
FROM vllm/vllm-openai:latest
# Enable HF Hub Transfer
ENV HF_HUB_ENABLE_HF_TRANSFER 1
# Expose port 80
EXPOSE 80
# Entrypoint with API key
ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "deepseek-ai/DeepSeek-R1", \
"--dtype", "bfloat16", \
"--trust-remote-code", \
"--tensor-parallel-size","8", \
"--max-model-len", "4096", \
"--port", "80", \
"--cpu-offload-gb", "80", \
"--gpu-memory-utilization", "0.95", \
"--api-key", "${VLLM_API_KEY}"]
Esta configuración asegura que el servidor vLLM esté optimizado para los requisitos específicos de Deepseek R1, incluyendo la utilización de la memoria de la GPU y el paralelismo de tensores.
Paso 3: Configuración de la implementación
Crea un archivo deployment.yaml para definir tu configuración de implementación:
# deployment.yaml for Deepseek-R1-671B
gpus: 8
gpu_type: h100
secret:
- vllm-token
min-scale: 1
readiness:
httpGet:
path: /health
port: 80
Implementa tu servicio usando el siguiente comando:
tensorkube deploy --config-file ./deployment.yaml
Este comando configura un servicio LLM de producción de escalado automático listo para servir solicitudes autenticadas.
Paso 4: Accediendo a la aplicación implementada
Una vez que la implementación sea exitosa, puedes probar tu punto final usando curl o la biblioteca cliente OpenAI de Python. Aquí hay un ejemplo usando curl:
curl --request POST \
--url YOUR_APP_URL/v1/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer vllm-key' \
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "Earth to Robotland. What's up?",
"max_tokens": 200
}'
Para los usuarios de Python, aquí hay un fragmento de código de ejemplo:
import openai
# Replace with your actual URL and token
base_url = "YOUR_APP_URL/v1"
api_key = "vllm-key"
openai.api_base = base_url
openai.api_key = api_key
response = openai.Completion.create(
model="deepseek-ai/DeepSeek-R1",
prompt="Hello, Deepseek R1! How are you today?",
max_tokens=200
)
print(response)
Opción 2: Implementar Deepseek R1 en Azure
Implementar Deepseek R1 en Azure Machine Learning (Azure ML) es un proceso optimizado que aprovecha la infraestructura robusta de la plataforma y las herramientas avanzadas para la inferencia en tiempo real. En esta sección, te guiaremos a través de la implementación de Deepseek R1 usando los Managed Online Endpoints de Azure ML. Este enfoque garantiza escalabilidad, eficiencia y facilidad de gestión.
Paso 1: Crea un entorno personalizado para vLLM en Azure ML
Para comenzar, necesitamos crear un entorno personalizado adaptado para vLLM, que servirá como la columna vertebral para implementar Deepseek R1. El marco de trabajo vLLM está optimizado para la inferencia de alto rendimiento, lo que lo hace ideal para manejar modelos de lenguaje grandes como Deepseek R1.
1.1: Define el Dockerfile :Comenzamos creando un Dockerfile que especifica el entorno para nuestro modelo. El contenedor base vLLM incluye todas las dependencias y controladores necesarios, asegurando una configuración sin problemas:
FROM vllm/vllm-openai:latest
ENV MODEL_NAME deepseek-ai/DeepSeek-R1-Distill-Llama-8B
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME $VLLM_ARGS
Este Dockerfile nos permite pasar el nombre del modelo a través de una variable de entorno (MODEL_NAME), lo que permite flexibilidad al seleccionar el modelo deseado durante la implementación. Por ejemplo, puedes cambiar fácilmente entre diferentes versiones de Deepseek R1 sin modificar el código subyacente.
1.2: Inicia sesión en el espacio de trabajo de Azure ML: A continuación, inicia sesión en tu espacio de trabajo de Azure ML usando la CLI de Azure. Reemplaza <subscription ID>, <Azure Machine Learning workspace name> y <resource group> con tus detalles específicos:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Este paso asegura que todos los comandos subsiguientes se ejecuten dentro del contexto de tu espacio de trabajo.
1.3: Crea el archivo de configuración del entorno: Ahora, crea un archivo environment.yml para definir la configuración del entorno. Este archivo hace referencia al Dockerfile que creamos anteriormente:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: r1
build:
path: .
dockerfile_path: Dockerfile
1.4: Construye el entorno: Con el archivo de configuración listo, construye el entorno usando el siguiente comando:
az ml environment create -f environment.yml
Este paso compila el entorno, haciéndolo disponible para su uso en tu implementación.
Paso 2: Implementa el Managed Online Endpoint de Azure ML
Una vez que el entorno está configurado, pasamos a implementar el modelo Deepseek R1 usando Managed Online Endpoints de Azure ML. Estos puntos finales proporcionan capacidades de inferencia escalables en tiempo real, lo que los hace perfectos para aplicaciones de nivel de producción.
2.1: Crea el archivo de configuración del punto final: Comienza creando un archivo endpoint.yml para definir el Managed Online Endpoint:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: r1-prod
auth_mode: key
Esta configuración especifica el nombre del punto final (r1-prod) y el modo de autenticación (key). Puedes recuperar el URI de puntuación y las claves de API del punto final más tarde para fines de prueba.
2.2: Crea el punto final: Usa el siguiente comando para crear el punto final:
az ml online-endpoint create -f endpoint.yml
2.3: Recupera la dirección de la imagen de Docker: Antes de continuar, recupera la dirección de la imagen de Docker creada en el Paso 1. Navega a Azure ML Studio > Entornos > r1 para localizar la dirección de la imagen. Se verá algo así:
xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx
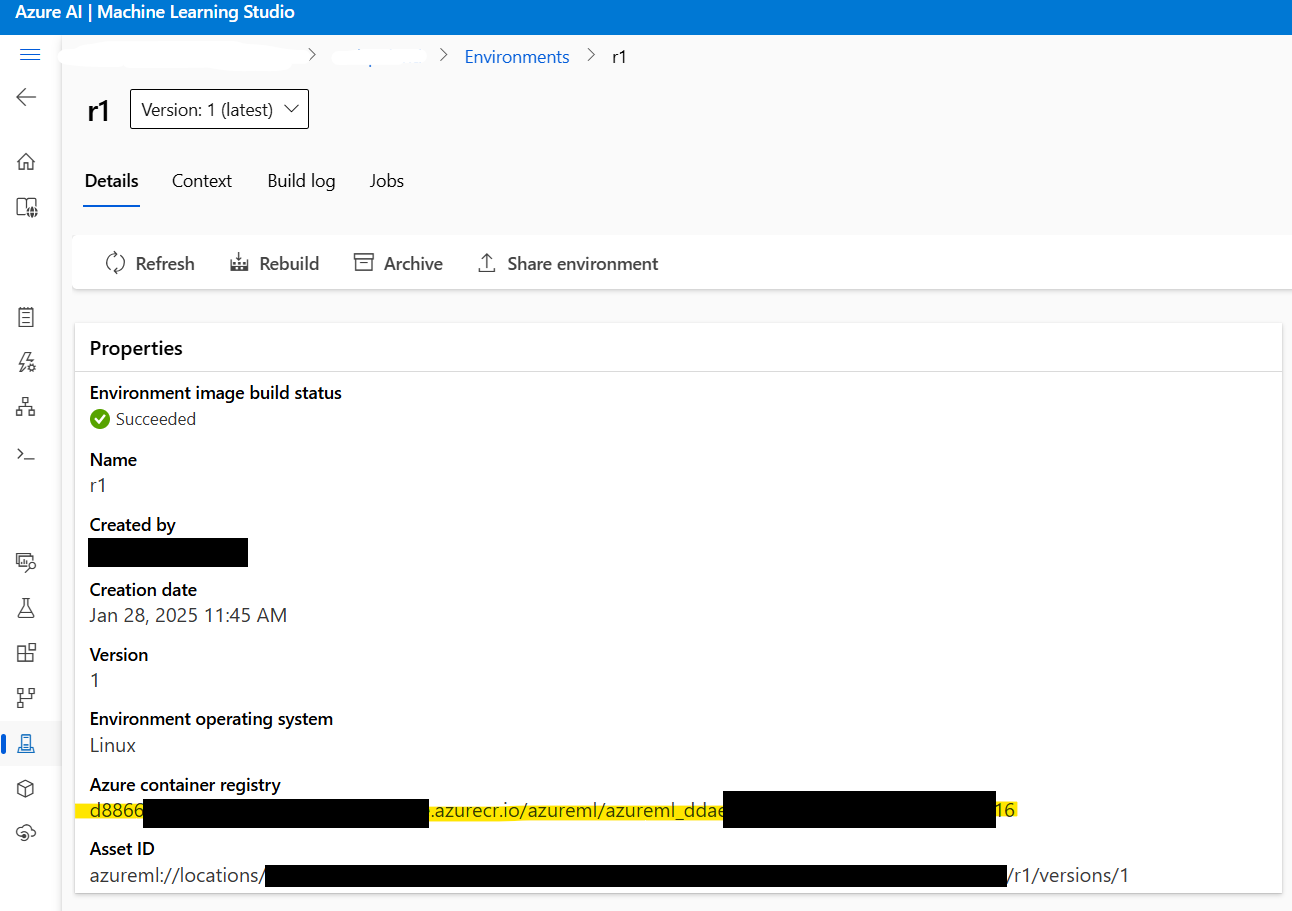
2.4: Crea el archivo de configuración de la implementación: A continuación, crea un archivo deployment.yml para configurar los ajustes de la implementación. Este archivo especifica el modelo, el tipo de instancia y otros parámetros:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: r1-prod
environment_variables:
MODEL_NAME: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
VLLM_ARGS: "" # Optional arguments for vLLM runtime
environment:
image: xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx # Paste Docker image address here
inference_config:
liveness_route:
port: 8000
path: /ping
readiness_route:
port: 8000
path: /health
scoring_route:
port: 8000
path: /
instance_type: Standard_NC24ads_A100_v4
instance_count: 1
request_settings: # Optional but important for optimizing throughput
max_concurrent_requests_per_instance: 32
request_timeout_ms: 60000
liveness_probe:
initial_delay: 10
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
readiness_probe:
initial_delay: 120 # Wait for 120 seconds before probing, allowing the model to load peacefully
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
Parámetros clave a considerar:
instance_count: Define cuántos nodos deStandard_NC24ads_A100_v4se van a activar. Aumentar este valor escala el rendimiento linealmente, pero también aumenta el costo.max_concurrent_requests_per_instance: Controla el número de solicitudes concurrentes permitidas por instancia. Los valores más altos aumentan el rendimiento, pero pueden aumentar la latencia.request_timeout_ms: Especifica el tiempo máximo (en milisegundos) que el punto final espera una respuesta antes de agotarse el tiempo. Ajusta esto según los requisitos de tu carga de trabajo.
2.5: Implementa el modelo: Finalmente, implementa el modelo Deepseek R1 usando el siguiente comando:
az ml online-deployment create -f deployment.yml --all-traffic
Este paso completa la implementación, haciendo que el modelo sea accesible a través del punto final especificado.
Paso 3: Probando la implementación
Una vez que la implementación está completa, es hora de probar el punto final para asegurar que todo esté funcionando como se espera.
3.1: Recupera los detalles del punto final: Usa los siguientes comandos para recuperar el URI de puntuación y las claves de API del punto final:
az ml online-endpoint show -n r1-prod
az ml online-endpoint get-credentials -n r1-prod
3.2: Transmite respuestas usando el SDK de OpenAI: Para transmitir respuestas, puedes usar el SDK de OpenAI:
from openai import OpenAI
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1"
client = OpenAI(base_url=url, api_key="xxxxxxxx")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
messages=[
{"role": "user", "content": "What is better, summer or winter?"},
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "content"):
print(delta.content, end="", flush=True)
Paso 4: Monitoreo y escalado automático
Azure Monitor proporciona información completa sobre la utilización de recursos, incluidas las métricas de la GPU. Cuando está bajo carga constante, notarás que vLLM consume aproximadamente el 90% de la memoria de la GPU, con una utilización de la GPU que se acerca al 100%. Estas métricas te ayudan a ajustar el rendimiento y optimizar los costos.
Para habilitar el escalado automático, configura las políticas de escalado basadas en los patrones de tráfico. Por ejemplo, puedes aumentar el instance_count durante las horas pico y reducirlo durante las horas de menor actividad para equilibrar el rendimiento y el costo.
Opción 3: Implementar Deepseek R1 en Digital Ocean
Finalmente, discutamos la implementación de Deepseek R1 en Digital Ocean , conocido por su simplicidad y asequibilidad.
Prerrequisitos
Antes de sumergirnos en el proceso de implementación, asegurémonos de que tienes todo lo que necesitas:
- Cuenta de DigitalOcean: Si aún no tienes una, regístrate para obtener una cuenta de DigitalOcean. Los nuevos usuarios reciben un crédito de $100 para los primeros 60 días, lo cual es perfecto para experimentar con droplets impulsados por GPU.
- Familiaridad con Bash Shell: Estarás usando la terminal para interactuar con tu droplet, descargar dependencias y ejecutar comandos. No te preocupes si no eres un experto: cada comando se proporcionará paso a paso.
- GPU Droplet: DigitalOcean ahora ofrece GPU droplets diseñados específicamente para cargas de trabajo de IA/ML. Estos droplets vienen equipados con GPU NVIDIA H100, lo que los hace ideales para implementar modelos grandes como Deepseek R1.
Con estos prerrequisitos en su lugar, estás listo para avanzar.
Configurando el GPU Droplet
El primer paso es configurar tu máquina. Piensa en esto como preparar el lienzo antes de pintar: quieres que todo esté listo antes de sumergirte en los detalles.
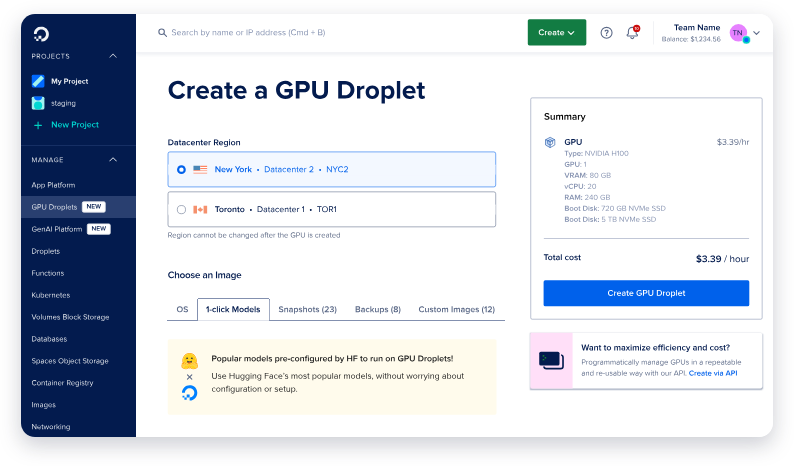
Paso 1: Crea un nuevo GPU Droplet
- Inicia sesión en tu cuenta de DigitalOcean y navega a la sección Droplets.
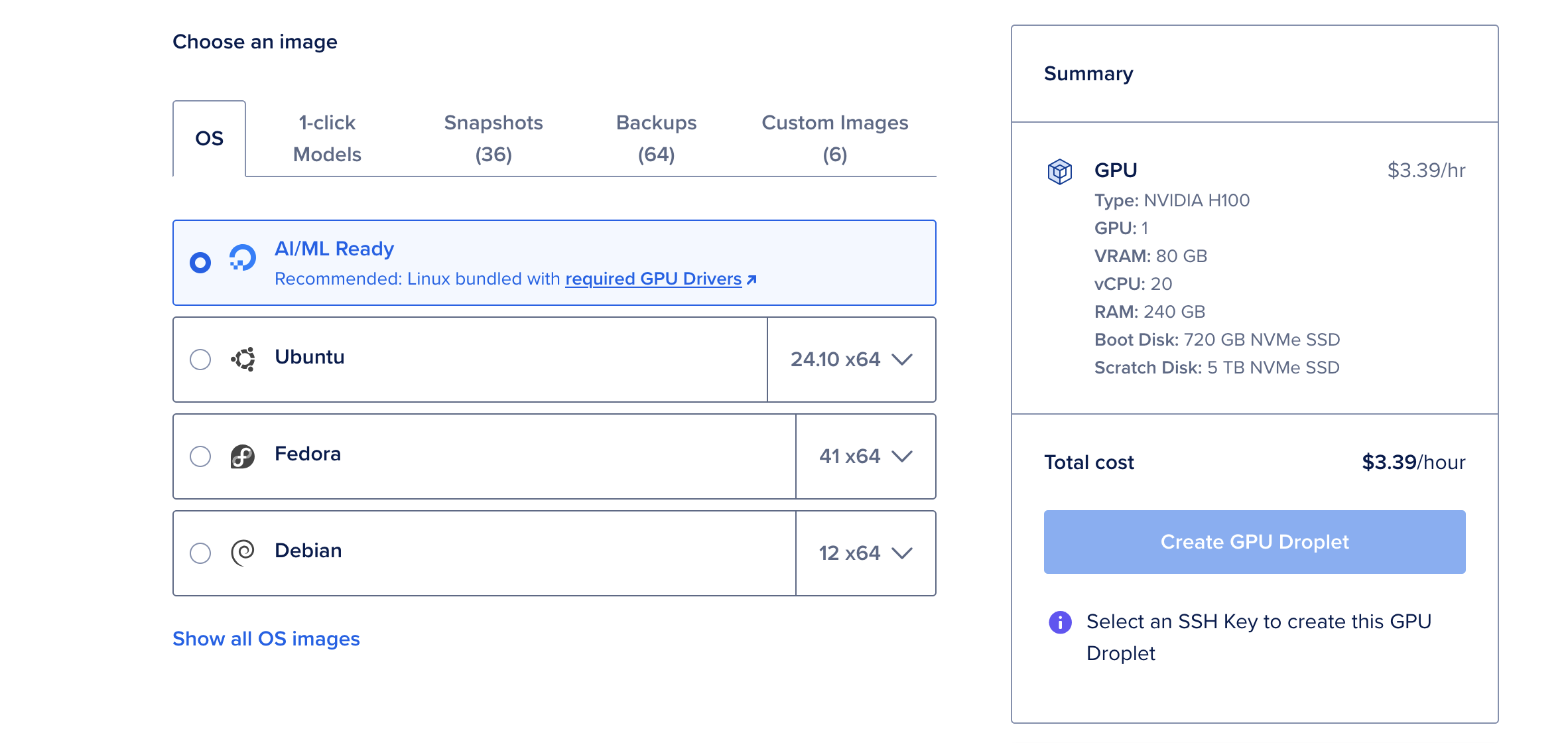
- Haz clic en Crear Droplet y selecciona el sistema operativo AI/ML Ready. Este sistema operativo viene preconfigurado con controladores CUDA y otras dependencias necesarias para la aceleración de la GPU.
- Elige una sola GPU NVIDIA H100 a menos que planees implementar la versión más grande de 671B parámetros de Deepseek R1, lo cual puede requerir múltiples GPU.
- Una vez que tu droplet esté creado, espera a que se active. Este proceso normalmente toma solo unos minutos.
¿Por qué elegir la GPU H100?
La GPU NVIDIA H100 es una potencia, que ofrece 80 GB de vRAM, 240 GB de RAM y 720 GB de almacenamiento. A $6.47 por hora, es una opción rentable para implementar modelos de lenguaje grandes como Deepseek R1. Para modelos más pequeños, como la versión de 70B parámetros, una sola GPU H100 es más que suficiente.
Instalando Ollama & Deepseek R1
Ahora que tu GPU droplet está en funcionamiento, es hora de instalar las herramientas necesarias para ejecutar Deepseek R1. Usaremos Ollama, un marco de trabajo ligero diseñado para simplificar la implementación de modelos de lenguaje grandes.
Paso 1: Abre la consola web
Desde la página de detalles de tu droplet, haz clic en el botón Consola web ubicado en la esquina superior derecha. Esto abre una ventana de terminal directamente en tu navegador, eliminando la necesidad de configuración SSH.
Paso 2: Instala Ollama
En la terminal, pega el siguiente comando para instalar Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Este script automatiza el proceso de instalación, descargando y configurando todas las dependencias necesarias. La instalación puede tomar unos minutos, pero una vez completa, tu máquina estará lista para ejecutar Deepseek R1.
Paso 3: Ejecuta Deepseek R1
Con Ollama instalado, ejecutar Deepseek R1 es tan simple como ejecutar un solo comando. Para esta demostración, usaremos la versión de 70B parámetros, que logra un equilibrio entre rendimiento y uso de recursos:
ollama run deepseek-r1:70b
La primera vez que ejecutes este comando, descargará el modelo (aproximadamente 40 GB) y lo cargará en la memoria. Este proceso puede tomar varios minutos, pero las ejecuciones posteriores serán mucho más rápidas ya que el modelo se almacena en caché localmente.
Una vez que el modelo esté cargado, verás un indicador interactivo donde puedes comenzar a interactuar con Deepseek R1. ¡Es como tener una conversación con un asistente altamente inteligente!
Pruebas y monitoreo con Apidog
Una vez que tu modelo Deepseek R1 esté implementado, es hora de probar y monitorear su rendimiento. Aquí es donde Apidog brilla. Prueba la API de DeepSeek aquí.
¿Qué es Apidog?
Apidog es una poderosa herramienta de prueba de API diseñada para simplificar la depuración y la validación. Con su interfaz intuitiva, puedes crear rápidamente casos de prueba, simular respuestas y monitorear la salud de la API.
¿Por qué usar Apidog?
- Facilidad de uso : ¡No se requiere codificación! La funcionalidad de arrastrar y soltar te permite construir pruebas visualmente.
- Capacidades de integración : Se integra perfectamente con las canalizaciones de CI/CD, lo que lo hace ideal para flujos de trabajo de DevOps.
- Información en tiempo real : Monitorea la latencia, las tasas de error y el rendimiento en tiempo real.
Al integrar Apidog en tu flujo de trabajo, puedes asegurar que tu implementación de Deepseek R1 siga siendo confiable y funcione de manera óptima bajo cargas variables.
Conclusión
Implementar Deepseek R1 en la nube no tiene por qué ser desalentador. Siguiendo los pasos descritos anteriormente, puedes configurar con éxito este modelo de vanguardia en AWS, Azure o Digital Ocean. Recuerda aprovechar herramientas como Apidog para optimizar los procesos de prueba y monitoreo.


