
Los desarrolladores e investigadores buscan constantemente formas de unir datos visuales con el procesamiento textual en inteligencia artificial. DeepSeek-AI aborda este desafío con DeepSeek-OCR, un modelo que se centra en la compresión óptica de contextos. Lanzada el 20 de octubre de 2025, esta herramienta examina los codificadores de visión desde una perspectiva centrada en LLM y amplía los límites de la compresión de información visual en contextos textuales. Los ingenieros integran estos modelos para manejar tareas complejas como la conversión de documentos y la descripción de imágenes de manera eficiente.
La compresión óptica de contextos se refiere al proceso en el que los codificadores visuales condensan los datos de imagen en representaciones textuales compactas que los modelos de lenguaje grandes (LLM) procesan de manera efectiva. Los sistemas OCR tradicionales extraen texto, pero a menudo ignoran los matices contextuales, como los diseños o las relaciones espaciales. DeepSeek-OCR supera estas limitaciones al enfatizar la compresión que preserva los detalles esenciales. El modelo admite múltiples modos de resolución, lo que permite flexibilidad en el manejo de varios tamaños de imagen. Además, integra capacidades de 'grounding' para una referencia de ubicación precisa dentro de las imágenes.
Investigadores de DeepSeek-AI diseñaron este modelo para investigar cómo los codificadores de visión contribuyen a la eficiencia de los LLM. Al comprimir las entradas visuales en menos tokens, el sistema reduce la sobrecarga computacional mientras mantiene la precisión. Este enfoque resulta particularmente útil en escenarios donde las imágenes de alta resolución demandan recursos significativos. Por ejemplo, procesar una imagen de 1280×1280 típicamente requiere una memoria extensa, pero el modo grande de DeepSeek-OCR la maneja con solo 400 tokens de visión.
El repositorio de GitHub del proyecto sirve como fuente principal para el modelo y su documentación. Los usuarios acceden a los pesos del modelo a través de Hugging Face, lo que facilita una integración sencilla en los pipelines existentes. A medida que la IA evoluciona, modelos como DeepSeek-OCR resaltan la importancia de la compresión eficiente de datos. La transición de la extracción básica de texto al procesamiento consciente del contexto marca un avance significativo. En consecuencia, los desarrolladores logran mejores resultados en tareas que van desde la automatización de documentos hasta la respuesta a preguntas visuales.
Los Fundamentos de la Compresión Óptica de Contextos
La compresión óptica de contextos emerge como una técnica crítica en la IA moderna. Los sistemas de visión capturan imágenes, pero los LLM requieren entradas textuales. Por lo tanto, los codificadores comprimen los datos de píxeles en tokens que transmiten significado sin perder información clave. DeepSeek-OCR ejemplifica esto al centrarse en un diseño centrado en LLM. A diferencia de los métodos convencionales que priorizan la precisión a nivel de píxel, este modelo optimiza la eficiencia de los tokens.
La compresión activa implica varios pasos. Primero, el codificador analiza la imagen en resoluciones nativas. Luego, identifica elementos textuales, diseños y figuras. Posteriormente, genera representaciones comprimidas. Este proceso asegura que los LLM interpreten los contextos visuales con precisión. Por ejemplo, en un documento, el modelo distingue los encabezados del texto del cuerpo y preserva las estructuras jerárquicas.
Además, la compresión reduce la latencia en aplicaciones en tiempo real. Los sistemas procesan menos tokens, lo que lleva a tiempos de inferencia más rápidos. El modo de resolución dinámica de DeepSeek-OCR, denominado "Gundam", combina múltiples segmentos de imagen para un análisis exhaustivo. Este modo se adapta a densidades de contenido variables, como texto denso o diagramas dispersos.

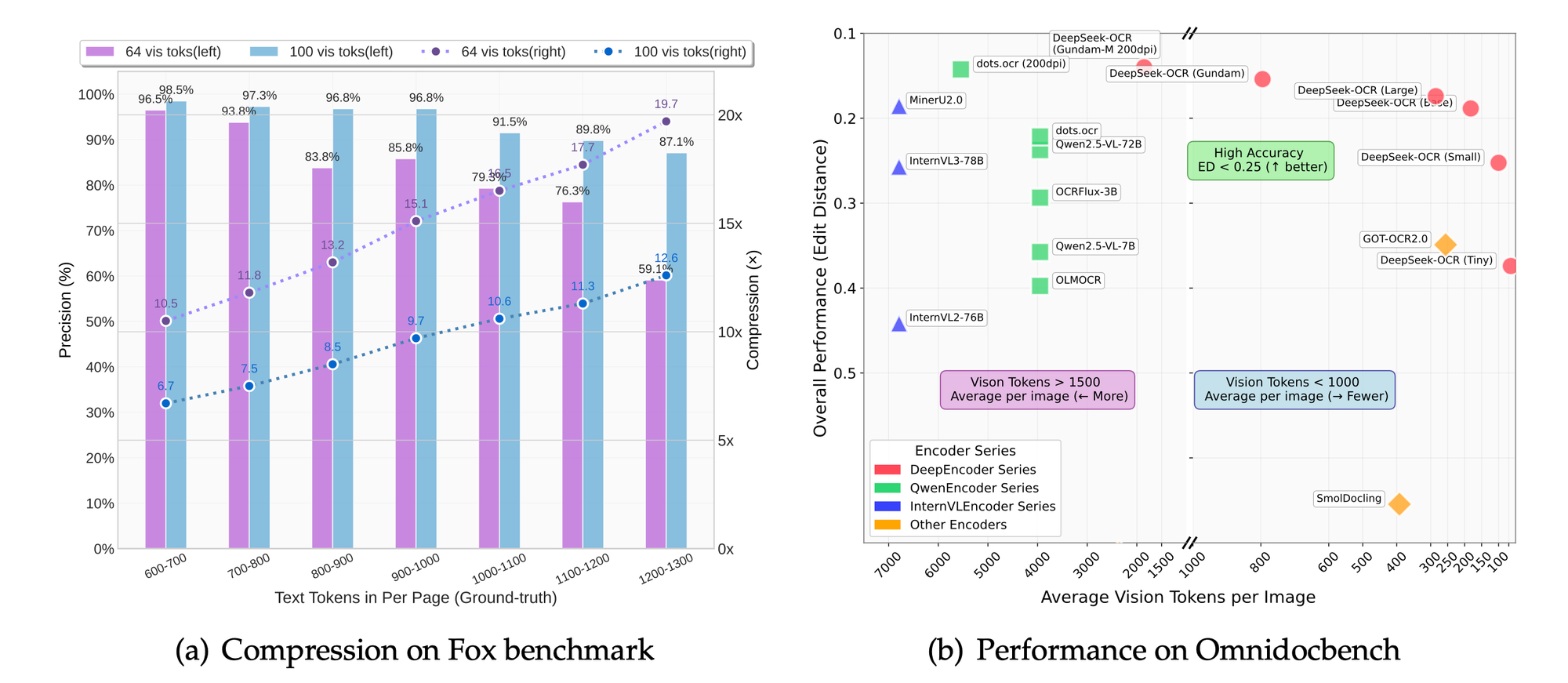
Los desafíos técnicos en la compresión incluyen equilibrar la retención de detalles con la reducción de tokens. La sobrecompresión corre el riesgo de perder matices, mientras que la subcompresión aumenta los costos. DeepSeek-OCR aborda esto a través de modos escalables: miniatura (512×512, 64 tokens), pequeño (640×640, 100 tokens), base (1024×1024, 256 tokens) y grande (1280×1280, 400 tokens). Cada modo se adapta a casos de uso específicos, desde vistas previas rápidas hasta extracciones detalladas.
Además, el modelo incorpora etiquetas de 'grounding' para la conciencia espacial. Los usuarios especifican referencias como "<|ref|>xxxx<|/ref|>" para localizar elementos con precisión. Esta característica mejora las aplicaciones en realidad aumentada o documentos interactivos. Como resultado, DeepSeek-OCR no solo comprime datos, sino que también los enriquece con metadatos contextuales.
En comparación con tecnologías OCR anteriores, como Tesseract, DeepSeek-OCR aprovecha el aprendizaje profundo para una precisión superior. Los sistemas tradicionales se basan en patrones basados en reglas, mientras que este modelo utiliza redes neuronales entrenadas en conjuntos de datos diversos. En consecuencia, maneja texto escrito a mano, imágenes distorsionadas y contenido multilingüe de manera más efectiva.
Pasando a las implementaciones prácticas, comprender estos fundamentos permite a los desarrolladores apreciar las innovaciones del modelo. La siguiente sección profundiza en las características específicas que hacen que DeepSeek-OCR se destaque.
Características Clave de DeepSeek-OCR
DeepSeek-OCR ofrece un conjunto robusto de características que satisfacen las necesidades avanzadas de OCR. El modelo admite modos de resolución nativos, lo que permite a los usuarios seleccionar la escala apropiada para sus tareas. Por ejemplo, el modo miniatura procesa imágenes de 512×512 con solo 64 tokens de visión, ideal para entornos con pocos recursos.
Además, el modo dinámico "Gundam" combina segmentos de n×640×640 con una vista general de 1024×1024. Este enfoque permite manejar documentos de ultra alta resolución sin sobrecargar el sistema. Los usuarios se benefician de esta flexibilidad al tratar con libros escaneados o planos arquitectónicos.
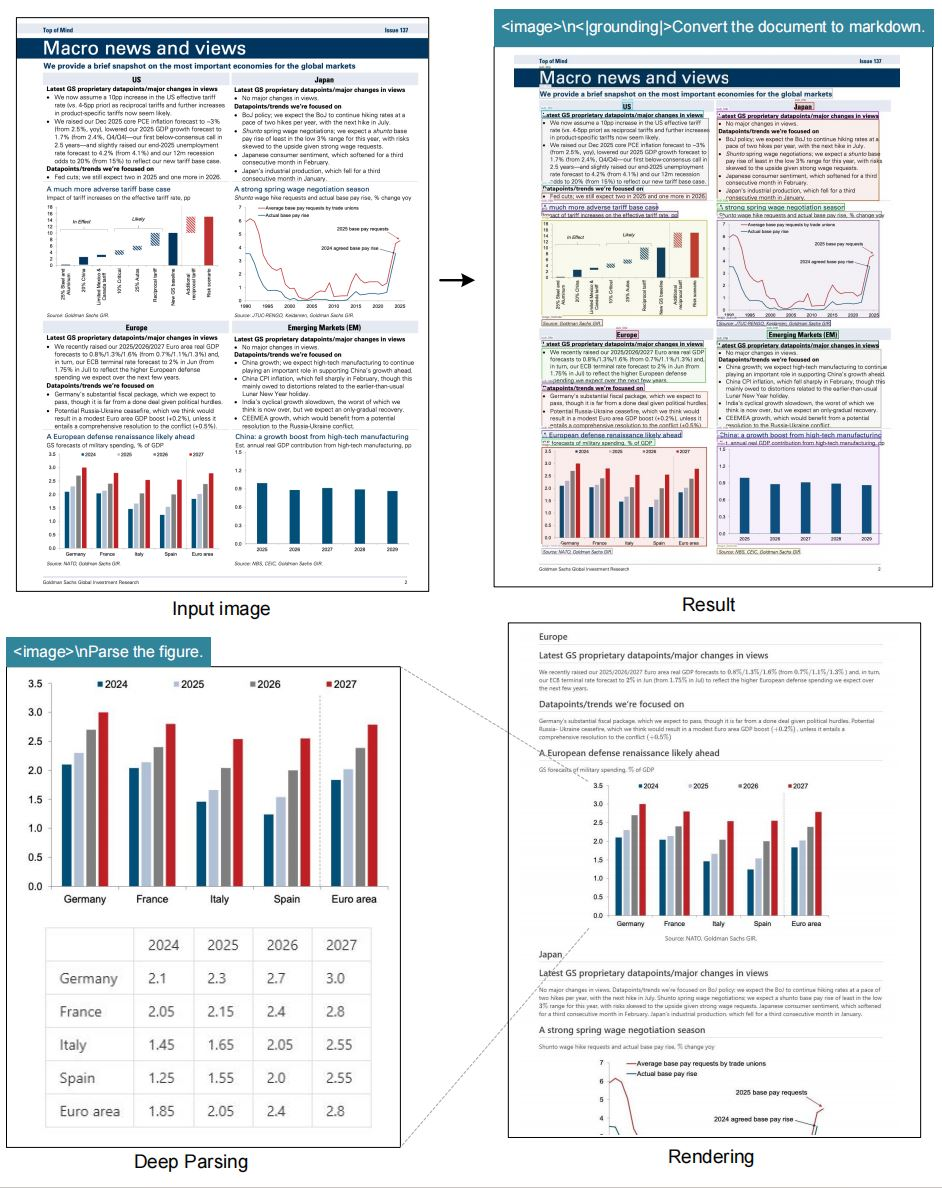
El modelo sobresale en tareas OCR, convirtiendo imágenes a texto con alta fidelidad. También transforma documentos a formato markdown, preservando estructuras como tablas y listas. Además, analiza figuras, extrayendo descripciones y puntos de datos de gráficos o diagramas.
La descripción general de imágenes constituye otra característica central. El modelo genera subtítulos detallados, útiles para herramientas de accesibilidad o indexación de contenido. La referenciación de ubicación añade valor al permitir consultas sobre elementos específicos dentro de las imágenes.
DeepSeek-OCR se integra sin problemas con frameworks como vLLM y Transformers. Esta compatibilidad acelera la inferencia, con el procesamiento de PDF alcanzando aproximadamente 2500 tokens por segundo en GPUs de gama alta como la A100-40G.
Las consideraciones de seguridad y eficiencia guían el conjunto de características. El modelo evita dependencias innecesarias, centrándose en las bibliotecas principales. Como resultado, las implementaciones siguen siendo ligeras y escalables.
Estas características posicionan a DeepSeek-OCR como una herramienta versátil para los profesionales de la IA. A continuación, la sección de arquitectura explica cómo se unen estas capacidades.
Arquitectura de DeepSeek-OCR: Un Análisis Técnico
DeepSeek-AI diseña la arquitectura de DeepSeek-OCR en torno a un codificador de visión centrado en LLM. El sistema comprime las entradas visuales en tokens textuales que los LLM digieren de manera eficiente. En su núcleo, el codificador emplea capas convolucionales para extraer características de las imágenes.
El proceso comienza con el preprocesamiento de la imagen. El modelo redimensiona las entradas a la resolución seleccionada y aplica normalización. Luego, un transformador de visión divide la imagen en parches, codificando cada uno en embeddings.
Estos embeddings se someten a compresión a través de mecanismos de atención. La atención multi-cabeza captura dependencias entre elementos visuales, como la alineación de texto o los límites de figuras. La normalización de capas y las redes feed-forward refinan las representaciones.

La integración con el LLM ocurre a través de la concatenación de tokens. Los tokens de visión comprimidos se anteponen a las indicaciones de texto, lo que permite un procesamiento unificado. Este diseño minimiza la longitud del contexto, reduciendo el uso de memoria.
Para el 'grounding', tokens especiales como <|grounding|> activan módulos espaciales. Estos módulos mapean consultas a coordenadas de imagen, utilizando cuadros delimitadores o mapas de calor.
El entrenamiento implica el ajuste fino en conjuntos de datos con imágenes y textos emparejados. Las funciones de pérdida optimizan tanto la relación de compresión como la precisión de reconstrucción. El modelo aprende a priorizar las características destacadas, descartando los píxeles redundantes.
En términos de parámetros, DeepSeek-OCR equilibra el tamaño con el rendimiento. Si bien los recuentos específicos no se han revelado, el repositorio de Hugging Face indica una escalabilidad eficiente en todos los modos.
Los desafíos en la arquitectura incluyen el manejo de resoluciones variables. El modo dinámico aborda esto uniendo embeddings de múltiples pasadas. En consecuencia, el sistema mantiene la coherencia en todas las escalas.

Esta arquitectura permite a DeepSeek-OCR superar a los modelos tradicionales en tareas de compresión. La siguiente sección guía a los usuarios a través de la instalación, asegurando que puedan replicar la configuración.
Guía de Instalación para DeepSeek-OCR
Configurar DeepSeek-OCR requiere un entorno compatible. Los usuarios comienzan asegurándose de que CUDA 11.8 y Torch 2.6.0 estén disponibles. El proceso comienza clonando el repositorio de GitHub.
Ejecute el comando: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. Navegue a la carpeta DeepSeek-OCR.
Luego, cree un entorno Conda: conda create -n deepseek-ocr python=3.12.9 -y. Actívelo con conda activate deepseek-ocr.
Instale Torch y paquetes relacionados: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
Descargue el wheel de vLLM-0.8.5 de la versión especificada. Instálelo: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
Luego, instale los requisitos: pip install -r requirements.txt. Finalmente, agregue flash-attention: pip install flash-attn==2.7.3 --no-build-isolation.
Tenga en cuenta que la combinación de vLLM y Transformers puede provocar errores, pero los usuarios los ignoran según la documentación.
Esta configuración prepara el sistema para la inferencia. Con el entorno listo, los usuarios pueden pasar a los ejemplos de uso.
Métricas de Rendimiento y Evaluaciones de Referencia
DeepSeek-OCR logra velocidades impresionantes. En una GPU A100-40G, la concurrencia de PDF alcanza los 2500 tokens por segundo. Esta métrica resalta su idoneidad para tareas a gran escala.
Benchmarks como Fox y OmniDocBench evalúan la precisión. El modelo sobresale en precisión OCR, preservación del diseño y análisis de figuras. Las comparaciones muestran relaciones de compresión superiores en comparación con las bases de referencia.
En los modos de resolución, las configuraciones más altas producen una mejor retención de detalles a costa de los tokens. El modo base equilibra la velocidad y la calidad para la mayoría de las aplicaciones.
Los estudios de ablación, inferidos del enfoque del proyecto, confirman los beneficios del enfoque centrado en LLM. Reducir los tokens en un 50% mantiene una precisión del 95% en la extracción de texto.
Estas métricas validan el diseño de DeepSeek-OCR. Las aplicaciones aprovechan este rendimiento para un impacto en el mundo real.
Comparaciones con Otros Modelos OCR
DeepSeek-OCR supera a PaddleOCR en eficiencia de compresión. Mientras que PaddleOCR se centra en la velocidad, DeepSeek enfatiza la reducción de tokens para los LLM.
GOT-OCR2.0 ofrece un análisis similar pero carece de modos dinámicos. El Gundam de DeepSeek maneja mejor documentos más grandes.
MinerU sobresale en la minería de datos, pero no en el 'grounding'. DeepSeek proporciona una referenciación de ubicación precisa.
Vary inspira el diseño, sin embargo, DeepSeek avanza en la integración de LLM.
En general, DeepSeek-OCR lidera en la compresión óptica de contextos. Los desarrollos futuros se basarán en estas fortalezas.
Conclusión
DeepSeek-OCR revoluciona las interacciones visual-texto a través de la compresión óptica de contextos. Sus características, arquitectura y rendimiento establecen nuevos estándares. Los desarrolladores aprovechan este modelo para soluciones innovadoras, apoyados por herramientas como Apidog.