
Como herramienta colaborativa para el diseño, documentación, depuración, simulación y prueba de API, Apidog cuenta con una característica muy elogiada: la compatibilidad con operaciones de base de datos al enviar/recibir solicitudes. Esta característica facilita enormemente a los usuarios que necesitan preparar datos de solicitud al llamar a un endpoint o insertar datos en una base de datos al recibir una respuesta, lo que la convierte en una de las favoritas entre los usuarios.
Sin embargo, dado que muchos usuarios hacen un uso extensivo de esta función a diario, se han identificado algunas áreas de mejora. Uno de los puntos más frecuentes es:
¿Puede el administrador del equipo configurar la conexión a la base de datos para que luego la utilicen de forma colaborativa otros miembros del equipo? Es realmente problemático que todos tengan que volver a introducir los detalles de la conexión.
Desde el diseño inicial de esta característica, ya habíamos considerado si permitir que las configuraciones de la base de datos se utilizaran de forma colaborativa. Sin embargo, permitir a los usuarios guardar información sensible como nombres de usuario y contraseñas de bases de datos en un servidor en la nube es un asunto que requiere una cuidadosa consideración. Por lo tanto, la seguridad de los datos fue la razón principal por la que el uso colaborativo de las configuraciones de conexión a la base de datos no se implementó en ese momento.
Hoy en día, Apidog se ha convertido en la principal herramienta de colaboración y gestión de API para millones de desarrolladores, y las capacidades fundamentales de Apidog se han vuelto más potentes. Por lo tanto, hemos reconsiderado este requisito de optimización para el uso colaborativo de las configuraciones de conexión a la base de datos, esforzándonos por equilibrar la seguridad de los datos y la eficiencia del desarrollo para satisfacer a nuestros usuarios.
Almacenamiento de configuraciones de conexión a la base de datos en la nube
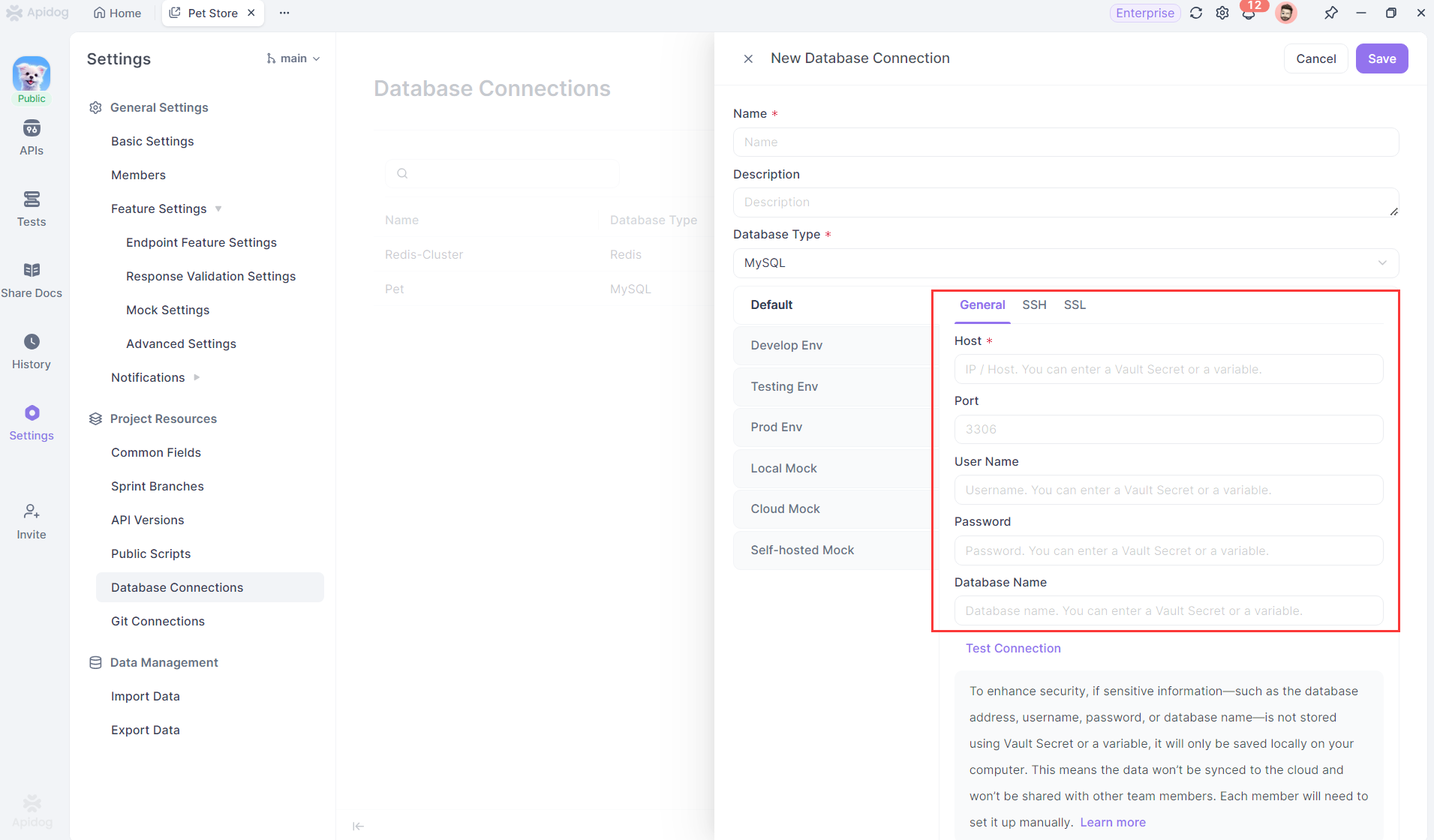
Paso 1: Crear nueva conexión a la base de datos
Cuando su versión de Apidog se actualice a 2.6.50 o superior, vaya a "Configuración del proyecto -> Conexión a la base de datos" y haga clic para crear una nueva conexión a la base de datos. Encontrará que todos los campos de conexión le guían para usar variables para rellenar los valores de los campos.
Paso 2: Configurar variables en diferentes entornos
En la gestión de entornos, configure variables para las conexiones a la base de datos que se utilizarán en diferentes entornos. De esta manera, estas variables se pueden aplicar en las configuraciones de conexión a la base de datos.
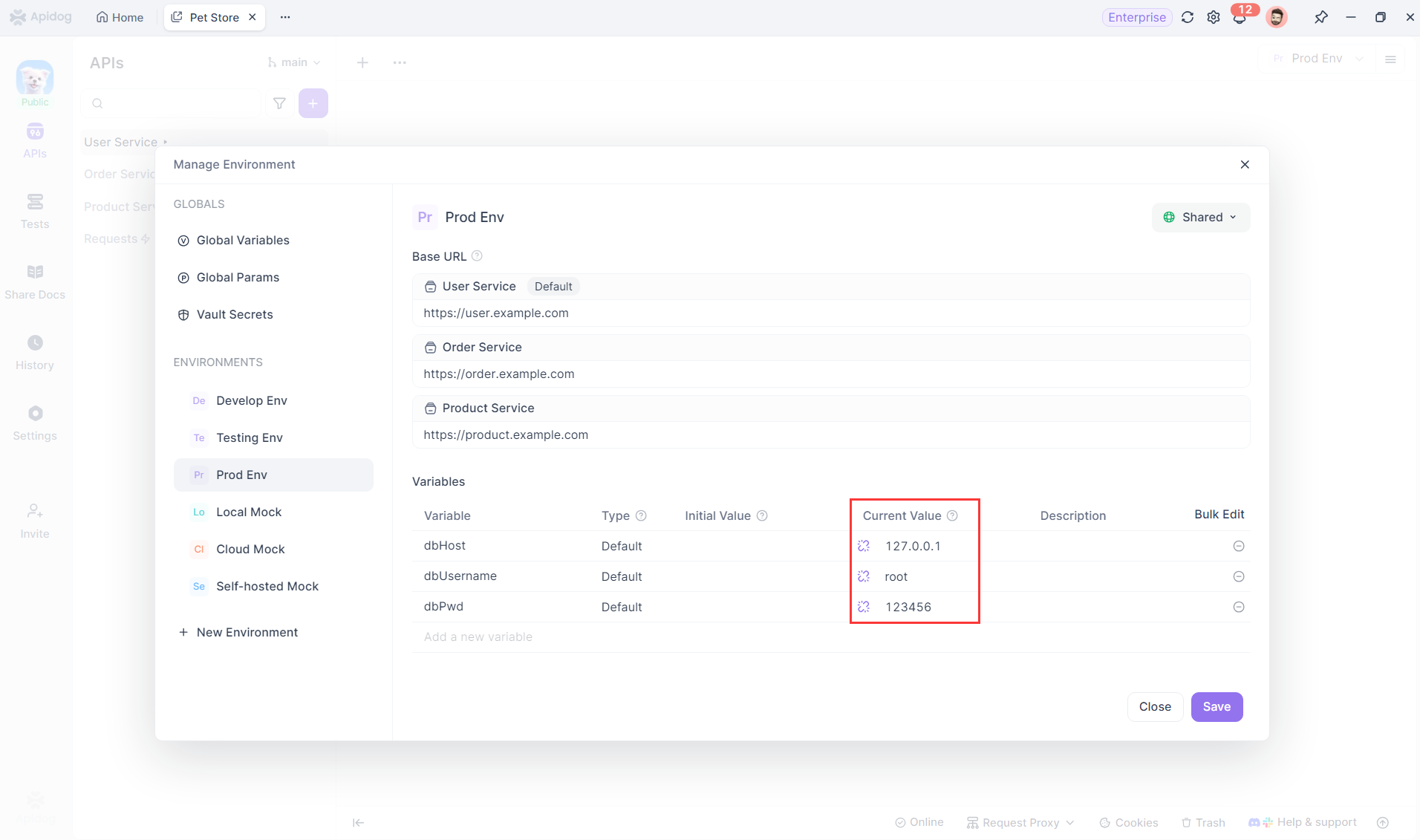
Paso 3: Configurar conexiones a la base de datos usando variables
De vuelta a la página de configuración de la conexión a la base de datos, puede rellenar manualmente las variables usando el formato de variable, o referenciar directamente estas variables a través de la función de valor dinámico. Recomendamos usar variables de entorno aquí para que la configuración cambie automáticamente con el contexto de diferentes entornos. Excepto el número de puerto, es mejor rellenar todos los demás campos usando variables.
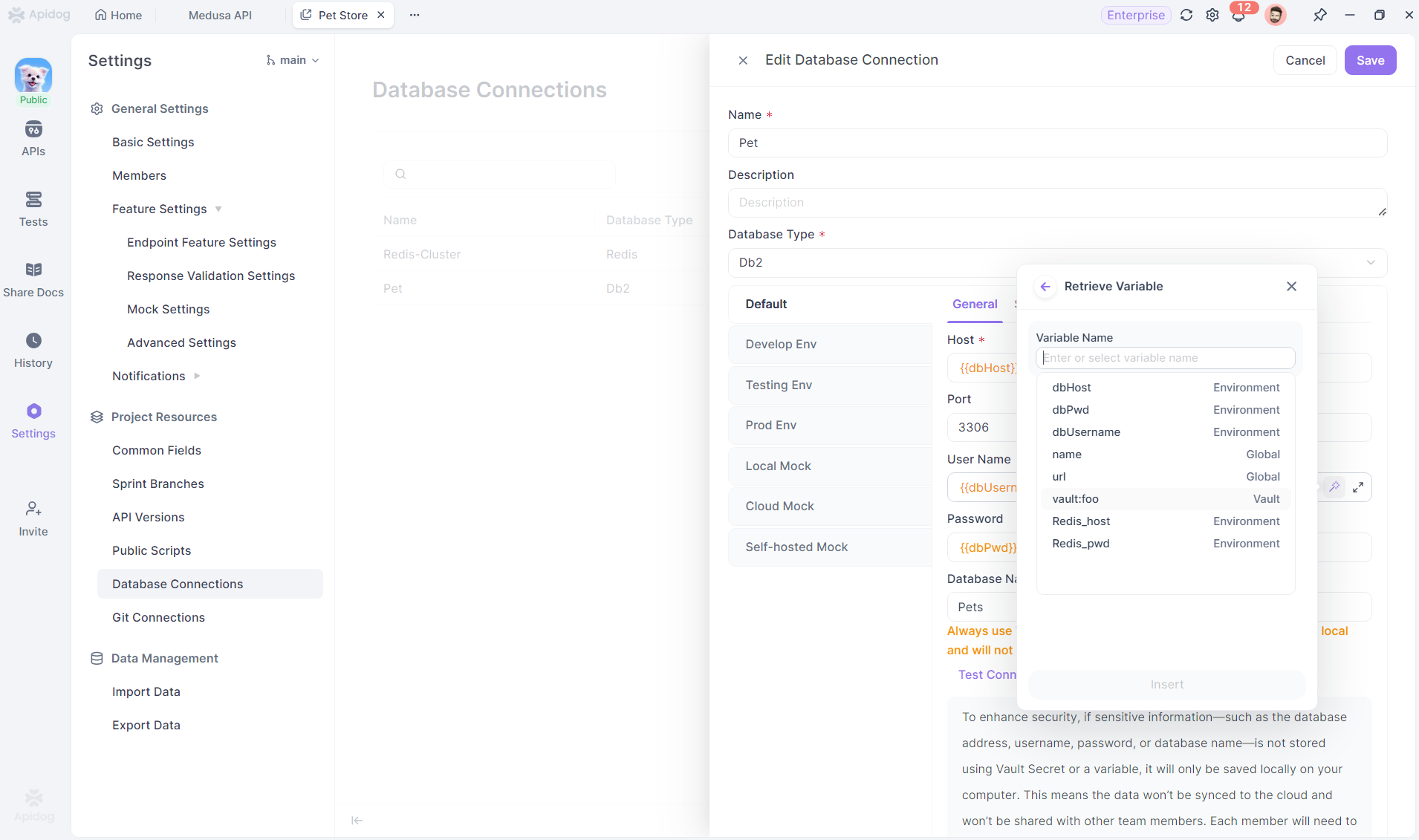
Paso 4: Guardar y usar conexiones a la base de datos
Guarde la configuración de conexión a la base de datos que utiliza variables, y podrá utilizarse en operaciones de base de datos en la gestión de API, pruebas automatizadas y otras áreas.
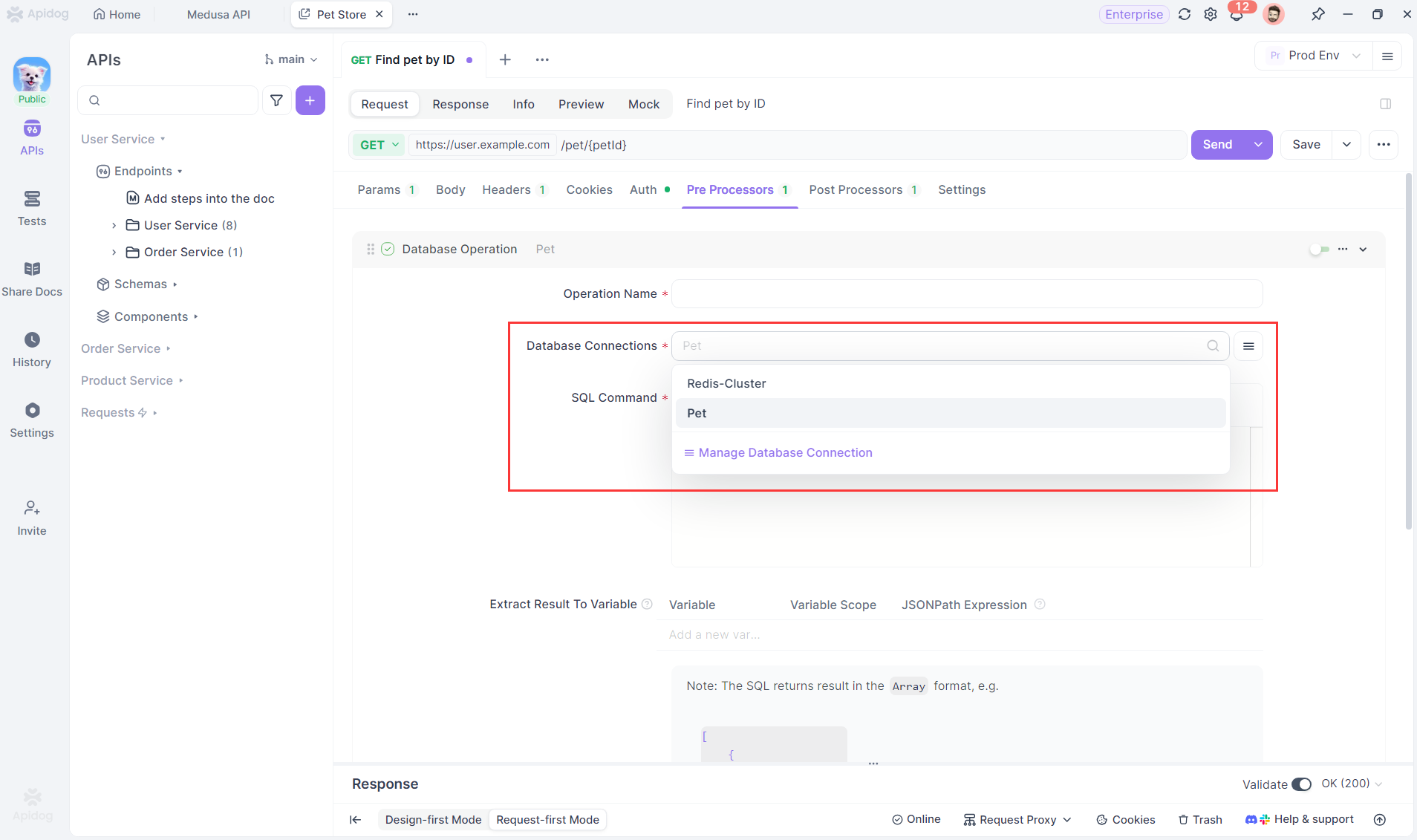
Cuando se utilizan, el mecanismo de uso real para las configuraciones de conexión a la base de datos guardadas localmente frente a las guardadas en la nube es el siguiente:
| Configuración guardada localmente (sin usar variables) | Configuración guardada en la nube (usando variables) |
| 1. Cuando una solicitud de endpoint activa una operación de base de datos, se lee la configuración de base de datos especificada. | 1. Cuando una solicitud de endpoint activa una operación de base de datos, se lee la configuración de base de datos especificada. |
| 2. El sistema lee los detalles de la configuración de un archivo local, usando los valores reales directamente. | 2. La configuración se obtiene de la nube y contiene variables. El sistema resuelve estas variables basándose en sus nombres y prioridad. |
| 3. Estos valores (por ejemplo, host, nombre de usuario, contraseña) se utilizan para construir una conexión completa a la base de datos e iniciar la conexión. | 3. Las variables se reemplazan con sus valores reales para formar una configuración de conexión a la base de datos completa, y se inicia la conexión. |
| 4. Una vez que la conexión es exitosa, las sentencias SQL definidas en la operación de base de datos se ejecutan, junto con cualquier operación como guardar resultados en variables. | 4. Una vez que la conexión es exitosa, las sentencias SQL definidas en la operación de base de datos se ejecutan, junto con cualquier operación como guardar resultados en variables. |
CONSEJO PROFESIONAL: Para otros miembros del proyecto que necesiten usar esta configuración de conexión a la base de datos, ahora solo necesitan ir a la gestión de entornos, encontrar las variables correspondientes y rellenar los valores locales, sin tener que configurar en la gestión del proyecto como antes.
Estos son los pasos detallados para configurar conexiones a bases de datos en la nube. Dado que se recomienda usar valores locales y la configuración real se sigue almacenando localmente, no hay necesidad de preocuparse por los riesgos de seguridad de los datos. Las variables simplemente hacen el proceso más conveniente y manejable.
Apidog también sigue admitiendo la introducción directa de valores reales en la configuración de la conexión a la base de datos. Esto garantiza la compatibilidad con las configuraciones existentes y es compatible con los usuarios que prefieren trabajar con datos locales. Sin embargo, se mostrará un recordatorio claro, animando a los usuarios a cambiar a variables y guardarlas en la nube para una experiencia mejor y más optimizada.
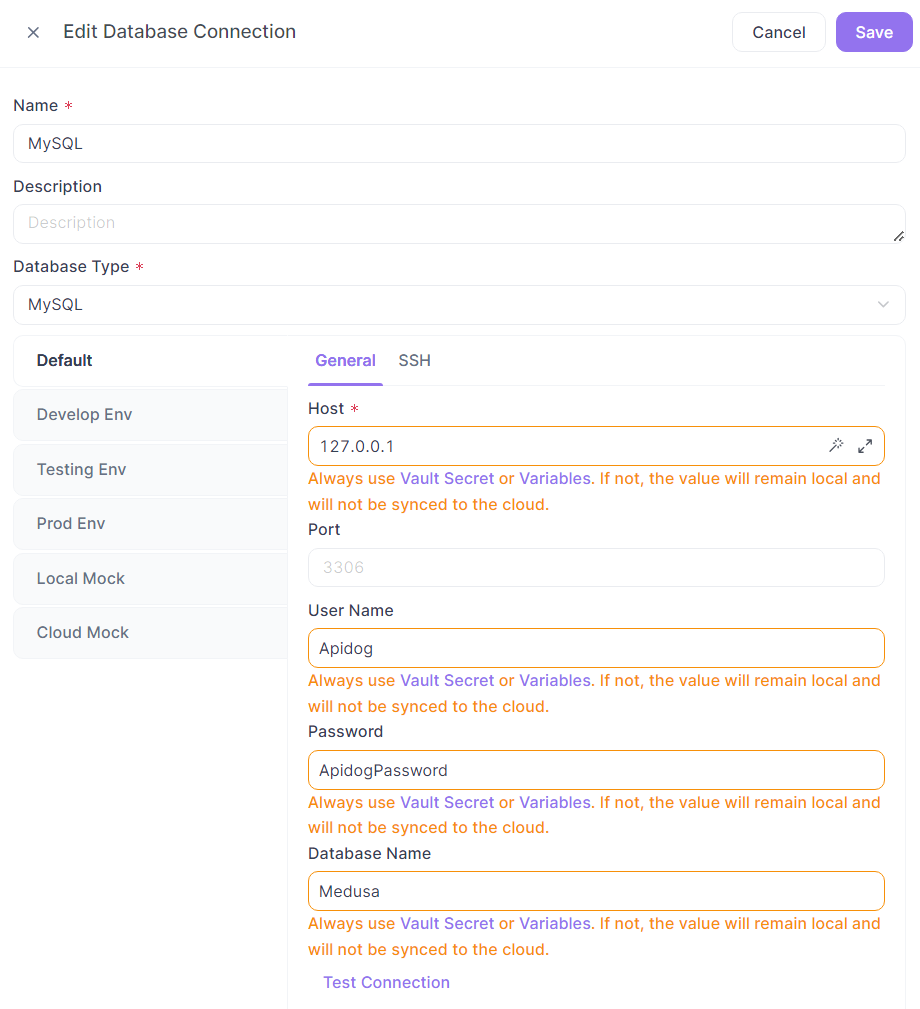
Precauciones para el uso de conexiones a bases de datos en la nube:
En las configuraciones de conexión a la base de datos, cuando se utilizan variables, lo que realmente se guarda en la nube es el nombre de la variable. Al ejecutar las conexiones a la base de datos, la configuración de conexión completa se ensamblará de acuerdo con las reglas de uso de variables para iniciar la conexión.
✅ Acciones recomendadas:
- Use "Valor actual" o "Variable de Vault" para los valores de las variables.
- El número de puerto se puede introducir directamente, no es necesario usar una variable, por comodidad y sin riesgo.
❌ Acciones no recomendadas:
- Usar "Valor inicial" para los valores de las variables.
- Mezclar texto plano y variables, lo que aún requiere que todos configuren por separado en la configuración del proyecto.
Uso de variables de Vault para guardar configuraciones de conexión a la base de datos
Para la configuración de la conexión a la base de datos, recomendamos usar variables de Vault. Estas variables se obtienen de un servicio externo de gestión de secretos y se almacenan de forma cifrada en su máquina local. Este enfoque ofrece lo mejor de ambos mundos: protección segura de datos y colaboración eficiente en equipo a través del almacenamiento en la nube.
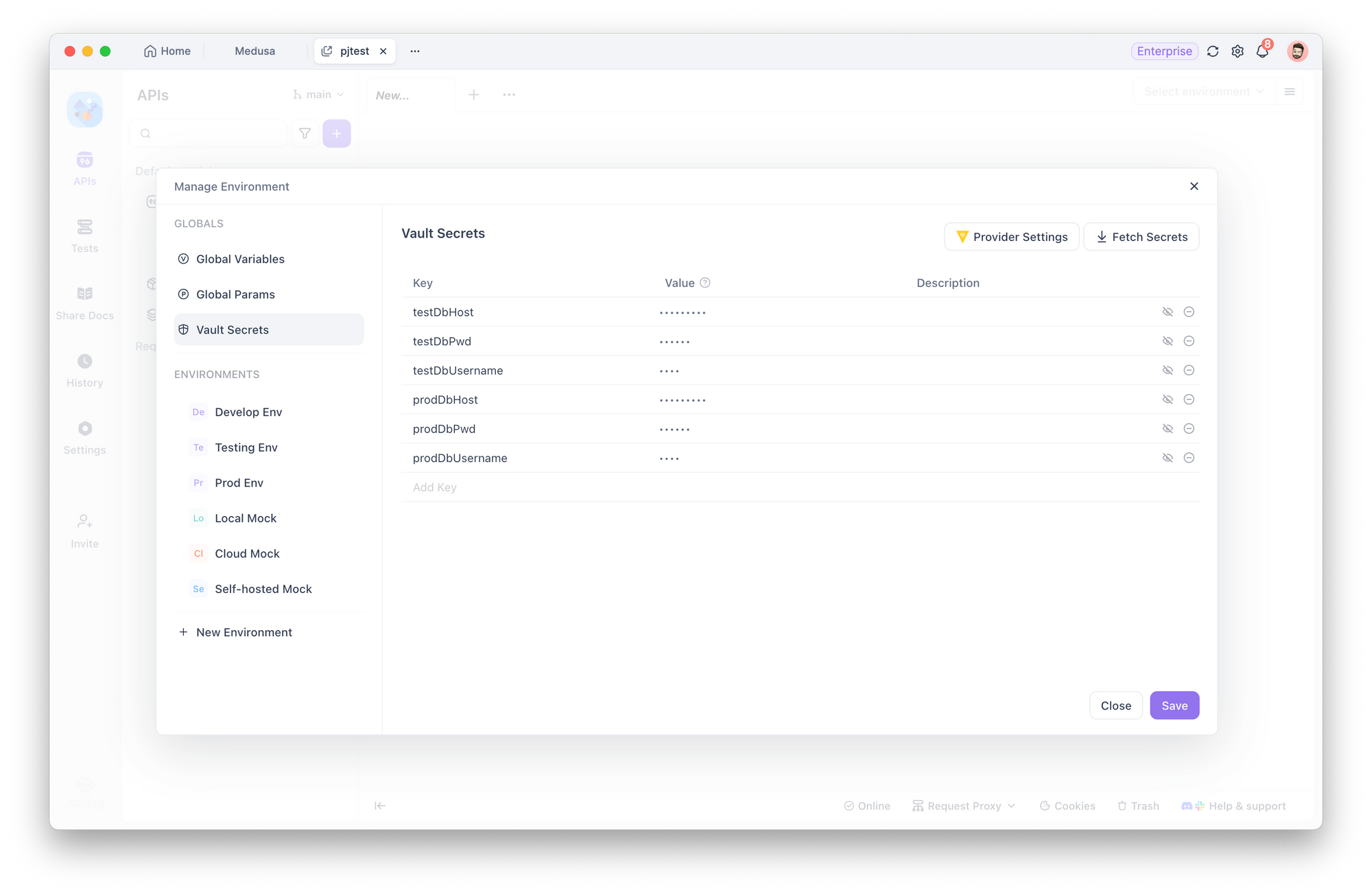
Paso 1: Configurar variables de Vault
Configure un proveedor de Vault y almacene en él el texto plano de las credenciales de conexión a la base de datos. Para las configuraciones de conexión a la base de datos en diferentes entornos, deberá crear diferentes claves de Vault en su proveedor. Para métodos específicos, consulte la documentación de ayuda.
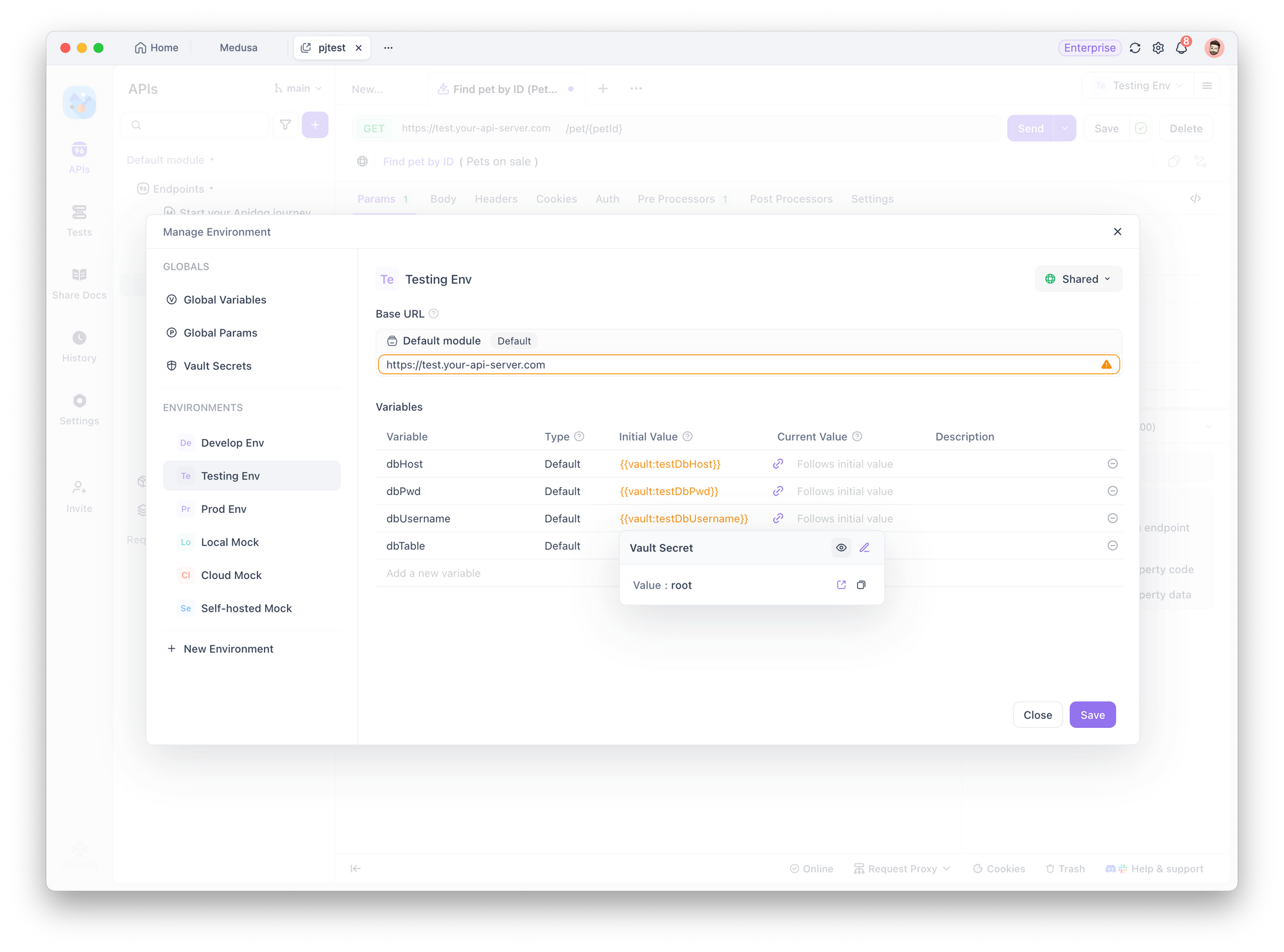
Paso 2: Crear variables de entorno
Para cada entorno, cree variables de entorno con el mismo nombre, como dbHost. Luego, establezca el Valor inicial para que haga referencia a la variable de Vault apropiada para ese entorno, y deje que el Valor actual siga al inicial.
¿Por qué hacer esto?
- Envuelve la variable de Vault en una variable de entorno. Así, cuando configure la conexión a la base de datos más tarde, solo tendrá que seleccionar la variable de entorno. Apidog utilizará automáticamente el valor correcto según el entorno actual.
- Almacenar los datos en un valor inicial asegura que todos los miembros del proyecto puedan usarlo sin tener que configurarlo manualmente de nuevo, lo que aumenta la eficiencia del equipo.
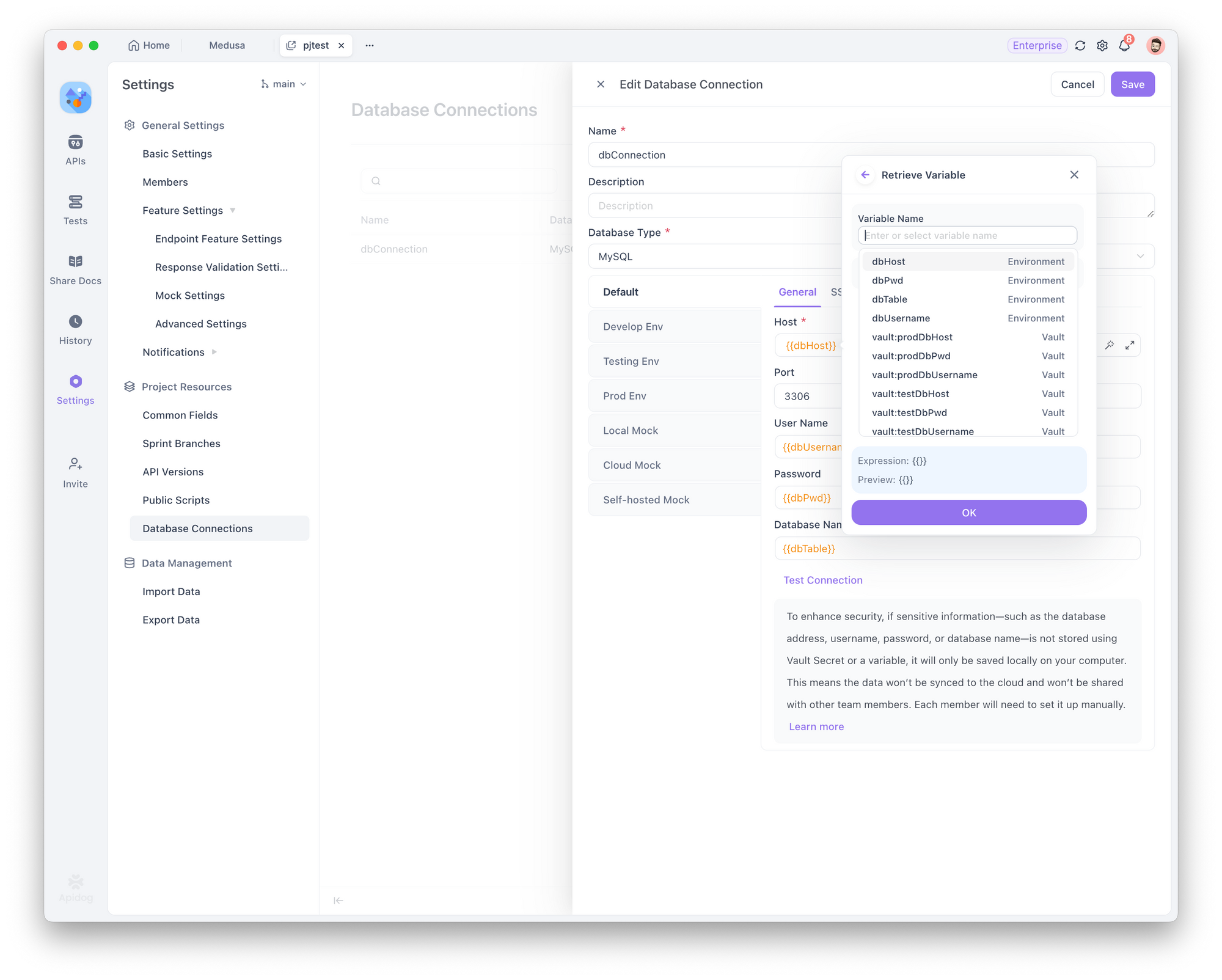
Paso 3: Configurar conexiones a la base de datos usando un secreto de Vault
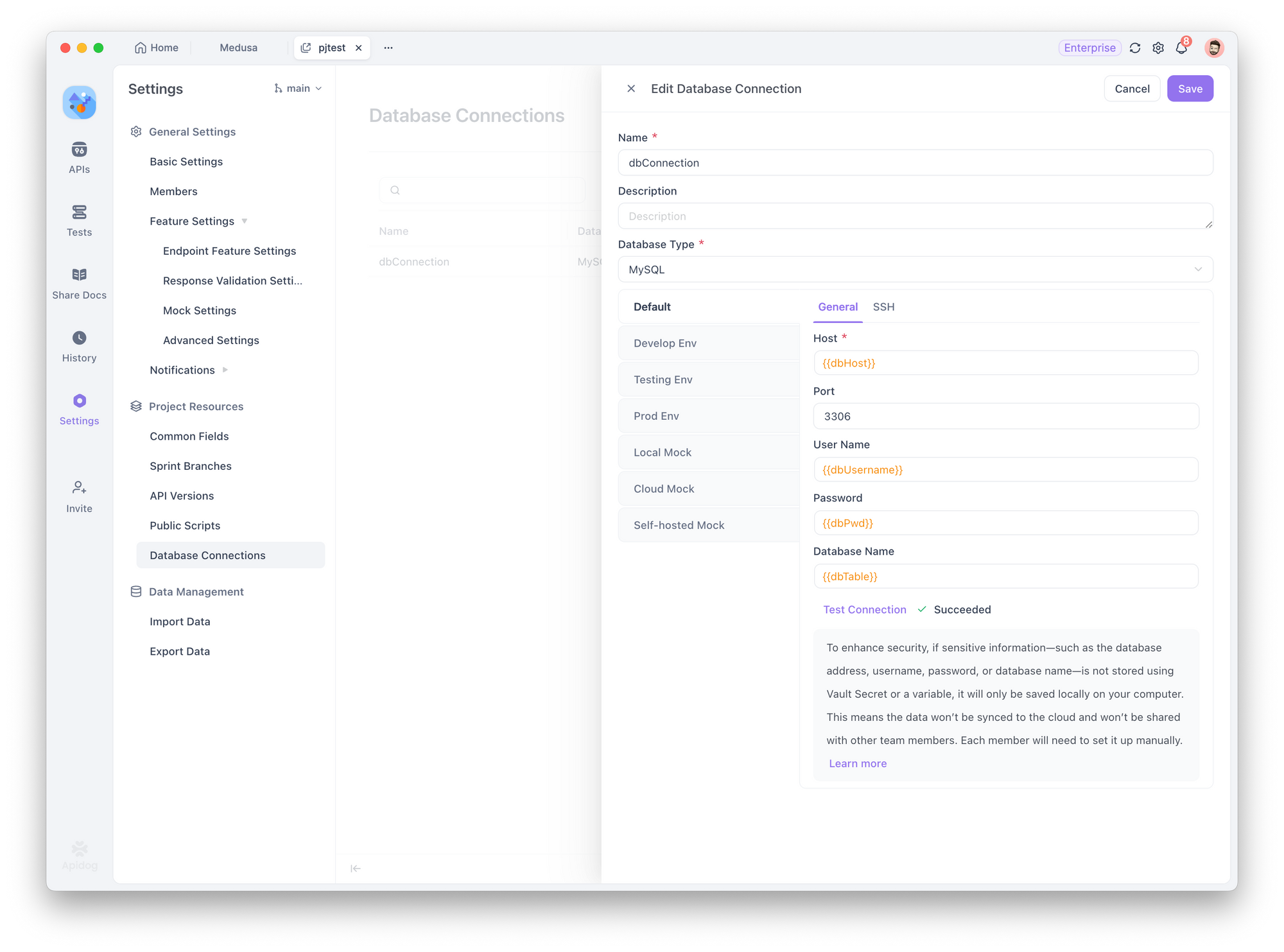
Al configurar una conexión a la base de datos, utilice las variables de entorno que ha definido en Gestión de entorno (por ejemplo, dbHost, dbUser, dbPassword). Para referenciar estas variables rápidamente, utilice la función de valor dinámico.
Paso 4: Probar la conexión a la base de datos
Haga clic en "Probar conexión". Se le pedirá que elija un entorno para la prueba.
- Asegúrese de que las variables utilizadas en la conexión (como host, puerto, nombre de usuario, etc.) estén configuradas correctamente para ese entorno. Una vez confirmado, el sistema probará la conexión:
- ✅ Si es exitoso, todo está listo.
- ❌ Si falla, revise el mensaje de error para conocer los pasos específicos de solución de problemas.
Paso 5: Usar operaciones de base de datos en solicitudes de endpoint
En los Pre Processors o Post Processors de una solicitud de endpoint, puede añadir una operación de base de datos utilizando la configuración de base de datos en la nube guardada.
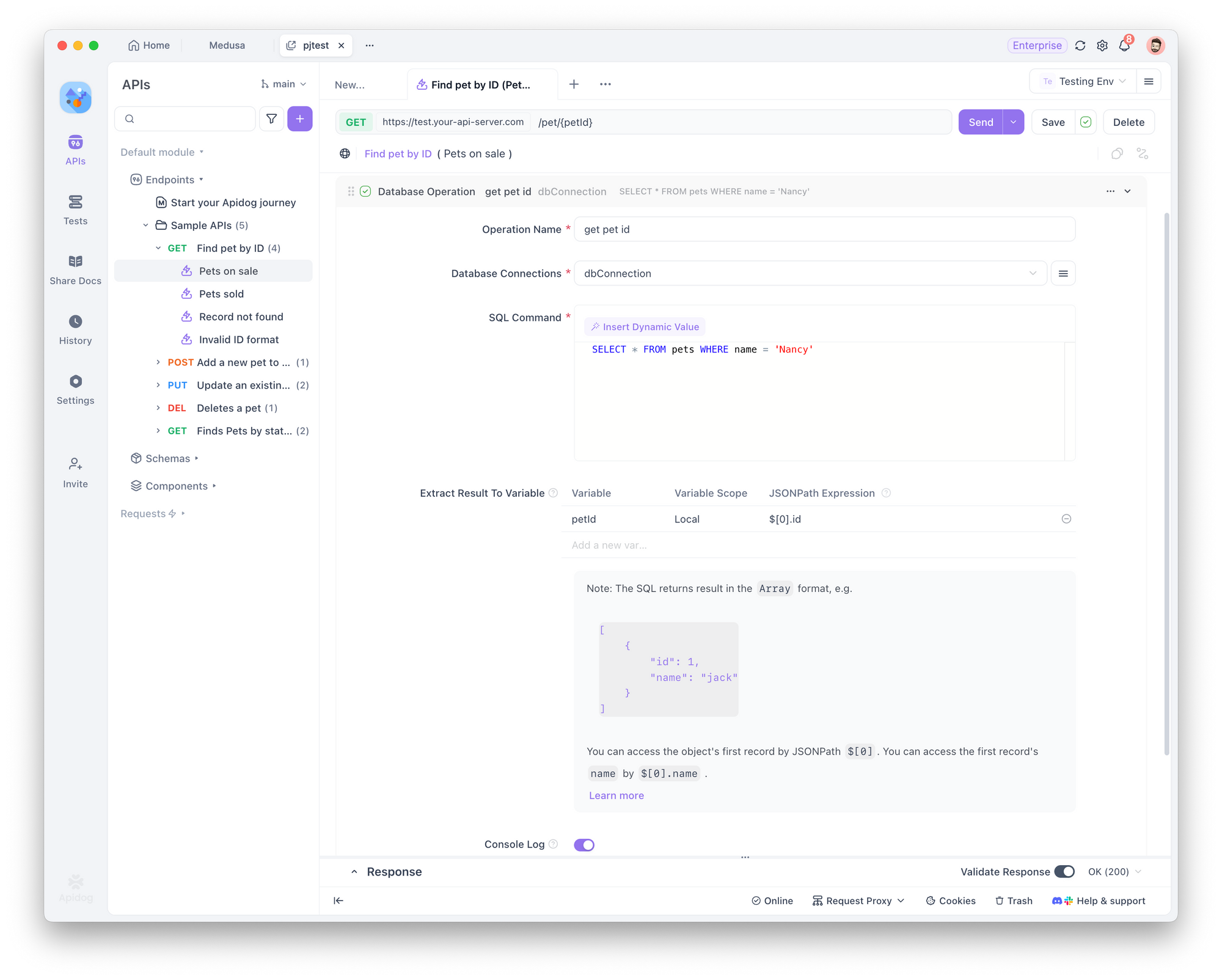
Ejemplo:
Supongamos que desea:
- Buscar el
idde una mascota llamada "Nancy" en la base de datos. - Usar ese ID para obtener información detallada a través de una solicitud de endpoint.
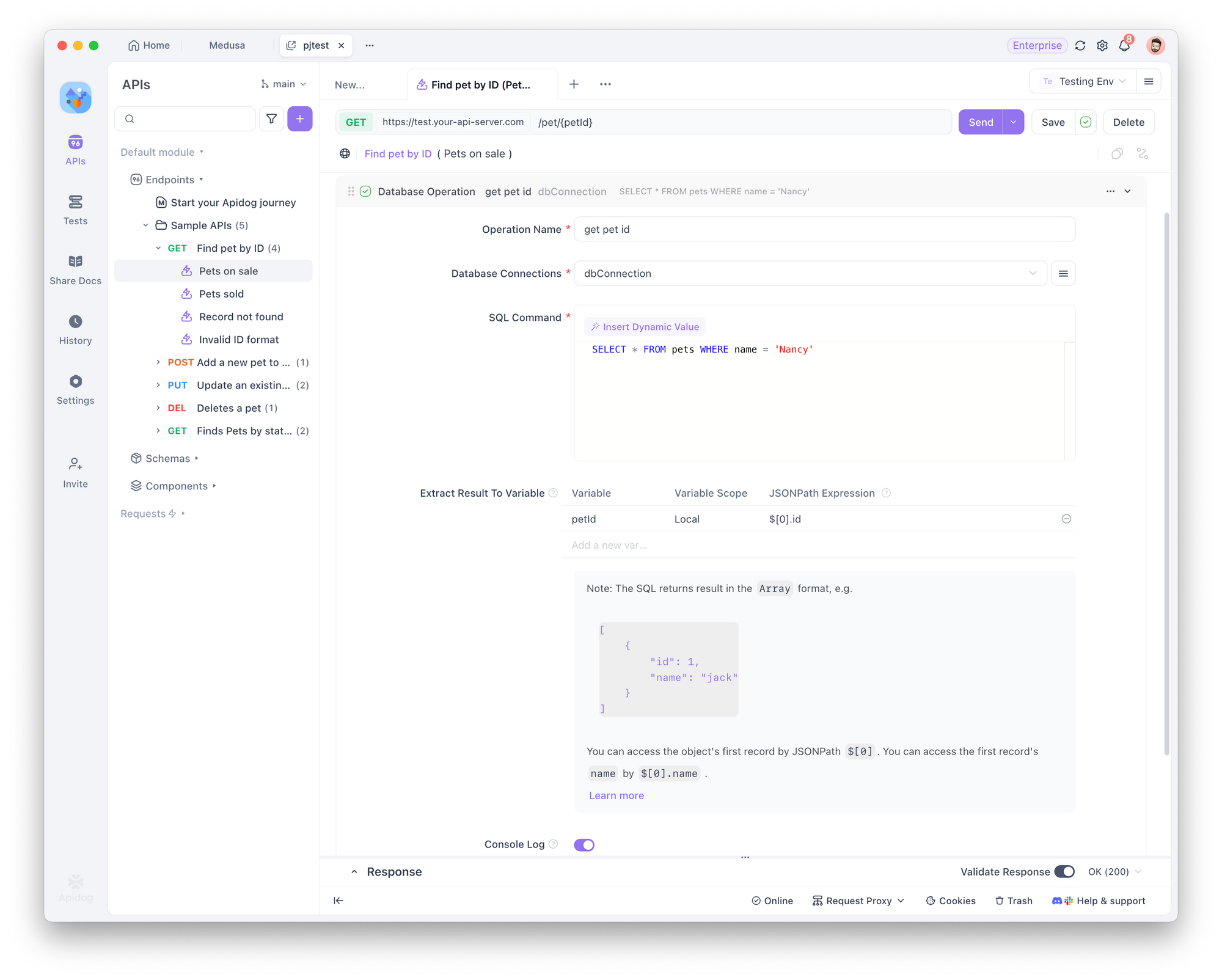
Apidog entonces:
- Ejecutará la operación de base de datos
- Obtendrá el valor (por ejemplo,
petID) - Lo guardará como una variable (por ejemplo,
petId) - Usará esa variable en la solicitud de endpoint
Una vez que la configuración de la base de datos esté configurada en la nube como se describió anteriormente:
- Otros miembros del equipo pueden reutilizarla en sus propias operaciones de base de datos.
- No es necesario que cada persona la configure manualmente.
- Ahorra tiempo y asegura la consistencia en todo su proyecto.
Conclusión final
La práctica anterior muestra cómo usar variables de Vault para almacenar y aplicar de forma segura las configuraciones de conexión a la base de datos. Aquí hay un resumen rápido de los pasos:
- Cree variables de Vault separadas para cada configuración de base de datos en diferentes entornos (por ejemplo,
testDBHostpara pruebas,prodDBHostpara producción). Puede omitir el puerto, ya que suele ser el mismo. - Defina variables de entorno con el mismo nombre en todos los entornos. Para cada entorno, establezca el valor inicial de la variable de entorno para que haga referencia a su variable de Vault correspondiente.
La siguiente tabla ilustra cómo configurar estas variables de entorno tanto para pruebas como para producción. Puede establecer el valor actual para que coincida con el valor inicial.
| Entorno | Nombre de la variable de entorno | Valor inicial | Descripción |
| Entorno de prueba | dbHost | {{vault:testDbHost}} | Hace referencia a la variable de Vault para la dirección de la base de datos en el entorno de prueba |
| dbUsername | {{vault:testDbUsername}} | Hace referencia a la variable de Vault para el nombre de usuario de la base de datos en el entorno de prueba | |
| dbPwd | {{vault:testDbPwd}} | Hace referencia a la variable de Vault para la contraseña de la base de datos en el entorno de prueba | |
| dbTable | store | No hay preocupaciones de seguridad de datos, por lo que se introduce directamente. La variable de Vault es opcional | |
| Entorno de producción | dbHost | {{vault:prodDbHost}} | Hace referencia a la variable de Vault para la dirección de la base de datos en el entorno de producción |
| dbUsername | {{vault:prodDbUsername}} | Hace referencia a la variable de Vault para el nombre de usuario de la base de datos en el entorno de producción | |
| dbPwd | {{vault:prodDbPwd}} | Hace referencia a la variable de Vault para la contraseña de la base de datos en el entorno de producción | |
| dbTable | store | No hay preocupaciones de seguridad de datos, por lo que se introduce directamente. La variable de Vault es opcional |