
Ese momento de fluidez, cuando estás inmerso en una sesión de depuración con tu herramienta de IA favorita, solo para encontrarte con un muro invisible que dice: "¡Alto, más despacio, has alcanzado tu límite!"? Si trabajas con **Codex**, el asistente de codificación de OpenAI, esa frustración podría resultarte demasiado familiar. Los **límites de uso de Codex** son un tema candente en este momento, especialmente a medida que más desarrolladores lo utilizan para todo, desde fragmentos de código rápidos hasta la creación completa de aplicaciones. ¿La respuesta corta? Sí, hay **cuotas** y **límites de tasa**, pero no son universales: dependen de tu plan, la complejidad de la tarea e incluso de cómo accedas a él. En esta guía, desglosaremos los detalles de los límites de **Codex**, analizaremos los niveles de precios, exploraremos soluciones alternativas con claves API y echaremos un vistazo a lo que la comunidad de desarrolladores en Reddit y GitHub se queja (y cómo lo están solucionando). Al final, sabrás exactamente cómo mantener tus sesiones de **Codex** fluyendo sin esos infartos a mitad de prompt. ¡Desmitifiquemos esto y volvamos a construir!
¿Quieres una plataforma integrada y todo en uno para que tu equipo de desarrolladores trabaje con máxima productividad?
¡Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!
Comprendiendo los Límites de Uso de Codex: Lo Básico
Primero, aclaremos el panorama: **Codex** viene con salvaguardas incorporadas para mantener las cosas justas y sostenibles. Estos no son obstáculos arbitrarios; están diseñados para gestionar los recursos computacionales de OpenAI mientras previenen el abuso. A partir de septiembre de 2025, los **límites de uso de Codex** se basan principalmente en tareas, medidos en "mensajes" o "tareas" en lugar de tokens brutos como las API más antiguas. Piénsalo así: una simple finalización de código podría contar como un mensaje, pero una refactorización de varios archivos podría consumir varios, dependiendo de la complejidad.
Según la documentación oficial, los límites se restablecen en una ventana móvil, a menudo cada 5 horas para tareas locales (como el uso de CLI o IDE), con topes semanales que entran en vigor para usuarios más intensivos. Para los usuarios de ChatGPT Plus, eso es aproximadamente de 30 a 150 mensajes cada 5 horas localmente, más un límite semanal general que puede agotarse rápidamente si estás trabajando en proyectos grandes. Las tareas basadas en la nube (a través de la interfaz web de ChatGPT) tienen más margen de maniobra ahora mismo, con asignaciones "generosas" durante esta fase beta, pero no cuentes con que sea ilimitado para siempre; OpenAI está ajustando según la demanda.
¿**Límites de tasa**? Aquí son más flexibles, vinculados a la duración de la tarea en lugar de RPM/TPM estrictos como la API principal. Las operaciones complejas (por ejemplo, depurar un repositorio de 10.000 líneas) podrían ralentizarse si las realizas 10 veces seguidas, pero se trata más de equidad que de límites estrictos. Los usuarios empresariales obtienen configuraciones personalizables, extrayendo de un fondo de créditos compartido, ¿y las versiones gratuitas? Olvídalo: **Codex** está bloqueado por un muro de pago. ¿El objetivo? Asegurarse de que todos obtengan una parte sin colapsar los servidores. Si te encuentras con el límite, verás un educado mensaje de "límite de uso alcanzado", lo que te obligará a esperar o cambiar al modo API. ¿Molesto? Claro. Pero mantiene a **Codex** funcionando para las masas.
Planes de Precios: ¿Cuál se Adapta a tu Flujo de Codex?
Adentrándonos en el aspecto económico, **Codex** se apoya en el ecosistema de ChatGPT, por lo que tu plan dicta tus **límites de uso de Codex**. No hay una suscripción de Codex independiente; viene incluida, lo que simplifica las cosas pero vincula tu presupuesto de codificación al de chat. Aquí está el desglose:
ChatGPT Plus ($20/mes): El punto de entrada para la mayoría de los desarrolladores individuales. Obtienes 30-150 mensajes locales cada 5 horas, con un límite semanal que se agota después de unos días intensos (piensa en 6-7 sesiones). Las tareas en la nube son más indulgentes por ahora, ideales si combinas la generación de código con la lluvia de ideas. Genial para aficionados o usuarios ligeros, pero si codificas a tiempo completo, espera rotar sesiones o actualizar tu plan.
ChatGPT Pro ($200/mes): Para usuarios avanzados, esto te eleva a 300-1.500 mensajes cada 5 horas localmente, además de límites semanales ampliados. Es una bestia para el trabajo diario en múltiples proyectos, perfecto si **Codex** es tu herramienta principal. El acceso a la nube sigue siendo generoso, y desbloqueas prioridad en nuevos modelos como las vistas previas de GPT-5-Codex.
Equipo ($25/usuario/mes, mín. 2 usuarios): Refleja el plan Plus por puesto, pero añade funciones de colaboración como espacios de trabajo compartidos. La fijación de precios flexible te permite comprar créditos adicionales para un uso intermitente, evitando límites estrictos. Si tu equipo realiza maratones de depuración, esto se escala sin problemas.
Empresarial/Educativo (Personalizado, desde ~$60/usuario/mes): Las grandes ligas. Los fondos de crédito compartidos significan límites a nivel de organización que puedes ajustar, con análisis para rastrear las tasas de consumo. Los SLA personalizados incluyen líneas de base más altas y aumentos bajo demanda; piensa en ilimitado para un sprint, luego reduce. Las variantes educativas añaden beneficios de cumplimiento para escuelas.
¿Excesos? Plus y los planes inferiores obligan a esperar, pero Pro/Equipo/Empresarial te permiten comprar complementos a través de la tarjeta de tarifas (por ejemplo, $0.02 por mensaje extra). Se basa en el uso, así que monitorea a través de tu panel de control para evitar sorpresas. La filosofía de OpenAI: Paga por lo que usas, pero comienza de forma conservadora para evitar sorpresas en la factura. Para los incondicionales de **Codex**, Pro es el punto ideal: potencia asequible sin la sobrecarga empresarial.

Saltando los Límites: El Truco de la Clave API de OpenAI
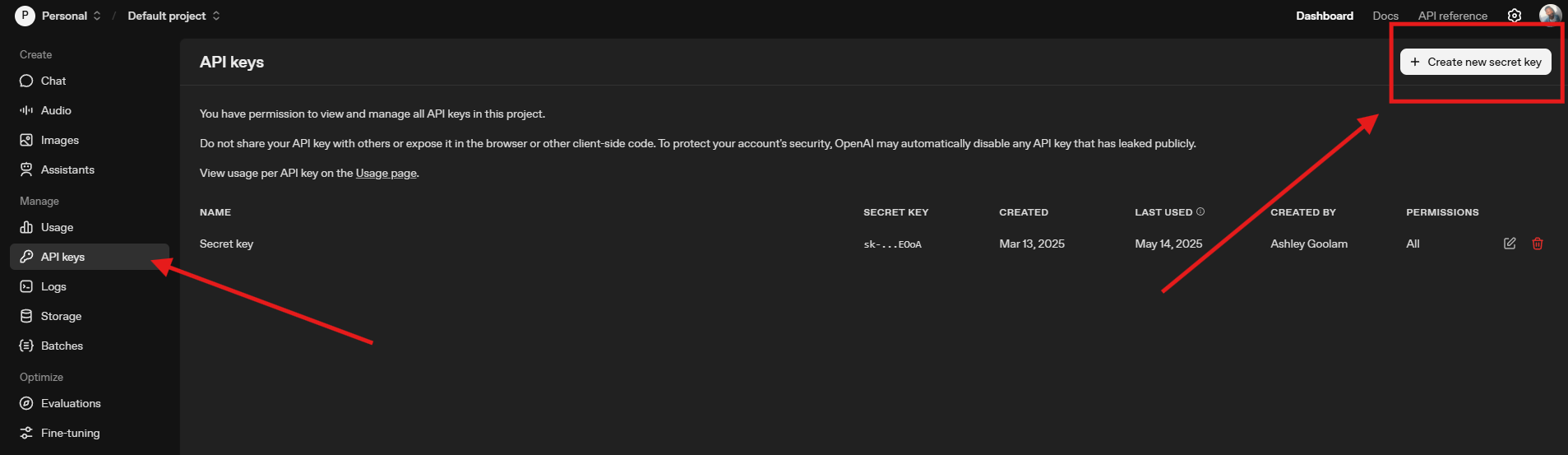
¿Te encuentras con un muro a mitad de sesión? Introduce la **clave API de OpenAI**, tu vía de escape de los **límites de uso de Codex** basados en planes. En lugar de depender de la autenticación de ChatGPT, cambia al modo API para tener libertad de pago por uso. Genera una clave en platform.openai.com/api-keys (gratis, pero se factura por uso), luego configúrala como una variable de entorno: export OPENAI_API_KEY=sk-yourkeyhere.
En la **CLI de Codex**, cambia con codex config set preferred_auth_method apikey o de forma ad-hoc mediante --api-key. Las extensiones de IDE también lo solicitan. Ahora, estás con las tarifas estándar de la API: GPT-5-Codex a $0.015/1K tokens de entrada, $0.045/1K de salida, muy barato para la mayoría de las tareas. No hay reinicios cada 5 horas; solo límites de RPM/TPM (por ejemplo, 500 RPM para claves vinculadas a Plus). Una sesión de depuración completa podría costar centavos, en comparación con esperar días en Plus.
Consejo profesional: Combina modos: usa ChatGPT para cosas rápidas, la API para maratones. Los hilos de GitHub elogian los scripts .bat que cambian automáticamente las claves cuando se alcanzan los límites, o rotan los archivos auth.json entre cuentas. No es infinito (la API tiene sus propios niveles), pero se siente ilimitado en comparación con los planes empaquetados. Solo vigila tu factura: configura alertas en el panel de control para limitar los gastos.
Lo que Dice la Comunidad de Desarrolladores: Quejas y Victorias en Reddit y GitHub
Ningún artículo sobre los **límites de uso de Codex** está completo sin el testimonio crudo de los desarrolladores en las trincheras. En r/OpenAI de Reddit, un hilo viral (con 97 votos positivos) describe el dolor: "¡Los límites de Codex son molestos porque no te avisa!" El usuario Visible-Delivery-978 pagó por Plus, consumió el equivalente a una semana en 1,5 días de depuración feliz, y luego ¡BAM!, bloqueado sin previo aviso. Los comentarios se hacen eco del caos: un usuario canceló después de una espera de 5 días, otro lo llamó "adictivo" pero cambió a Pro para menos interrupciones. ¿Consejos? Baja a "razonamiento medio" para estirar los límites, o usa el modo nube para ejecuciones casi ilimitadas. Un lado positivo: OpenAI restableció el límite del usuario como un gesto de buena voluntad, lo que generó esperanza de mejores advertencias.
El repositorio de Codex en GitHub es una mina de oro de frustraciones convertidas en soluciones. En la Discusión #2251, los desarrolladores se quejan de que los límites de Plus se activan después de 12 horas en total, mucho más estrictos que los de Claude Pro. Las quejas se acumulan: la falta de visibilidad del uso provoca pánicos a mitad de tarea, y los límites semanales se sienten "gradualmente más bajos" como un estrangulamiento sigiloso. Las soluciones alternativas brillan: rotar 3-5 cuentas Plus mediante intercambios de autenticación (chapucero pero efectivo), o scripts .bat para cambiar a claves API a mitad de flujo. Un desarrollador estima que €2-3/día en la API es más barato que actualizar, mientras que otro propone resumir las sesiones en AGENTS.md para reanudarlas con elegancia. ¿Requisitos de características? Reautenticación automática al alcanzar límites y exportación de progreso (vinculado a la Issue #3366).
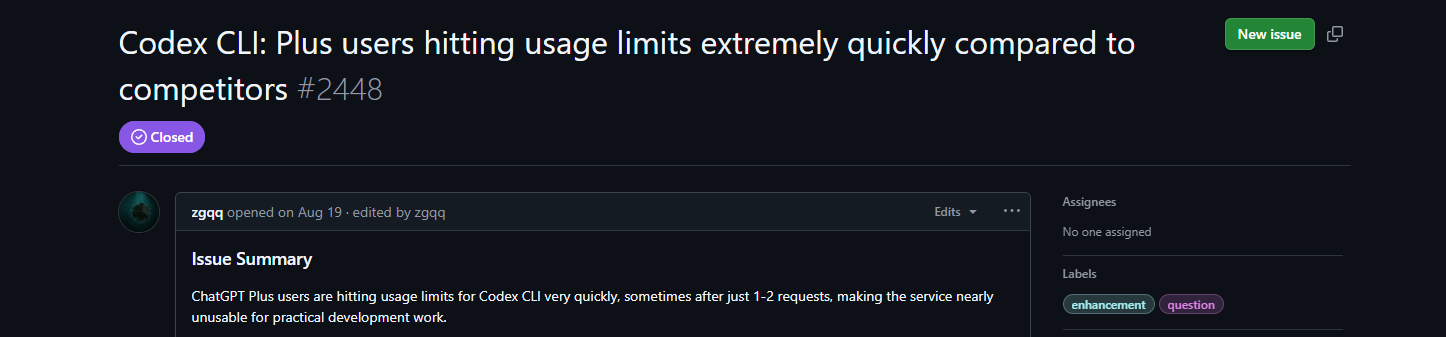
La Issue #2448 eleva la temperatura: los usuarios de Plus alcanzan el límite después de 1-2 solicitudes, lo que hace que la CLI sea "casi inutilizable". En comparación con las sesiones maratonianas de Claude, es un fastidio: los desarrolladores amenazan con cambiar, citando la pérdida de impulso. Sugerencias: Aumentar las bases de Plus, añadir medidores de uso en la CLI (la PR #3977 se fusionará pronto), o pasar completamente a un modelo basado en el uso. Los trucos de la comunidad incluyen el trabajo con subdirectorios para almacenar en caché el contexto y agrupar tareas pequeñas. La referencia rápida de Milvus lo respalda: planifica estratégicamente, monitorea los paneles y solicita aumentos empresariales para proyectos grandes.
¿La vibra? Los límites son un fastidio para el flujo, pero la comunidad es resiliente: los cambios de API y las pilas de planes mantienen el código en marcha. OpenAI está escuchando (esos reinicios y PR lo demuestran), por lo que los ciclos de retroalimentación se están ajustando.
Conclusión: Navegando Límites y Consejos para Maximizar tus Sesiones de Codex
Para concluir con una nota alta, aquí te explicamos cómo sortear los **límites de uso de Codex** como un profesional. Prompts por lotes: Una gran solicitud de "generar + probar + depurar" en lugar de intercambios de chat conversacionales. Usa la nube para picos de uso y monitorea mediante notificaciones del panel, y configura una API como respaldo. Para los equipos, el pool de Enterprise es un salvavidas. Y oye, si los límites evolucionan (OpenAI está ajustando según los comentarios), mantente atento a esos problemas de GitHub.
**Codex** vale la pena los ajustes: su inteligencia ahorra horas, con límites o sin ellos. ¿Tienes una historia de terror con los límites o un truco? Compártelo en las plataformas de desarrolladores. Hasta la próxima, codifica de forma inteligente, prueba a menudo, ¡y que tus cuotas estén siempre llenas!
