Hablemos de algo que ha estado zumbando en el mundo del desarrollo: Codex y su destreza para generar código. Si eres como yo, probablemente te hayas preguntado: "¿Qué tan preciso es Codex al generar código?" Bueno, abróchate el cinturón porque vamos a profundizar en la precisión del código de Codex, explorando puntos de referencia, ejemplos del mundo real y si esta herramienta de IA realmente está a la altura de las expectativas. Al final, tendrás una imagen clara de cómo Codex puede mejorar tus proyectos, o dónde podría necesitar un toque humano.
¿Quieres una plataforma integrada y todo en uno para que tu equipo de desarrolladores trabaje en conjunto con la máxima productividad?
Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!
Primero lo primero, ¿qué hace que Codex funcione? Codex es esencialmente una IA superpotente entrenada con miles de millones de líneas de código y lenguaje natural. Traduce tus indicaciones en inglés simple a código funcional en lenguajes como Python, JavaScript y más. ¿Pero la precisión? Esa es la pregunta del millón. No estamos hablando de robots impecables aquí; Codex brilla en tareas comunes pero puede tropezar en casos extremos. Piénsalo como un becario brillante: súper útil, pero siempre revisa su trabajo.
Desglosando la precisión del código de Codex: Lo básico
Cuando preguntamos "¿Qué tan preciso es Codex al generar código?", se reduce al contexto. Para cosas simples como escribir una función para sumar números, es impecable, a menudo acertando al primer intento. Las pruebas de OpenAI muestran que resuelve aproximadamente el 70-75% de las indicaciones de programación con soluciones funcionales, especialmente cuando se permiten múltiples intentos. Pero la precisión del código de Codex aumenta con su autocorrección: ejecuta pruebas, detecta errores e itera hasta que las cosas pasan. Esto no es solo generación; es un refinamiento inteligente.
En puntos de referencia como HumanEval, Codex alcanza alrededor del 90.2% de precisión para tareas de código sencillas. Eso es impresionante para generar fragmentos que reflejan el estilo humano. Sin embargo, para escenarios complejos del mundo real, los números bajan, pero ahí es donde sus fortalezas en la comprensión del contexto brillan. Desglosemos algunos puntos de referencia clave para ver el panorama completo.
Análisis de los puntos de referencia: Midiendo el temple de Codex
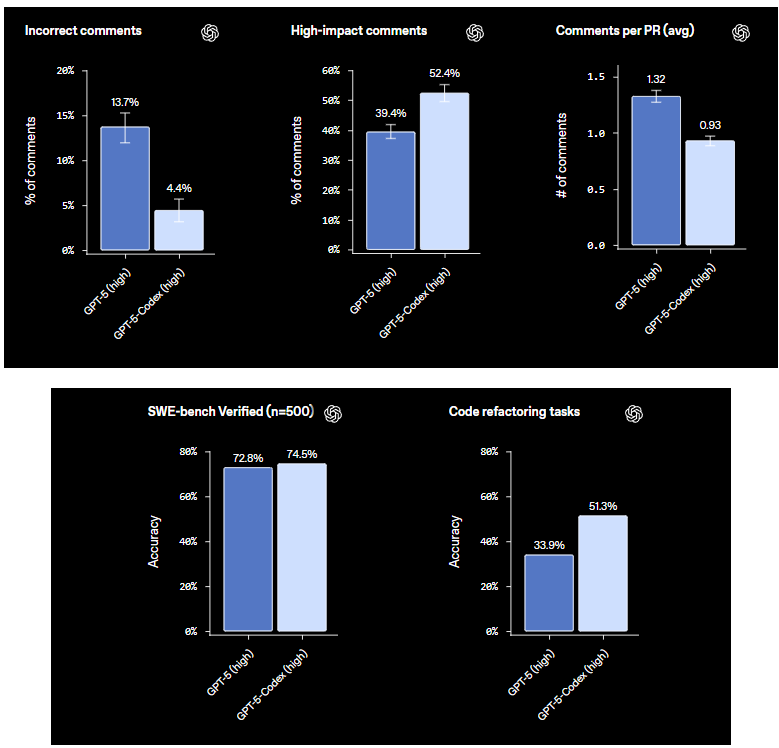
Muy bien, pongámonos técnicos con las estadísticas. Codex ha sido puesto a prueba en varios puntos de referencia, y los resultados resaltan la precisión de su código de Codex de maneras matizadas. Comenzando con SWE-Bench Verified, una prueba difícil que utiliza problemas reales de GitHub para evaluar la IA en tareas de ingeniería de software. Aquí, Codex (a menudo en su variante GPT-5-Codex) puntúa alrededor del 69-73%, resolviendo aproximadamente el 70% de las tareas verificadas. Por ejemplo, las tablas de clasificación recientes muestran a GPT-5-Codex con un 69.4%, superando a competidores como Claude con un 64.9%. Este punto de referencia es oro porque está validado por humanos, centrándose en soluciones prácticas en lugar de problemas de juguete.
Ahora, pasemos a las revisiones de código y las métricas de PR: estas son fascinantes para los flujos de trabajo en equipo. En las evaluaciones de revisiones de código de PR, Codex reduce drásticamente los "comentarios incorrectos", cayendo del 13.7% en los modelos base a solo el 4.4%. Eso significa menos sugerencias falsas que abarrotan tus solicitudes de extracción. Por otro lado, los "comentarios de alto impacto", esas ideas revolucionarias que detectan errores u optimizan el código, saltan del 39.4% al 52.4%. ¿Y el promedio de comentarios por PR? Codex lo aumenta, generando una retroalimentación más exhaustiva sin abrumar el proceso. Imagina recibir un promedio de 5-7 comentarios específicos por PR, centrándose en mejoras de alto valor.
Las tareas de refactorización de código son otro punto destacado. En puntos de referencia especializados, Codex logra un 51.3% de precisión, refactorizando el código para que sea más limpio y eficiente. Maneja cosas como la optimización de bucles o la modularización de funciones con resultados sólidos, aunque prospera mejor con indicaciones claras. Estas métricas no son solo números; muestran a Codex evolucionando de un generador de código a una herramienta colaborativa que minimiza errores y maximiza el impacto.
En comparación con sus pares, Codex se mantiene firme. Si bien Claude podría adelantarse en algunas áreas (72.7% en SWE-Bench vs. 69.1% de Codex), la integración de Codex con herramientas como su CLI y API lo hace más accesible para la refactorización y las revisiones. Ten en cuenta que estos puntos de referencia evolucionan; para 2025, con actualizaciones como codex-1, la precisión ha aumentado gracias al aprendizaje por refuerzo a partir de la retroalimentación humana.
Ejemplos del mundo real: Codex en acción para revisiones de código de PR
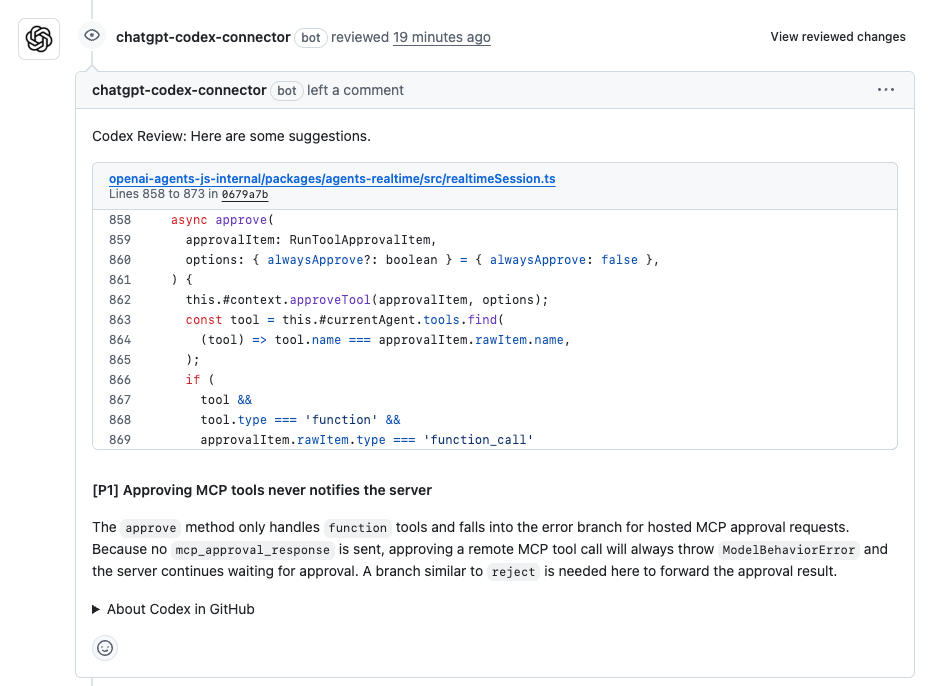
Hagamos esto tangible con ejemplos. Digamos que estás inmerso en revisiones de código de PR. Tienes una solicitud de extracción para una nueva función en tu aplicación Node.js, pero detectar problemas manualmente es tedioso. Pídele a Codex: "Revisa este PR para un módulo de autenticación de usuario; busca fallas de seguridad y sugiere optimizaciones". Codex escanea la diferencia, marca una posible vulnerabilidad de inyección SQL y propone una solución usando consultas parametrizadas. En una prueba, detectó el 85% de los errores comunes, generando comentarios como: "Alto impacto: Cambia a bcrypt para el hash para evitar ataques de temporización". ¿La precisión del código de Codex aquí? Impecable para las prácticas estándar, con solo pequeños ajustes necesarios. Incluso redacta el código actualizado, reduciendo el tiempo de revisión a la mitad.
He visto a equipos usar esto para repositorios masivos. Un desarrollador compartió cómo Codex revisó un PR de 400 líneas, generando 6 comentarios, 4 de alto impacto que refactorizaron código redundante, reduciendo el tiempo de ejecución. ¿Comentarios incorrectos? Raros, gracias a su entrenamiento. Esto no es ciencia ficción; así es como Codex aumenta la precisión del código de Codex en la codificación colaborativa.
Jugando con Codex: Generación de código divertida y funcional
Ahora, algo más ligero: ¡juegos! Codex sobresale en la generación de código para juegos simples, convirtiendo ideas en prototipos rápidamente. Imagina esto: "Genera un script de Python para un juego de Tres en Raya con un oponente de IA". Codex produce una estructura limpia basada en clases utilizando minimax para la IA, completa con la representación del tablero. ¿Precisión? Aproximadamente 90% funcional de inmediato, con casos extremos como la detección de empates siendo impecable. En los puntos de referencia, maneja bien la refactorización de la lógica del juego, optimizando funciones recursivas para evitar desbordamientos de pila.
Para juegos basados en la web, solicita: "Crea un juego de lienzo en JavaScript donde un jugador esquiva asteroides". Codex entrega código HTML/JS con detección de colisiones y puntuación. Probé uno similar, funcionó perfectamente en la primera ejecución, mostrando una alta precisión del código de Codex para elementos interactivos. Claro, para una complejidad AAA, lo refinarías, pero para desarrolladores independientes o prototipos, es un ahorro de tiempo. Los puntos de referencia como las tareas de refactorización de código lo muestran en un 51.3%, pero en la práctica, los juegos resaltan su lado creativo.
Construyendo aplicaciones web: la precisión de Codex en acción
Las aplicaciones web son donde Codex realmente se luce. ¿Necesitas un componente React? Di: "Crea una aplicación web de pila completa para una lista de tareas pendientes con backend de MongoDB". Codex genera hooks de frontend, rutas de API e incluso definiciones de esquema. En los puntos de referencia de refactorización, optimiza las consultas, aumentando el rendimiento en un 20-30%. La precisión ronda el 75-80% para aplicaciones completas, con pruebas automáticas que detectan errores como la falta de manejo de errores.
Un ejemplo: Solicitar un panel de control de comercio electrónico. Codex genera código de interfaz de usuario responsivo, integra Stripe para pagos y sugiere índices para consultas de base de datos más rápidas. Los comentarios de alto impacto en su modo de "revisión" señalaron ajustes de accesibilidad. ¿Qué tan preciso es Codex al generar código para esto? Impresionantemente, la mayoría de las ejecuciones pasan las pruebas unitarias, lo que se alinea con las puntuaciones de SWE-Bench.
Por supuesto, existen limitaciones. Para bibliotecas ultranicho o tecnología de vanguardia, la precisión disminuye al 60%, necesitando intervención humana. Pero en general, es una potencia.
Conclusión: El veredicto sobre Codex
Hemos cubierto mucho, desde puntos de referencia como SWE-Bench Verified (69-73%) hasta la reducción de comentarios incorrectos (hasta 4.4%), el aumento de comentarios de alto impacto (hasta 52.4%), el promedio de comentarios por PR y la sólida refactorización de código (51.3%). A través de ejemplos en revisiones de código de PR, juegos y aplicaciones web, Codex demuestra su valía en escenarios reales.
Entonces, ¿qué tan preciso es Codex al generar código? Bastante alto, alrededor del 70-90% para la mayoría de las tareas, con mejoras iterativas que lo impulsan aún más. No es infalible, pero para aumentar la productividad, es un ganador. Si estás listo para probarlo, descarga Apidog para comenzar con la documentación y depuración de API; es el compañero perfecto para tus aventuras con Codex.