
La familia Qwen 3 domina el panorama de los LLM de código abierto en 2025. Los ingenieros implementan estos modelos en todas partes, desde agentes empresariales de misión crítica hasta asistentes móviles. Antes de comenzar a enviar solicitudes a Alibaba Cloud o a autoalojarlos, optimice su flujo de trabajo con Apidog.
Panorama General de Qwen 3: Innovaciones Arquitectónicas que Impulsan el Rendimiento en 2025
El equipo Qwen de Alibaba lanzó la serie Qwen 3 el 29 de abril de 2025, marcando un avance fundamental en los modelos de lenguaje grandes (LLM) de código abierto. Los desarrolladores elogian su licencia Apache 2.0, que permite el ajuste fino y la implementación comercial sin restricciones. En su núcleo, Qwen 3 emplea una arquitectura basada en Transformer con mejoras en incrustaciones posicionales y mecanismos de atención, admitiendo longitudes de contexto de hasta 128K tokens de forma nativa, y extendible a 131K mediante YaRN.

Además, la serie incorpora diseños de Mezcla de Expertos (MoE) en variantes seleccionadas, activando solo una fracción de los parámetros durante la inferencia. Este enfoque reduce la sobrecarga computacional manteniendo una alta fidelidad en los resultados. Por ejemplo, los ingenieros reportan un rendimiento hasta 10 veces más rápido en tareas de contexto largo en comparación con predecesores densos como Qwen2.5-72B. Como resultado, las variantes de Qwen 3 escalan eficientemente en todo el hardware, desde dispositivos perimetrales hasta clústeres en la nube.
Qwen 3 también destaca en el soporte multilingüe, manejando más de 119 idiomas con un seguimiento matizado de instrucciones. Los puntos de referencia confirman su ventaja en dominios STEM, donde procesa datos sintéticos de matemáticas y código refinados a partir de 36 billones de tokens. Por lo tanto, las aplicaciones en empresas globales se benefician de la reducción de errores de traducción y una mejor capacidad de razonamiento interlingüístico. Pasando a los detalles, el modo de razonamiento híbrido —activado mediante indicadores de tokenizador— permite a los modelos aplicar lógica paso a paso para matemáticas o codificación, o por defecto a un modo "no pensante" para el diálogo. Esta dualidad permite a los desarrolladores optimizar por caso de uso.
Características Clave que Unifican las Variantes de Qwen 3
Todos los modelos Qwen 3 comparten rasgos fundamentales que elevan su utilidad en 2025. Primero, soportan una operación de doble modo: el modo de pensamiento activa procesos de cadena de pensamiento para benchmarks como AIME25, mientras que el modo no pensante prioriza la velocidad para aplicaciones de chat. Los ingenieros alternan esto con parámetros simples, logrando hasta un 92.3% de precisión en matemáticas complejas sin sacrificar la latencia.
Segundo, las características de agente permiten la invocación de herramientas sin problemas, superando a sus pares de código abierto en tareas como la navegación de navegador o la ejecución de código. Por ejemplo, las variantes de Qwen 3 obtienen una puntuación de 69.6 en Tau2-Bench Verified, rivalizando con modelos propietarios. Además, su destreza multilingüe cubre dialectos desde el mandarín hasta el suajili, con un 73.0 en los benchmarks MultiIF.
Tercero, la eficiencia proviene de variantes cuantificadas (por ejemplo, Q4_K_M) y frameworks como vLLM o SGLang, que entregan 25 tokens/segundo en GPUs de consumo. Sin embargo, los modelos más grandes requieren más de 16GB de VRAM, lo que impulsa las implementaciones en la nube. Los precios siguen siendo competitivos, con tokens de entrada a $0.20–$1.20 por millón a través de Alibaba Cloud.
Además, Qwen 3 enfatiza la seguridad a través de la moderación incorporada, reduciendo las alucinaciones en un 15% en comparación con Qwen2.5. Los desarrolladores aprovechan esto para aplicaciones de nivel de producción, desde recomendadores de comercio electrónico hasta analizadores legales. A medida que pasamos a las variantes individuales, estas fortalezas compartidas proporcionan una base consistente para la comparación.
Las 5 Mejores Variantes del Modelo Qwen 3 en 2025
Basándonos en los benchmarks de 2025 de LMSYS Arena, LiveCodeBench y SWE-Bench, clasificamos las cinco mejores variantes de Qwen 3. Los criterios de selección incluyen puntuaciones de razonamiento, velocidad de inferencia, eficiencia de parámetros y accesibilidad API. Cada una destaca en escenarios distintos, pero todas avanzan las fronteras del código abierto.
1. Qwen3-235B-A22B – El Monstruo MoE Insignia Absoluto
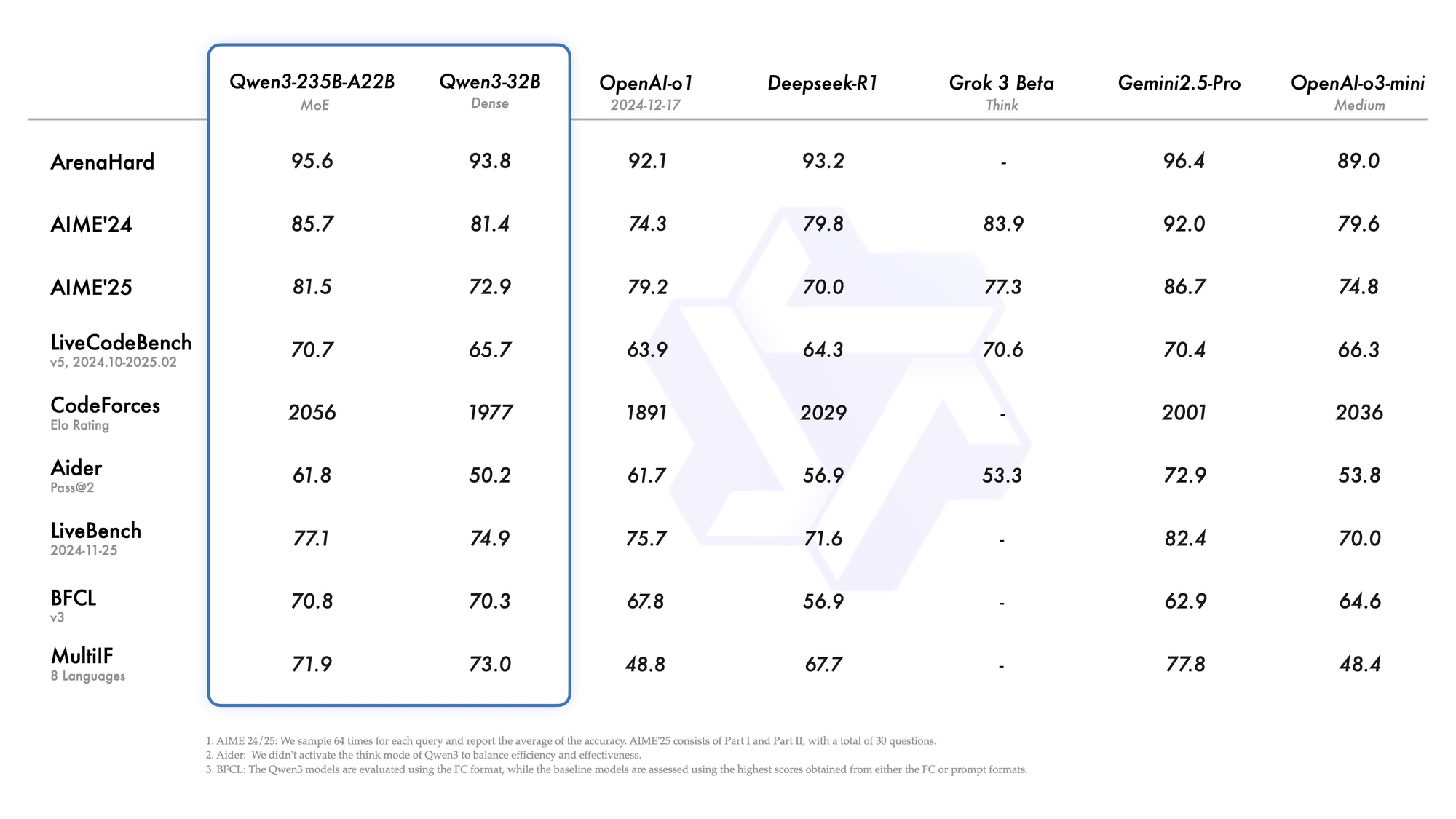
Qwen3-235B-A22B acapara la atención como la principal variante MoE, con 235 mil millones de parámetros totales y 22 mil millones activos por token. Lanzado en julio de 2025 como Qwen3-235B-A22B-Instruct-2507, activa ocho expertos mediante enrutamiento top-k, reduciendo la computación en un 90% en comparación con equivalentes densos. Los benchmarks lo sitúan codo con codo con Gemini 2.5 Pro: 95.6 en ArenaHard, 77.1 en LiveBench, y liderazgo en CodeForces Elo (con un 5% de ventaja).
En codificación, logra 74.8 en LiveCodeBench v6, generando TypeScript funcional con iteraciones mínimas. Para matemáticas, el modo de pensamiento produce 92.3 en AIME25, resolviendo integrales de varios pasos mediante deducción explícita. Las tareas multilingües ven 73.0 en MultiIF, procesando consultas en árabe sin fallos.
La implementación favorece las API en la nube, donde maneja contextos de 256K. Sin embargo, las ejecuciones locales requieren 8x GPUs H100. Los ingenieros lo integran para flujos de trabajo de agente, como la depuración a escala de repositorio. En general, esta variante establece el estándar de 2025 en cuanto a profundidad, aunque su escala se adapta a equipos con presupuestos elevados.
Fortalezas
- Iguala o supera a Gemini 2.5 Pro y Claude 3.7 Sonnet en casi todas las clasificaciones de 2025 (95.6 ArenaHard, 92.3 AIME25 modo pensamiento, 74.8 LiveCodeBench v6).
- Destaca en flujos de trabajo de agente de múltiples turnos, invocación compleja de herramientas y comprensión de código a nivel de repositorio.
- Maneja contextos de 256K–1M con YaRN sin pérdida de calidad.
- El modo de pensamiento ofrece un razonamiento de cadena de pensamiento verificable que rivaliza con los modelos de frontera de código cerrado.
Debilidades
- Extremadamente caro y lento localmente—requiere 8×H100 o equivalente para una latencia razonable.
- El precio de la API es el más alto de la familia ($1.20–$6.00/M tokens de salida en contexto pico).
- Exagerado para el 95% de las cargas de trabajo de producción; la mayoría de los equipos nunca saturan su capacidad.
Cuándo usarlo
- Agentes autónomos de nivel empresarial que deben resolver matemáticas de nivel de doctorado, depurar bases de código completas o realizar análisis de contratos legales con una alucinación cercana a cero.
- Laboratorios de investigación con alto presupuesto que impulsan el estado del arte en nuevos benchmarks.
- Backends de razonamiento internos donde el costo por token es secundario a la máxima inteligencia.
2. Qwen3-30B-A3B – El Campeón MoE del Punto Óptimo
Qwen3-30B-A3B emerge como la opción ideal para configuraciones con recursos limitados, presentando 30.5 mil millones de parámetros totales y 3.3 mil millones activos. Su estructura MoE —48 capas, 128 expertos (ocho enrutados)— refleja la del modelo insignia pero con un 10% de la huella. Actualizado en julio de 2025, supera a QwQ-32B en 10 veces en eficiencia activa, obteniendo 91.0 en ArenaHard y 69.6 en SWE-Bench Verified.
Las evaluaciones de codificación destacan su destreza: 32.4% pass@5 en PRs nuevos de GitHub, igualando a GPT-5-High. Los benchmarks de matemáticas muestran 81.6 en AIME25 en modo de pensamiento, rivalizando con sus hermanos mayores. Con 131K de contexto vía YaRN, procesa documentos largos sin truncamiento.
Fortalezas
- Parámetros activos 10 veces más baratos que el 235B, manteniendo aproximadamente el 90–95% de la calidad de razonamiento del modelo insignia (91.0 ArenaHard, 81.6 AIME25).
- Funciona cómodamente en una sola A100 de 80GB o dos tarjetas de 40GB con vLLM + FlashAttention.
- La mejor relación precio-rendimiento entre todos los modelos MoE abiertos de 2025.
- Supera a todos los modelos densos de 72B–110B en codificación y matemáticas.
Debilidades
- Todavía necesita ~24–30GB de VRAM en FP8/INT4; no es amigable con laptops.
- Fluidez de escritura creativa ligeramente inferior a la de modelos densos puros de tamaño similar.
- La latencia del modo de pensamiento aumenta 2–3 veces en comparación con el modo no pensante.
Cuándo usarlo
- Agentes de codificación de producción, revisiones automáticas de PRs o copilotos internos de DevOps.
- Pipelines de investigación de alto rendimiento que necesitan razonamiento de nivel de frontera en matemáticas o ciencias con un presupuesto razonable.
- Cualquier equipo que haya utilizado previamente Llama-405B o Mixtral-123B pero que quiera un mejor razonamiento a menor costo.
3. Qwen3-32B – El Rey Denso Todoterreno
El denso Qwen3-32B ofrece 32 mil millones de parámetros totalmente activos, enfatizando el rendimiento bruto sobre la escasez. Entrenado con 36T tokens, iguala a Qwen2.5-72B en rendimiento base pero destaca en la alineación post-entrenamiento. Los benchmarks revelan 89.5 en ArenaHard y 73.0 en MultiIF, con una fuerte escritura creativa (por ejemplo, narrativas de juego de rol que obtienen un 85% de preferencia humana).
En codificación, lidera BFCL con 68.2, generando interfaces de usuario de arrastrar y soltar a partir de prompts. En matemáticas, obtiene 70.3 en AIME25, aunque se queda atrás de sus pares MoE en la cadena de pensamiento. Su contexto de 128K se adapta a bases de conocimiento, y el modo no pensante aumenta la velocidad de diálogo a 20 tokens/segundo.
Fortalezas
- Excepcional seguimiento de instrucciones y salida creativa —a menudo preferido sobre modelos MoE más grandes en evaluaciones humanas ciegas para escritura y juego de rol.
- Fácil de ajustar con LoRA/QLoRA en hardware de consumo (16–24GB VRAM).
- La inferencia más rápida entre los modelos que aún superan a GPT-4o en muchas tareas (89.5 ArenaHard).
- Rendimiento multilingüe muy fuerte en más de 119 idiomas.
Debilidades
- Se queda ~8–12 puntos por detrás de sus hermanos MoE en los benchmarks de matemáticas y codificación más difíciles cuando el modo de pensamiento está activado.
- No hay trucos de eficiencia de parámetros —cada token cuesta la computación completa de 32B.
Cuándo usarlo
- Plataformas de generación de contenido, asistentes de escritura de novelas, herramientas de copia de marketing.
- Proyectos que requieren un ajuste fino intensivo (chatbots específicos de dominio, transferencia de estilo).
- Equipos que desean una calidad casi insignia pero deben mantenerse por debajo de los 24GB de VRAM.
4. Qwen3-14B – Potencia para Dispositivos Periféricos y Móviles
Qwen3-14B prioriza la portabilidad con 14.8 mil millones de parámetros, soportando contextos de 128K en hardware de gama media. Rivaliza con Qwen2.5-32B en eficiencia, obteniendo 85.5 en ArenaHard e intercambiando golpes con Qwen3-30B-A3B en matemáticas/codificación (dentro de un margen del 5%). Cuantificado a Q4_0, funciona a 24.5 tokens/segundo en móviles como el RedMagic 8S Pro.
Las tareas de agente obtienen 65.1 en Tau2-Bench, permitiendo el uso de herramientas en aplicaciones de baja latencia. El soporte multilingüe brilla, con un 70% de precisión en inferencia dialectal. Para dispositivos de borde, procesa contextos de 32K sin conexión, ideal para análisis de IoT.
Los ingenieros valoran su huella para el aprendizaje federado, donde la privacidad supera la escala. Por lo tanto, encaja en asistentes de IA móviles o sistemas embebidos.
Fortalezas
- Funciona a 24–30 tokens/segundo en teléfonos modernos (Snapdragon 8 Gen 4, Dimensity 9400) cuando se cuantifica a Q4_K_M.
- Todavía supera a Qwen2.5-32B y Llama-3.1-70B en la mayoría de los benchmarks de razonamiento.
- Excelente para RAG en dispositivo con contexto de 32K–128K.
- El costo más bajo de API en el segmento de rendimiento de alto nivel.
Debilidades
- Comienza a tener dificultades con tareas de agente de múltiples pasos que requieren más de 5 llamadas a herramientas.
- Calidad de escritura creativa notablemente inferior a la de los modelos de 32B+.
- Menos a prueba de futuro a medida que los benchmarks siguen aumentando.
Cuándo usarlo
- Asistentes en dispositivo (aplicaciones Android/iOS, wearables).
- Implementaciones sensibles a la privacidad (salud, finanzas) donde los datos no pueden salir del dispositivo.
- Sistemas embebidos en tiempo real (robots, coches, pasarelas IoT).
5. Qwen3-8B – El Caballo de Batalla Ligero Definitivo para Prototipos
Completando los cinco primeros, Qwen3-8B ofrece 8 mil millones de parámetros para una iteración rápida, superando a Qwen2.5-14B en 15 benchmarks. Logra 81.5 en AIME25 (sin pensamiento) y 60.2 en LiveCodeBench, suficiente para revisiones básicas de código. Con 32K de contexto nativo, se implementa en laptops vía Ollama, alcanzando 25 tokens/segundo.
Esta variante es adecuada para principiantes que prueban chats multilingües o agentes simples. Su modo de pensamiento mejora los rompecabezas lógicos, obteniendo un 75% en tareas de deducción. Como resultado, acelera las pruebas de concepto antes de escalar a variantes más grandes.
Fortalezas
- Funciona a >25 tokens/segundo incluso en laptops con 8–12GB de VRAM (MacBook M3 Pro, RTX 4070 móvil).
- Seguimiento de instrucciones sorprendentemente competente —supera a Gemma-2-27B y Phi-4-14B en la mayoría de las clasificaciones de 2025.
- Perfecto para experimentación local con Ollama o LM Studio.
- El precio de API más económico de la familia.
Debilidades
- Techo de razonamiento obvio en matemáticas de nivel de posgrado y problemas de codificación avanzados.
- Más propenso a la alucinación en tareas intensivas en conocimiento.
- Contexto limitado (32K nativo, 128K con YaRN pero más lento).
Cuándo usarlo
- Prototipado rápido y construcción de MVP.
- Herramientas educativas, asistentes personales o proyectos de hobby.
- Capa de enrutamiento frontend en sistemas híbridos (usar 8B para clasificar, escalar a 30B/235B cuando sea necesario).
Precios de API y Consideraciones de Implementación para Modelos Qwen 3
El acceso a Qwen 3 a través de APIs democratiza la IA avanzada, con Alibaba Cloud liderando con tarifas competitivas. Los precios se dividen por tokens: para Qwen3-235B-A22B, los costos de entrada son de $0.20–$1.20/millón (rango 0–252K), y los de salida de $1.00–$6.00/millón. Qwen3-30B-A3B refleja esto a un 80% de la tarifa, mientras que los densos como Qwen3-32B bajan a $0.15 de entrada/$0.75 de salida.
Proveedores de terceros como Together AI ofrecen Qwen3-32B a $0.80/1M tokens totales, con descuentos por volumen. Los aciertos de caché reducen las facturas: implícitos en un 20%, explícitos en un 10%. Comparado con GPT-5 ($3–15/1M), Qwen 3 recorta los precios en un 70%, permitiendo una escalabilidad rentable.
Consejos de implementación: Usa vLLM para el procesamiento por lotes, SGLang para la compatibilidad con OpenAI. Apidog mejora esto al simular los endpoints de Qwen, probar las cargas útiles y generar documentación, algo crucial para los pipelines de CI/CD. Las ejecuciones locales vía Ollama son adecuadas para la creación de prototipos, pero las API son excelentes para la producción.
Funcionalidades de seguridad como la limitación de velocidad y la moderación añaden valor, sin cargos adicionales. Por lo tanto, los equipos conscientes del presupuesto seleccionan según el volumen de tokens: variantes pequeñas para desarrollo, y los modelos insignia para inferencia.
Tabla de Decisión – Elige Tu Modelo Qwen 3 en 2025
| Rango | Modelo | Parámetros (Total/Activo) | Resumen de Fortalezas | Principales Debilidades | Mejor Para | Costo Aproximado de API (Entrada/Salida por 1M tokens) | VRAM Mínima (cuantificada) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | Razonamiento máximo, agéntico, matemáticas, código | Extremadamente caro y pesado | Investigación de vanguardia, agentes empresariales, precisión de tolerancia cero | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (nube) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | Mejor relación precio-rendimiento, razonamiento sólido | Todavía necesita GPU de servidor | Agentes de codificación de producción, backends de matemáticas/ciencia, inferencia de alto volumen | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B Denso | Escritura creativa, ajuste fino fácil, velocidad | Se queda atrás de MoE en las tareas más difíciles | Plataformas de contenido, ajuste fino de dominio, chatbots multilingües | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B Denso | Capaz para borde/móvil, excelente RAG en dispositivo | Habilidad limitada de agente de múltiples pasos | IA en dispositivo, aplicaciones críticas para la privacidad, sistemas embebidos | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B Denso | Velocidad de laptop/teléfono, el más barato | Techo obvio en tareas complejas | Prototipado, asistentes personales, capa de enrutamiento en sistemas híbridos | $0.10 / $0.50 | 4–8GB |
Recomendación Final para 2025
La mayoría de los equipos en 2025 deberían optar por Qwen3-30B-A3B —ofrece más del 90% de la potencia del modelo insignia a una fracción del costo y los requisitos de hardware. Solo suba a 235B-A22B si realmente necesita el último 5-10% de calidad de razonamiento y tiene el presupuesto. Pase al modelo denso de 32B para cargas de trabajo creativas o intensivas en ajuste fino, y use 14B/8B cuando la latencia, la privacidad o las restricciones del dispositivo dominen.
Cualquiera que sea la variante que elija, Apidog le ahorrará horas de depuración de API. Descárguelo gratis hoy y comience a construir con Qwen 3 con confianza.