
لطالما كان معالجة المستندات أحد أكثر تطبيقات الذكاء الاصطناعي عملية - ومع ذلك، فإن معظم حلول التعرف الضوئي على الأحرف (OCR) تفرض مقايضة غير مريحة بين الدقة والكفاءة. تتطلب الأنظمة التقليدية مثل Tesseract معالجة مسبقة واسعة النطاق. وتفرض واجهات برمجة تطبيقات السحابة رسومًا لكل صفحة وتضيف زمن وصول. وحتى نماذج الرؤية واللغة الحديثة تكافح مع انفجار الرموز الذي يأتي من صور المستندات عالية الدقة.
DeepSeek-OCR 2 يغير هذه المعادلة تمامًا. بناءً على نهج "الضغط البصري للسياقات" من الإصدار الأول، يقدم الإصدار الجديد "التدفق السببي البصري" (Visual Causal Flow) - وهي بنية تعالج المستندات بالطريقة التي يقرأها بها البشر فعليًا، حيث تفهم العلاقات البصرية والسياق بدلاً من مجرد التعرف على الأحرف. والنتيجة هي نموذج يحقق دقة 97% مع ضغط الصور إلى 64 رمزًا فقط، مما يتيح معالجة أكثر من 200,000 صفحة يوميًا على وحدة معالجة رسومات واحدة.
يغطي هذا الدليل كل شيء بدءًا من الإعداد الأساسي وصولاً إلى النشر في بيئة الإنتاج – مع كود جاهز للعمل يمكنك نسخه ولصقه وتشغيله على الفور.
ما هو DeepSeek-OCR 2؟
DeepSeek-OCR 2 هو نموذج رؤية-لغة مفتوح المصدر مصمم خصيصًا لفهم المستندات واستخراج النصوص. أطلقته DeepSeek AI في يناير 2026، وهو يبني على DeepSeek-OCR الأصلي ببنية "التدفق السببي البصري" الجديدة التي تحاكي كيفية ارتباط العناصر البصرية في المستندات ببعضها البعض سببيًا - حيث يفهم أن رأس الجدول يحدد كيفية تفسير الخلايا تحته، أو أن تسمية الشكل تشرح الرسم البياني الذي فوقه.
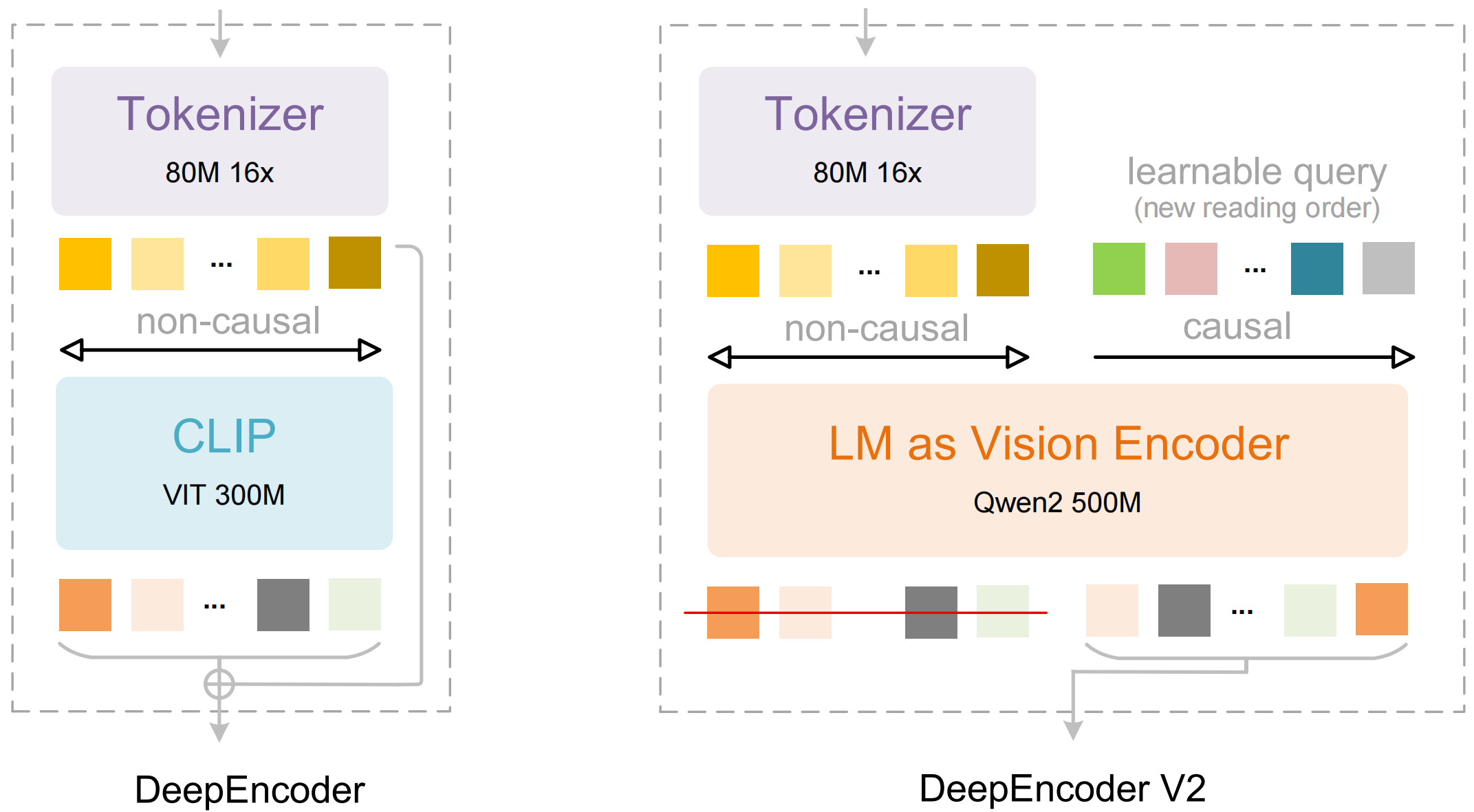
يتكون النموذج من مكونين رئيسيين:
- DeepEncoder: محول رؤية مزدوج transformer يجمع بين استخراج التفاصيل المحلية (المعتمد على SAM، 80 مليون معلمة) وفهم التخطيط العالمي (المعتمد على CLIP، 300 مليون معلمة)
- DeepSeek3B-MoE Decoder: نموذج لغة من نوع "مزيج الخبراء" (mixture-of-experts) يولد مخرجات منظمة (Markdown، LaTeX، JSON) من التمثيل المرئي المضغوط
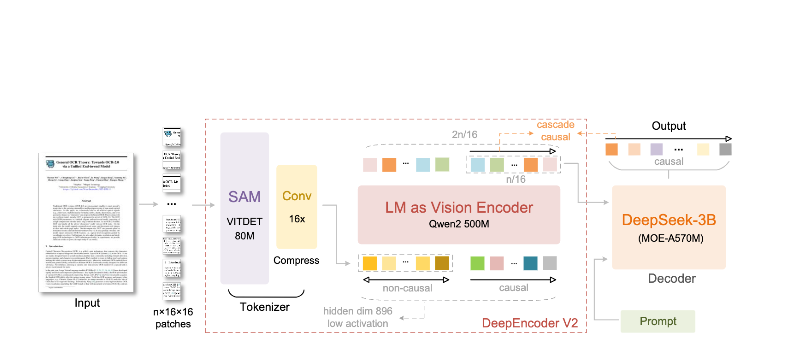
ما الذي يميز DeepSeek-OCR 2:
- ضغط فائق: يقلل الصورة بحجم 1024×1024 من 4,096 جزءًا إلى 256 رمزًا فقط - تخفيض بمقدار 16 مرة
- مخرجات منظمة: يولد Markdown نظيفًا مع جداول ورؤوس وتنسيق مناسب
- دعم تنسيقات متعددة: يتعامل مع ملفات PDF، والمستندات الممسوحة ضوئيًا، ولقطات الشاشة، والملاحظات المكتوبة بخط اليد، والمزيد
- أكثر من 100 لغة: تم تدريبه على 30 مليون صفحة تغطي حوالي 100 لغة
- أوزان مفتوحة: مرخصة برخصة MIT، متاحة على Hugging Face
الميزات الرئيسية والبنية
التدفق السببي البصري
الميزة البارزة في الإصدار الثاني هي "التدفق السببي البصري" - وهو نهج جديد لفهم المستندات يتجاوز التعرف الضوئي على الحروف (OCR) البسيط. بدلاً من التعامل مع الصفحة كشبكة مسطحة من الأحرف، يتعلم النموذج العلاقات السببية بين العناصر البصرية:
- استدلال ترتيب القراءة: يحدد تلقائيًا الترتيب الصحيح للتخطيطات متعددة الأعمدة
- فهم بنية الجدول: يتعرف على الرؤوس، والخلايا المدمجة، والجداول المتداخلة
- ربط الشكل بالتسمية التوضيحية: يربط الصور بأوصافها
- تحليل التعبيرات الرياضية: يتعامل مع معادلات LaTeX المضمنة والكتل بدقة
بنية DeepEncoder
هنا تكمن الروعة في DeepEncoder. فهو يعالج الصور عالية الدقة مع الحفاظ على عدد رموز يمكن إدارته:
Input Image (1024×1024)
↓
SAM-base Block (80M params)
- Windowed attention for local detail
- Extracts fine-grained features
↓
CLIP-large Block (300M params)
- Global attention for layout
- Understands document structure
↓
Convolution Block
- 16× token reduction
- 4,096 patches → 256 tokens
↓
Output: Compressed Vision Tokens
المفاضلة بين الضغط والدقة
| نسبة الضغط | رموز الرؤية (Vision Tokens) | الدقة |
|---|---|---|
| 4× | 1,024 | 99%+ |
| 10× | 256 | 97% |
| 16× | 160 | 92% |
| 20× | 128 | ~60% |
النقطة المثلى لمعظم التطبيقات هي نسبة الضغط 10x، والتي تحافظ على دقة 97% مع تمكين الإنتاجية العالية التي تجعل النشر في بيئة الإنتاج عمليًا.
التثبيت والإعداد
المتطلبات الأساسية
- بايثون 3.10+ (يوصى بـ 3.12.9)
- CUDA 11.8+ مع وحدة معالجة رسومات NVIDIA متوافقة
- ذاكرة وحدة معالجة رسومات لا تقل عن 16 جيجابايت (يوصى بـ A100-40G للإنتاج)
الطريقة 1: تثبيت vLLM (موصى به)
يوفر vLLM أفضل أداء لعمليات النشر في بيئة الإنتاج:
# Create virtual environment
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# Install vLLM with CUDA support
pip install vllm>=0.8.5
# Install flash attention for optimal performance
pip install flash-attn==2.7.3 --no-build-isolation
الطريقة 2: تثبيت Transformers
للتطوير والتجريب:
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
الطريقة 3: Docker (للإنتاج)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# Pre-download model
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
التحقق من التثبيت
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
import vllm
print(f"vLLM version: {vllm.__version__}")
أمثلة على كود بايثون
التعرف الضوئي على الأحرف (OCR) الأساسي باستخدام vLLM
إليك أبسط طريقة لاستخراج النص من صورة مستند:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Initialize the model
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# Load your document image
image = Image.open("document.png").convert("RGB")
# Prepare the prompt - "Free OCR." triggers standard extraction
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# Configure sampling parameters
sampling_params = SamplingParams(
temperature=0.0, # Deterministic for OCR
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # <td>, </td> for tables
},
skip_special_tokens=False,
)
# Generate output
outputs = llm.generate(model_input, sampling_params)
# Extract the markdown text
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
معالجة دفعات من مستندات متعددة
معالجة مستندات متعددة بكفاءة في دفعة واحدة:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""Process multiple images in a single batch."""
# Load all images
images = [Image.open(p).convert("RGB") for p in image_paths]
# Prepare batch input
prompt = "<image>\nFree OCR."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# Generate all outputs in one call
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# Usage
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # First 500 chars
print()
استخدام Transformers مباشرة
للمزيد من التحكم في عملية الاستدلال (inference):
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# Set GPU
device = "cuda:0"
# Load model and tokenizer
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# Load and preprocess image
image = Image.open("document.png").convert("RGB")
# Different prompts for different tasks
prompts = {
"ocr": "<image>\nFree OCR.",
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
"table": "<image>\nExtract all tables as markdown.",
"math": "<image>\nExtract mathematical expressions as LaTeX.",
}
# Process with your chosen prompt
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Add image to inputs (model-specific preprocessing)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
المعالجة غير المتزامنة للإنتاجية العالية
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""Process a single document asynchronously."""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nFree OCR."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# Initialize async engine
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# Process multiple documents concurrently
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: {len(text)} characters extracted")
asyncio.run(main())
استخدام vLLM للإنتاج
بدء تشغيل الخادم المتوافق مع OpenAI
انشر DeepSeek-OCR 2 كخادم API:
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
استدعاء الخادم باستخدام OpenAI SDK
from openai import OpenAI
import base64
# Initialize client pointing to local server
client = OpenAI(
api_key="EMPTY", # Not required for local server
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""Encode image to base64."""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""Extract text from document using OCR API."""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# Usage
result = ocr_document("invoice.png")
print(result)
الاستخدام مع عناوين URL
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
الاختبار باستخدام Apidog
يتطلب اختبار واجهات برمجة تطبيقات OCR بشكل فعال تصور كل من مستندات الإدخال والمخرجات المستخرجة. يوفر Apidog واجهة سهلة الاستخدام لتجربة DeepSeek-OCR 2.
إعداد نقطة نهاية OCR
الخطوة 1: إنشاء طلب جديد
- افتح Apidog وأنشئ مشروعًا جديدًا
- أضف طلب POST إلى
http://localhost:8000/v1/chat/completions
الخطوة 2: تكوين الرؤوس (Headers)
Content-Type: application/json
الخطوة 3: تكوين نص الطلب (Request Body)
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
اختبار أنواع المستندات المختلفة
أنشئ طلبات محفوظة لأنواع المستندات الشائعة:
- استخراج الفواتير - اختبار استخراج البيانات المنظمة
- ورقة أكاديمية - اختبار معالجة معادلات LaTeX
- ملاحظات مكتوبة بخط اليد - اختبار التعرف على خط اليد
- تخطيط متعدد الأعمدة - اختبار استدلال ترتيب القراءة
مقارنة أوضاع الدقة
قم بإعداد متغيرات البيئة لاختبار الأوضاع المختلفة بسرعة:
| الوضع | الدقة | الرموز (Tokens) | حالة الاستخدام |
|---|---|---|---|
tiny | 512×512 | 64 | معاينات سريعة |
small | 640×640 | 100 | مستندات بسيطة |
base | 1024×1024 | 256 | مستندات قياسية |
large | 1280×1280 | 400 | نصوص كثيفة |
gundam | ديناميكي | متغير | تخطيطات معقدة |

أوضاع الدقة والضغط
يدعم DeepSeek-OCR 2 خمسة أوضاع دقة، كل منها مُحسَّن لحالات استخدام مختلفة:
الوضع المصغر (Tiny Mode) (64 رمزًا)
الأفضل لـ: الكشف السريع عن النصوص، النماذج البسيطة، المدخلات منخفضة الدقة
# Configure for tiny mode
os.environ["DEEPSEEK_OCR_MODE"] = "tiny" # 512×512
الوضع الصغير (Small Mode) (100 رمز)
الأفضل لـ: المستندات الرقمية النظيفة، النصوص ذات العمود الواحد
الوضع الأساسي (Base Mode) (256 رمزًا) - الافتراضي
الأفضل لـ: معظم المستندات القياسية، الفواتير، الرسائل
الوضع الكبير (Large Mode) (400 رمز)
الأفضل لـ: الأوراق الأكاديمية الكثيفة، المستندات القانونية
وضع Gundam (ديناميكي)
الأفضل لـ: المستندات المعقدة متعددة الصفحات ذات التخطيطات المتغيرة
# Gundam mode combines multiple views
# - n × 640×640 local tiles for detail
# - 1 × 1024×1024 global view for structure
اختيار الوضع الصحيح
def select_mode(document_type: str, page_count: int) -> str:
"""Select optimal resolution mode based on document characteristics."""
if document_type == "simple_form":
return "tiny"
elif document_type == "digital_document" and page_count == 1:
return "small"
elif document_type == "academic_paper":
return "large"
elif document_type == "mixed_layout" or page_count > 1:
return "gundam"
else:
return "base" # Default
معالجة ملفات PDF والمستندات
تحويل ملفات PDF إلى صور
import fitz # PyMuPDF
from PIL import Image
import io
def pdf_to_images(pdf_path: str, dpi: int = 150) -> list[Image.Image]:
"""Convert PDF pages to PIL Images."""
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc[page_num]
# Render at specified DPI
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
# Convert to PIL Image
img_data = pix.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img)
doc.close()
return images
# Usage
images = pdf_to_images("report.pdf", dpi=200)
print(f"Extracted {len(images)} pages")
خط أنابيب معالجة PDF الكامل
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from pathlib import Path
import fitz
from PIL import Image
import io
class PDFProcessor:
def __init__(self, model_name: str = "deepseek-ai/DeepSeek-OCR-2"):
self.llm = LLM(
model=model_name,
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
self.sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
def process_pdf(self, pdf_path: str, dpi: int = 150) -> str:
"""Process entire PDF and return combined markdown."""
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(len(doc)):
# Convert page to image
page = doc[page_num]
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# OCR the page
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": img}
}]
output = self.llm.generate(model_input, self.sampling_params)
page_text = output[0].outputs[0].text
all_text.append(f"## Page {page_num + 1}\n\n{page_text}")
doc.close()
return "\n\n---\n\n".join(all_text)
# Usage
processor = PDFProcessor()
markdown = processor.process_pdf("annual_report.pdf")
# Save to file
Path("output.md").write_text(markdown)
أداء المعايير
معايير الدقة
| المعيار | DeepSeek-OCR 2 | GOT-OCR2.0 | MinerU2.0 |
|---|---|---|---|
| OmniDocBench | 94.2% | 91.8% | 89.5% |
| الرموز/الصفحة | 100-256 | 256 | 6,000+ |
| Fox (ضغط 10×) | 97% | – | – |
| Fox (ضغط 20×) | 60% | – | – |
أداء الإنتاجية
| العتاد | الصفحات/اليوم | الصفحات/الساعة |
|---|---|---|
| A100-40G (واحدة) | 200,000+ | ~8,300 |
| A100-40G × 20 | 33M+ | ~1.4M |
| RTX 4090 | ~80,000 | ~3,300 |
| RTX 3090 | ~50,000 | ~2,100 |
الدقة في العالم الحقيقي حسب نوع المستند
| نوع المستند | الدقة | ملاحظات |
|---|---|---|
| ملفات PDF الرقمية | 98%+ | أفضل أداء |
| المستندات الممسوحة ضوئيًا | 95%+ | ماسحات ضوئية ذات جودة جيدة |
| التقارير المالية | 92% | جداول معقدة |
| ملاحظات مكتوبة بخط اليد | 85% | يعتمد على وضوح الخط |
| المستندات التاريخية | 80% | جودة متدهورة |
أفضل الممارسات والتحسين
المعالجة المسبقة للصور
from PIL import Image, ImageEnhance, ImageFilter
def preprocess_document(image: Image.Image) -> Image.Image:
"""Preprocess document image for optimal OCR."""
# Convert to RGB if necessary
if image.mode != "RGB":
image = image.convert("RGB")
# Resize if too small (minimum 512px on shortest side)
min_dim = min(image.size)
if min_dim < 512:
scale = 512 / min_dim
new_size = (int(image.width * scale), int(image.height * scale))
image = image.resize(new_size, Image.Resampling.LANCZOS)
# Enhance contrast for scanned documents
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(1.2)
# Sharpen slightly
image = image.filter(ImageFilter.SHARPEN)
return image
هندسة الأوامر (Prompt Engineering)
# Different prompts for different tasks
PROMPTS = {
# Standard OCR - fastest, good for most cases
"ocr": "<image>\nFree OCR.",
# Markdown conversion - better structure preservation
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
# Table extraction - optimized for tabular data
"table": "<image>\nExtract all tables in markdown format.",
# Math extraction - for academic/scientific documents
"math": "<image>\nExtract all text and mathematical expressions. Use LaTeX for math.",
# Specific fields - for form extraction
"fields": "<image>\nExtract the following fields: name, date, amount, signature.",
}
تحسين الذاكرة
# For limited GPU memory
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
gpu_memory_utilization=0.8, # Leave headroom
max_model_len=8192, # Reduce max context
enable_chunked_prefill=True, # Better memory efficiency
)
استراتيجية المعالجة الدفعية
def optimal_batch_size(gpu_memory_gb: int, avg_image_size: tuple) -> int:
"""Calculate optimal batch size based on GPU memory."""
# Approximate memory per image (in GB)
pixels = avg_image_size[0] * avg_image_size[1]
mem_per_image = (pixels * 4) / (1024**3) # 4 bytes per pixel
# Reserve 60% of GPU memory for model
available = gpu_memory_gb * 0.4
return max(1, int(available / mem_per_image))
# Example: A100-40G with 1024x1024 images
batch_size = optimal_batch_size(40, (1024, 1024))
print(f"Recommended batch size: {batch_size}") # ~10
استكشاف المشكلات الشائعة وإصلاحها
أخطاء نفاد الذاكرة
المشكلة: CUDA out of memory (نفاد ذاكرة CUDA)
الحلول:
# 1. Reduce batch size
sampling_params = SamplingParams(max_tokens=4096) # Reduce from 8192
# 2. Use smaller resolution mode
os.environ["DEEPSEEK_OCR_MODE"] = "small"
# 3. Enable memory optimization
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
gpu_memory_utilization=0.7,
enforce_eager=True, # Disable CUDA graphs
)
ضعف استخراج الجداول
المشكلة: الجداول غير محاذية أو بها خلايا مفقودة
الحلول:
# Ensure whitelist tokens are set
sampling_params = SamplingParams(
extra_args={
"whitelist_token_ids": {128821, 128822}, # Critical for tables
},
)
# Use higher resolution
os.environ["DEEPSEEK_OCR_MODE"] = "large"
بطء الاستدلال
المشكلة: تستغرق المعالجة وقتًا طويلاً جدًا
الحلول:
- استخدم vLLM بدلاً من Transformers (أسرع 2-3 مرات)
- قم بتمكين Flash Attention 2
- استخدم المعالجة الدفعية بدلاً من التسلسلية
- النشر على وحدة معالجة رسومات مزودة بنواة موتر (A100, H100)
مخرجات مشوشة
المشكلة: تحتوي المخرجات على كلام غير مفهوم أو أحرف مكررة
الحلول:
# Ensure logits processor is enabled
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
logits_processors=[NGramPerReqLogitsProcessor], # Required!
)
# Use temperature=0 for deterministic output
sampling_params = SamplingParams(temperature=0.0)
هل أنت مستعد لاستخراج النصوص من مستنداتك؟ قم بتنزيل Apidog لاختبار استدعاءات API لـ DeepSeek-OCR 2 بواجهة مرئية، ثم انشر بثقة باستخدام أنماط الإنتاج المذكورة في هذا الدليل.