تمثل تقنية استنساخ الصوت أحد أهم التطورات في تطوير التطبيقات الحديثة. يمتلك المطورون الآن القدرة على دمج أصوات اصطناعية واقعية للغاية ومعبرة عاطفيًا في تطبيقاتهم دون الحاجة إلى أشهر من جلسات التسجيل الصوتي. يصبح هذا التحول ممكنًا من خلال واجهات برمجة تطبيقات استنساخ الصوت المتطورة التي تستفيد من خوارزميات التعلم الآلي المتقدمة والشبكات العصبية.
يخلق تقارب واجهات برمجة تطبيقات تحويل النص إلى كلام (TTS) مع واجهات برمجة تطبيقات تحويل الكلام إلى نص (STT) نظامًا بيئيًا شاملاً للتطبيقات التي تدعم الصوت. سواء كنت تبني روبوتات دردشة لخدمة العملاء، أو تنشئ أنظمة سرد للكتب الصوتية، أو تطور تجارب ألعاب تفاعلية، فإن اختيار منصة واجهة برمجة التطبيقات المناسبة يحدد مقاييس نجاحك.
فهم أساسيات تقنية استنساخ الصوت
يعمل استنساخ الصوت على مبدأ مباشر وقوي: تقوم نماذج التعلم الآلي بتحليل عينات الصوت لاستخراج الخصائص الصوتية الفريدة، ثم إعادة إنتاج تلك الخصائص من خلال توليد الكلام الاصطناعي. تتطلب العملية فهم العديد من المكونات الأساسية التي تميز واجهات برمجة تطبيقات استنساخ الصوت المتميزة عن الحلول الأساسية.
تعمل أنظمة استنساخ الصوت الحديثة عبر ثلاث طبقات تشغيل أساسية. أولاً، تلتقط عينات صوتية تحتوي على صفات نغمية محددة، وأنماط لهجة، ونبرات عاطفية. بعد ذلك، تقوم الشبكات العصبية المتقدمة بمعالجة هذه البيانات لتحديد وعزل ميزات الصوت المميزة. أخيرًا، يقوم النموذج المدرب بتوليد كلام جديد مع الحفاظ على جميع خصائص الصوت الأصلية، بما في ذلك أنماط النطق وسرعة التحدث والعمق العاطفي.
1. ElevenLabs: المعيار الصناعي لجودة الصوت الإنجليزية
تحتل ElevenLabs المكانة المهيمنة في واجهات برمجة تطبيقات استنساخ الصوت، وقد رسخت مكانتها كمعيار ذهبي لجودة تركيب الصوت الإنجليزية. تتيح البنية التقنية للمنصة استنساخ الصوت بحد أدنى من بيانات التدريب، حيث تتطلب عادةً من 30 ثانية إلى دقيقتين فقط من عينات الصوت الواضحة.
الميزات التقنية الرئيسية:
- استنساخ صوت فائق السرعة: يولد استنساخًا صوتيًا في غضون ثوانٍ من تحميل الصوت
- أكثر من 300 خيار صوتي جاهز: يوفر أصواتًا جاهزة للاستخدام عبر أكثر من 30 لغة
- التحكم في العاطفة والنبرة: يتيح التعديل الديناميكي لمعايير التعبير الصوتي
- تصميم يركز على API أولاً: يوفر تكاملاً مباشرًا عبر نقاط نهاية REST وخيارات متعددة لحزم تطوير البرامج (SDK)
- دعم WebSocket: يسهل تركيب الكلام المتدفق في الوقت الفعلي للتطبيقات المحادثة
تقدم جودة صوت ElevenLabs نتائج دقيقة للغاية لدرجة أن المستخدمين يبلغون باستمرار أن الكلام الاصطناعي لا يمكن تمييزه تقريبًا عن الأصوات البشرية الطبيعية. لقد وضع هذا المستوى من الدقة معايير صناعية لا يزال المنافسون يسعون لتحقيقها.
هيكل التسعير:
تعمل المنصة على نماذج الاشتراك والدفع حسب الاستخدام. تبدأ الخطط الأساسية بسعر 5 دولارات شهريًا، بينما تصل اشتراكات المستوى الاحترافي إلى 99 دولارًا شهريًا للحصول على ميزات متقدمة بما في ذلك استنساخ الصوت المخصص والوصول ذي الأولوية إلى واجهة برمجة التطبيقات. تستوعب ترتيبات الشركات الاستخدام غير المحدود بـ أسعار مخصصة.
2. Resemble AI: تركيب صوتي على مستوى الشركات بقدرات في الوقت الفعلي
تتميز Resemble AI بتركيزها المتخصص على تحويل الصوت في الوقت الفعلي والتطبيقات التجارية. تقوم المنصة بمعالجة استنساخ الصوت عبر 62 لغة مذهلة، مما يجعلها مناسبة بشكل خاص للتطبيقات الموزعة عالميًا.
القدرات التقنية المميزة:
- تحويل الصوت في الوقت الفعلي: يدعم تحويل الكلام المباشر دون زمن استجابة محسوس
- ضوابط التعبير العاطفي: تضبط بدقة السعادة والحزن والإثارة والحالات العاطفية الإضافية
- إطار عمل التوطين: يتعامل مع خصائص الصوت الخاصة باللغة والحفاظ على اللهجة
- بنية نقطة نهاية API: توفر نقاط نهاية ذات زمن استجابة منخفض ومحسنة لتطبيقات البث
- تدريب النماذج المخصصة: يمكّن عملاء الشركات من تطوير نماذج صوتية خاصة بهم
يثبت تركيز المنصة على التحكم في التعبير العاطفي قيمته بشكل خاص للتطبيقات التي تتطلب تقديمًا صوتيًا دقيقًا. تستفيد روبوتات خدمة العملاء والمساعدون الافتراضيون وشخصيات الألعاب التفاعلية جميعها من هذا التحكم العاطفي الدقيق.
تدرج التسعير:
تنظم Resemble AI أسعارها في مستويات تتراوح من خطط البدء الشهرية بسعر 5 دولارات إلى ترتيبات الشركات التي تكلف 3000 دولار سنويًا. ومن الجدير بالذكر أن خطة الأعمال التي تبدأ بسعر 699 دولارًا شهريًا تفتح إمكانيات استنساخ الصوت المخصص ودعم واجهة برمجة التطبيقات ذي الأولوية.
3. Fish Audio: تركيب صوتي مفتوح المصدر بتحكم متقدم
تمثل Fish Audio نهجًا متطورًا مفتوح المصدر لتركيب الصوت، حيث توفر للمطورين تحكمًا غير مسبوق في توليد الصوت وتخصيصه. تتفوق المنصة للمؤسسات التي تبحث عن حلول مستضافة ذاتيًا، والتحكم الدقيق في معلمات الصوت، والتحرر من قيود الاعتماد على بائع معين.
نقاط قوة المنصة:
- بنية مفتوحة المصدر: توفر رمزًا شفافًا وقابلاً للتعديل مما يتيح تطبيقات مخصصة
- تحكم متقدم في معلمات الصوت: يوفر ضبطًا دقيقًا للنبرة والسرعة والعاطفة والخصائص الصوتية
- نماذج استنساخ صوت متعددة: تدعم أساليب استنساخ متنوعة من عينات بسيطة إلى تدريب شامل
- إمكانية الاستضافة الذاتية: تتيح النشر المحلي للتطبيقات الحساسة للخصوصية
- توسيع فعال من حيث التكلفة: يقلل من التكاليف لكل طلب من خلال البنية التحتية المستضافة ذاتيًا دون زيادة سعر البائع
تجذب قاعدة Fish Audio مفتوحة المصدر بشكل خاص المطورين الذين يبنون حلولًا صوتية خاصة أو المؤسسات ذات المتطلبات الصارمة لإقامة البيانات. تلغي المنصة تبعيات البائع مع الحفاظ على جودة تركيب الصوت المتطورة.
هيكل تسعير مرن:
تتيح الطبيعة مفتوحة المصدر لـ Fish Audio الاستضافة الذاتية المجانية مع تكاليف البنية التحتية فقط. توفر المتغيرات المستضافة على السحابة تسعيرًا بالدفع حسب الاستخدام يبدأ بأسعار رمزية، بينما تستوعب ترتيبات الشركات مثيلات مخصصة ودعمًا ذا أولوية. تجد المؤسسات التي تعطي الأولوية لفعالية التكلفة على نطاق واسع Fish Audio جذابة بشكل خاص.
4. Tavus: دمج الصوت مع تركيب الفيديو
تحتل Tavus مكانة فريدة من خلال دمج استنساخ الصوت مع توليد الفيديو الواقعي. تنشئ المنصة بشرًا يعملون بالذكاء الاصطناعي ويتحدثون بأصوات مستنسخة مع الحفاظ على تعابير وجه متسقة وتزامن الشفاه.
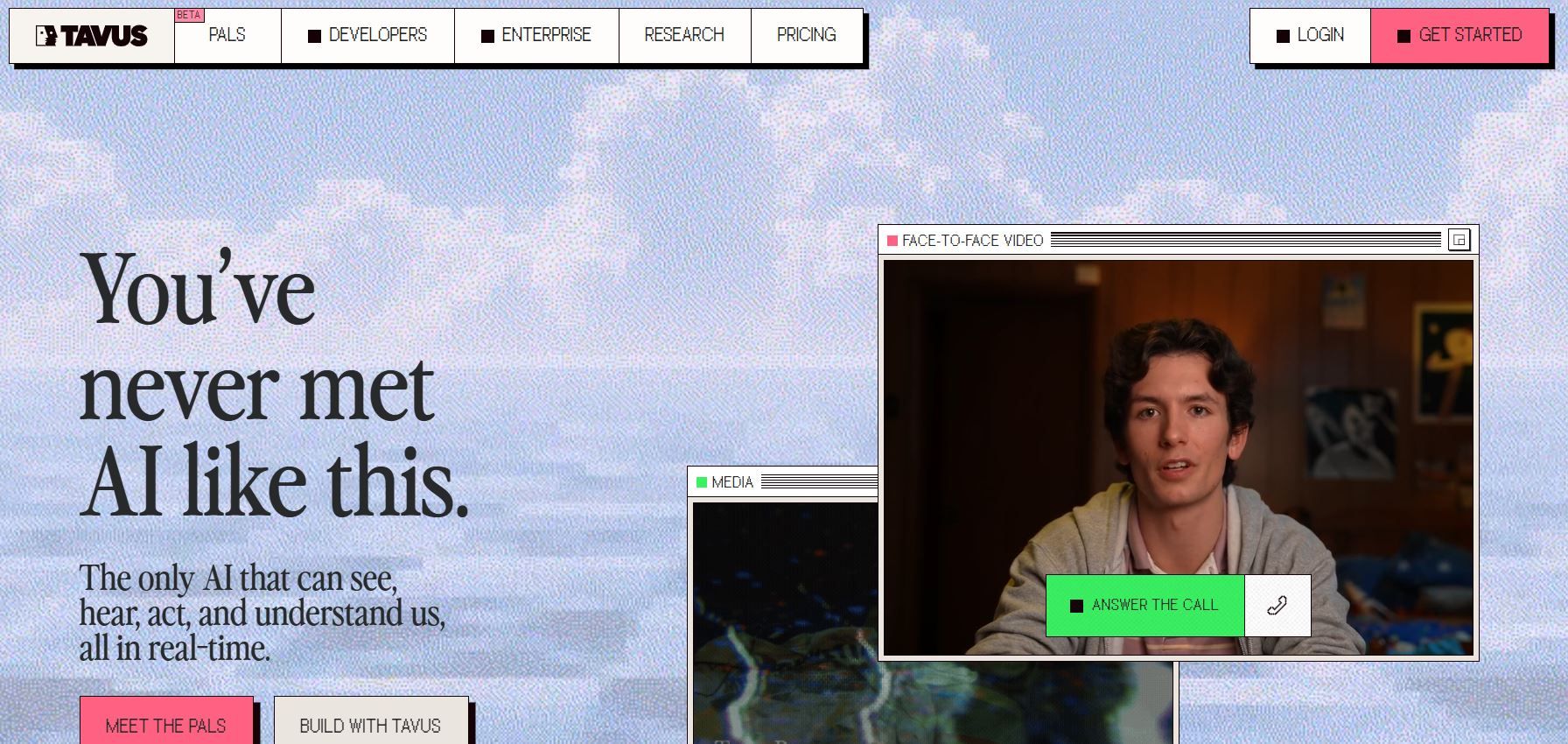
ميزات التكامل الثورية:
- واجهة الفيديو المحادثة (CVI): تتيح تفاعلات وجهًا لوجه في الوقت الفعلي مع صور الأفاتار بالذكاء الاصطناعي
- توليد صور أفاتار واقعية: ينشئ مقاطع فيديو "رؤوس متحدثة" من مدخلات النصوص
- دعم متعدد اللغات: يدعم أكثر من 30 لغة مع مزامنة الشفاه والدبلجة التلقائية
- مزامنة بجودة الاستوديو: يقدم صوتًا بتردد 24 كيلو هرتز بدقة تزامن شفاه مثالية
- التخصيص على نطاق واسع: يولد آلاف مقاطع الفيديو المخصصة مع الحفاظ على تناسق الصوت والمظهر
يثبت هذا الدمج بين تركيب الصوت والفيديو قيمة استثنائية لحملات التسويق، والمحتوى التعليمي، ومنصات مشاركة العملاء. يمكن للمؤسسات تخصيص الرسائل على نطاق واسع مع الحفاظ على تناسق بصري وصوتي كامل.
اعتبارات التكلفة:
يتطلب نموذج التسعير الموجه للشركات عروض أسعار مخصصة. ومع ذلك، فإن قدرة المنصة على توليد آلاف مقاطع الفيديو المخصصة تبرر الاستثمار للمؤسسات ذات احتياجات توزيع المحتوى الكبيرة.
5. Murf AI: توليد صوت احترافي متاح
تركز Murf AI على إمكانية الوصول دون التضحية بالجودة الاحترافية. تجذب المنصة منشئي المحتوى والمعلمين والشركات التي تبحث عن تركيب صوتي مباشر بدون عوائق تقنية باهظة.
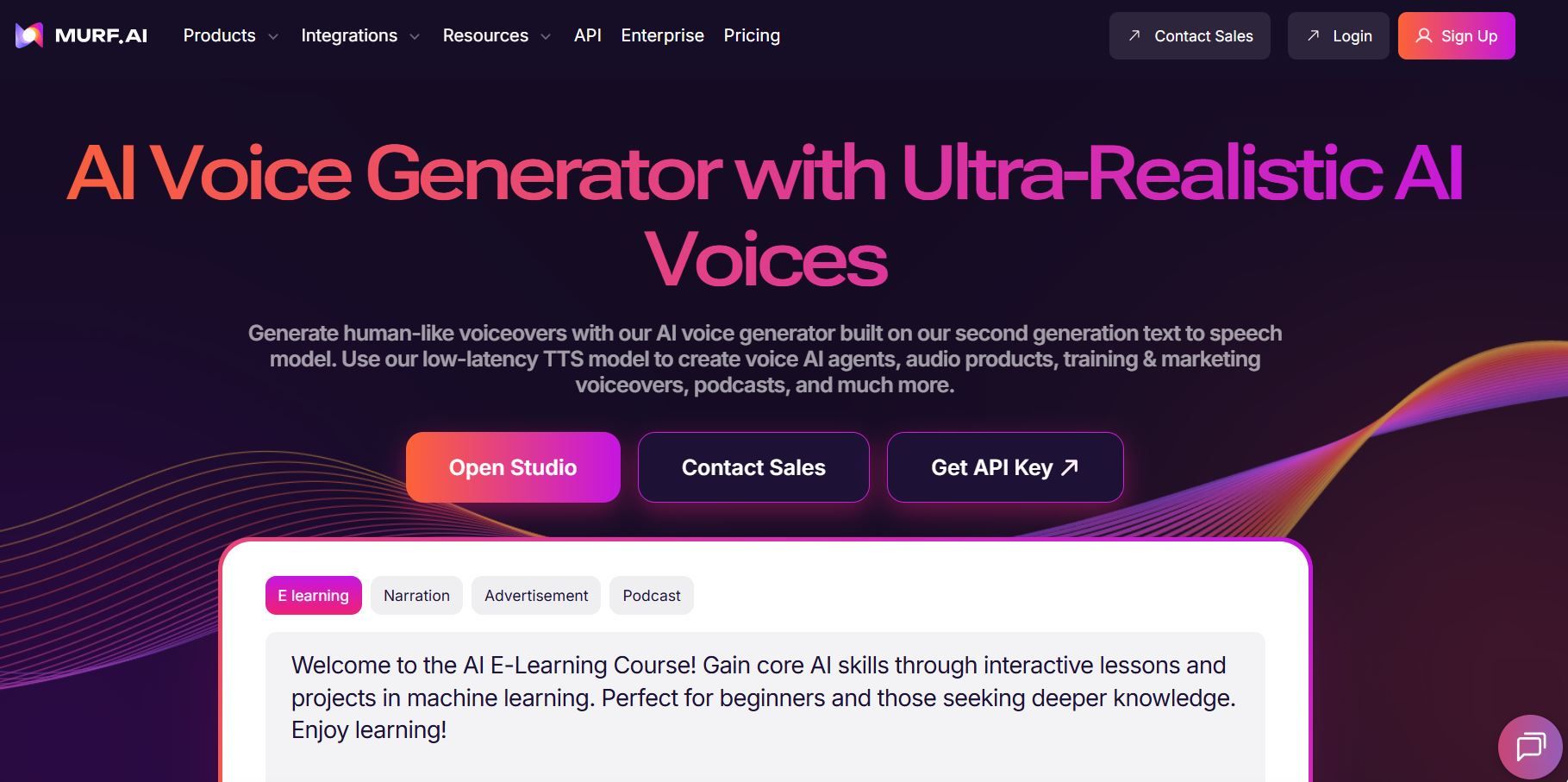
ميزات تركز على إمكانية الوصول:
- واجهة سحب وإفلات: تبسط تركيب الصوت دون متطلبات تقنية مسبقة
- أكثر من 120 صوتًا احترافيًا: توفر خيارات صوتية جاهزة واسعة النطاق
- الأنماط العاطفية: تدعم تعبيرات صوتية متعددة ضمن مشاريع فردية
- سرديات متعددة الأصوات: تتيح إنشاء حوارات تتضمن عدة متحدثين
- حقوق تجارية متضمنة: تسمح بالاستخدام التجاري غير المقيد للمحتوى المُنشأ
تضفي Murf طابعًا ديمقراطيًا على تركيب الصوت من خلال التخلص من التعقيد التقني. يمكن لمنشئي المحتوى التركيز على كتابة النصوص بينما تتولى المنصة توليد الصوت تلقائيًا.
هيكل تسعير شفاف:
توفر الخطة المجانية حوالي 10 دقائق من توليد الصوت شهريًا للاختبار. تبدأ خطط المبدعين بسعر 19 دولارًا شهريًا (الفوترة السنوية) وتوفر ساعتين من التوليد. تصل المستويات الاحترافية إلى 39 دولارًا شهريًا مع الوصول الكامل إلى مكتبة الأصوات والميزات المتقدمة.
تحليل مقارن: اختيار واجهة برمجة تطبيقات استنساخ الصوت المثالية لك
تتفوق كل منصة في سيناريوهات محددة، وتساعد مقارنة قدراتها التقنية في تبسيط عملية الاختيار. يقدم الجدول التالي نظرة عامة مبسطة لكيفية مقارنة واجهات برمجة تطبيقات استنساخ الصوت الخمس هذه بمعايير التقييم الحاسمة:
| ميزة | إلفن لابس | ريسمبل إيه آي | فيش أوديو | تافوس | مرف إيه آي |
|---|---|---|---|---|---|
| جودة الصوت الإنجليزية | الأعلى | ممتاز | ممتاز | مرتفع جدًا | جيد |
| دعم اللغات | 30+ | 62+ | 50+ | 30+ | 70+ |
| البث في الوقت الفعلي | نعم | نعم | نعم | لا | محدود |
| سرعة استنساخ الصوت | 30 ثانية | متفاوت | سريع | دقيقتين | لا |
| التحكم العاطفي | جيد | ممتاز | ممتاز | ممتاز | جيد جدًا |
| دمج الصور الرمزية للفيديو | لا | لا | لا | نعم | لا |
| السعر المبدئي | 5 دولارات/شهريًا | 5 دولارات/شهريًا | مجاني (مستضاف ذاتيًا) | مخصص | مجاني |
| أفضل حالة استخدام | جودة اللغة الإنجليزية | للشركات | يركز على المطورين | محتوى الفيديو | منشئي المحتوى |
معايير الاختيار الاستراتيجية
لأقصى جودة صوت إنجليزية: تحتل ElevenLabs مكانة مميزة عندما تكون دقة الصوت الإنجليزي هي العامل الحاسم في نجاح التطبيق. إذا كان سوقك المستهدف يتحدث الإنجليزية حصريًا وأصبحت طبيعية الصوت غير قابلة للتفاوض، فإن ElevenLabs تقدم أعلى مستوى من الاتساق والأصالة العاطفية مقارنة بالمنصات المنافسة.
للتطبيقات المحادثة في الوقت الفعلي: تدعم كل من Resemble AI و Fish Audio بنية البث الأساسية للتجارب المحادثة. يجب أن تعطي التطبيقات التي تتطلب زمن استجابة أقل من 100 مللي ثانية الأولوية لهذه المنصات، حيث تلغي تطبيقاتها التأخيرات الملحوظة بين إدخال النص وإخراج الصوت.
لعمليات النشر التي يتحكم فيها المطورون: تجذب قاعدة Fish Audio مفتوحة المصدر فرق التطوير التي تسعى إلى التحكم الكامل في مسارات تركيب الصوت. يلغي النشر المستضاف ذاتيًا تبعيات البائع، ويقلل من تكاليف كل طلب على نطاق واسع، ويسمح بتخصيصات خاصة مستحيلة مع المنافسين مفتوحي المصدر.
للتطبيقات التي تركز على الفيديو: تتفرد Tavus بدمج استنساخ الصوت مع توليد الصور الرمزية الواقعية. يجب على المؤسسات التي تنشئ حملات فيديو مخصصة، أو محتوى تعليميًا تفاعليًا، أو صورًا رمزية لخدمة العملاء نابضة بالحياة، تقييم Tavus حصريًا، حيث لا توجد منصة أخرى تقدم قدرات متكاملة مماثلة.
للفرق غير التقنية: تجعل واجهة Murf AI التي تعمل بالسحب والإفلات والمتطلبات التقنية الدنيا منها خيارًا مثاليًا لفرق التسويق ومنشئي المحتوى والمؤسسات التي تفتقر إلى موارد تطوير مخصصة. تتنازل المنصة عن بعض التخصيصات المتقدمة مقابل إمكانية وصول رائعة.
للشركات الناشئة المهتمة بالتكلفة: تقدم كل من ElevenLabs و Resemble AI أسعارًا تنافسية تبدأ من 5 دولارات شهريًا، مما يجعلها نقاط دخول ميسورة التكلفة. يوفر خيار Fish Audio المجاني المستضاف ذاتيًا استخدامًا غير محدود بدون تكاليف اشتراك، على الرغم من تطبيق نفقات البنية التحتية.
التطبيق العملي مع Apidog
يتطلب دمج واجهات برمجة تطبيقات استنساخ الصوت اختبارًا وتحققًا منهجيين. يبسط Apidog هذه العملية عن طريق مركزة اختبار API داخل منصة واحدة.
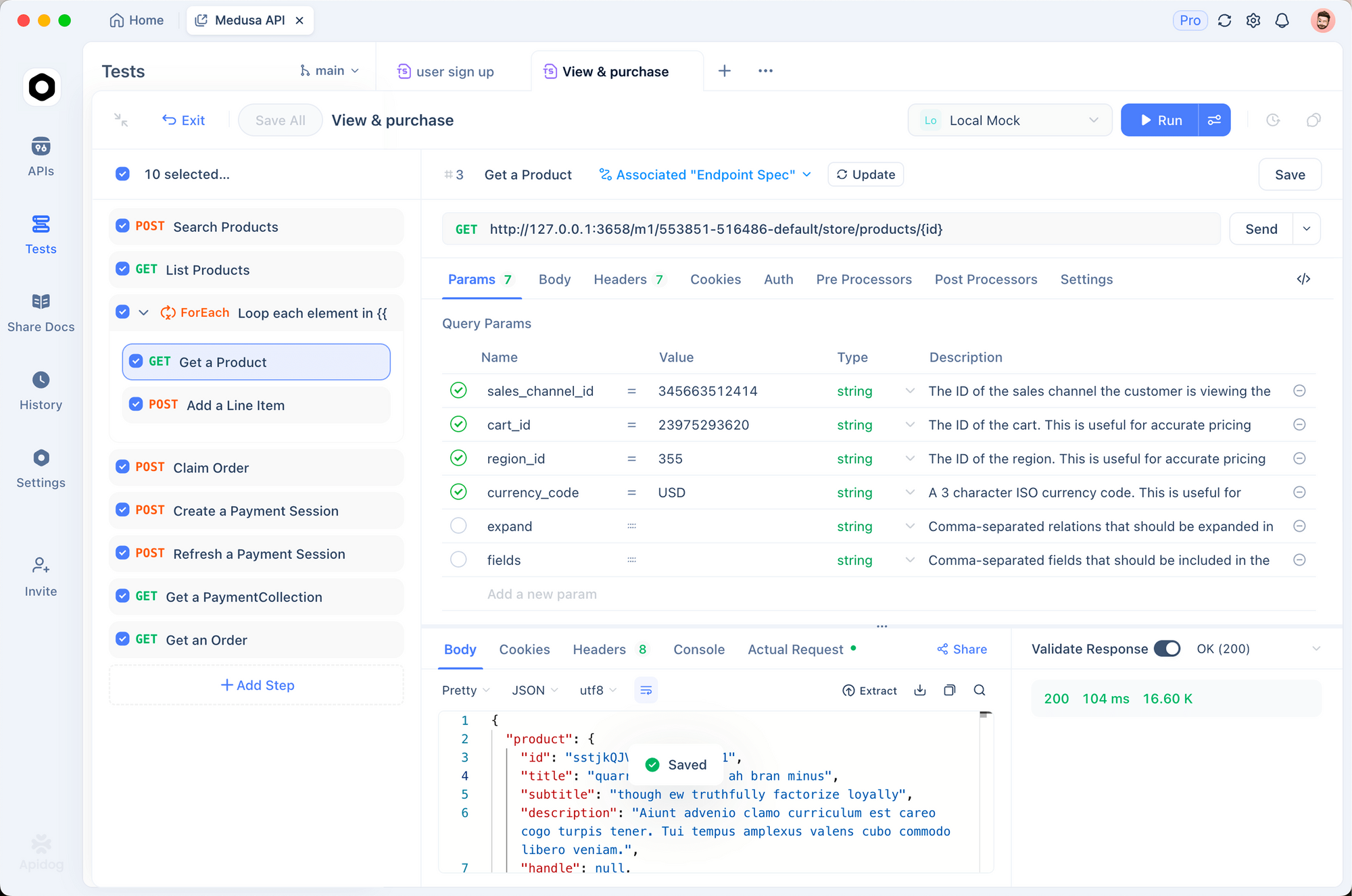
سير عمل التنفيذ:
- تصميم API: استخدم المحرر المرئي لـ Apidog لتوثيق نقاط نهاية واجهة برمجة تطبيقات استنساخ الصوت جنبًا إلى جنب مع عمليات التكامل الأخرى
- إنشاء سيناريوهات الاختبار: قم ببناء سيناريوهات اختبار شاملة للتحقق من جودة تركيب الصوت ومعلمات زمن الاستجابة
- توليد البيانات الوهمية (Mock Data): أنشئ استجابات وهمية واقعية قبل النشر مقابل واجهات برمجة تطبيقات الإنتاج
- الاختبار الآلي: قم بإجراء اختبار تكامل مستمر لضمان بقاء تركيب الصوت متسقًا عبر عمليات النشر
- توليد التوثيق: قم بتوليد توثيق API تلقائيًا لتعاون الفريق
تثبت ميزة إدارة البيئات في Apidog قيمتها بشكل خاص عند الاختبار مقابل واجهات برمجة تطبيقات استنساخ الصوت المتعددة في وقت واحد. يتطلب التبديل بين ElevenLabs و Resemble AI والمنصات الأخرى مجرد تحديد البيئة - لا يلزم إجراء تعديلات على نقاط النهاية.
الخلاصة: اختيار مستقبل تركيب الصوت الخاص بك
انتقلت واجهات برمجة تطبيقات استنساخ الصوت من التقنيات التجريبية إلى مكونات التطوير الأساسية. تمثل المنصات الخمس المفصلة في هذا الدليل أولويات تحسين مختلفة، سواء كانت الجودة، أو إمكانية الوصول، أو دعم اللغات المتعددة، أو تكامل الفيديو، أو المتطلبات التقنية المحددة.
يعتمد نجاح تنفيذك على اختيار المنصة التي تتوافق مع المتطلبات الفريدة لتطبيقك. اختبر خيارات متعددة باستخدام منصات مثل Apidog لتقييم الأداء، وزمن الاستجابة، وجودة الصوت عبر سيناريوهات واقعية.
ابدأ الآن: قم بتنزيل Apidog لتصميم واختبار ودمج واجهات برمجة تطبيقات استنساخ الصوت جنبًا إلى جنب مع نظامك البيئي الأوسع للتطوير. قم بمركزة اختبار واجهة برمجة التطبيقات الخاصة بك بينما يتقدم تنفيذ تركيب الصوت الخاص بك من النموذج الأولي إلى الإنتاج.