
يعيد Tongyi DeepResearch من Alibaba تعريف وكلاء الذكاء الاصطناعي المستقلين بنموذجه "مزيج الخبراء" (MoE) ذي الـ 30 مليار معلمة، والذي يُفعّل 3 مليارات معلمة فقط لكل رمز لتمكين بحث ويب فعال وعالي الدقة. تتفوق هذه القوة المفتوحة المصدر على معايير مثل Humanity's Last Exam (32.9% مقابل 24.9% لـ OpenAI o3) وxbench-DeepSearch (75.0% مقابل 67.0%)، مما يُمكّن المطورين من معالجة الاستعلامات المعقدة متعددة الخطوات—من التحليل القانوني إلى مسارات السفر—دون قيود الملكية.
قام المهندسون في مختبر Tongyi بتصميم هذا الوكيل للتغلب على التفكير طويل الأمد واستخدام الأدوات الديناميكي بشكل مباشر. ونتيجة لذلك، فإنه يتفوق على النماذج المغلقة في التوليف الواقعي، كل ذلك أثناء تشغيله محليًا عبر Hugging Face. في هذا التحليل الفني، نقوم بتشريح بنيته المتفرقة، وخط أنابيب البيانات الآلي، والتدريب المحسن بالتعلم المعزز (RL)، وهيمنته على المعايير، واختراقات النشر. بحلول النهاية، سترى كيف يفتح Tongyi DeepResearch—وأدوات مثل Apidog—الذكاء الاصطناعي الوكيلي القابل للتطوير لمشاريعك.
فهم Tongyi DeepResearch: المفاهيم الأساسية والابتكارات
يعيد Tongyi DeepResearch تعريف الذكاء الاصطناعي الوكيلي من خلال التركيز على استرجاع المعلومات العميقة وتوليفها. على عكس نماذج اللغة الكبيرة التقليدية (LLMs) التي تتفوق في التوليد قصير المدى، يتنقل هذا الوكيل في بيئات ديناميكية مثل متصفحات الويب للكشف عن رؤى دقيقة. على وجه التحديد، يستخدم بنية "مزيج الخبراء" (MoE)، حيث يتم تنشيط 30 مليار معلمة بالكامل بشكل انتقائي إلى 3 مليارات معلمة فقط لكل رمز. تتيح هذه الكفاءة أداءً قويًا على الأجهزة ذات الموارد المحدودة مع الحفاظ على وعي سياقي عالٍ يصل إلى 128 ألف رمز.
علاوة على ذلك، يتكامل النموذج بسلاسة مع نماذج الاستدلال التي تحاكي اتخاذ القرار الشبيه بالبشر. في وضع ReAct، يتنقل عبر خطوات التفكير والعمل والملاحظة بشكل طبيعي، متجاوزًا هندسة المطالبات المعقدة. للمهام الأكثر تطلبًا، يقوم الوضع الثقيل (Heavy mode) بتنشيط إطار عمل IterResearch، الذي ينسق استكشافات الوكلاء المتوازية لتجنب التحميل الزائد للسياق. ونتيجة لذلك، يحقق المستخدمون نتائج متفوقة في السيناريوهات التي تتطلب تحسينًا تكراريًا، مثل مراجعات الأدبيات الأكاديمية أو تحليل السوق.
ما يميز Tongyi DeepResearch هو التزامه بالانفتاح. يتوفر المكدس بأكمله—من أوزان النموذج إلى كود التدريب—على منصات مثل Hugging Face و GitHub. يمكن للمطورين الوصول مباشرة إلى نسخة Tongyi-DeepResearch-30B-A3B، مما يسهل الضبط الدقيق للاحتياجات الخاصة بالمجال. بالإضافة إلى ذلك، فإن توافقه مع بيئات Python القياسية يقلل من حاجز الدخول. على سبيل المثال، يتضمن التثبيت أمر pip بسيطًا بعد إعداد بيئة Conda باستخدام Python 3.10.
بالانتقال إلى الفائدة العملية، يدعم Tongyi DeepResearch التطبيقات التي تتطلب مخرجات قابلة للتحقق. في البحث القانوني، يقوم بتحليل القوانين والسوابق القضائية، مع ذكر المصادر بدقة. وبالمثل، في تخطيط السفر، يقوم بإنشاء مسارات متعددة الأيام عن طريق الرجوع إلى البيانات في الوقت الفعلي. تنبع هذه الإمكانيات من فلسفة تصميم مدروسة: إعطاء الأولوية للتفكير الوكيلي على مجرد التنبؤ.
هندسة Tongyi DeepResearch: الكفاءة تلتقي بالقوة
في جوهره، يستفيد Tongyi DeepResearch من تصميم MoE المتفرق لموازنة المتطلبات الحسابية مع القوة التعبيرية. يقوم النموذج بتنشيط مجموعة فرعية فقط من الخبراء لكل رمز، ويوجه المدخلات ديناميكيًا بناءً على تعقيد الاستعلام. يقلل هذا النهج زمن الاستجابة بنسبة تصل إلى 90% مقارنة بالنظراء الكثيفة، مما يجعله قابلاً للتطبيق لعمليات نشر الوكلاء في الوقت الفعلي. علاوة على ذلك، تدعم نافذة السياق البالغة 128 ألفًا التفاعلات الموسعة، وهو أمر بالغ الأهمية للمهام التي تتضمن سلاسل مستندات طويلة أو عمليات بحث ويب مترابطة.
تشمل المكونات المعمارية الرئيسية مُرمّزًا مخصصًا مُحسَّنًا لرموز الوكلاء—مثل بادئات الإجراءات ومحددات الملاحظة—ومجموعة أدوات مدمجة للتنقل في المتصفح والاسترجاع والحساب. يدعم الإطار تكامل التعلم المعزز على السياسة (RL)، حيث يتعلم الوكلاء من عمليات المحاكاة في بيئة مستقرة. ونتيجة لذلك، يُظهر النموذج عددًا أقل من الهلوسات في استدعاءات الأدوات، كما يتضح من درجاته العالية في معايير استخدام الأدوات.
بالإضافة إلى ذلك، يدمج Tongyi DeepResearch ذاكرة معرفية مثبتة بالكيانات، مشتقة من توليف البيانات القائم على الرسوم البيانية. تثبت هذه الآلية الاستجابات بالكيانات الواقعية، مما يعزز إمكانية التتبع. على سبيل المثال، أثناء استعلام حول التطورات في الحوسبة الكمومية، يسترجع الوكيل ويولف الأوراق عبر أدوات شبيهة بـ WebSailor، مما يرسخ المخرجات في مصادر قابلة للتحقق. وبالتالي، فإن البنية لا تعالج المعلومات فحسب، بل تقوم بتنظيمها بنشاط.
للتوضيح، فكر في كيفية تعامل النموذج مع المدخلات متعددة الوسائط. على الرغم من أنه يعتمد بشكل أساسي على النصوص، إلا أن الإضافات عبر مستودع GitHub تسمح بالتكامل مع محللات الصور أو منفذي التعليمات البرمجية. يقوم المطورون بتكوين هذه في برنامج الاستدلال، وتحديد مسارات لمجموعات البيانات بتنسيق JSONL. على هذا النحو، تعزز البنية قابلية التوسع، وتدعو إلى مساهمات من مجتمع المصادر المفتوحة.
توليف البيانات الآلي: تعزيز قدرات Tongyi DeepResearch
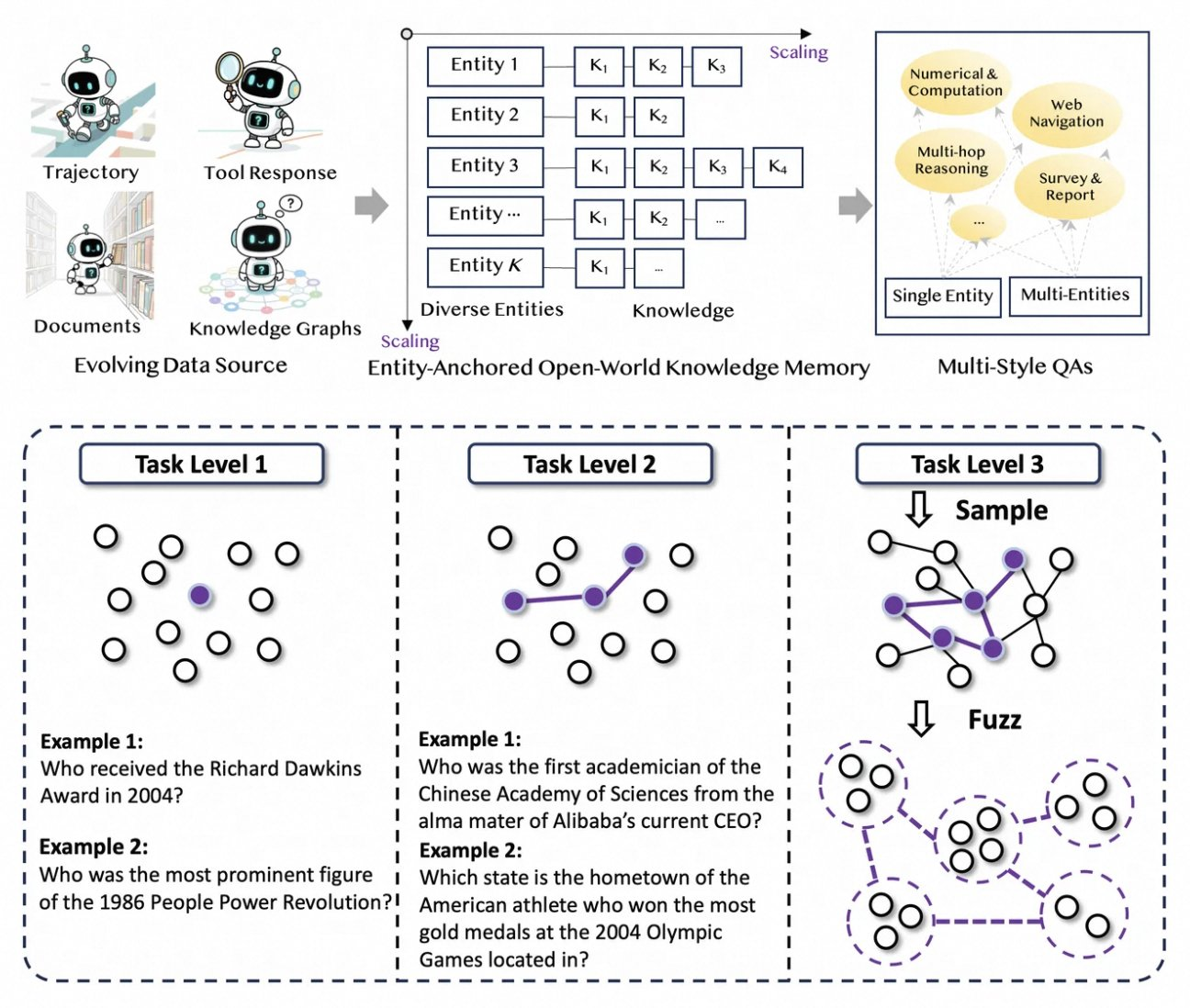
يزدهر Tongyi DeepResearch بفضل خط أنابيب بيانات جديد ومؤتمت بالكامل يلغي اختناقات التعليقات التوضيحية البشرية. تبدأ العملية بـ AgentFounder، وهو محرك توليف يعيد تنظيم مجموعات البيانات الخام—المستندات، وزحف الويب، والرسوم البيانية المعرفية—إلى أزواج أسئلة وأجوبة مثبتة بالكيانات. تولد هذه الخطوة مسارات متنوعة للتدريب المسبق المستمر (CPT)، وتغطي سلاسل التفكير، واستدعاءات الأدوات، وأشجار القرار.
بعد ذلك، يزيد خط الأنابيب من الصعوبة من خلال الترقيات التكرارية. للتدريب اللاحق، يستخدم طرقًا قائمة على الرسوم البيانية مثل WebSailor-V2 لمحاكاة تحديات "فوق بشرية"، مثل أسئلة مستوى الدكتوراه المصممة عبر نظرية المجموعات. ونتيجة لذلك، تمتد مجموعة البيانات إلى ملايين التفاعلات عالية الدقة، مما يضمن تعميم النموذج عبر المجالات. ومن الجدير بالذكر أن هذا التشغيل الآلي يتوسع خطيًا مع الحوسبة، مما يسمح بتحديثات مستمرة دون تنسيق يدوي.
علاوة على ذلك، يدمج Tongyi DeepResearch بيانات متعددة الأنماط لتعزيز المتانة. تسجل سجلات توليف الإجراءات أنماط استخدام الأدوات، بينما تعمل أزواج الأسئلة والأجوبة متعددة المراحل على تحسين مهارات التخطيط. من الناحية العملية، ينتج عن ذلك وكلاء يتكيفون مع بيئات الويب الصاخبة، ويقومون بتصفية المقتطفات غير ذات الصلة بفعالية. بالنسبة للمطورين، يوفر المستودع نصوصًا برمجية لتكرار خط الأنابيب هذا، مما يتيح إنشاء مجموعات بيانات مخصصة.
من خلال إعطاء الأولوية للجودة على الكمية، تعالج استراتيجية التوليف المزالق الشائعة في تدريب الوكلاء، مثل التحولات التوزيعية. ونتيجة لذلك، تُظهر النماذج المدربة بهذه الطريقة توافقًا فائقًا مع مهام العالم الحقيقي، كما يتضح من هيمنتها على المعايير.
خط أنابيب التدريب الشامل: من CPT إلى تحسين RL
يتكشف تدريب Tongyi DeepResearch في خط أنابيب سلس: CPT الوكيلي، والضبط الدقيق الخاضع للإشراف (SFT)، والتعلم المعزز (RL). أولاً، يعرض CPT النموذج الأساسي لبيانات وكيلية واسعة، مما يغرس فيه أولويات التنقل عبر الويب وإشارات الحداثة. تنشط هذه المرحلة القدرات الكامنة، مثل التخطيط الضمني، من خلال نمذجة اللغة المقنعة على المسارات.

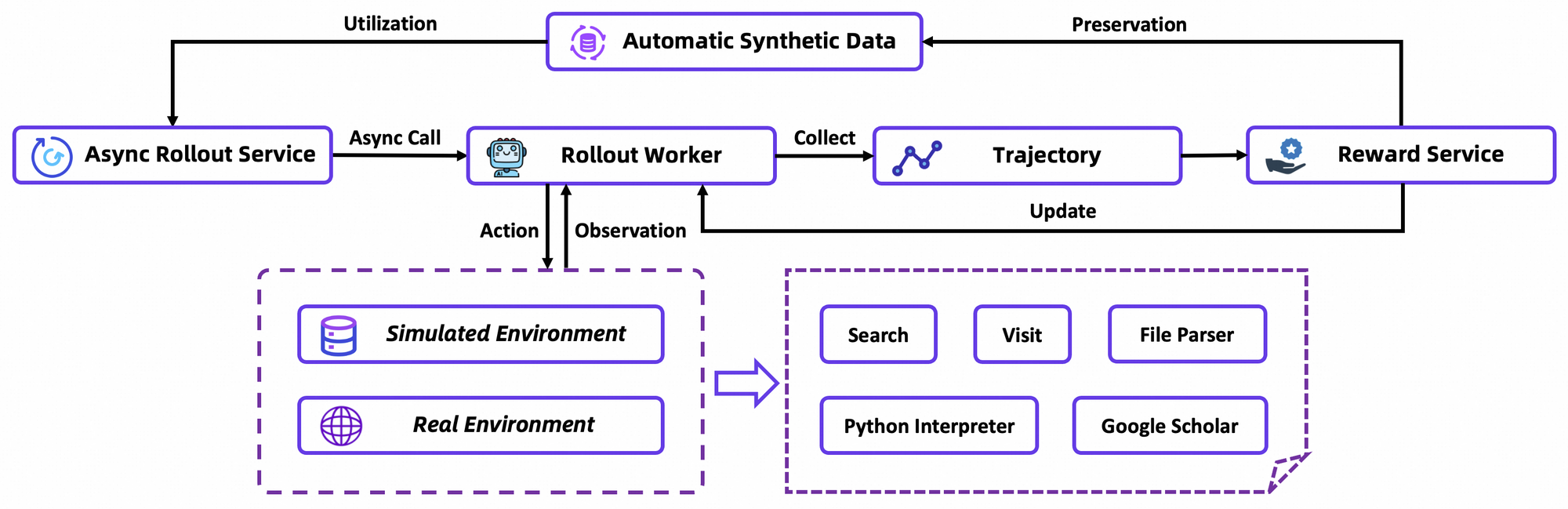
بعد CPT، يقوم SFT بمواءمة النموذج مع التنسيقات التعليمية، باستخدام عمليات المحاكاة الاصطناعية لتعليم صياغة الإجراءات الدقيقة. هنا، يتعلم النموذج توليد دورات ReAct متماسكة، مما يقلل الأخطاء في تحليل الملاحظات. بالانتقال بسلاسة، تستخدم مرحلة RL خوارزمية Group Relative Policy Optimization (GRPO)، وهي خوارزمية مخصصة على السياسة.
تحسب GRPO تدرجات السياسة على مستوى الرمز مع تقدير ميزة "ترك واحد خارجًا" (leave-one-out)، مما يقلل التباين في الإعدادات غير المستقرة. كما تقوم بتصفية العينات السلبية بشكل متحفظ، مما يثبت التحديثات في المحاكي المخصص—قاعدة بيانات ويكيبيديا غير متصلة بالإنترنت مقترنة بصندوق أدوات. تسرع عمليات المحاكاة غير المتزامنة عبر إطار عمل rLLM التقارب، وتحقق أحدث النتائج بأقل قدر من الحوسبة.
بالتفصيل، تحاكي بيئة RL تفاعلات المتصفح بأمانة، وتكافئ النجاح متعدد الخطوات على الإجراءات الفردية. يعزز هذا التخطيط طويل الأمد، حيث يقوم الوكلاء بالتكرار على الإخفاقات الجزئية. كملاحظة فنية، تتضمن دالة الخسارة تباعد KL للتحفظ، مما يمنع انهيار الوضع. يقوم المطورون بتكرار هذا عبر نصوص التقييم الخاصة بالمستودع، وقياس السياسات المخصصة.
بشكل عام، يمثل خط الأنابيب هذا إنجازًا: فهو يربط التدريب المسبق بالنشر دون عزل، مما ينتج عنه وكلاء يتطورون من خلال التجربة والخطأ.
أداء المعايير: كيف يتفوق Tongyi DeepResearch
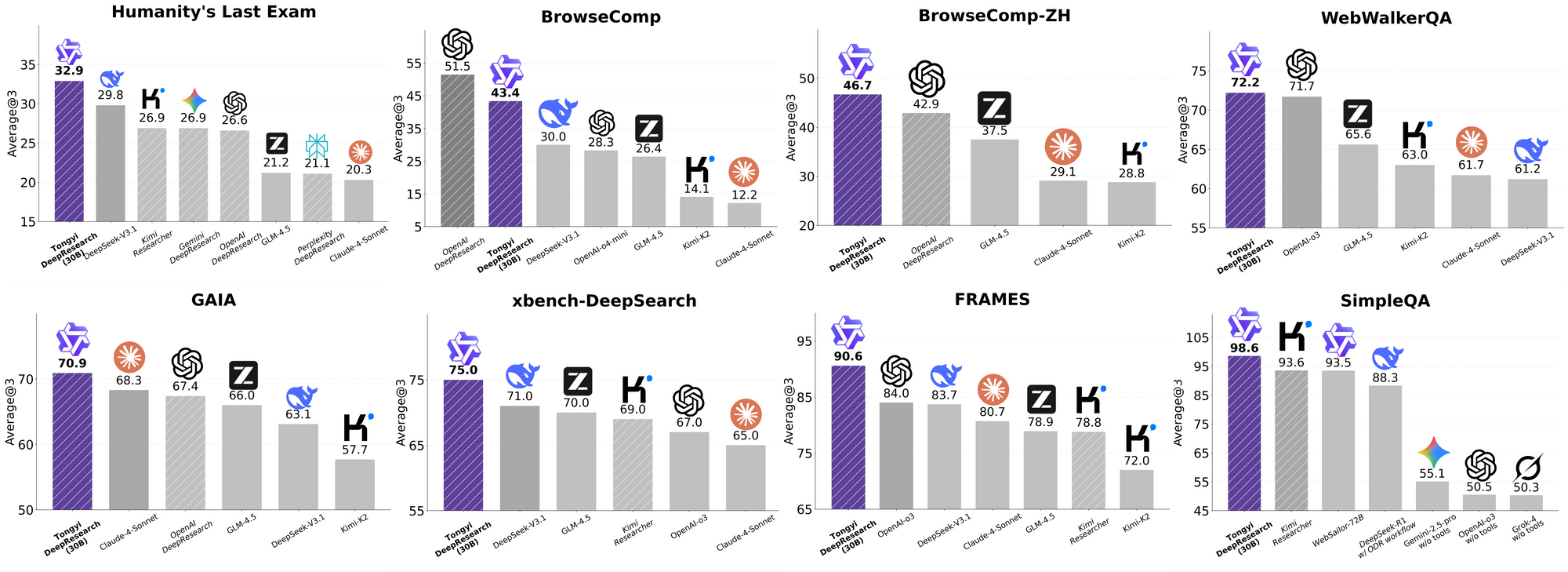
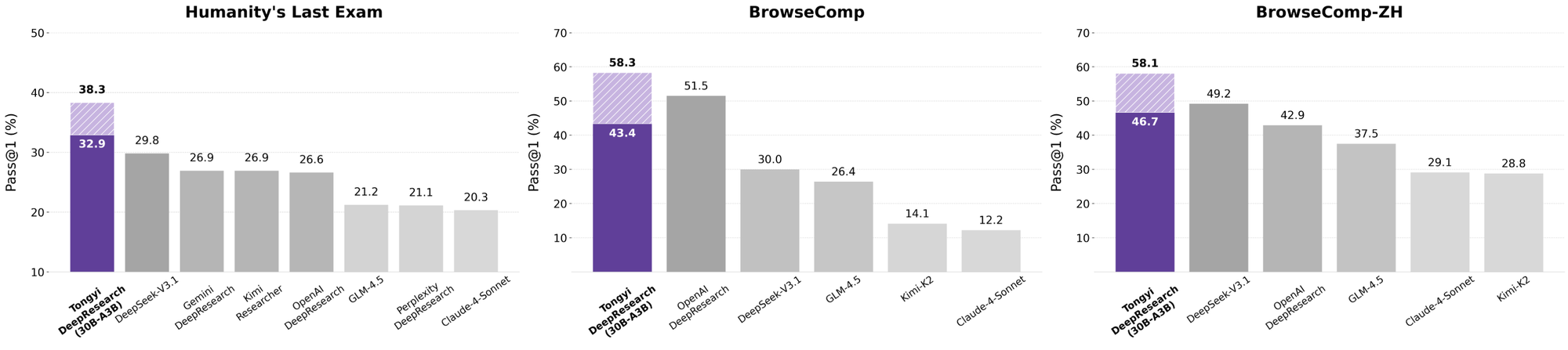
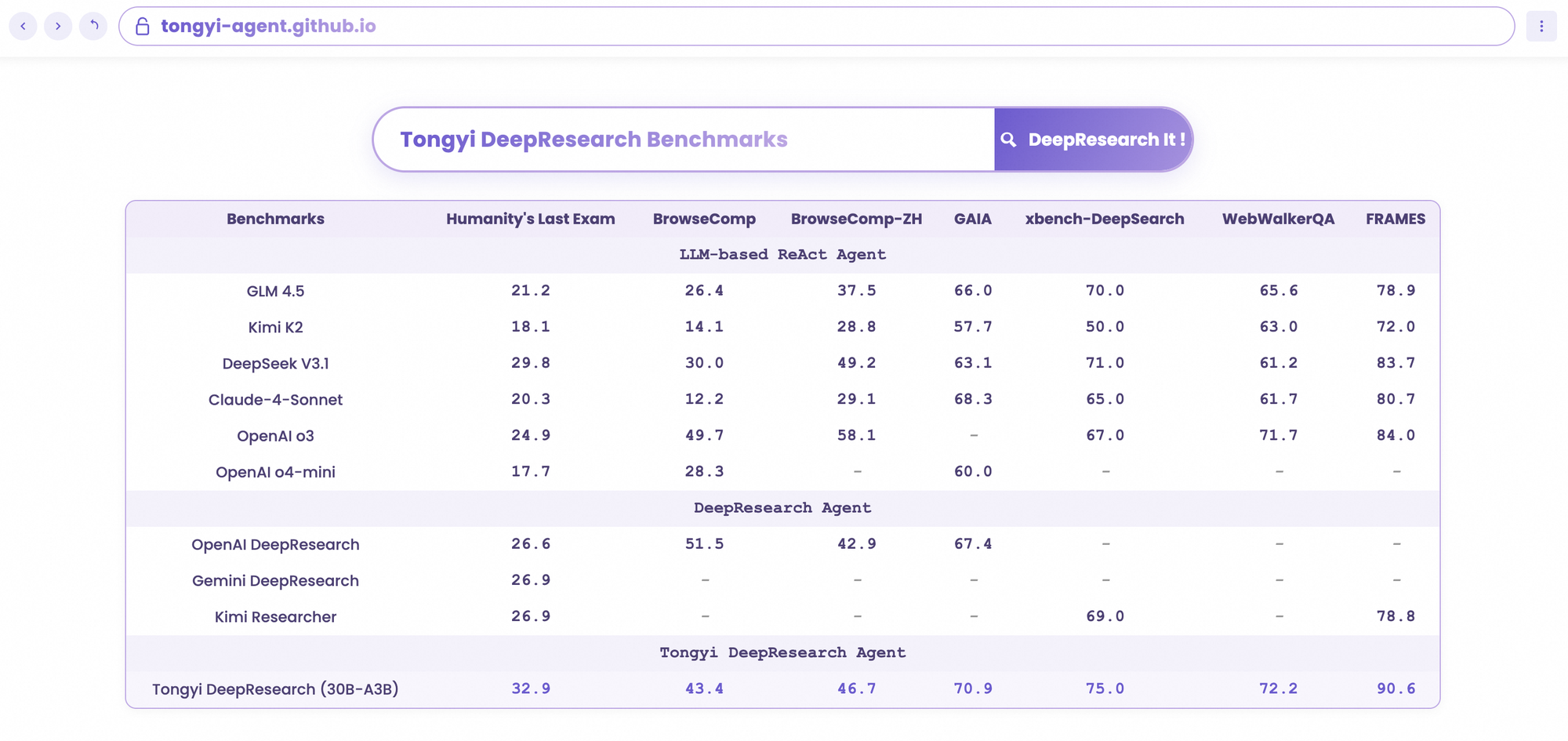
يتألق Tongyi DeepResearch في معايير الوكلاء الصارمة، مما يؤكد تصميمه. في اختبار Humanity's Last Exam (HLE)، وهو اختبار للتفكير الأكاديمي، يحقق 32.9 في وضع ReAct—متجاوزًا OpenAI o3 بنتيجة 24.9. يتسع هذا الفارق في الوضع الثقيل (Heavy mode) إلى 38.3، مما يسلط الضوء على فعالية IterResearch.
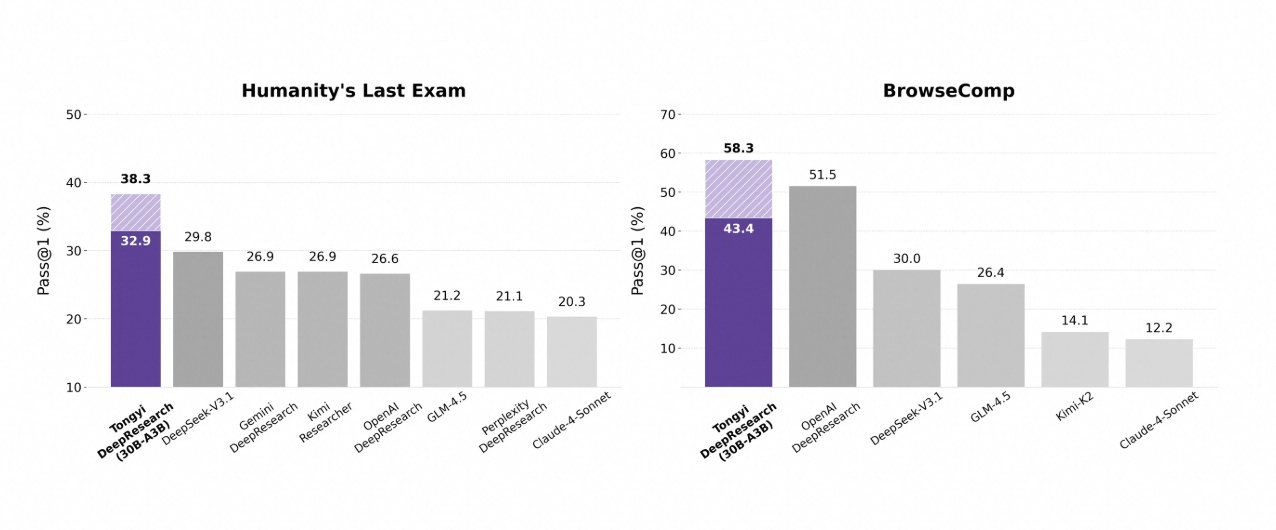
وبالمثل، يقيم BrowseComp البحث المعقد عن المعلومات؛ يحقق Tongyi 43.4 (EN) و 46.7 (ZH)، متفوقًا على o3 بنتيجة 49.7 و 58.1 على التوالي في الكفاءة. يشهد معيار xbench-DeepSearch، الموجه للمستخدم للاستعلامات العميقة، Tongyi عند 75.0 مقابل 67.0 لـ o3، مما يؤكد تفوق توليف الاسترجاع.
تعزز المقاييس الأخرى هذا: FRAMES عند 90.6 (مقابل 84.0 لـ o3)، GAIA عند 70.9، و SimpleQA عند 95.0. يوضح مخطط مقارن هذه النتائج، مع أعمدة لـ Tongyi DeepResearch تتفوق على Gemini و Claude وغيرها عبر HLE و BrowseComp و xbench و FRAMES والمزيد. تشير الأعمدة الزرقاء إلى تقدم Tongyi، بينما تظهر الخطوط الأساسية الرمادية أوجه القصور لدى المنافسين.
تنبع هذه النتائج من تحسينات مستهدفة، مثل التوجيه الانتقائي للخبراء لمهام البحث. وبالتالي، فإن Tongyi DeepResearch لا ينافس فحسب، بل يقود في مجال الوكلاء مفتوح المصدر.
مقارنة Tongyi DeepResearch بقادة الصناعة
عندما يقوم المطورون بتقييم وكلاء الذكاء الاصطناعي، تكشف المقارنات عن القيمة الحقيقية. يتفوق Tongyi DeepResearch، بنسخته 30B-A3B، على OpenAI o3 في HLE (32.9 مقابل 24.9) و xbench (75.0 مقابل 67.0)، على الرغم من حجم o3 الأكبر. ضد Gemini من Google، يدعي 35.2 في BrowseComp-ZH، بفارق 10 نقاط.
تتأخر النماذج الاحتكارية مثل Claude 3.5 Sonnet في استخدام الأدوات؛ 90.6 لـ Tongyi في FRAMES تتجاوز 84.3 لـ Sonnet. يتأخر نظراء المصادر المفتوحة، مثل متغيرات Llama، بشكل أكبر—على سبيل المثال، 21.1 في HLE. تتيح ندرة MoE في Tongyi هذا التكافؤ، وتستهلك حوسبة استدلال أقل.
علاوة على ذلك، فإن إمكانية الوصول ترجح الكفة: بينما يتطلب o3 أرصدة API، يعمل Tongyi محليًا عبر Hugging Face. لسير العمل الكثيف لواجهة برمجة التطبيقات، قم بإقرانه بـ Apidog لمحاكاة نقاط النهاية، ومحاكاة استدعاءات الأدوات بكفاءة.
في جوهره، يضفي Tongyi DeepResearch الطابع الديمقراطي على الأداء النخبوي، متحديًا النظم البيئية المغلقة.
تطبيقات العالم الحقيقي: Tongyi DeepResearch في العمل
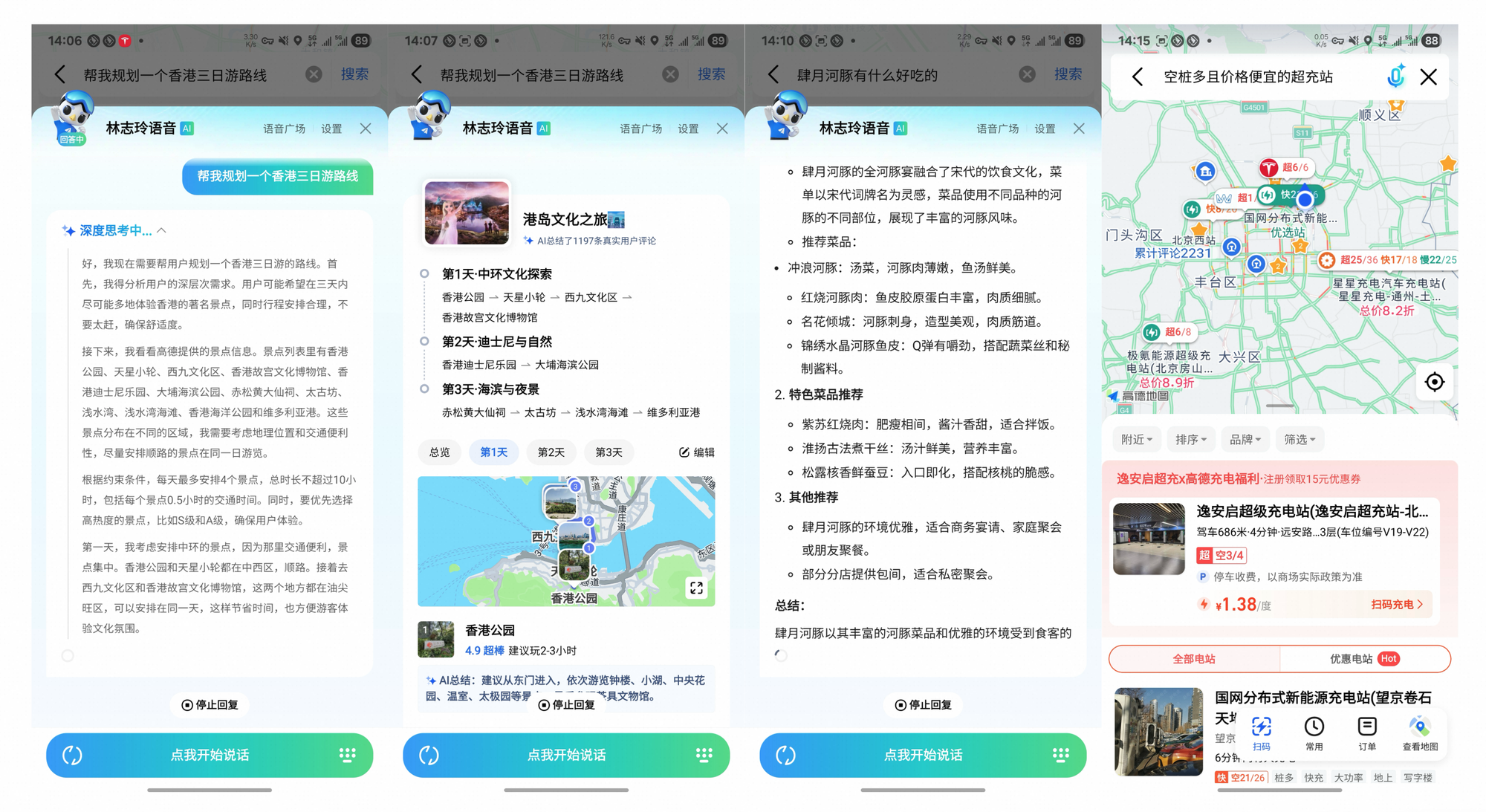
يتجاوز Tongyi DeepResearch المعايير، ويحقق تأثيرًا ملموسًا. في Gaode Mate، تطبيق الملاحة من Alibaba، يخطط لرحلات معقدة—يستعلم عن الرحلات الجوية والفنادق والفعاليات بالتوازي عبر الوضع الثقيل (Heavy mode). يتلقى المستخدمون مسارات رحلات مُولّفة مع مراجع، مما يقلل وقت التخطيط بنسبة 70%.
وبالمثل، يحدث Tongyi FaRui ثورة في البحث القانوني. يقوم الوكيل بتحليل القوانين، والرجوع إلى السوابق، وتوليد ملخصات بروابط قابلة للتحقق. يتحقق المحترفون من المخرجات بسرعة، مما يقلل الأخطاء في المجالات عالية المخاطر.
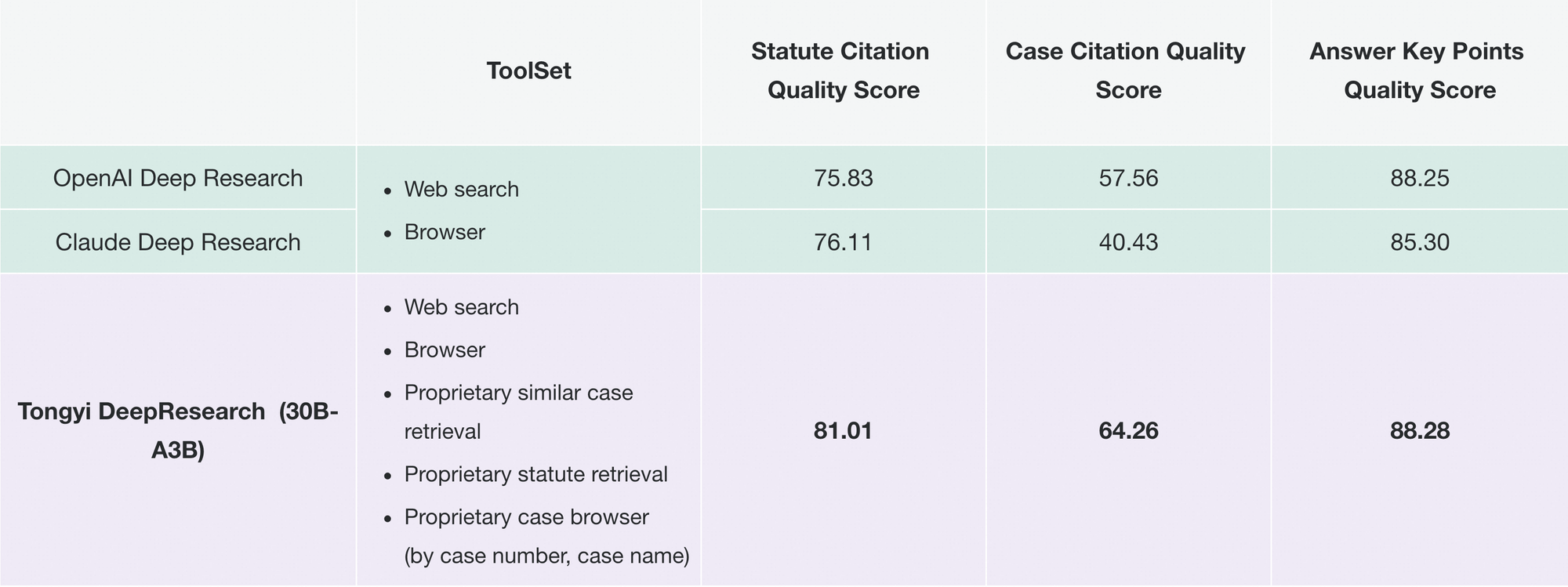
بالإضافة إلى ذلك، تقوم الشركات بتكييفه لاستخبارات السوق: جمع بيانات المنافسين، وتوليف الاتجاهات. تدعم نمطية المستودع هذه التوسعات—أضف أدوات مخصصة عبر تكوينات JSON.
مع تزايد الاعتماد، يتكامل Tongyi DeepResearch في أنظمة بيئية مثل LangChain، مما يعزز أسراب الوكلاء. لمطوري واجهة برمجة التطبيقات، يكمل Apidog هذا من خلال التحقق من صحة التكاملات قبل النشر.
توضح هذه الحالات قابلية التوسع: من تطبيقات المستهلك إلى أدوات الشركات، يقدم النموذج استقلالية موثوقة.
البدء مع Tongyi DeepResearch: دليل المطورين
نفّذ Tongyi DeepResearch بسهولة باستخدام مستودع GitHub الخاص به. ابدأ بإنشاء بيئة Conda: conda create -n deepresearch python=3.10. ثم قم بتنشيطها وتثبيت المتطلبات: pip install -r requirements.txt.
جهز البيانات في eval_data/ بتنسيق JSONL، مع مفاتيح question و answer. للملفات، أضف الأسماء إلى بداية الأسئلة وخزنها في file_corpus/. عدّل run_react_infer.sh لمسار النموذج (مثل عنوان URL لـ Hugging Face) ومفاتيح API للأدوات.
شغّل: bash run_react_infer.sh. ستظهر المخرجات في المسارات المحددة، جاهزة للتحليل.
بالنسبة للوضع الثقيل (Heavy mode)، قم بتكوين معلمات IterResearch في الكود—اضبط عدد الوكلاء والجولات. قم بالقياس المعياري عبر نصوص evaluation/، مقارنة بالخطوط الأساسية.
استكشف الأخطاء وإصلاحها باستخدام السجلات؛ يتم حل المشكلات الشائعة مثل عدم تطابق الرموز المميزة عبر فحوصات موتر BF16. للتحسين، قم بتنزيل Apidog مجانًا لمحاكاة API، واختبار نقاط نهاية الأدوات دون مكالمات حية.
يجهزك هذا الإعداد لإنشاء نماذج أولية للوكلاء بسرعة.
التوجهات المستقبلية: توسيع نطاق Tongyi DeepResearch
تتطلع Tongyi Lab إلى توسيع السياق إلى ما بعد 128 ألفًا، مما يتيح آفاقًا فائقة الطول مثل تحليلات بحجم كتاب. يخططون للتحقق من الصحة على قواعد MoE أكبر، واستكشاف حدود قابلية التوسع.
تشمل تحسينات التعلم المعزز (RL) عمليات نشر جزئية للكفاءة وطرقًا خارج السياسة لتخفيف التحولات. يمكن أن تدمج مساهمات المجتمع أدوات الرؤية أو الأدوات متعددة اللغات، مما يوسع النطاق.
مع تطور المصادر المفتوحة، سيثبت Tongyi DeepResearch التطورات التعاونية، مما يعزز مساعي الذكاء الاصطناعي العام (AGI).
الخاتمة: احتضن عصر Tongyi DeepResearch
يُحدث Tongyi DeepResearch تحولًا في الذكاء الاصطناعي الوكيلي، حيث يمزج بين الكفاءة والانفتاح والبراعة. تضعه معاييره وبنيته وتطبيقاته في موقع الريادة، متفوقًا على المنافسين مثل عروض OpenAI. أيها المطورون، استغلوا هذه القوة—قوموا بتنزيل النموذج، وجربوه، وادمجوه مع Apidog لواجهات برمجة تطبيقات سلسة.
في مجال يتسابق نحو الاستقلالية، يسرّع Tongyi DeepResearch التقدم. ابدأ البناء اليوم؛ الرؤى تنتظر.