
تتطور مشهد نماذج اللغة الكبيرة (LLMs) بسرعة فائقة. أصبحت النماذج أكثر قوة، وقدرة، والأهم من ذلك، أكثر وصولاً. كشفت فريق Qwen مؤخرًا عن Qwen3، أحدث جيل من LLMs، والذي يتمتع بأداء مثير للإعجاب عبر مجموعة متنوعة من المعايير، بما في ذلك البرمجة، الرياضيات، والتفكير العام. مع نماذج رائدة مثل Qwen3-235B-A22B التي تنافس عمالقة مؤسسين ونماذج كثيفة أصغر مثل Qwen3-4B التي تنافس نماذج الجيل السابق ذات 72B من المعلمات، تمثل Qwen3 قفزة كبيرة إلى الأمام.
أساس هذا الإصدار هو الوزن المفتوح لعدة نماذج، بما في ذلك نوعين من متجانسي الخبراء (Qwen3-235B-A22B وQwen3-30B-A3B) وستة نماذج كثيفة تتراوح من 0.6B إلى 32B من المعلمات. تدعو هذه الانفتاحية المطورين والباحثين والهواة لاستكشاف واستخدام وبناء هذه الأدوات القوية. بينما توفر واجهات برمجة التطبيقات المعتمدة على السحابة الراحة، تزداد الرغبة في تشغيل هذه النماذج المتطورة محليًا، مدفوعة بحاجات الخصوصية، التحكم في التكاليف، التخصيص، والوصول عند عدم الاتصال.
لحسن الحظ، نضج نظام الأدوات لتشغيل LLM محليًا بشكل كبير. اثنان من المنصات المميزة التي تبسط هذه العملية هما Ollama وvLLM. توفر Ollama طريقة سهلة للغاية للبدء مع مجموعة متنوعة من النماذج، بينما تقدم vLLM حل خدمة عالي الأداء محسّن للعبء والكفاءة، خاصةً للنماذج الأكبر. ستوجهك هذه المقالة لفهم Qwen3 وإعداد هذه النماذج القوية على جهازك المحلي باستخدام كل من Ollama وvLLM.
هل تريد منصة متكاملة وشاملة لفريق المطورين لديك للعمل سوياً مع أقصى قدر من الإنتاجية?
تقدم Apidog جميع مطالبك، و تستبدل Postman بسعر أكثر قدرة على تحمل التكاليف بكثير!
ما هو Qwen 3 والمعايير
تمثل Qwen3 الجيل الثالث من نماذج اللغة الكبيرة (LLMs) التي طورتها فريق Qwen، وتم إصدارها في أبريل 2025. تشير هذه النسخة إلى تقدم كبير على النسخ السابقة، مع التركيز على تحسين قدرات التفكير، والكفاءة من خلال الابتكارات المعمارية مثل متجانسي الخبراء (MoE)، ودعم متعدد اللغات أوسع، وأداء محسّن عبر مجموعة واسعة من المعايير. شمل الإصدار الوزن المفتوح لعدة نماذج تحت ترخيص Apache 2.0، مما يعزز إمكانية الوصول للبحث والتطوير.
البنية المعمارية لنموذج Qwen 3 وأنواعها، موضحاً
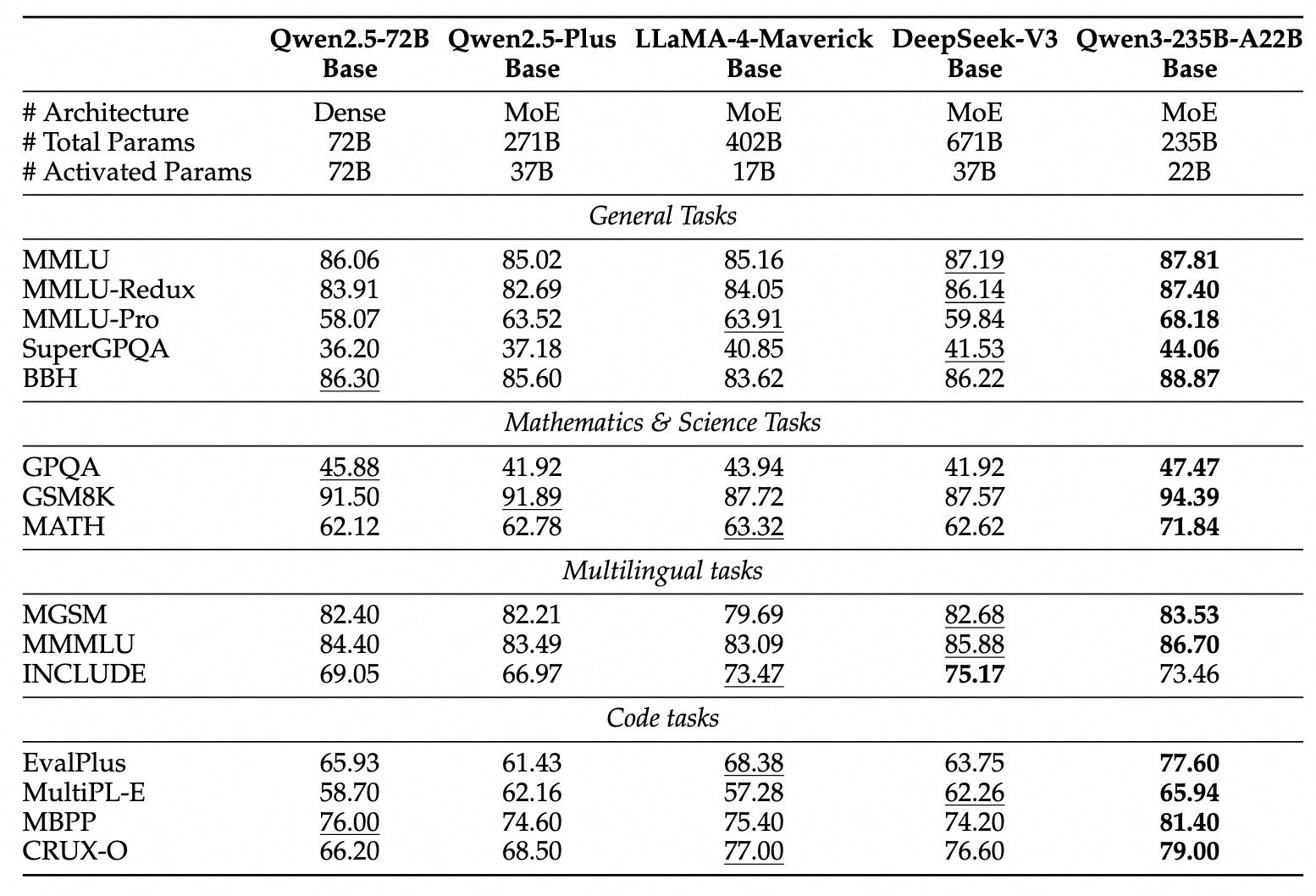
تشمل عائلة Qwen3 كل من النماذج الكثيفة التقليدية والهياكل المتجانسة MoE، لتلبية ميزانيات حسابية مختلفة ومتطلبات الأداء.
النماذج الكثيفة: تستخدم هذه النماذج جميع معلماتها أثناء الاستدلال. تشمل التفاصيل المعمارية الرئيسية:
| النموذج | الطبقات | رؤوس الانتباه (استعلام / مفتاح-قيمة) | تضمين الكلمات المرتبطة | أقصى طول للسياق |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | نعم | 32,768 توكن (32K) |
| Qwen3-1.7B | 28 | 16 / 8 | نعم | 32,768 توكن (32K) |
| Qwen3-4B | 36 | 32 / 8 | نعم | 32,768 توكن (32K) |
| Qwen3-8B | 36 | 32 / 8 | لا | 131,072 توكن (128K) |
| Qwen3-14B | 40 | 40 / 8 | لا | 131,072 توكن (128K) |
| Qwen3-32B | 64 | 64 / 8 | لا | 131,072 توكن (128K) |
ملاحظة: يتم استخدام انتباه الاستعلام المجمع (GQA) في جميع النماذج، كما هو موضح بعدد مختلف من رؤوس الاستعلام ومفتاح-قيمة.
نماذج متجانسي الخبراء (MoE): تستفيد هذه النماذج من النقص من خلال تفعيل مجموعة فقط من "الخبراء" لشبكات التغذية الأمامية (FFNs) لكل توكن أثناء الاستدلال. هذا يسمح بوجود عدد إجمالي كبير من المعلمات مع الحفاظ على التكاليف الحسابية أقرب إلى النماذج الكثيفة الأصغر.
| النموذج | الطبقات | رؤوس الانتباه (استعلام / مفتاح-قيمة) | # الخبراء (الإجمالي / المفعل) | أقصى طول للسياق |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131,072 توكن (128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131,072 توكن (128K) |
ملاحظة: تستخدم كلا النماذج من نوع MoE إجمالي 128 خبير، ولكنها تفعل فقط 8 لكل توكن، مما يقلل بشكل ملحوظ من العبء الحسابي مقارنة بنموذج كثيف بالحجم المعادل.
الميزات التقنية الرئيسية لـ Qwen 3
أوضاع التفكير الهجينة: ميزة مميزة لـ Qwen3 هي قدرتها على العمل في وضعين متميزين، يمكن التحكم فيهما من قبل المستخدم:
- وضع التفكير (افتراضي): ينفذ النموذج تفكير داخلي، خطوة بخطوة (أسلوب سلسلة أفكار) قبل توليد الاستجابة النهائية. يتم احتواء هذه العملية الفكرية، وغالبًا ما تكون مميزة برموز خاصة (على سبيل المثال، إخراج
<think>...</think>محتوى قبل الإجابة النهائية عند استخدام تكوينات إطار معينة). يعزز هذا الوضع الأداء في المهام المعقدة التي تتطلب استنتاج منطقي، تفكير رياضي، أو تخطيط. يسمح بتحسينات في الأداء قابلة للتوسع تتناسب مع ميزانية التفكير الحسابية المخصصة. - وضع غير تفكير: يولد النموذج استجابة مباشرة بدون مرحلة استنتاج داخلية صريحة، مما يؤدي إلى تحسين السرعة وتقليل التكلفة الحسابية في الاستفسارات البسيطة.
يمكن للمستخدمين التبديل ديناميكيًا بين هذه الأوضاع، قد يحدث ذلك بناءً على دورات في المحادثات متعددة الأدوار باستخدام علامات مثل/thinkو/no_thinkفي موجهاتهم (باستخدام إطار توجيهات)، مما يتيح تحكمًا دقيقًا في التوازن بين زمن الانتظار/التكلفة وعمق التفكير.
دعم متعدد اللغات الشامل: تم تدريب نماذج Qwen3 مسبقًا على مجموعة متنوعة من النصوص مما يمكّنها من دعم 119 لغة ولهجة عبر أسر اللغات الرئيسية (الأوروبية-الآسيوية، السينوتبتية، الأفروآسيوية، الأسترونيزية، الدرافيدية، التركية، وغيرها)، مما يجعلها مناسبة لمجموعة واسعة من التطبيقات العالمية.
منهجية تدريب متقدمة:
- التدريب المسبق: تم تدريب النماذج مسبقًا على مجموعة بيانات بحجم كبير تضم تريليونات من التوكنات. تضمنت المرحلة النهائية من التدريب المسبق استخدام بيانات سياق طويلة عالية الجودة لتمديد نافذة السياق الفعالة إلى 32K توكن في البداية، مع تمديدات إضافية وصلت إلى 128K للنماذج الأكبر.
- التدريب بعد الإطلاق: تم استخدام خط أنابيب معقد من أربع مراحل لتزويد النماذج بقدرات اتباع التعليمات، ومهارات التفكير، وآلية التفكير الهجينة:
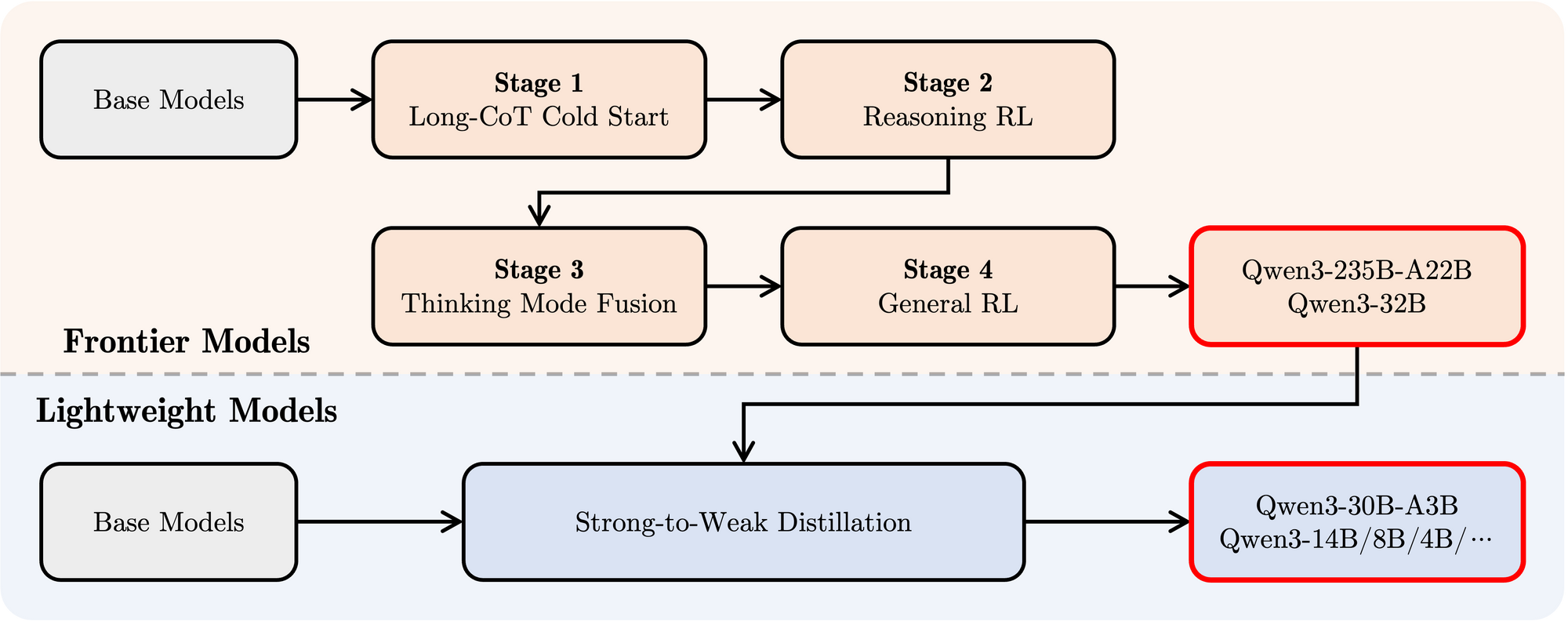
- بدء طويل السلسلة: تعزيز دقيق (SFT) باستخدام بيانات طويلة متنوعة من سلسلة الأفكار (CoT) تشمل الرياضيات، والترميز، والاستدلال المنطقي، وSTEM لبناء قدرات استدلال أساسية.
- التعلم المعزز القائم على التفكير: زيادة الموارد الحسابية للتعلم المعزز باستخدام مكافآت قائمة على القواعد لتعزيز الاستكشاف والاستغلال بصفة خاصة بالنسبة لمهام التفكير.
- دمج وضع التفكير: تكامل قدرات غير التفكير عن طريق تعزيز النموذج المحسن بالتفكير باستخدام مزيج من بيانات سلسلة الأفكار الطويلة وبيانات تعليم معيارية تم إنشاؤها بواسطة نموذج المرحلة 2. هذا يدمج التفكير العميق مع توليد استجابة سريعة.
- التعلم المعزز العام: تطبيق التعلم المعزز عبر العديد من المهام العامة (اتّباع التعليمات، الالتزام بالتنسيق، قدرات الوكيل) لتحسين السلوك العام وتقليل المخرجات غير المرغوب فيها.
أداء Qwen 3 في المعايير
تظهر Qwen3 أداءً تنافسياً عالياً مقابل نماذج معاصرة أخرى رائدة:
النموذج الرائد من نوع MoE: يحقق النموذج Qwen3-235B-A22B نتائج مشابهة لنماذج قمة مثل DeepSeek-R1، وo1 وo3-mini من Google، وGrok-3، وGemini-2.5-Pro عبر معايير مختلفة تقيم البرمجة، والرياضيات، والقدرات العامة.
MoE الأصغر: يتفوق النموذج Qwen3-30B-A3B بشكل كبير على نماذج مثل QwQ-32B، على الرغم من تفعيل فقط جزء (3B مقابل 32B) من المعلمات أثناء الاستدلال، مما يبرز كفاءة بنية MoE.
النماذج الكثيفة: نظرًا للتطورات المعمارية والتدريب، عادةً ما تتطابق نماذج Qwen3 الكثيفة مع أو تتجاوز أداء نماذج Qwen2.5 الكثيفة الأكبر حجماً. على سبيل المثال:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(وتتنافس معQwen2.5-72B-Instructفي بعض الجوانب)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
ملحوظة، تظهر نماذج Qwen3 الكثيفة تحسنًا كبيرًا في الأداء مقارنة بأسلافها في مهام STEM، والترميز، والتفكير.
كفاءة MoE: تحقق نماذج Qwen3 من نوع MoE أداءً مشابهاً لنماذج Qwen2.5 الكثيفة الأكبر بكثير مع تفعيل حوالي 10% فقط من المعلمات، مما يؤدي إلى توفير كبير في كل من التدريب والاستدلال.
تؤكد هذه النتائج المعيارية على موقع Qwen3 كعائلة نماذج متقدمة تقدم أداءً عالياً وأيضًا، خصوصًا مع نماذج MoE، كفاءة حسابية محسنة. النماذج متاحة من خلال منصات قياسية مثل Hugging Face وModelScope وKaggle، وهي مدعومة بأطر نشر شعبية مثل Ollama وvLLM وSGLang وLMStudio وllama.cpp، مما يسهل دمجها في مجموعة متنوعة من تدفقات العمل والتطبيقات، بما في ذلك التنفيذ المحلي.
كيفية تشغيل Qwen 3 محليًا باستخدام Ollama
حصلت Ollama على شعبية واسعة بسبب بساطتها في التنزيل، الإدارة، وتشغيل LLMs محليًا. فهي تُخفي كثيرًا من التعقيد، مُقدمة واجهة سطر الأوامر وخادم API.
1. التثبيت:
يكون تثبيت Ollama عادةً بسيطًا. قم بزيارة الموقع الرسمي لـ Ollama (ollama.com) واتبع تعليمات التنزيل لنظام التشغيل الخاص بك (macOS، Linux، Windows).
2. سحب نماذج Qwen3:
تحافظ Ollama على مكتبة من النماذج المتاحة. لتشغيل نموذج Qwen3 معين، استخدم الأمر ollama run. إذا لم يكن النموذج موجودًا محليًا، ستقوم Ollama بتحميله تلقائيًا. جعل فريق Qwen عدة أنواع من Qwen3 متاحة مباشرة على مكتبة Ollama.
يمكنك العثور على علامات Qwen3 المتاحة على صفحة Qwen3 لموقع Ollama (مثل ollama.com/library/qwen3). قد تشمل العلامات الشائعة:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(نموذج MoE الأصغر)
لتشغيل نموذج المعلمات 4B، على سبيل المثال، افتح الطرفية الخاصة بك واكتب:
ollama run qwen3:4b
سيقوم هذا الأمر بتحميل النموذج (إذا لزم الأمر) وبدء جلسة دردشة تفاعلية.
3. التفاعل مع النموذج:
بمجرد تنشيط الأمر ollama run، يمكنك كتابة الموجهات الخاصة بك مباشرة في الطرفية. تبدأ Ollama أيضًا خادمًا محليًا (عادةً عند http://localhost:11434) الذي يعرض API متوافقًا مع معيار OpenAI. يمكنك التفاعل مع هذا برمجيًا باستخدام أدوات مثل curl أو مختلف مكتبات العميل في Python، JavaScript، إلخ.
4. اعتبارات الأجهزة:
يتطلب تشغيل LLMs محليًا موارد كبيرة.
- RAM: حتى النماذج الأصغر (0.6B، 1.7B) تتطلب عدة جيجابايت من RAM. تحتاج النماذج الأكبر (8B، 14B، 32B، 30B-A3B) إلى موارد أكبر بشكل كبير، وغالبًا ما تحتاج إلى 16GB، 32GB، أو حتى 64GB+، حسب مستوى التكميم الذي تستخدمه Ollama.
- VRAM (GPU): للحصول على أداء مقبول، يوصى بشدة باستخدام GPU مخصص مع VRAM وافر. تستخدم Ollama تلقائيًا وحدات معالجة الرسوم المتوافقة (NVIDIA، Apple Silicon). يحدد مقدار VRAM أكبر نموذج يمكنك تشغيله تمامًا على GPU، مما يزيد بشكل كبير من سرعة الاستدلال.
- CPU: بينما يمكن لـ Ollama تشغيل النماذج على CPU، سيكون الأداء منخفضًا بشكل كبير مقارنةً بـ GPU.
تعتبر Ollama ممتازة للبدء بسرعة، التطوير المحلي، التجريب، وتطبيقات الدردشة للمستخدمين الفرديين، خاصةً على الأجهزة المخصصة لكفاءة معينة (ضمن الحدود).
كيفية تشغيل Ollama محليًا مع vLLM
vLLM هي مكتبة تقدم LLM ذات قدرة عالية على الإخراج، وتستخدم تحسينات مثل PagedAttention لتحسين سرعة الاستدلال وكفاءة الذاكرة بشكل ملحوظ، مما يجعلها مثالية للتطبيقات متعددة الطلبات وخدمة النماذج الأكبر. يوفر فريق vLLM دعمًا ممتازًا للهياكل الجديدة، بما في ذلك دعم اليوم الأول لـ Qwen3 عند إصدارها.
1. التثبيت:
قم بتثبيت vLLM باستخدام pip. يوصى عمومًا باستخدام بيئة افتراضية:
pip install -U vllm
تأكد من أنك تملك المتطلبات اللازمة، عادةً ما يكون لديك وحدة معالجة رسوم NVIDIA متوافقة مع مجموعة أدوات CUDA المناسبة. راجع وثائق vLLM لمتطلبات محددة.
2. خدمة نماذج Qwen3:
تستخدم vLLM الأمر vllm serve لتحميل نموذج وإطلاق خادم API متوافق مع OpenAI. يقدم فريق Qwen و وثائق vLLM إرشادات حول كيفية تشغيل Qwen3.
استنادًا إلى المعلومات المقدمة والاستخدام الشائع لـ vLLM، إليك كيفية خدمة نموذج Qwen3-235B MoE الكبير باستخدام تكميم FP8 (لتقليل استخدام الذاكرة) والتوازي عبر 4 وحدات معالجة رسوم:
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
دعونا نفصل هذا الأمر:
Qwen/Qwen3-235B-A22B-FP8: هذا هو معرف النموذج، ويشير على الأرجح إلى موقع في مستودع Hugging Face. يشيرFP8إلى استخدام تكميم النقطة العائمة مل ت. الثمانية بتات، مما يقلل من البصمة الذاكرية للنموذج مقارنة بـ FP16 أو BF16، وهو أمر بالغ الأهمية لنموذج بهذا الحجم.--enable-reasoning: تعتبر هذه العلامة ضرورية لتفعيل قدرات التفكير الهجينة لـ Qwen3 في vLLM.--reasoning-parser deepseek_r1: يتمتع إنتاج التفكير لـ Qwen3 بتنسيق معين. يحتاج vLLM إلى محلل للتعامل مع ذلك. تشير التدوينة إلى أنه بالنسبة لـ vLLM، ينبغي استخدام محللdeepseek_r1(بينما تستخدم SGLang محللqwen3). يضمن ذلك أن vLLM يمكنه تفسير خطوات التفكير بشكل صحيح وفصلها عن الاستجابة النهائية.--tensor-parallel-size 4: وتسترشد هذه العلامة vLLM بتوزيع أوزان النموذج والحساب عبر 4 وحدات معالجة رسوم. يعتبر التوازي المحدد للتوترات ضروريًا لتشغيل نماذج أكبر من أن تتناسب على وحشة واحدة من GPU. يمكنك ضبط هذا الرقم بناءً على وحدات معالجة الرسوم المتاحة لديك.
يمكنك تعديل هذا الأمر لنماذج Qwen3 الأخرى (مثل Qwen/Qwen3-30B-A3B أو Qwen/Qwen3-32B) وضبط المعلمات مثل tensor-parallel-size حسب الأجهزة الخاصة بك.
3. التفاعل مع خادم vLLM:
بمجرد تشغيل vllm serve، يستضيف خادم API (يكون بشكل افتراضي عند http://localhost:8000) ويتطابق مع مواSpecification الـ API لـ OpenAI. يمكنك التفاعل معه باستخدام أدوات قياسية:
- curl:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # استخدم اسم النموذج الذي قمت بخدمته
"prompt": "اشرح مفهوم متجانسي الخبراء في LLMs.",
"max_tokens": 150,
"temperature": 0.7
}'
- عميل Python OpenAI:
from openai import OpenAI
# الإشارة إلى خادم vLLM المحلي
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # استخدم اسم النموذج الذي قمت بخدمته
prompt="اكتب قصة قصيرة عن روبوت يكتشف الموسيقى.",
max_tokens=200
)
print(completion.choices[0].text)
4. الأداء وحالات الاستخدام:
يتألق vLLM في السيناريوهات التي تتطلب إنتاجية عالية (العديد من الطلبات في الثانية) وزمن استجابة منخفض. تجعل تحسيناته منه مناسبًا لـ:
- بناء تطبيقات مدعومة بـ LLMs محلية.
- خدمة النماذج للعديد من المستخدمين بالتوازي.
- نشر نماذج كبيرة تتطلب إعدادات متعددة لوحدات المعالجة الرسومية.
- بيئات الإنتاج حيث يكون الأداء أمرًا حاسمًا.
اختبار واجهة API المحلية لـ Ollama باستخدام Apidog
Apidog هو أداة اختبار API تتناسب تمامًا مع وضع API الخاص بـ Ollama. يتيح لك إرسال الطلبات، عرض الاستجابات، وتصحيح إعداد Qwen 3 الخاص بك بشكل فعال.
إليك كيفية استخدام Apidog مع Ollama:
- أنشئ طلب API جديد:
- نقطة النهاية:
http://localhost:11434/api/generate - أرسل الطلب وتابع الاستجابة في الشريط الزمني الفوري لـ Apidog.
- استخدم استخراج JSONPath من Apidog لتحليل الردود تلقائيًا، وهي ميزة تتفوق على أدوات مثل Postman.


استجابات مباشرة:
- لتطبيقات الوقت الحقيقي، قم بتمكين التدفق:
- تجمع ميزة الدمج التلقائي لـ Apidog رسائل التعبير المباشر، مما يبسط التصحيح.
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "اكتب قصيدة عن الذكاء الاصطناعي.", "stream": true}'

تضمن هذه العملية أن النموذج الخاص بك يعمل كما هو متوقع، مما يجعل Apidog إضافة قيمة.
الخاتمة
تعتبر إصدار عائلة نماذج Qwen3 القوية والمتنوعة، جنبًا إلى جنب مع أدوات التنفيذ المحلية الناضجة مثل Ollama وvLLM، علامة على وقت مثير لممارسي الذكاء الاصطناعي. سواء كنت تفضل بساطة التوصيل والتشغيل لـ Ollama للاستخدام الشخصي والتجريب أو القدرات العالية في تقديم الأداء لـ vLLM لبناء تطبيقات قوية، فإن تشغيل نماذج LLM المتطورة محليًا أصبح ممكنًا أكثر من أي وقت مضى.
من خلال جلب نماذج مثل Qwen3-30B-A3B أو حتى الأنماط الكثيفة الأكبر إلى الأجهزة الخاصة بك، تحصل على تحكم غير مسبوق، وخصوصية، وفعالية من حيث التكلفة. يمكنك الاستفادة من ميزاتها المتقدمة، مثل التفكير الهجين والدعم المتعدد اللغات الواسع، لمشاريع مبتكرة. مع استمرار تحسين البيئات البرمجية والأدوات، ستصبح قوة نماذج اللغة الكبيرة أكثر ديمقراطية، تنتقل من خوادم السحابة البعيدة مباشرة إلى أجهزتنا المحلية. جرب Qwen3 باستخدام Ollama وvLLM لتختبر طليعة هذه الثورة المحلية للذكاء الاصطناعي.
هل تريد منصة متكاملة وشاملة لفريق المطورين لديك للعمل سوياً مع أقصى قدر من الإنتاجية?
تقدم Apidog جميع مطالبك، و تستبدل Postman بسعر أكثر قدرة على التحمل بكثير!