
إن تشغيل نماذج لغوية كبيرة مثل Mistral 3 على جهازك المحلي يمنح المطورين تحكمًا لا مثيل له في خصوصية البيانات وسرعة الاستدلال والتخصيص. مع تزايد متطلبات أعباء عمل الذكاء الاصطناعي، يصبح التنفيذ المحلي ضروريًا لإنشاء النماذج الأولية والاختبار ونشر التطبيقات دون اتصال بالإنترنت. علاوة على ذلك، تبسط أدوات مثل Ollama هذه العملية، مما يتيح لك الاستفادة من قدرات Mistral 3 مباشرة من جهاز الكمبيوتر المكتبي أو الخادم الخاص بك.
يزودك هذا الدليل بتعليمات خطوة بخطوة لتثبيت وتشغيل متغيرات Mistral 3 محليًا. نركز على سلسلة Ministral 3 مفتوحة المصدر، والتي تتفوق في عمليات النشر على الأجهزة الطرفية. بنهاية هذا الدليل، ستكون قد حسّنت الأداء للمهام الواقعية، مما يضمن استجابات منخفضة الكمون وكفاءة في استخدام الموارد.
فهم Mistral 3: القوة مفتوحة المصدر في الذكاء الاصطناعي
تواصل Mistral AI تجاوز الحدود بإصدارها الأخير: Mistral 3. يثني المطورون والباحثون على هذه المجموعة من النماذج لتوازنها بين الدقة والكفاءة وسهولة الوصول. على عكس العمالقة الاحتكارية، يتبنى Mistral 3 مبادئ المصادر المفتوحة، ويتم إصداره بموجب ترخيص Apache 2.0. تُمكّن هذه الخطوة المجتمع من التعديل والتوزيع والابتكار دون قيود.
في جوهره، يتكون Mistral 3 من فرعين رئيسيين: سلسلة Ministral 3 المدمجة وMistral Large 3 الموسعة. تستهدف نماذج Ministral 3—المتوفرة بأحجام 3B و 8B و 14B معلمة—البيئات ذات الموارد المحدودة. يصمم المهندسون هذه النماذج للاستخدامات المحلية والطرفية، حيث كل واط ونواة مهمان. على سبيل المثال، يتناسب متغير 3B بسهولة مع أجهزة الكمبيوتر المحمولة ذات وحدات معالجة الرسومات المتواضعة، بينما يدفع 14B الحدود على إعدادات وحدات معالجة الرسومات المتعددة دون التضحية بالسرعة.
أما Mistral Large 3، من ناحية أخرى، فيستخدم بنية "خليط الخبراء المتناثرة" مع 41 مليار معلمة نشطة و 675 مليار معلمة إجمالية. يعمل هذا التصميم على تنشيط الخبراء ذوي الصلة فقط لكل استعلام، مما يقلل من النفقات الحسابية. يصل المطورون إلى إصدارات معدلة حسب التعليمات لمهام مثل المساعدة في البرمجة، وتلخيص المستندات، والترجمة متعددة اللغات. يدعم النموذج أكثر من 40 لغة بشكل أصلي، متفوقًا على أقرانه في الحوارات غير الإنجليزية.
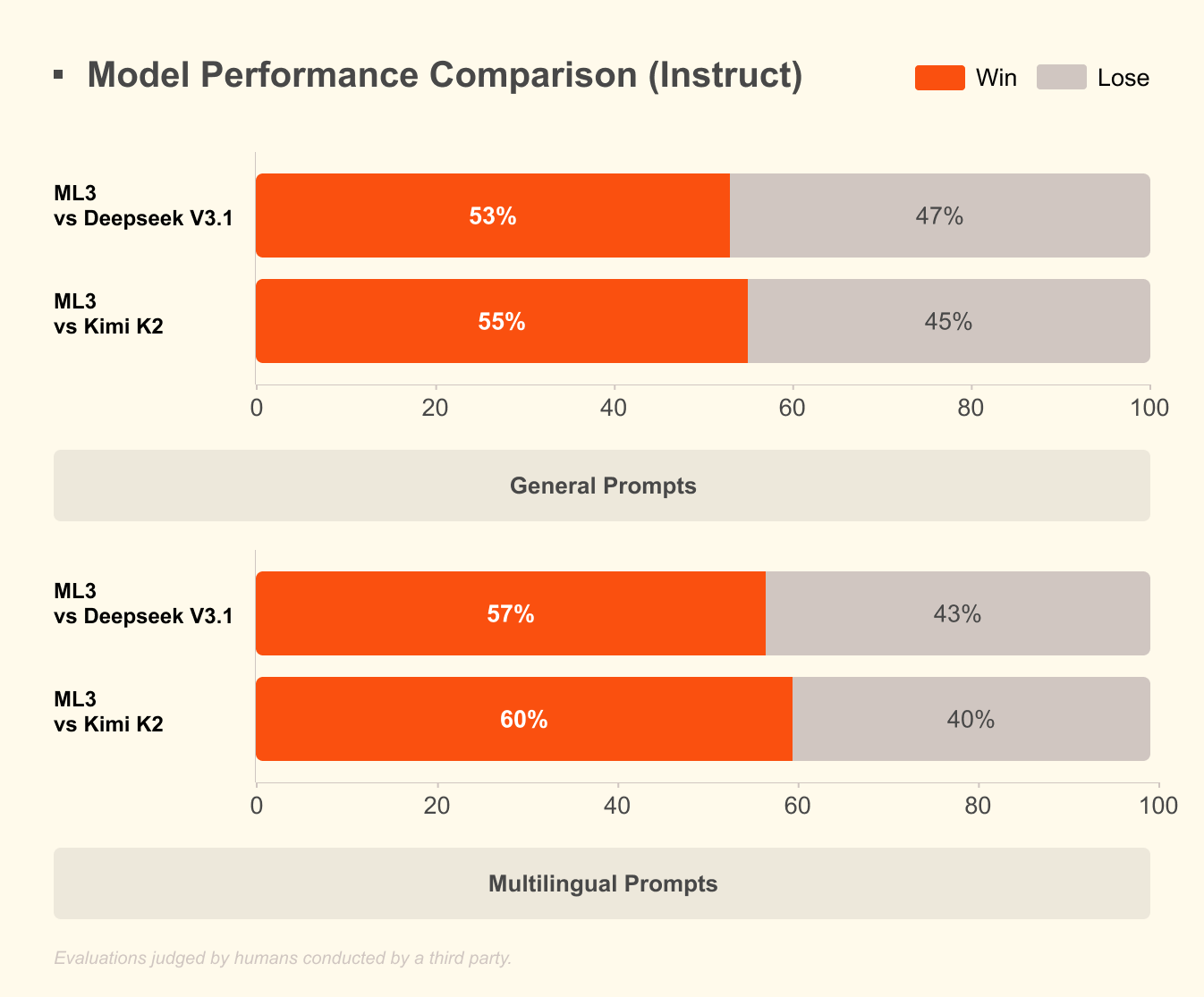
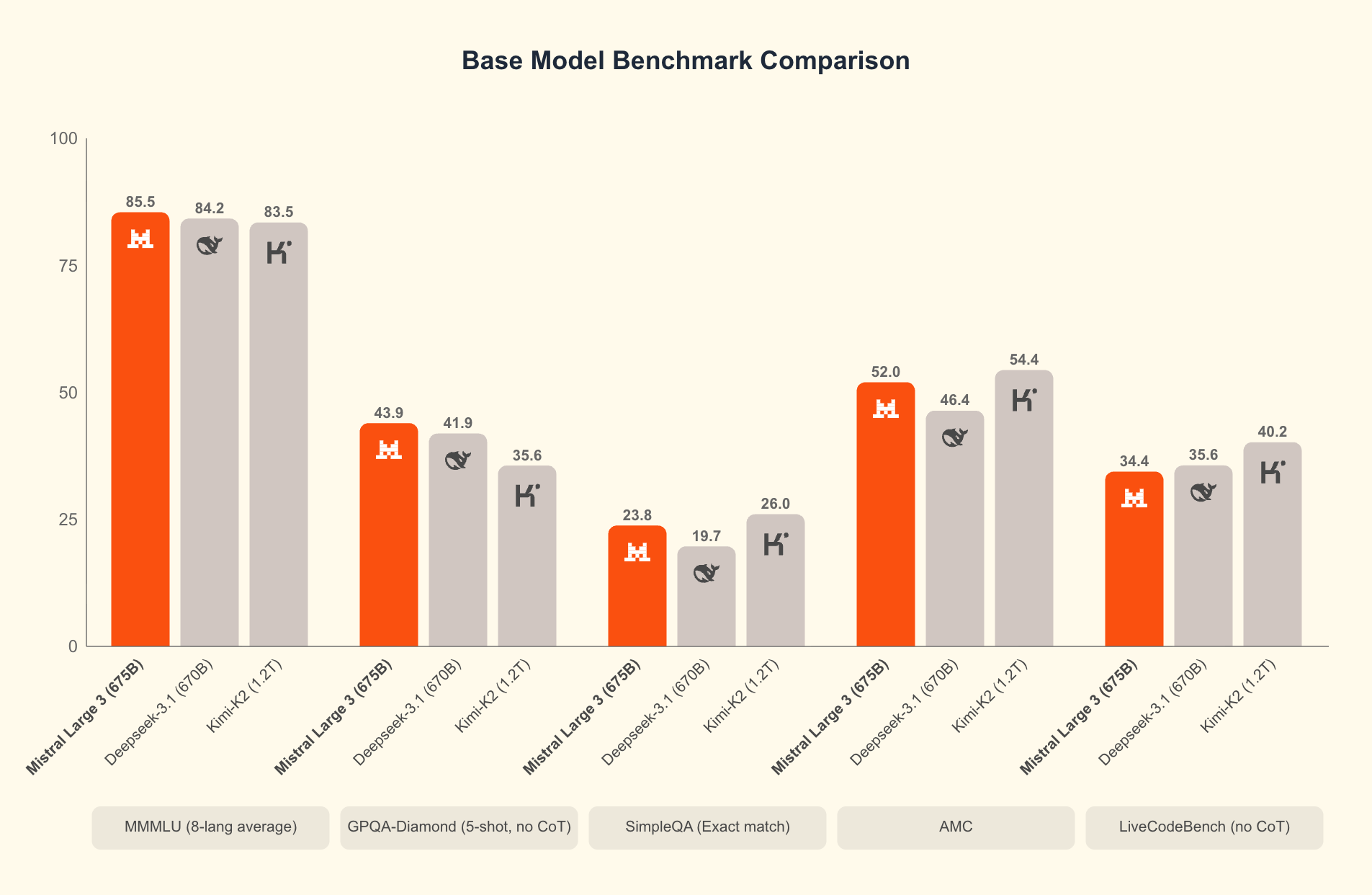
ما الذي يميز Mistral 3؟ تكشف المعايير عن تفوقه في السيناريوهات الواقعية. على مجموعة بيانات GPQA Diamond—وهو اختبار صارم للتفكير العلمي—تحافظ متغيرات Mistral 3 على دقة عالية حتى مع زيادة رموز الإخراج. على سبيل المثال، يحافظ نموذج Ministral 3B Instruct على دقة تتراوح بين 35-40% حتى 20,000 رمز، منافسًا النماذج الأكبر مثل Gemma 2 9B مع استخدام موارد أقل. تنبع هذه الكفاءة من تقنيات التكميم المتقدمة، مثل ضغط NVFP4، الذي يقلل حجم النموذج دون تدهور جودة الإخراج.
علاوة على ذلك، يدمج Mistral 3 ميزات متعددة الوسائط، معالجة الصور جنبًا إلى جنب مع النص لتطبيقات الاستجابة البصرية للأسئلة أو إنشاء المحتوى. يؤدي فتح مصدر هذه النماذج إلى التكرار السريع؛ وتقوم المجتمعات بالفعل بضبطها الدقيق لمجالات متخصصة مثل التحليل القانوني أو الكتابة الإبداعية. ونتيجة لذلك، يضفي Mistral 3 الطابع الديمقراطي على الذكاء الاصطناعي الرائد، مما يمكّن الشركات الناشئة والمطورين الأفراد من التنافس مع عمالقة التكنولوجيا الكبار.

بالانتقال من النظرية إلى التطبيق العملي، يطلق تشغيل هذه النماذج محليًا إمكاناتها الكاملة. فواجهات برمجة تطبيقات السحابة (Cloud APIs) تسبب زمن انتقال وتكاليف، لكن الاستدلال المحلي يقدم استجابات في جزء من الثانية. بعد ذلك، سنفحص المتطلبات المسبقة للأجهزة التي تجعل ذلك ممكنًا.
لماذا تشغل Mistral 3 محليًا؟ الفوائد للمطورين ومكاسب الكفاءة
يختار المطورون التنفيذ المحلي لعدة أسباب مقنعة. أولاً، الخصوصية هي الأهم: تبقى البيانات الحساسة على جهازك، مما يتجنب خوادم الطرف الثالث. في الصناعات المنظمة مثل الرعاية الصحية أو التمويل، تثبت هذه الميزة في الامتثال أنها لا تقدر بثمن. ثانيًا، تتراكم وفورات التكلفة بسرعة. تعني الكفاءة العالية لـ Mistral 3 أنك تتجنب الرسوم لكل رمز مميز، وهو أمر مثالي لاختبارات الحجم الكبير.
علاوة على ذلك، تعمل عمليات التشغيل المحلية على تسريع التجريب. قم بتكرار المطالبات، وضبط المعلمات الفائقة، أو ربط النماذج دون تأخير الشبكة. تؤكد المعايير ذلك: على الأجهزة الاستهلاكية، يحقق Ministral 8B 50-60 رمزًا في الثانية، وهو ما يضاهي إعدادات السحابة ولكن بدون توقف.
الكفاءة تحدد جاذبية Mistral 3. النماذج محسّنة للاستدلال منخفض التكلفة، كما يتضح من نتائج GPQA Diamond حيث تتفوق متغيرات Ministral على Gemma 3 4B و 12B في الدقة المستمرة. هذا مهم للمهام ذات السياق الطويل؛ مع امتداد المخرجات إلى 20,000 رمز، تنخفض الدقة بشكل طفيف، مما يضمن أداءً موثوقًا في روبوتات الدردشة أو مولدات التعليمات البرمجية.
بالإضافة إلى ذلك، يتيح الوصول مفتوح المصدر عبر منصات مثل Hugging Face التكامل السلس مع أدوات مثل Apidog لإنشاء نماذج API الأولية. اختبر نقاط نهاية Mistral 3 محليًا قبل التوسع، لردم الفجوة بين التطوير والإنتاج.
ومع ذلك، يعتمد النجاح على الإعداد الصحيح. مع توفر الأجهزة، تشرع في التثبيت. يضمن هذا الإعداد التشغيل السلس وزيادة الإنتاجية.
متطلبات الأجهزة والبرامج لنشر Mistral 3 المحلي
قبل إطلاق Mistral 3، قم بتقييم قدرات نظامك. تشمل المواصفات الدنيا وحدة معالجة مركزية حديثة (Intel i7 أو AMD Ryzen 7) مع 16 جيجابايت من ذاكرة الوصول العشوائي (RAM) لنموذج 3B. أما لمتغيرات 8B و 14B، فخصص 32 جيجابايت من ذاكرة الوصول العشوائي ووحدة معالجة رسوميات NVIDIA بذاكرة فيديو (VRAM) لا تقل عن 8 جيجابايت—مثل RTX 3060 أو أفضل. يستفيد مستخدمو Apple Silicon من الذاكرة الموحدة؛ M1 Pro بذاكرة 16 جيجابايت يتعامل مع 3B دون عناء، بينما M3 Max يتفوق في 14B.
تتنوع متطلبات التخزين: يشغل نموذج 3B حوالي 2 جيجابايت مكممة، وتزداد إلى حوالي 9 جيجابايت لـ 14B. استخدم أقراص الحالة الصلبة (SSDs) لتحميل أسرع. أنظمة التشغيل؟ يوفر Linux (Ubuntu 22.04) أفضل أداء، يليه macOS Ventura+. يعمل Windows 11 عبر WSL2، على الرغم من أن تمرير وحدة معالجة الرسومات يتطلب تعديلات.
من الناحية البرمجية، يشكل Python 3.10+ العمود الفقري. قم بتثبيت CUDA 12.1 لبطاقات NVIDIA لتمكين تسريع وحدة معالجة الرسومات—وهو أمر ضروري لأزمنة استجابة أقل من 100 مللي ثانية. للتشغيل على وحدة المعالجة المركزية فقط، استفد من مكتبات مثل ONNX Runtime.
يلعب التكميم دورًا محوريًا هنا. يدعم Mistral 3 تنسيقات 4 بت و 8 بت، مما يقلل من حجم الذاكرة بنسبة 75% مع الحفاظ على 95% من الدقة. تتعامل أدوات مثل bitsandbytes مع هذا تلقائيًا.
بمجرد التجهيز، يتبع التثبيت مسارًا مباشرًا. نوصي بـ Ollama لبساطته، ولكن البدائل موجودة. هذا الاختيار يبسط العملية، ويقودنا إلى خطوات الإعداد الأساسية.
تثبيت Ollama: البوابة إلى الذكاء الاصطناعي المحلي السهل
تبرز Ollama كأداة رئيسية لتشغيل النماذج مفتوحة المصدر مثل Mistral 3 محليًا. تعمل هذه المنصة خفيفة الوزن على تجريد التعقيدات، وتوفر واجهة سطر أوامر (CLI) وخادم API في حزمة واحدة. يقدر المطورون دعمها عبر الأنظمة الأساسية والكشف عن وحدة معالجة الرسومات بدون تهيئة.
ابدأ بتنزيل Ollama من الموقع الرسمي (ollama.com). على نظام Linux، نفذ:
curl -fsSL https://ollama.com/install.sh | sh
يقوم هذا السكريبت بتثبيت الثنائيات وإعداد الخدمات. تحقق باستخدام ollama --version؛ توقع إخراجًا مثل "ollama version 0.3.0". لنظام macOS، يتعامل مثبت DMG مع التبعيات، بما في ذلك Rosetta لمحاكاة Intel على ARM.
يجب على مستخدمي Windows الحصول على ملف EXE من إصدارات GitHub. بعد التثبيت، قم بالتشغيل عبر PowerShell: ollama serve. تعمل Ollama كخدمة خلفية (daemon)، وتعرض واجهة برمجة تطبيقات REST على المنفذ 11434.
لماذا Ollama؟ إنها تسحب النماذج من سجلها، بما في ذلك Ministral 3، مع تكميم مدمج. لا حاجة إلى استنساخ Hugging Face يدويًا. بالإضافة إلى ذلك، تدعم Modelfiles للضبط الدقيق المخصص، بما يتماشى مع روح Mistral 3 مفتوحة المصدر.
مع جاهزية Ollama، ستسحب وتشغل النماذج بعد ذلك. تحول هذه الخطوة إعدادك إلى محطة عمل AI وظيفية.
سحب وتشغيل نماذج Ministral 3 باستخدام Ollama
تستضيف مكتبة Ollama متغيرات Ministral 3.
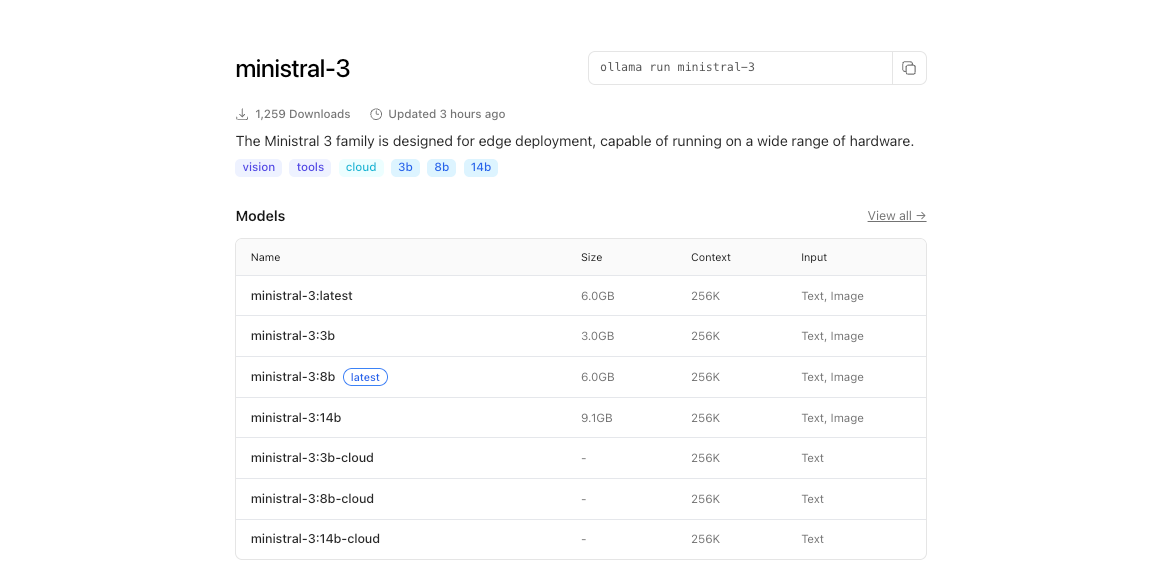
ابدأ بسرد العلامات المتاحة:
ollama list
لتنزيل نموذج 3B:
ollama pull ministral:3b-instruct-q4_0
يقوم هذا الأمر بجلب ~2 جيجابايت، ويتحقق من السلامة عبر التجزئة. تتعقب أشرطة التقدم التنزيل، والذي يكتمل عادةً في دقائق على النطاق العريض.
ابدأ جلسة تفاعلية:
ollama run ministral-3
تحمل Ollama النموذج إلى الذاكرة، مما يؤدي إلى تسخين ذاكرات التخزين المؤقت للاستعلامات اللاحقة. اكتب المطالبات مباشرة؛ على سبيل المثال:
>> Explain quantum entanglement in simple terms.

يستجيب النموذج في الوقت الفعلي، مستفيدًا من ضبط التعليمات للمخرجات المتماسكة. للخروج، استخدم /bye.
استكشاف المشكلات الشائعة وإصلاحها؟ إذا حدث نقص في استخدام وحدة معالجة الرسومات، قم بتعيين المتغير البيئي OLLAMA_NUM_GPU=999. بالنسبة لأخطاء نفاد الذاكرة (OOM)، انتقل إلى تكميم أقل مثل q3_K_M.
أبعد من الأساسيات، تتيح واجهة برمجة تطبيقات Ollama الوصول البرنامجي. قم بطلب إكمال باستخدام Curl:
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "Write a Python function to sort a list.",
"stream": false
}'
يتضمن استجابة JSON هذه نصًا تم إنشاؤه، وهو مثالي للدمج مع Apidog أثناء تطوير API.
تشغيل النماذج يمثل البداية؛ التحسين يرفع الأداء. ونتيجة لذلك، ننتقل إلى التقنيات التي تستغل كل قطرة من الكفاءة من جهازك.
تحسين استدلال Mistral 3: مقايضات السرعة والذاكرة والدقة
الكفاءة تحدد نجاح الذكاء الاصطناعي المحلي. يتألق تصميم Mistral 3 هنا، لكن التعديلات تزيد المكاسب. ابدأ بالتكميم: تستخدم Ollama افتراضيًا Q4_0، موازنة بين الحجم والدقة. للموارد شديدة الانخفاض، جرب Q2_K—مضاعفة الذاكرة مقابل تكلفة 10% في الارتباك.
تنسيق وحدة معالجة الرسومات مهم. قم بتمكين الانتباه السريع عبر OLLAMA_FLASH_ATTENTION=1 لتحقيق تسريع بمقدار 2x على السياقات الطويلة. يدعم Mistral 3 ما يصل إلى 128 ألف رمز؛ اختبر باستخدام مطالبات بأسلوب GPQA للتحقق من الدقة المستمرة.
تزيد المعالجة الدفعية من الإنتاجية. استخدم /api/generate في Ollama مع مطالبات متعددة بالتوازي، مستفيدًا من عملاء Python غير المتزامنين. على سبيل المثال، قم ببرمجة حلقة:
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["Prompt 1", "Prompt 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
يتعامل هذا مع أكثر من 10 استعلامات في الثانية على إعدادات متعددة النوى.
تمنع إدارة الذاكرة عمليات التبادل. راقب باستخدام nvidia-smi؛ قم بتحميل الطبقات إلى وحدة المعالجة المركزية إذا نفدت ذاكرة الفيديو (VRAM). تتكامل مكتبات مثل vLLM مع Ollama للدفعات المستمرة، مما يحافظ على 100 رمز/ثانية على وحدات A100.
ضبط الدقة؟ قم بالضبط الدقيق باستخدام محولات LoRA على بيانات المجال. تطبق مكتبة PEFT من Hugging Face هذه على Ministral 3، مما يتطلب مساحة إضافية تبلغ حوالي 1 جيجابايت. بعد الضبط الدقيق، قم بالتصدير إلى تنسيق Ollama عبر ollama create.
قم بقياس إعداداتك مقابل GPQA Diamond. قم بتقييمات برمجية لرسم الدقة مقابل الرموز، مما يعكس مخططات Mistral. تحافظ المتغيرات عالية الكفاءة مثل Ministral 8B على درجات تزيد عن 50%، مما يؤكد تفوقها على Qwen 2.5 VL.
تُعد هذه التحسينات لإعدادك للتطبيقات المتقدمة. وبالتالي، نستكشف عمليات التكامل التي توسع نطاق Mistral 3.
دمج Mistral 3 مع أدوات التطوير: واجهات برمجة التطبيقات وما بعدها
يزدهر Mistral 3 المحلي في الأنظمة البيئية. قم بإقرانه مع Apidog لمحاكاة واجهات برمجة التطبيقات المدعومة بالذكاء الاصطناعي. صمم نقاط نهاية تستعلم Ollama، واختبر الحمولات، وتحقق من الاستجابات—كل ذلك دون اتصال بالإنترنت.
على سبيل المثال، قم بإنشاء مسار POST /generate في Apidog، وقم بإعادة توجيهه إلى واجهة برمجة تطبيقات Ollama. استورد مجموعات لقوالب المطالبات، مما يضمن أن Mistral 3 يتعامل مع الطلبات متعددة اللغات بسلاسة.
يقوم مستخدمو LangChain بربط Mistral 3 بالأدوات:
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello world"}))
يعالج هذا الإعداد 50 استعلامًا في الدقيقة، وهو مثالي لخطوط أنابيب RAG.
تعرض لوحات معلومات Streamlit المخرجات بشكل مرئي. قم بتضمين استدعاءات Ollama في التطبيقات للدردشات التفاعلية، مستفيدًا من قدرة Mistral 3 على التفكير لأسئلة وأجوبة ديناميكية.
اعتبارات الأمان؟ قم بتشغيل Ollama خلف وكلاء NGINX، مع تحديد معدل الوصول إلى نقاط النهاية. للإنتاج، قم بتغليفه في حاويات باستخدام Docker:
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
يعزل هذا البيئات، ويتوسع إلى Kubernetes.
مع تطور التطبيقات، يصبح الرصد أمرًا أساسيًا. تتعقب أدوات مثل Prometheus زمن الوصول، وتنبه إلى الانحرافات عن كفاءة الخط الأساسي.
باختصار، تحوّل عمليات التكامل هذه Mistral 3 من نموذج مستقل إلى محرك متعدد الاستخدامات. ومع ذلك، تنشأ التحديات؛ معالجتها تضمن عمليات نشر قوية.
استكشاف الأخطاء الشائعة في تشغيل Mistral 3 محليًا
حتى الإعدادات المحسنة تواجه عقبات. تتصدر مشكلات عدم تطابق CUDA القائمة: تحقق من الإصدارات باستخدام nvcc --version. قم بالرجوع إلى إصدار أقدم إذا نشأت تعارضات، حيث أن Mistral 3 يتوافق مع الإصدار 11.8+.
فشل تحميل النموذج؟ امسح ذاكرة التخزين المؤقت لـ Ollama: ollama rm ministral:3b-instruct-q4_0 ثم اسحبه مرة أخرى. تنبع التنزيلات التالفة من الشبكات؛ استخدم --insecure باعتدال.
على نظام macOS، يتأخر تسريع Metal عن CUDA. اجبر وحدة المعالجة المركزية على الثبات: OLLAMA_METAL=0. يقوم مستخدمو Windows WSL بتمكين برامج تشغيل NVIDIA عبر wsl --update.
تعاني أجهزة الكمبيوتر المحمولة من ارتفاع درجة الحرارة؛ قم بتقليل السرعة باستخدام nvidia-smi -pl 100 لتحديد الطاقة. بالنسبة لانخفاض الدقة، افحص المطالبات—يتفوق Ministral 3 في تنسيقات التعليمات.
تحل منتديات المجتمع على Reddit و Hugging Face 90% من الحالات الهامشية. سجل الأخطاء باستخدام OLLAMA_DEBUG=1 للتشخيص.
مع تجاوز العقبات، يقدم Mistral 3 قيمة ثابتة. أخيرًا، نتأمل في تأثيره الأوسع.
الخاتمة: استغل Mistral 3 محليًا لابتكارات الذكاء الاصطناعي المستقبلية
يعيد Mistral 3 تعريف الذكاء الاصطناعي مفتوح المصدر بمزيجه من القوة والعملية. من خلال تشغيله محليًا عبر Ollama، يكتسب المطورون السرعة والخصوصية والتحكم في التكلفة الذي لا يمكن تحقيقه في أي مكان آخر. من سحب النماذج إلى دمجها بدقة، يزودك هذا الدليل بخطوات قابلة للتنفيذ.
جرب بجرأة: ابدأ بمتغير 3B، وقم بالتوسع إلى 14B، وقارن بالمعايير. مع تكرار Mistral AI، ستبقى عمليات التشغيل المحلية متقدمًا.
هل أنت مستعد للبناء؟ قم بتنزيل Apidog مجانًا وقم بإنشاء نماذج أولية لواجهات برمجة التطبيقات المدعومة بإعداد Mistral 3 الخاص بك. يبدأ مستقبل الذكاء الاصطناعي الفعال على جهازك—اجعله ذا قيمة.